
Nutanix Cloud バイブル
Copyright (c) 2025: The Nutanix Cloud Bible and NutanixBible.com, 2025. 本サイトの著者または所有者から書面による許可を受けることなしに、本著作物を無断で使用すること、またはコピーすることを固く禁じます。 本著作物を引用、または本著作物に対するリンクを設定することは許可されますが、 NutanixおよびNutanixBible.comの著作であることを明記し、かつ原著の内容を適切かつ明確に示すよう、該当箇所を提示することを前提とします。
日本語版に関して、誤植や不自然な翻訳など、お気づきの点がございましたら こちらのフォームよりお知らせください。
- 他言語版はこちらからご覧ください。
- For other languages, click the flag icon.
- 다른 언어는 국기 아이콘을 클릭하십시오.
- Для других языков щелкните значок флага.
- 对于其他语言,请单击标记图标。




翻訳版について: Nutanix Cloud バイブルの原著(英語版)は頻繁に更新されるため、日本語版を含む各言語の翻訳版では最新の更新を反映しているとは限りません。 あらかじめご了承ください。 また、同じ理由によりPDFバージョンを提供していません。 ハードコピーを印刷したい場合には、「PDFに変換」などの手段をご利用ください。
The Basics: Compute, Storage and Networking
The Basics
一般的に「Webスケール」の説明に用いられる原則を、Nutanixはスタック全体で活用しています。このセクションでは、これらの基本と、核となるアーキテクチャーの概念について説明します。
Webスケール - ウェブスケール - 名詞 - コンピューターアーキテクチャー
インフラストラクチャーおよびコンピューティングのための
新しいアーキテクチャー
Nutanix は、ソフトウェアスタックを通して「Webスケール」の原則を活用しています。 Webスケールだからといって、GoogleやFacebook、Microsoftのような「超大規模なスケール」になる必要はないということを明言しておきます。 Webスケールな構成はどんな規模でも(3ノードでも、数千ノードでも)適用可能であり、その恩恵を受けることができます。
Webスケールなインフラストラクチャーについて説明するために、いくつか重要な要素があります:
- ハイパーコンバージェンス
- ソフトウェア デファインド インテリジェンス
- 自律分散システム
- インクリメンタルかつリニアな拡張性
その他の要素:
- APIベースの自動化と豊富な分析機能
- セキュリティをコアに据えている
- 自己修復機能
本書では、これらの基礎とアーキテクチャーコンセプト説明します。
Where We Started
Nutanixは、ある一つの目標に焦点を当てて考案されました:
あらゆる場所のインフラストラクチャーコンピューティングを、存在を意識しなくていいくらい簡単(インビジブル)にする。
このシンプルさは、次の3つのコア領域に焦点を当てることで達成されました。
- 選択とポータビリティを可能にする。 (HCI/Cloud/Hypervisor)
- コンバージェンス、抽象化、インテリジェント ソフトウェア(AOS)による「スタック」のシンプル化。
- ユーザーエクスペリエンス(UX)とデザイン(Prism)を重視した、直感的なユーザーインターフェイス(UI)の提供。
HCI/クラウド/ハイパーバイザー:「選択」
私達は、単一のハイパーバイザー(ESXi)をサポートする単一のハードウェア プラットフォーム(NX)からスタートしましたが、常に単一のハイパーバイザー/プラットフォーム/クラウド企業以上の存在であることを認識していました。 これが、vCenter でプラグインではなく独自の UI をゼロから構築したり、カーネル内のネイティブなものではなくVM として実行したり、といった選択をした理由の1つです(他にも多くの理由があります)。 なぜでしょうか? と聞かれるかもしれません。
1つのハイパーバイザー、プラットフォーム、またはクラウドがすべてのお客様のニーズに適合するわけではありません。 同じプラットフォームで複数のハイパーバイザーをサポートすることによって、お客様に選択と活用の自由を与えます。 また、それらの間で移動できるようにすることで、お客様に柔軟性を与えます。 すべてがNutanixプラットフォームの一部であるため、同じ操作体験が提供されます。
現在、12種類以上のハードウェアプラットフォーム(Direct/OEM/サードパーティ)、複数のハイパーバイザー(AHV、ESXi、Hyper-Vなど)をサポートし、主要なクラウドベンダーすべて(AWS、Azure、GCP)とのインテグレーションを拡充しています。 これによりお客様は自分にとって最適なものを選択でき、ベンダーとの交渉目的としても利用できます。
注:プラットフォームとは、このセクション全体、そして一般的に使われている一つのキーワードです。 私たちはワンオフの製品を作ろうとしているのではなく、プラットフォームを構築しているのです。
以下に、Nutanixプラットフォームのアーキテクチャー概要を示します。
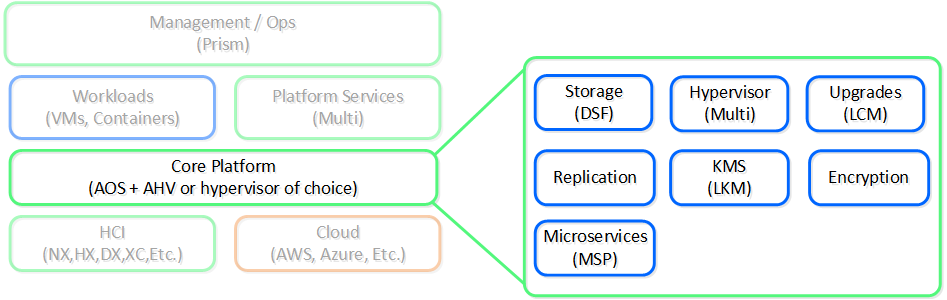
AOS + AHV/ハイパーバイザー:「ランタイム」
私たちは、分散ストレージ ファブリック(DSF。当時はNutanix Distributed Filesystem、別名NDFSとして知られていました)と呼ばれる機能でストレージをシンプル化することからこの旅をはじめて、 それは、ローカルストレージリソースとインテリジェントソフトウェアを組み合わせて「集中型ストレージ」のような機能を提供するものでした。
長年にわたり、私たちは多くの機能を追加してきました。 物事をシンプル化するために、これらは 2 つのコア領域に分割されています:
- コア サービス
- 基礎的なサービス群
- プラットフォーム サービス
- コア サービスをもとにしたサービス群であり、付加的な機能およびサービスを提供する
コア サービスは、ワークロード(VM/コンテナ)や他のよりハイレベルのNutanixサービスの実行を容易にする、基礎的なサービスとコンポーネントを提供します。 当初は単なるDSF製品でしたが、スタックのシンプル化と抽象化を支援するために、プラットフォームの機能を拡張し続けています。
以下に、AOSコア プラットフォームの概観を示します:
何年にもわたって、これは独自のハイパーバイザー(AHV)の導入による仮想化の抽象化(私達は、これは透過的なもので、システムの一部であるべきだと信じています)、アップグレードのシンプル化、セキュリティや暗号化のような他の重要なサービスの提供などにまで拡張してきました。
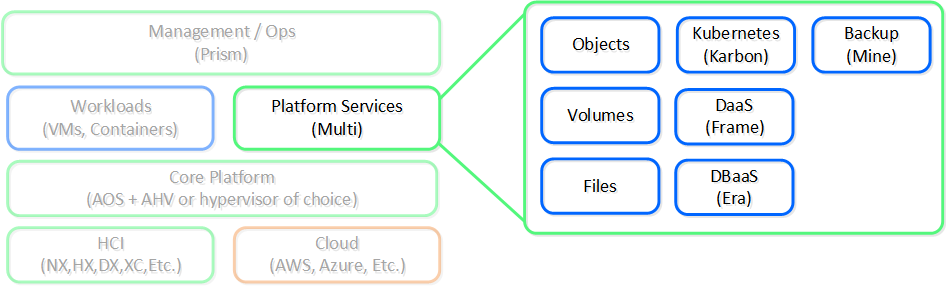
これらの機能により、私達は多くのインフラストラクチャーレベルの問題を解決しましたが、そこで止まりませんでした。 人々はまだ、ファイル共有、オブジェクトストレージ、コンテナのような追加サービスを必要としました。
いくつかのサービスについて、他ベンダーの製品を使用するようにお客様に要求するのではなく、どのサービスでパートナーと提携し、どのサービスを自社で構築するかを考えました。 バックアップについてはVeeamやHYCUなどのベンダーと提携し、ファイルやオブジェクトサービスのような他のサービスについてはプラットフォームサービスとして構築しました。
以下に、Nutanixプラットフォームサービスの概観を示します:
Prism:「インターフェイス」
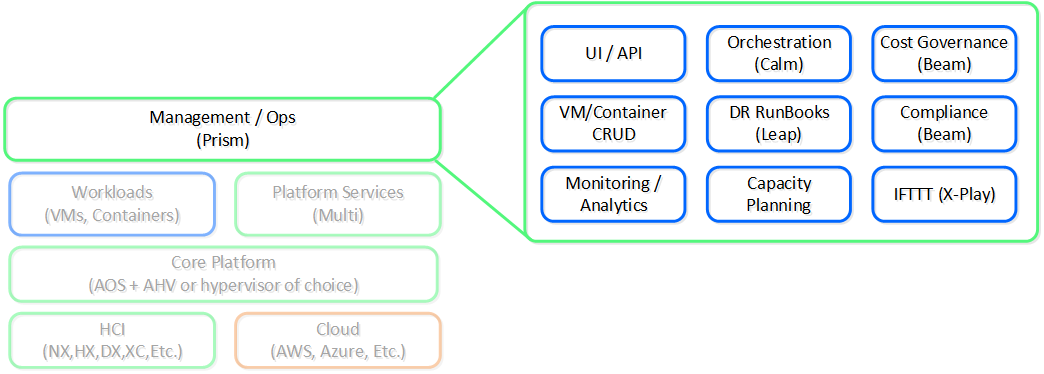
端的にいうと、Appleのような企業が培ってきた、シンプルさ、一貫性、直観性にフォーカスを当てたデザイン原則を適用することです。 当初から、私達はNutanix製品の「フロントエンド」に多大な時間と労力を費やしてきました。 後回しにせず、UI/UXとデザインのチームは、常に限界に挑戦してきました。 例えば、私達は(SaaSプレイヤーを除けば)企業向けソフトウェア企業の中では、管理用UIをHTML5で作成した最初の企業の1つでした。
ここでのもう一つの核となる項目は、プラットフォームに単一のインターフェイスを提供し、その中で一貫した操作体験を維持することに重点を置いていることです。 私達の目標は、インフラストラクチャーを統合したようにUIを統合することです。 私達はPrismを、データセンターでの仮想化の管理、クラウドでのDesktop-as-a-Serviceの管理、または支出の可視性の提供など、 Nutanixプラットフォームの管理と利用ができる単一のインターフェイスとして提供したいと考えています。
これは、機能やサービスの創造と買収を通してプラットフォームを拡張し続ける上で重要なことです。 新しい機能をただ追加するのではなく、それらをプラットフォームにネイティブに統合するために時間を費やしたいと考えています。 その方が時間はかかりますが、長期的には一貫した操作体験を維持し、リスクを軽減することができます。
Nutanix:「プラットフォーム」
要約すると私達のビジョンはシンプルであり、「単一のプラットフォームでアプリとデータを場所を問わず実行可能に」です。

これは当初から私達の目標でした。 その証明として、以下にあるものが2014年頃に作成されたNutanixプラットフォーム アーキテクチャーについて説明するためのイメージ図です。 ご覧のように多くは変わっていませんが、私たちはただ拡大を続け、この目標に向かって努力を続けています。
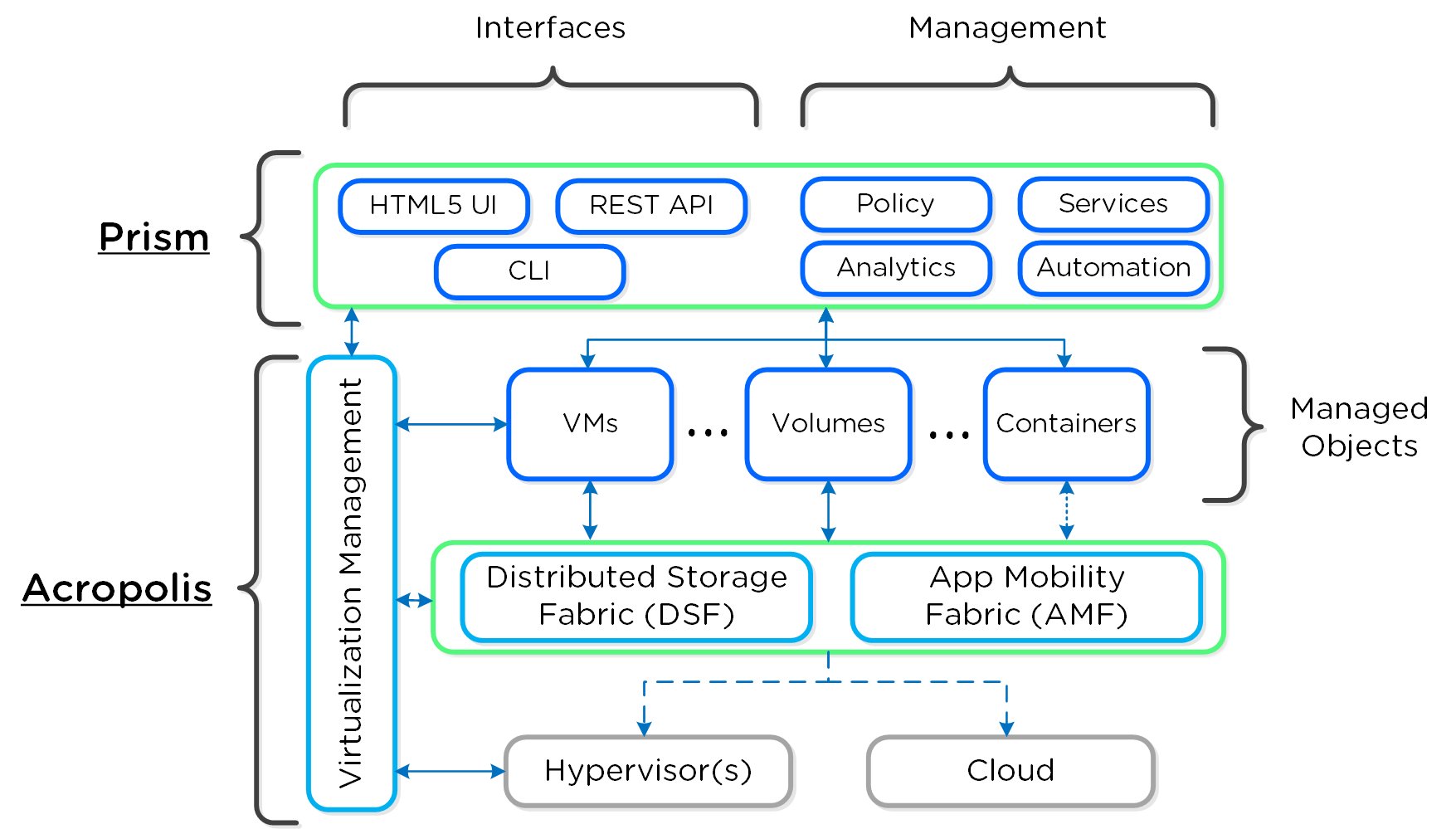
製品とプラットフォーム
製品
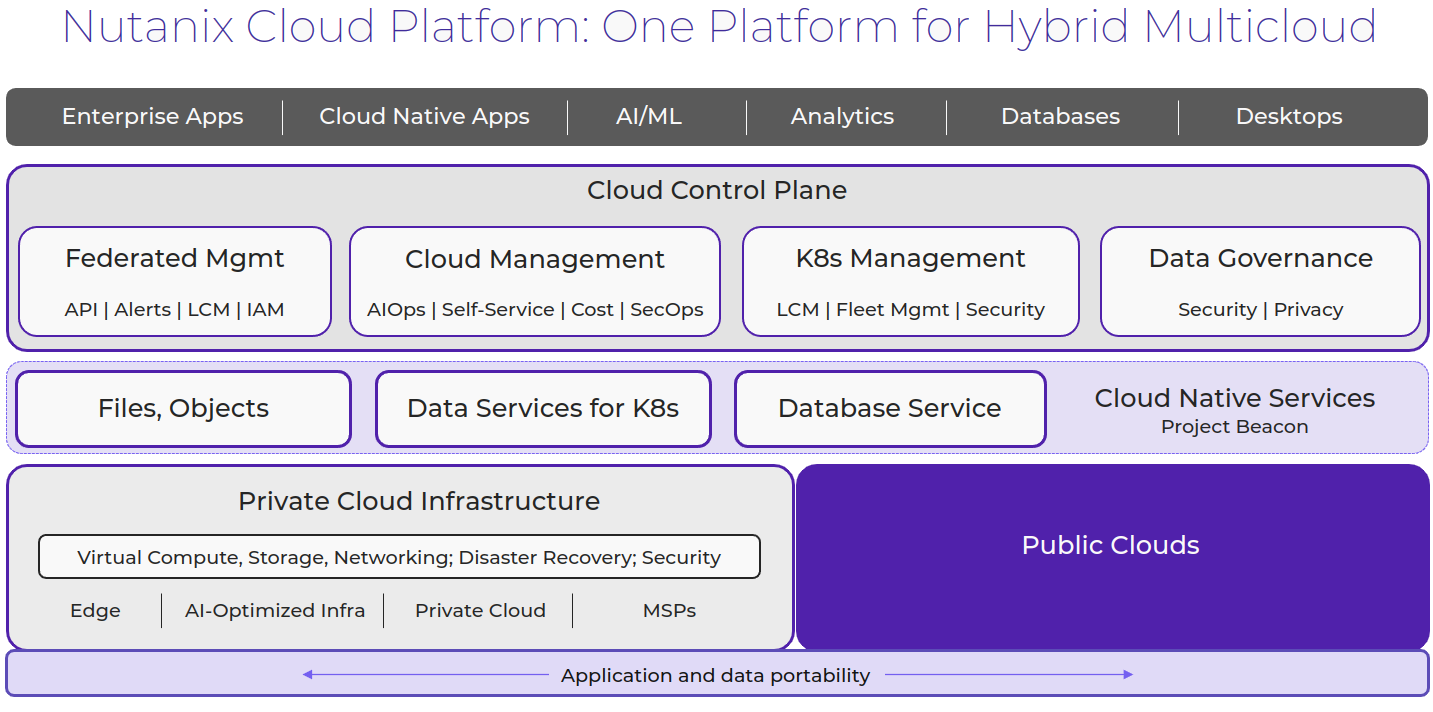
Nutanixは、ハイパーコンバージド インフラストラクチャー(HCI)の先駆者として、コンピューティング、ストレージ、ネットワーキングを単一の使いやすいデータセンター プラットフォームに統合することで従来のサイロを解消しました。 現在、クラウドがITインフラストラクチャーの重要な要素として登場し、Nutanixは再びサイロ(今度はオンプレミス、クラウド、エッジ間の)を打ち破り、ハイブリッド マルチクラウド プラットフォームを提供しています。
Nutanix Cloud Platform
Nutanix Cloud Platformは、ハイブリッドマルチクラウドインフラストラクチャーを構築するための、安全性、弾力性、自己修復を備えているプラットフォームです。 さまざまなコンピュート、ストレージ、ネットワークの要件のあるパブリックおよびプライベートクラウド、複数のハイパーバイザーとコンテナを横断してあらゆる種類のワークロードとユースケースをサポートします。
Nutanixクラウドプラットフォームの構成要素は、NutanixクラウドインフラストラクチャーとNutanixクラウドマネージャーです。 これらはそれぞれの下に位置する製品で、完全なソリューションを形成しています。
Nutanixクラウドインフラストラクチャー(NCI)
- AOSスケールアウトストレージ
- これはNutanix Cloud Platformのコアであり、線形にスケーリングする、分散、高パフォーマンス、回復力のあるストレージプラットフォームを提供します。
- AHVハイパーバイザー
- ネイティブなエンタープライズクラスの仮想化、管理、そして監視の機能は、AHVによって提供されます。 Nutanix Cloud PlatformはESXiとHyper-Vもサポートします。
- 仮想ネットワーキング
- AHVには、標準的なVLANベースの仮想ネットワーキングが搭載されています。 また、Flow Virtual Networkingを有効にすることで、仮想プライベートクラウド(VPC)やその他の高度なネットワーク構成をAHVで提供し、分離、自動化、マルチテナンシーを強化できます。
- ディザスタリカバリ
- シンプルに展開でき管理が容易な、統合されたディザスタリカバリであり、オンプレミスおよびクラウドで柔軟なRPOとRTOの選択肢を提供します。
- コンテナサービス
- Nutanix Cloud Platformは、OpenShiftなどのコンテナサービスにコンピュートとデータを提供し、そしてエンタープライズKubernetesマネージメントソリューション(Nutanix Kubernetes Engine)を提供して、エンドツーエンドの本番利用に対応しているKubernetes環境を提供および管理します。
- データとネットワークのセキュリティ
- 内蔵のローカルキーマネージャーでの暗号化を使用したデータの包括的なセキュリティと、Flow Network Securityでのネットワークとアプリケーションのためのソフトウェアベースのファイアウォールがあります。
Nutanixクラウドマネージャー(NCM)
- AI Operations(NCM インテリジェントオペレーション)
- キャパシティの最適化、プロアクティブなパフォーマンス異常検出、そしてインフラストラクチャー管理を合理化できる運用タスク自動化機能を提供します。
- セルフサービスによるインフラストラクチャーとアプリのライフサイクル管理(NCM Self-Service)
- セルフサービス、自動化、そして集中化されたロールベースのガバナンスによる、ハイブリッドクラウド全体でアプリケーションを管理、展開、および拡張する機能を備えたオーケストレーションです。
- コストガバナンス
- インテリジェントなリソースサイジングと、クラウドメータリングおよびチャージバックへの正確な可視性により、財務説明責任を推進します。
- Security Central
- クラウドセキュリティオペレーションの統合、ワークロード脆弱性の特定、マイクロセグメンテーション管理、ゼロトラストなどの戦略的イニシアチブにおける規制コンプライアンス要件順守のためのセキュリティダッシュボードです。
NCIとNCMに加えて、Nutanix Cloud Platformは次のサービスも提供しています。
Nutanix ユニファイドストレージサービス
- Filesストレージ
- シンプルで安全なソフトウェア定義スケールアウトファイルストレージとその管理
- Objectsストレージ
- シンプルで安全、そしてスケールアウトするS3と互換性のある大規模なオブジェクトストレージ
- Volumesブロックストレージ
- ストレージリソースを仮想化されたゲストOSまたは物理ホストに直接公開できる、エンタープライズクラスのスケールアウトブロックストレージ
Nutanixデータベースサービス
シンプルで自動化された、ハイブリッドクラウド全体でのデータベースライフサイクル管理
デスクトップサービス
あらゆるクラウド上で仮想デスクトップとアプリケーションを大規模に提供します。
Nutanix Cloud Platformは、オンプレミス、Nutanix Cloud Clusters(NC2)を使用したパブリッククラウド、コロケーション、または必要に応じてエッジに展開できます。 ライセンスおよびソフトウェアオプションについては Nutanix.comのNutanix クラウドプラットフォームソフトウェアオプションページ をご確認ください。
プラットフォーム
Nutanixは、さまざまなベンダーのプラットフォームと構成をサポートしています。 プラットフォームは、Nutanixアプライアンス、OEMプラットフォーム、そしてオンプレミスプラットフォーム用のサードパーティサーバーベンダーによるものです。 さらに、NutanixソフトウェアはNC2を備えたパブリッククラウドプラットフォームとサービスプロバイダークラウドでも実行されています。 完全なリストについては Nutanix.comのハードウェアプラットフォームページ をご確認ください。
ハイパーコンバージド プラットフォーム
ビデオによる解説は、こちらからご覧いただけます: LINK
ハイパーコンバージドシステムには、いくつかの核となる構造があります:
- コンピューティングスタックの収束と崩壊が必要(例:コンピュート+ストレージ)
- システム内のノード間でデータとサービスのシャード(分散)が必要
- 集中型ストレージと同等の機能を備えていることが必要(例:HA、ライブマイグレーションなど)
- データを可能な限り実行処理(コンピュート)に近づける必要 (Importance of Latency)
- ハイパーバイザーに依存しない
- ハードウェアに依存しない
以下の図は、典型的な3層スタック対ハイパーコンバージドの例を示しています:
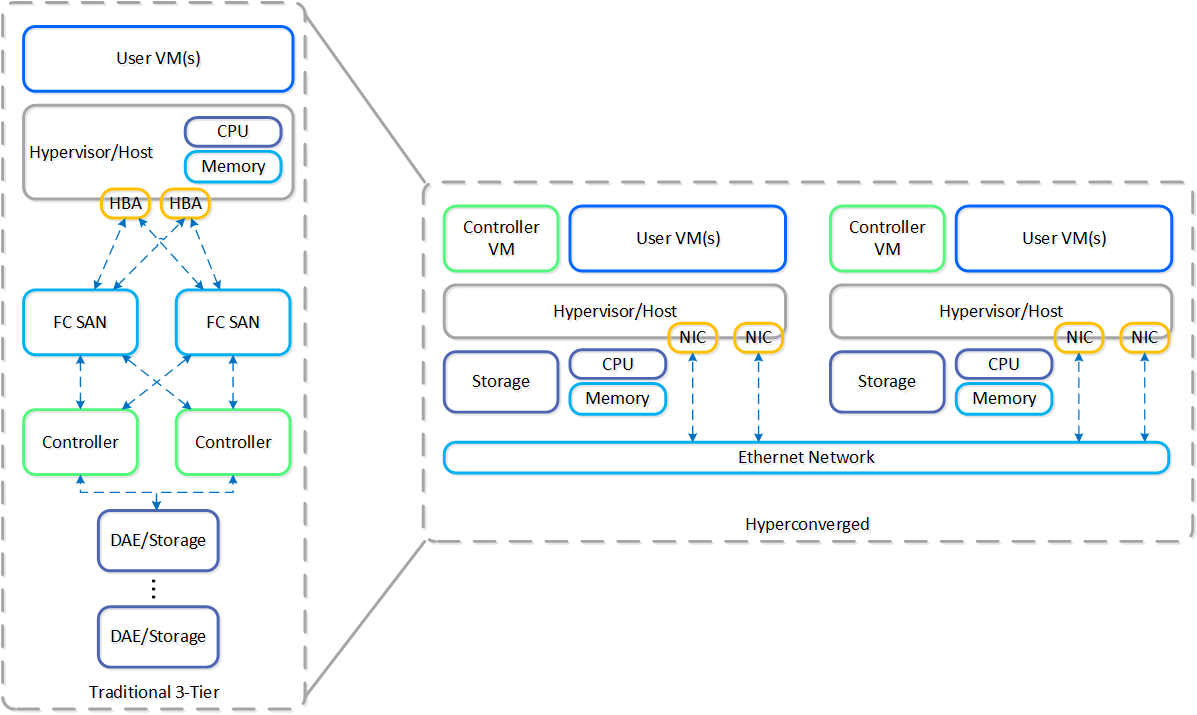
ご覧のように、ハイパーコンバージドシステムは以下のことを行います:
- コントローラーを仮想化してホストに移動する
- コアサービスとロジックをソフトウェアによって提供する
- システム内のすべてのノードにデータを分散(シャード)する
- ストレージをコンピュートのローカルに移動する
Nutanixソリューションは、ローカルコンポーネントを活用してワークロードを実行するための分散プラットフォームを作成する、統合ストレージ+コンピューティングのソリューションです。
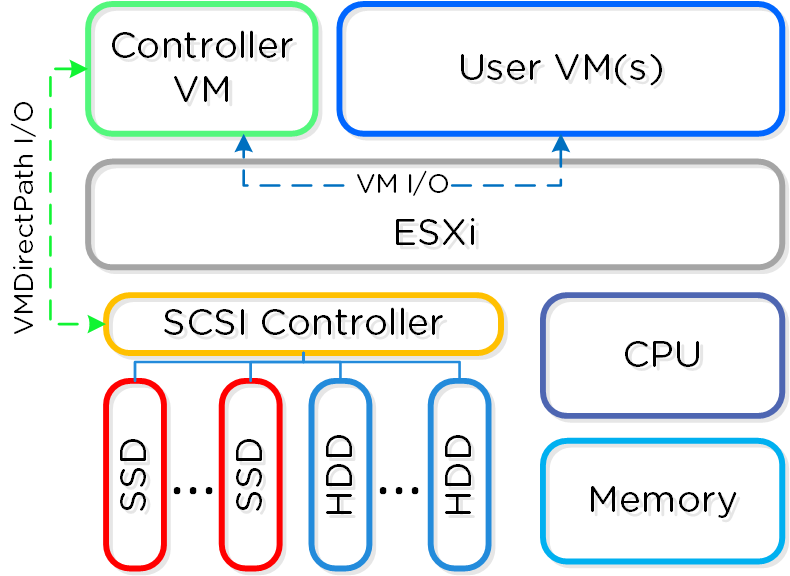
それぞれのノードで、業界の標準的なハイパーバイザー(現在はESXi、AHV、Hyper-V)およびNutanixコントローラーVM(CVM)を稼動させることができます。 Nutanix CVMは、Nutanixソフトウェアを稼動させ、ハイパーバイザーおよびその上で稼動する全てのVMに対するI/O処理の全てを受け持ちます。
以下は、典型的なノードの論理構成例を図示したものです:
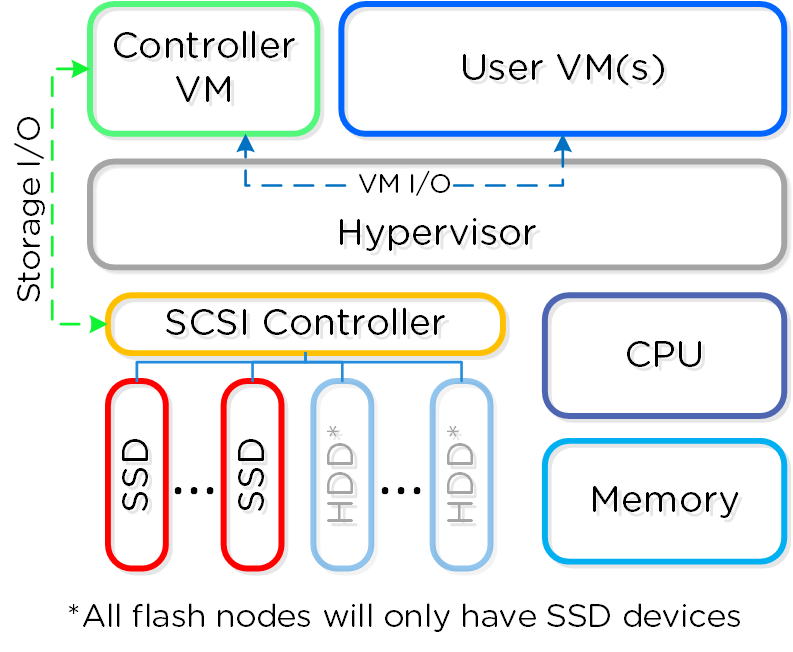
Nutanix CVMは、コアとなるNutanixプラットフォームロジックを担当し、以下のようなサービスを処理します:
- ストレージI/Oと変換(重複排除、圧縮、EC)
- UI / API
- アップグレード
- DR / レプリケーション
- その他
注: 一部のサービスや機能は、追加のヘルパーVMを作成したり、マイクロサービスプラットフォーム(MSP)を使用したりします。 例えば、Nutanix Filesは追加のVMをデプロイしますが、Nutanix ObjectsはMSPのためのVMをデプロイし、それらを活用します。
VMware vSphereが動作するNutanixユニットの場合、SSDやHDDデバイスを管理するSCSIコントローラーが、VM-Direct Path(Intel VT-d)を利用して直接CVMに接続されます。 Hyper-Vの場合は、ストレージデバイスがCVMにパススルー接続されます。
コントローラーの仮想化
Nutanixコントローラーをユーザー空間でのVMとして実行する主な理由は、以下の4領域に分類されます:
- 移動性
- 回復性
- 保守とアップグレード
- パフォーマンス(はい、本当ですよ)
はじめから、私達は単一のプラットフォーム企業ではないことを知っていました。 それ故に、ハードウェア、クラウド、ハイパーバイザーベンダーのいずれであっても、選択肢を持つことは常に私たちにとって重要でした。
ユーザー空間でVMとして実行することで、Nutanixソフトウェアをアンダーレイとなるハイパーバイザーおよびハードウェアプラットフォームから切り離します。 これにより、コアのコードベースをすべての運用環境(オンプレミスおよびクラウド)で同じに保ちながら、他のハイパーバイザーのサポートを迅速に追加できました。 そのうえ、ベンダー固有のリリースサイクルに縛られない柔軟性を提供しました。
ユーザー空間でVMとして実行する性質上、ハイパーバイザーの外部にあるため、アップグレードやCVMの「障害」といったものをエレガントに処理できます。 例えば、CVMがダウンするという破滅的な問題が発生した場合でも、ノード全体が、クラスタ内の他のCVMからのストレージI/Oとサービスで引き続き稼働します。 AOS(NutanixのCoreソフトウェア)のアップグレード中でも、そのホストで実行されているワークロードに影響を与えることなくCVMを再起動できます。
しかし、カーネル内にあるほうがより高速ではないでしょうか? 簡潔に答えると、NOです。
よく議論に上がるのは、カーネル内とユーザー空間のどちらにあるかについてです。 これについては、実際の内容とそれぞれの長所と短所を説明する「ユーザー空間とカーネル空間」のセクションを一読することをお勧めします。
要約すると、オペレーティングシステム(OS)には2つの実行空間があり、それは カーネル(特権のあるOSのコアでドライバーが常駐するような場所)とユーザー空間(アプリケーションやプロセスが常駐する場所)です。 慣例上、ユーザー空間とカーネルの間を移動すること(コンテキストスイッチとして知られる)は、CPUと時間(コンテキストスイッチあたり~1,000ns)の面でコストがかかる可能性があります。
その議論では、カーネルにいることは常にベターで速いということですが、これは誤りです。 何があっても、ゲストVMのOSには常にコンテキストスイッチがあります。
分散システム
分散システムとして不可欠な要素が3つあります:
- 単一障害点 (SPOF) を持たないこと
- 規模に関わりなくボトルネックが発生しないこと(リニアな拡張が可能であること)
- 並列処理を利用していること (MapReduce)
Nutanixの複数のノードから成るグループが、分散システム(Nutanixクラスタ)を形成し、PrismやAOSの機能を提供します。全てのサービスやコンポーネントは、クラスタ内の全てのCVMに分散され、高い可用性やリニアなパフォーマンスの拡張性能を提供します。
以下の図は、NutanixノードがどのようにNutanixクラスタを形成するのかを例示したものです:
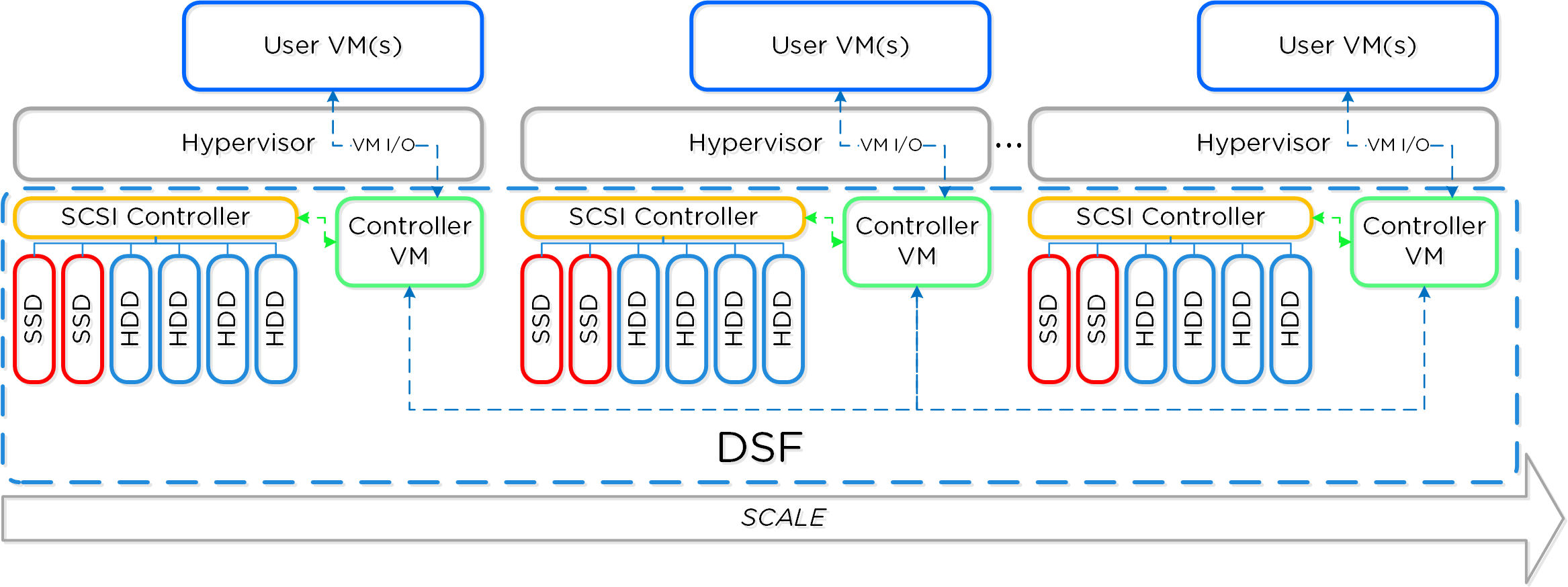
これらのテクニックは、メタデータやデータにも同様に適用されています。全てのノードやディスクデバイスにメタデータやデータを分散することで、通常のデータ投入や再保護を行う際、最大のパフォーマンスが発揮されるようになっています。
これによって、クラスタの能力を最大限に引き出しながら、Nutanixが使用するMapReduceフレームワーク(Curator)が並列処理を行えるようになります。例えば、データの再保護や圧縮、消失訂正号、重複排除といった処理がこれに該当します。
以下の図は、それぞれのノードがどの程度の割合で処理を分担しているのかを示したもので、クラスタの規模が拡大するにつれ、分担割合が劇的に低下していることが分かります:
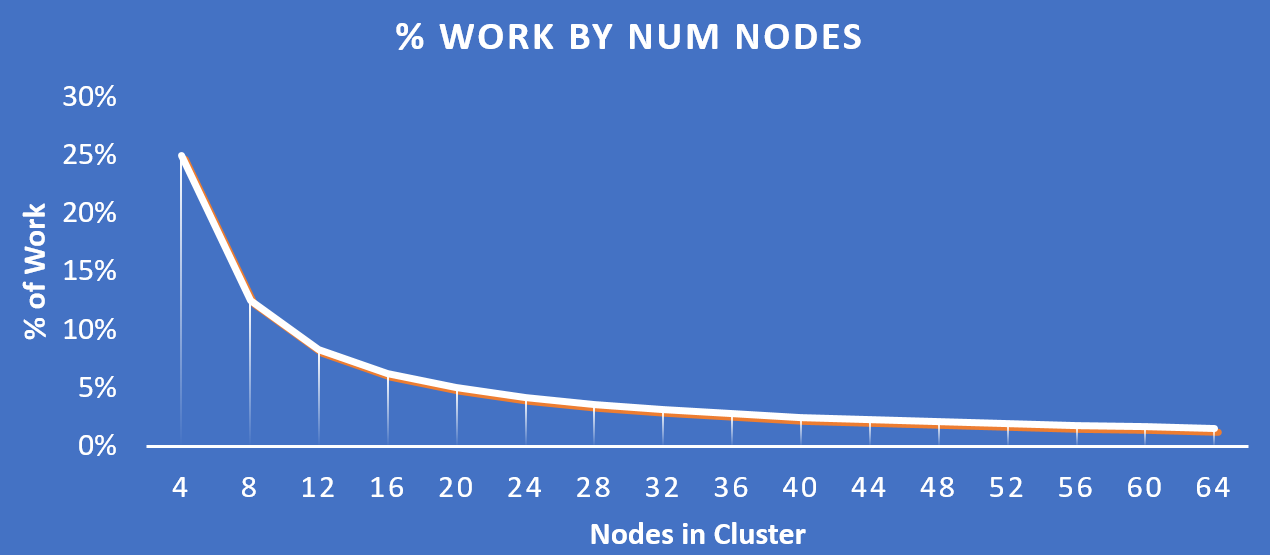
重要な点: クラスタのノード数が増加(クラスタが拡大)すると、各ノードが負担すべき処理の割合が低下し、処理全体としての効率も向上します。
ソフトウェア デファインド
ソフトウェア デファインド システムには、4つの不可欠な要素があります:
- プラットフォーム(ハードウェア、ハードウェア)間のモビリティ(可搬性)を提供できること
- カスタムなハードウェアに依存しないこと
- 迅速な開発(機能開発、バグ修正、セキュリティパッチ)を可能にすること
- ムーアの法則の恩恵を活かせること
既に何度か説明した通り、Nutanixプラットフォームは、ソフトウェアベースのソリューションであり、ソフトウェアとハードウェアをバンドルしたアプライアンスとして出荷されます。 コントローラーVMには、Nutanixソフトウェアとロジックの大半が組み込まれており、当初から拡張性を持つプラガブルなアーキテクチャーとして設計されたものです。ソフトウェア デファインドとしてハードウェアの構成に依存しないメリットは、その拡張性にあります。製品を既に使用中の場合でも、拡張機能や新機能をいつでも取り入れることができます。
Nutanixは、カスタム仕様のASICやFPGA、またはハードウェア機能に依存しないことで、単にソフトウェア アップデートのみで新しい機能を開発・展開することができます。 これは、データ重複排除などの新機能をNutanixソフトウェアのバージョンをアップグレードすることにより展開できることを意味します。 また、レガシーなハードウェア モデルに対しても、新しい機能の導入を可能にします。 例えば、Nutanixソフトウェアの古いバージョンと、前世代のハードウェア プラットフォーム(例えば2400)でワークロードを稼動させていたと仮定します。 稼動中のソフトウェアバージョンでは、データ重複排除機能を提供しないため、ワークロードはその恩恵にあずかることができません。 このデータ重複排除機能は、ワークロードが稼動中であっても、Nutanixソフトウェアのバージョンをローリング アップグレードすることで利用可能です。 これは非常に簡単な作業です。
このような機能と同様に、新しい「アダプター」あるいはインターフェイスをDSFに向け作成できることも、非常に重要な性能です。 製品が出荷された当初、サポートはハイパーバイザーからのI/Oに対するiSCSIに限定されていましたが、現在では、NFSとSMBもその対象になっています。 将来的には、新しいアダプターを様々なワークロードやハイパーバイザー(HDFSなど)に向けて作成できるようになるでしょう。 繰り返しますが、これらの対応は全てソフトウェアのアップデートで完了します。 「最新の機能」を入手するために、ハードウェアを更改したりソフトウェアを購入したりする必要がある多くのレガシーなインフラストラクチャーとは対照的に、Nutanixではその必要がありません。 全ての機能がソフトウェアで実装されているため、ハードウェア プラットフォームやハイパーバイザーを問わずに稼動させることが可能で、ソフトウェア アップグレードによって新たな機能を実装することができます。
以下は、ソフトウェア デファインド コントローラー フレームワークの論理的な構成を図示したものです:
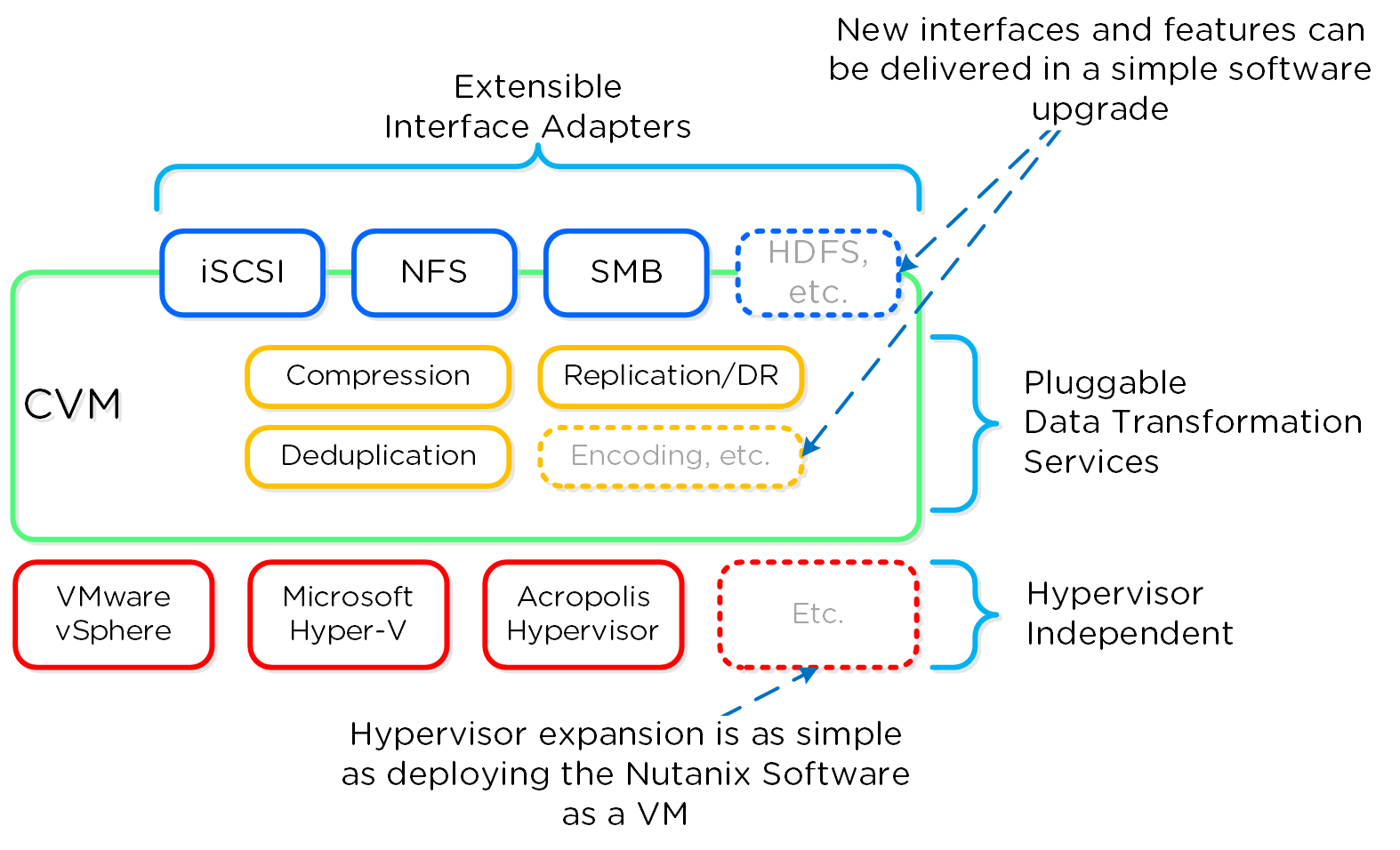
クラスタ コンポーネント
常にユーザーを主眼に置くNutanix製品は、その導入や使用が極めて容易です。 これは基本的に、抽象化や様々な自動化、さらにソフトウェアの連携機能によって実現されています。
以下にNutanix Clusterの主要コンポーネントを示します。(心配は無用です。全部記憶したり、個々の役割を全て理解したりする必要はありません)
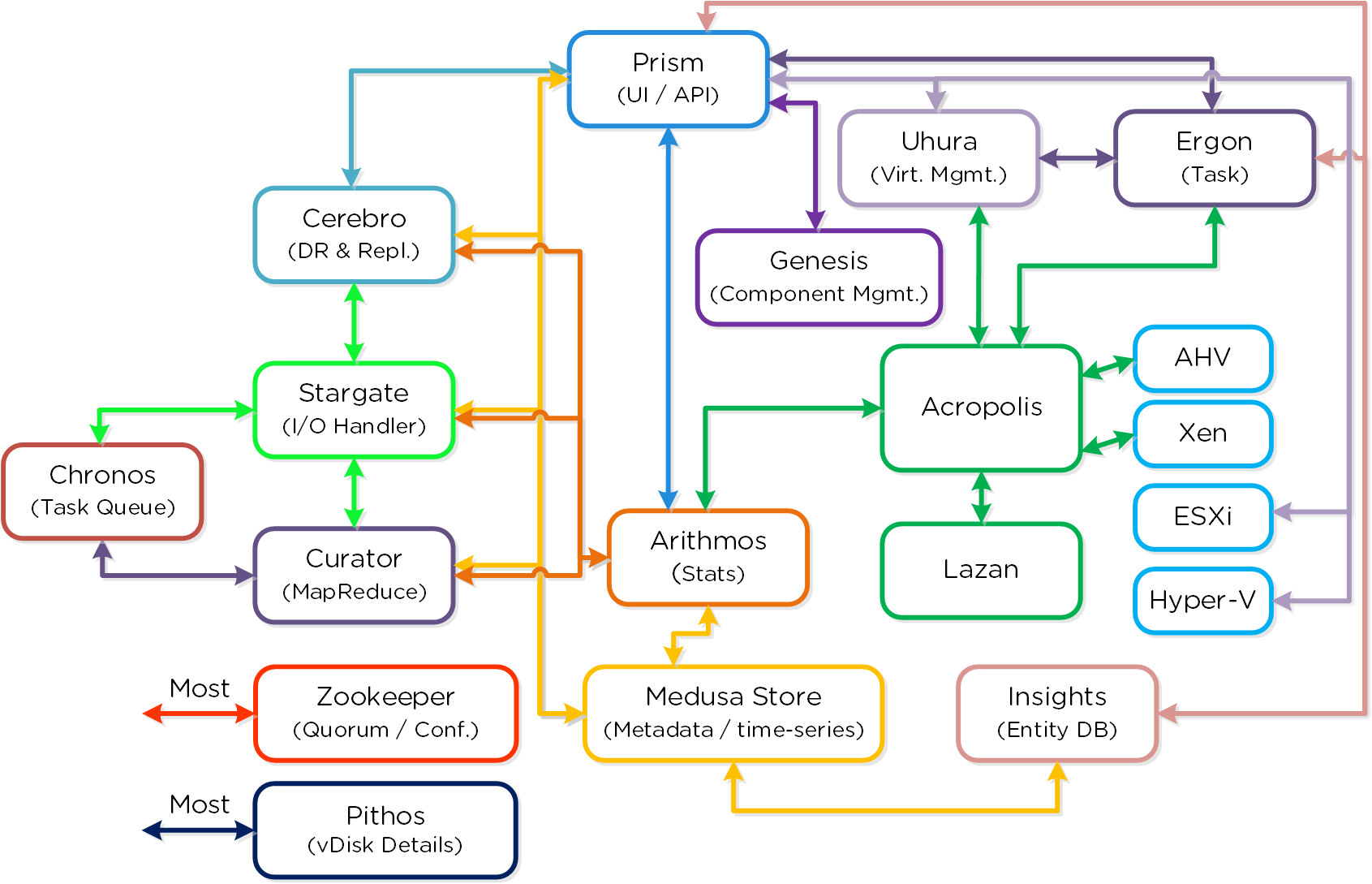
Cassandra
- 主な役割: 分散メタデータ ストア
- 説明: Cassandraは、Apache Cassandraを大幅に改修した分散リング上に全てのクラスタ メタデータをストアして管理を行います。 一貫性を厳格に保つため、Paxosアルゴリズムが使用されています。 そして本サービスは、クラスタ内の全てのノードで稼動します。 Cassandraは、Medusaと呼ばれるインターフェイスを介してアクセスされます。
Zookeeper
- 主な役割: クラスタ構成マネージャー
- 説明: Apache ZookeeperをベースにしたZookeeperは、ホスト、IP、状態など全てのクラスタ構成をストアします。 本サービスは、クラスタ内の3つのノードで稼動し、その内の1つがリーダーとして選出されます。 リーダーが全てのリクエストを受信し残りのサービスに転送します。 リーダーからのレスポンスが無い場合、新しいリーダーが自動的に選択されます。 Zookeeperは、Zeusと呼ばれるインターフェイスを介してアクセスされます。
Stargate
- 主な役割: データI/Oマネージャー
- 説明: Stargateは、全てのデータ管理とI/O処理に対応し、ハイパーバイザーからの主なインターフェイス(NFS、iSCSIまたはSMB経由)となります。 該当サービスはクラスタ内の全てのノードで稼動し、ローカルI/Oを処理します。
Curator
- 主な役割: MapReduceクラスタの管理とクリーンアップ
- 説明: Curatorは、クラスタ全体のディスクのバランシング、事前スクラブといった多くのタスクの管理と分散を行います。 Curatorは全てのノードで稼動し、タスクとジョブの委任を行う選択されたCuratorリーダーによってコントロールされます。 Curatorには、6時間毎に行うフルスキャンと、1時間毎に行う部分スキャンという2つのスキャンタイプがあります。
Prism
- 主な役割: UIおよびAPI
- 説明: Prismは、コンポーネントや管理者が、Nutanixクラスタを構成およびモニターするための管理ゲートウェイとしての役割を果たします。 これにはHTML5 UI, nCLI, REST APIが含まれます。 Prismは、全てのノードで稼動し、クラスタ内の全てのコンポーネントと同様に選出されたリーダーを使用します。
Genesis
- 主な役割: クラスタのコンポーネントおよびサービス マネージャー
- 説明: Genesisは全てのノードで稼動するプロセスで、サービスの初期設定と制御(開始、停止など)を行います。 Genesisは、クラスタから独立して稼動するプロセスで、クラスタの構成や稼動を必要としません。 Zookeeperが稼動していることがGenesisの動作要件になります。 cluster_initおよびcluster_statusページは、Genesisプロセスによって表示されます。
Chronos
- 主な役割: ジョブとタスクのスケジューラー
- 説明: Chronosは、Curatorスキャンされたジョブやタスクをノード間で実行するためのスケジューリングや調整を行います。 Chronosは、全てのノードで稼動し、選出されたChronosリーダーによってコントロールされます。 Chronosリーダーはタスクやジョブを委任し、Curatorリーダーと同じノード上で稼働します。
Cerebro
- 主な役割: レプリケーション/DRマネージャー
- 説明: Cerebroは、DSFのレプリケーションとDR機能を担っています。 これには、スナップショットのスケジューリング、リモートサイトへのレプリケーション、サイトの移行、そしてフェイルオーバー機能が含まれています。 CerebroはNutanixクラスタ内の全てのノードとリモート クラスタ/サイトへのレプリケーションに加わる全てのノードで稼動します。
Pithos
- 主な役割: vDisk構成マネージャー
- 説明: Pithosは、vDisk(DSFファイル)の構成データを担っています。Pithosは全てのノードで稼動し、Cassandraの上に構築されます。
無停止アップグレード
Prismの「Nutanixソフトウェアのアップグレード」および「ハイパーバイザーのアップグレード」セクションで、AOSおよびハイパーバイザーバージョンのアップグレードを実行するために使用される手順を説明しました。 このセクションでは、さまざまなタイプのアップグレードを無停止で実行できるようにする方法について説明します。
AOSのアップグレード
AOSのアップグレードでは、いくつかの核となる手順が実行されます:
1 - アップグレード前のチェック
アップグレード前のチェックでは、以下の項目が確認されます。 注: アップグレードを続行するには、これが正常に完了する必要があります。
- AOSとハイパーバイザーのバージョン互換性を確認する
- クラスタの状態を確認する(クラスタのステータス、空き容量、Medusa、Stargate、Zookeeperなどコンポーネントのチェック)
- すべてのCVMとハイパーバイザー間のネットワーク接続を確認する
2 - アップグレードソフトウェアの2ノードへのアップロード
アップグレード前のチェックが完了すると、システムはアップグレードソフトウェアバイナリをクラスタ内の2ノードにアップロードします。 これは、耐障害性のためであり、1つのCVMが再起動している場合に、他方のCVMからソフトウェアを取得できるようにします。
3 - アップグレードソフトウェアのステージング
ソフトウェアが2つのCVMにアップロードされると、すべてのCVMが並行してアップグレードソフトウェアをステージングします。
CVMには、AOSバージョンのための2つのパーティションがあります:
- アクティブパーティション(現在実行中のバージョン)
- パッシブパーティション(アップグレードがステージングされる場所)
AOSアップグレードは、非アクティブパーティションでアップグレードが実行されます。 アップグレードトークンを受信すると、アップグレードされたパーティションをアクティブパーティションとしてマークし、CVMを再起動してアップグレードされたバージョンにします。 これは、bootbankとaltbootbankに似ています。
注: アップグレードトークンはノード間で反復的に渡されます。 これにより、一度に1つのCVMのみが再起動します。 CVMが再起動して安定すると(サービスの状態と通信を確認して)、すべてのCVMがアップグレードされるまでトークンが次のCVMに渡されます。
アップグレードのエラー処理
よくある質問として、アップグレードが失敗した場合や、プロセスの途中で問題が発生した場合はどうなるか、というものがあります。
アップグレードの問題が発生した場合は、アップグレードを停止して進行しません。 注: アップグレードが実際に開始される前に、アップグレード前のチェックでほとんどの問題が検出されるため、これは非常にまれです。 ただし、アップグレード前のチェックが成功して実際のアップグレード中に問題が発生した場合、クラスタで実行されているワークロードとユーザーのI/Oへの影響はありません。
Nutanixソフトウェアは、サポートされているアップグレードバージョン間の混在モードで無期限に動作するように設計されています。 例えば、クラスタがx.y.fooを実行していて、それをx.y.barにアップグレードしている場合、システムは両方のバージョンのCVMで無期限に実行できます。 これは、実際にアップグレードプロセス中に発生します。
例えば、x.y.fooの4ノードクラスタがあり、x.y.barにアップグレードを開始した場合、最初のノードをアップグレード開始すると、他のノードがx.y.fooである間にx.y.barが実行されます。 このプロセスは続行され、アップグレードトークンを受け取るとCVMはx.y.barで再起動します。
Foundation (イメージング)
Foundationイメージングのアーキテクチャー
Foundation(ファンデーション)は、Nutanixクラスタのブートストラップ、イメージング及び導入のためにNutanixが提供しているツールです。 イメージングプロセスにより、目的とするバージョンに対応するAOSソフトウェアやハイパーバイザーをインストールされます。
Nutanixノードには、デフォルトでAHVがプリインストールされており、異なるハイパーバイザーをインストールするためには、Foundationを使用して、該当ノード上に必要とされるハイパーバイザーを再イメージングする必要があります。
注意: 一部のOEMでは、事前に希望するハイパーバイザーがインストールされた形で出荷を行っています。
以下に、Foundationのアーキテクチャー概要を示します:
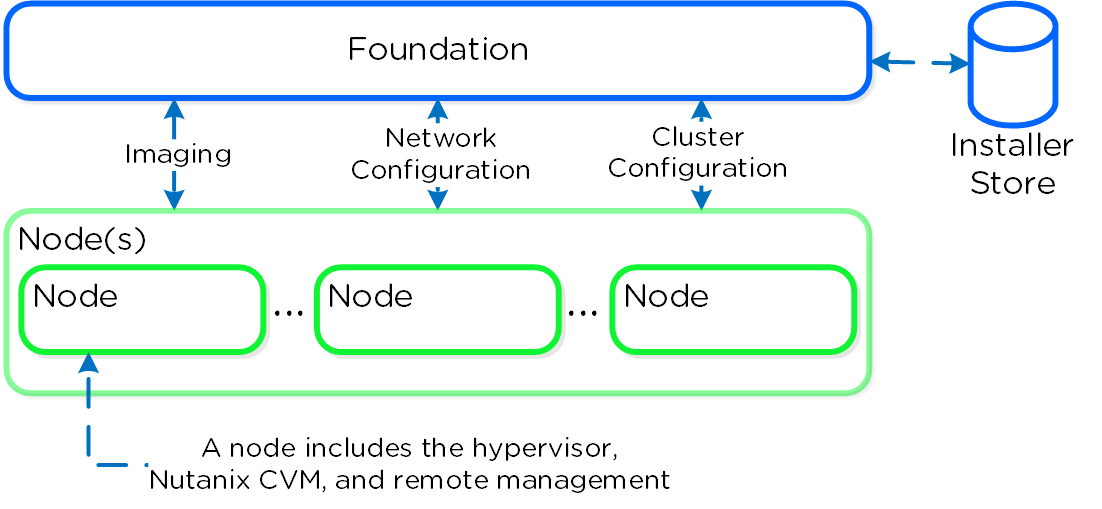
Foundationは、設定を容易にする目的でAOS 4.5からCVMに組み込まれました。 インストーラーの保存領域は、アップロードイメージを格納するためのディレクトリであり、初期のイメージングに加え、イメージングが必要になるクラスタ拡張でも使用されます。
Foundationディスカバリ アプレット(こちらからダウンロードできます)は、ノードをディスカバリしてユーザーが接続するノードを選択できるようにします。 ユーザーが接続ノードを選択すると、アプレットは localhost:9442のIPv4アクセスを、CVMのIPv6リンクローカルアドレスのポート8000にプロキシします。
以下にアプレットアーキテクチャーの概要を示します:
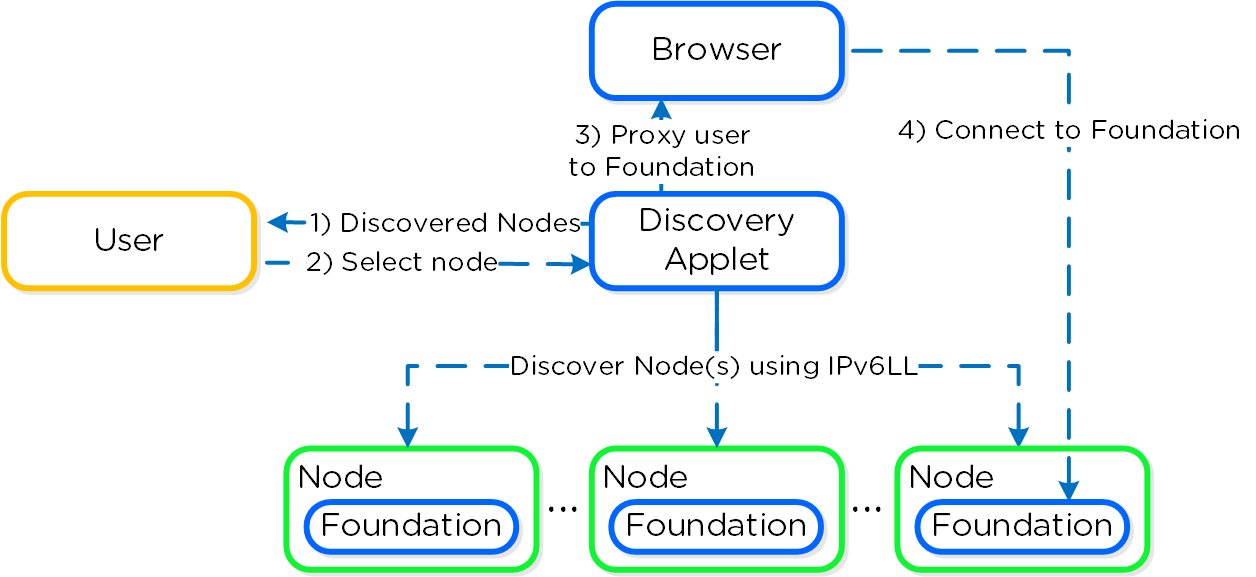
注意: ディスカバリアプレットは、ディスカバリやノード上で稼動するFoundationサービスにプロキシする1つの手段に過ぎません。 実際のイメージングやコンフィグレーションは、Foundationサービスが行うもので、アプレットではありません。
プロからのヒント
ターゲットとなるNutanixノードとは異なる(L2)ネットワークを使用している(WAN経由など)場合はディスカバリアプレットが使用できません。 しかしCVMにIPv4アドレスが割り当てられていれば、(ディスカバリアプレットを使わずに)直接Foundationサービスに接続することができます。
直接接続する際には、 <CVM_IP>:8000/gui/index.htmlをブラウズします
インプット
Foundationには、以下の入力設定があります。 典型的な導入例では、1ノードあたり3つのIP(ハイパーバイザー、CVM、リモート管理(IPMI、iDRACなど))が必要となります。 さらに、各ノードに対し、クラスタとデータサービスIPアドレスを設定することを推奨します。
- クラスタ
- クラスタ名
- IP*
- NTP*
- DNS*
- CVM
- CVM毎のIP
- Netmask
- Gateway
- メモリ
- ハイパーバイザー
- ハイパーバイザーホスト毎のIP
- Netmask
- Gateway
- DNS*
- ホスト名のプリフィックス
- IPMI*
- ノード毎のIP
- Netmask
- Gateway
注意: (*) が付いた項目はオプションですが、設定することを強く推奨します
システムのイメージングと導入
最初に、ディスカバリアプレット経由で、FoundationUIに接続します。(同じL2にあればノードIPの入力などは不要です)
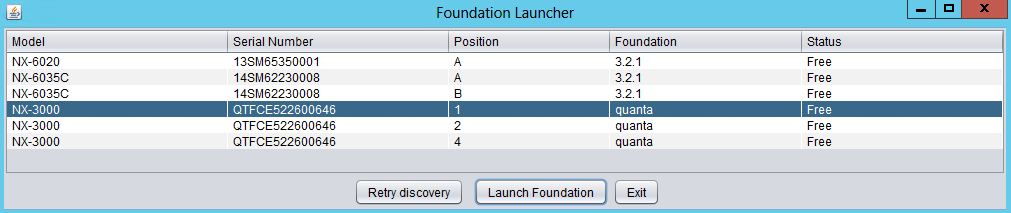
目的とするノードが見つからない場合は、同じL2ネットワーク上に存在するかどうかを確認してください。
選択したノードのFoundationインスタンスに接続すると、FoundationUIが表示されます:
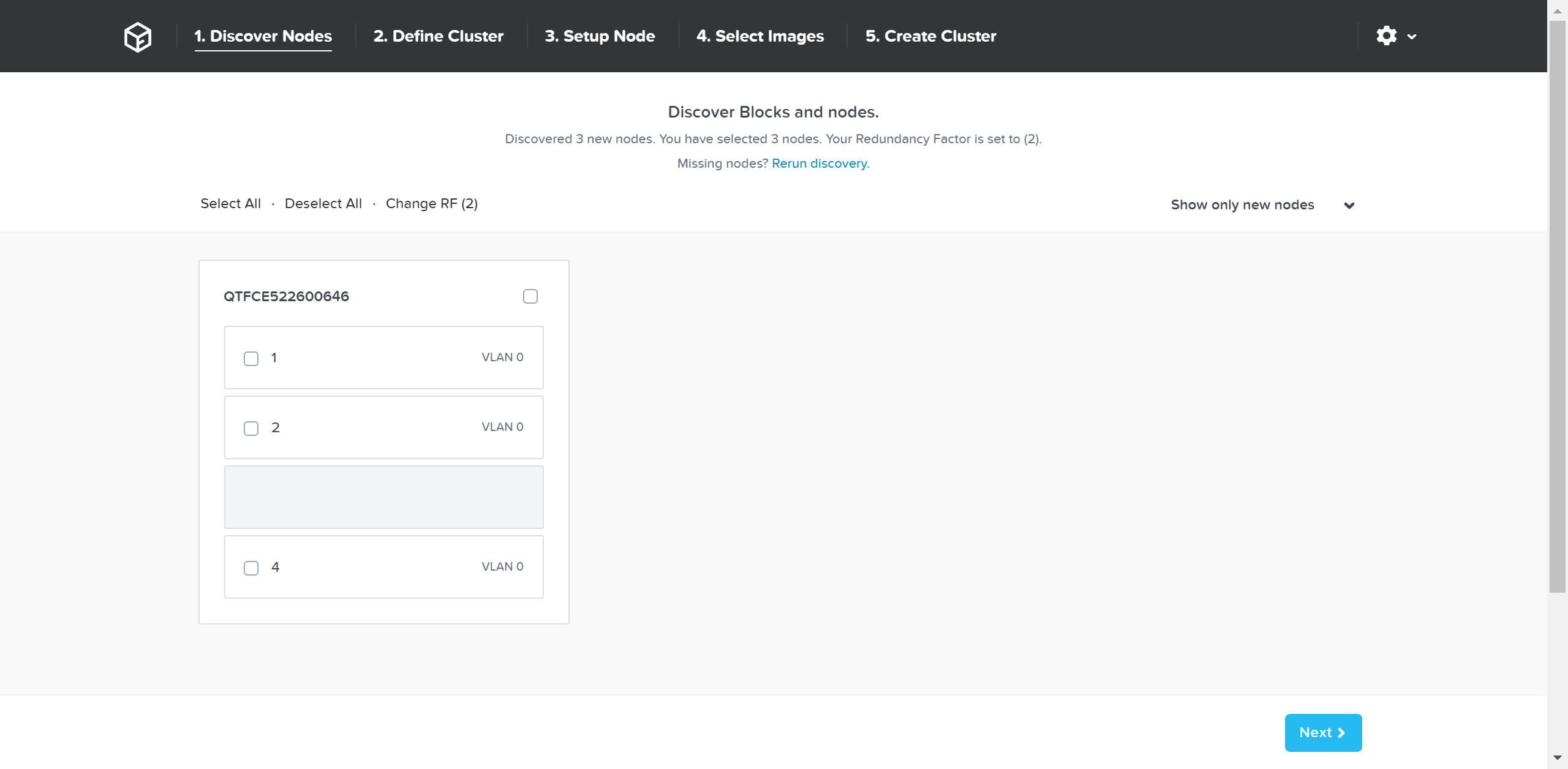
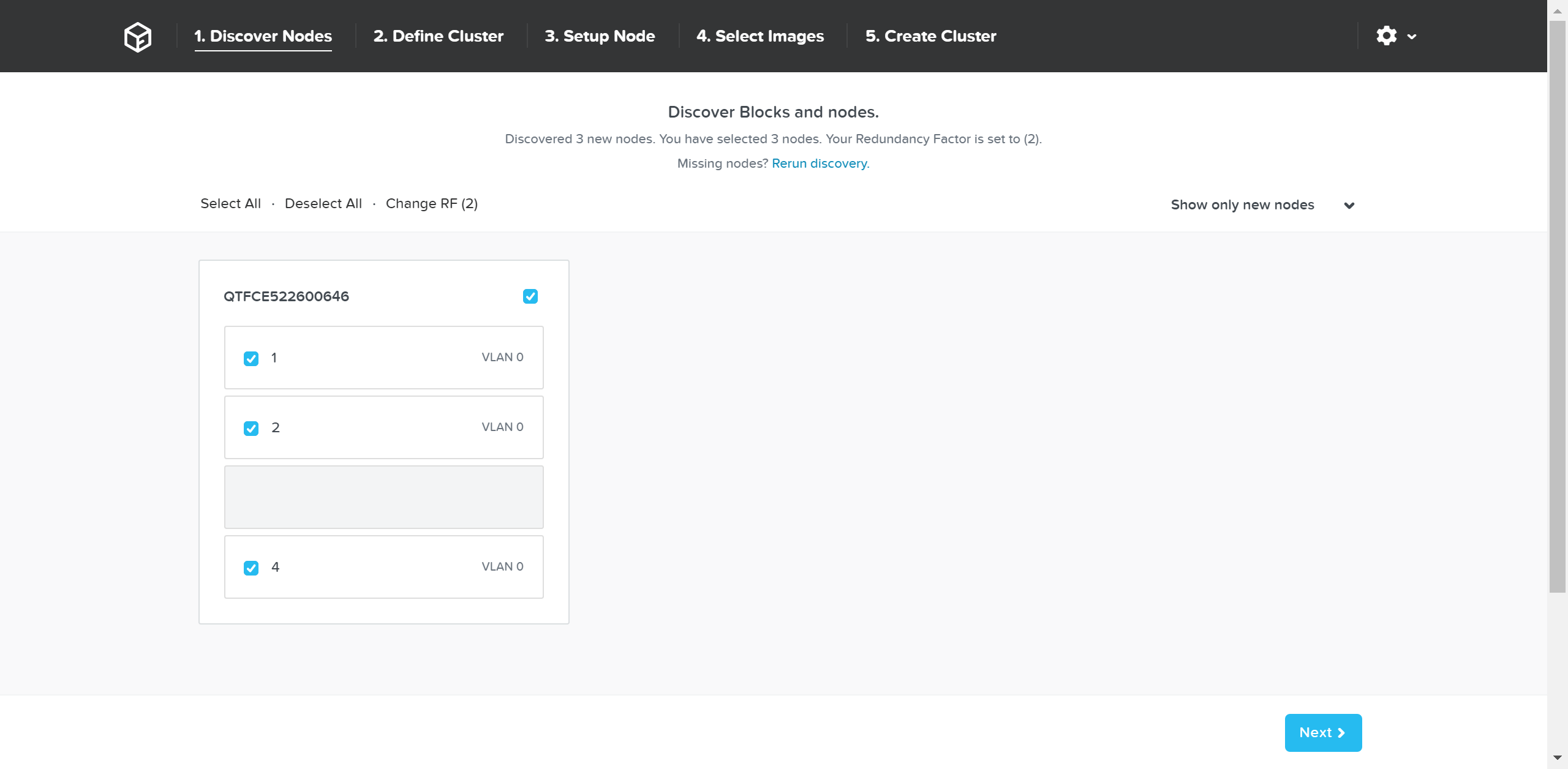
ここでは、検出した全てのノードとシャーシが表示されます。 必要なノードをクラスタから選択し「Next(次へ)」をクリックします。
次のページで、クラスタとネットワーク情報を入力します:
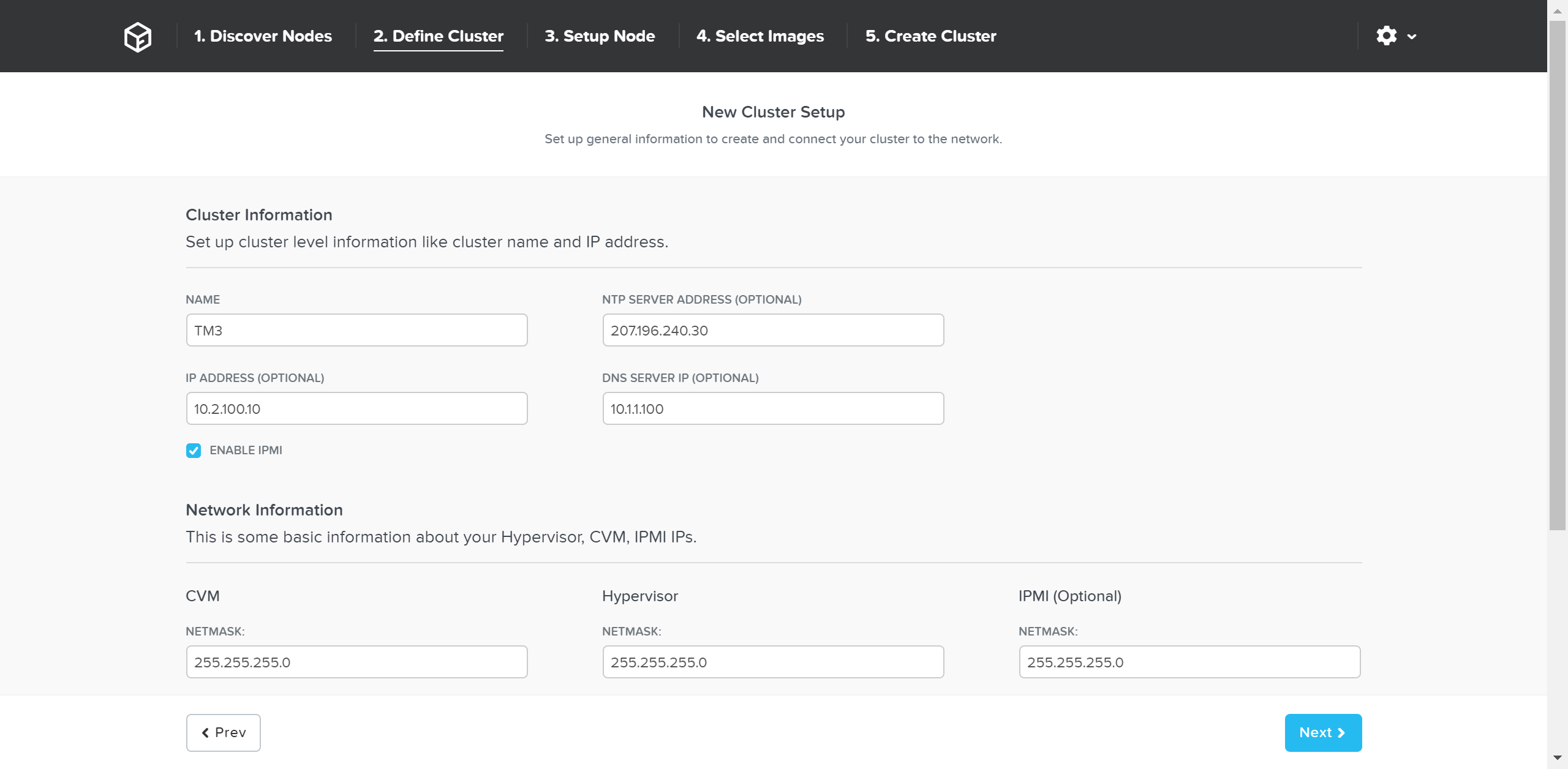
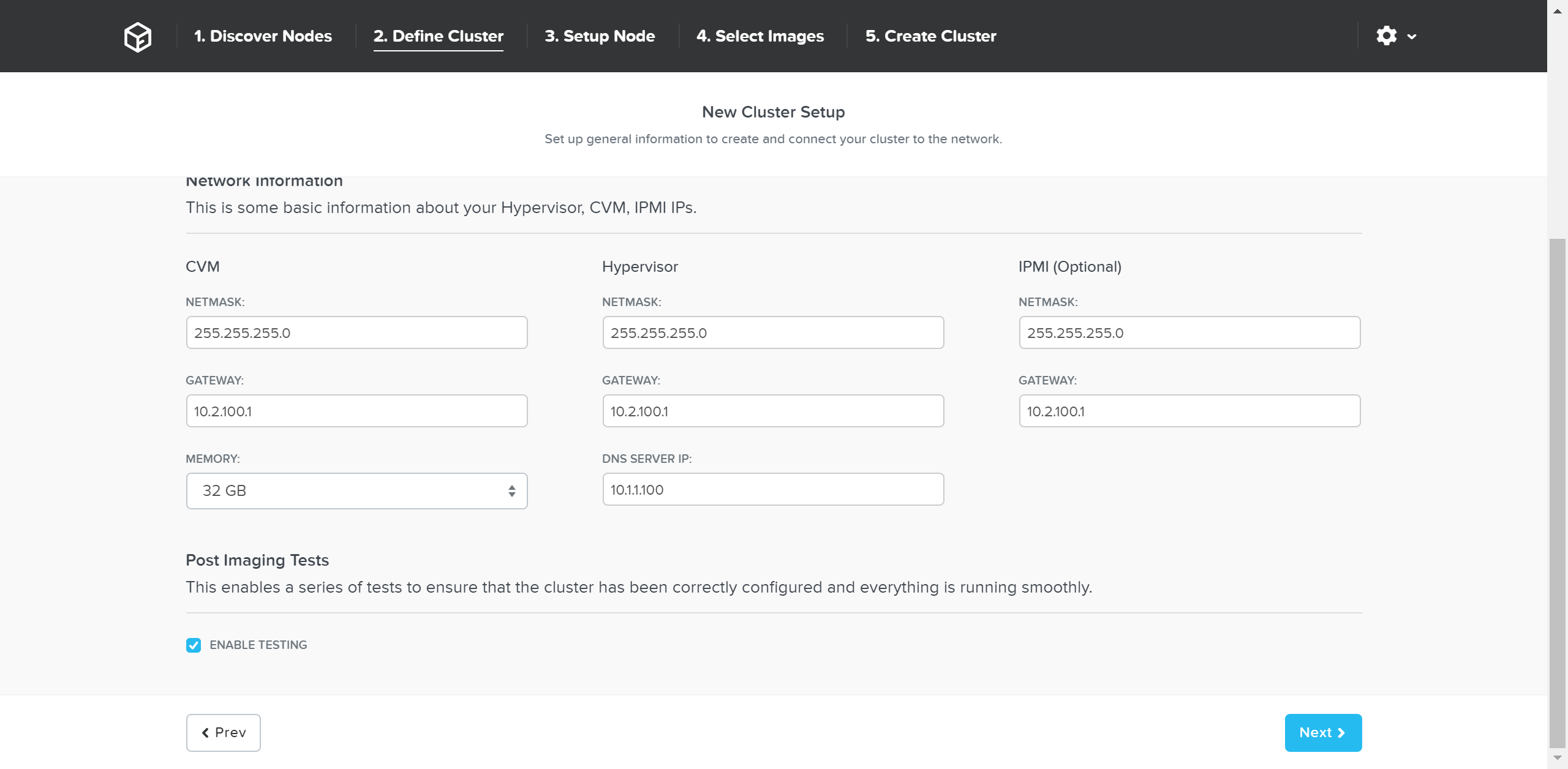
詳細の入力が完了したら「Next(次へ)」をクリックします。
次のページで、ノードの詳細とIPアドレスを入力します:
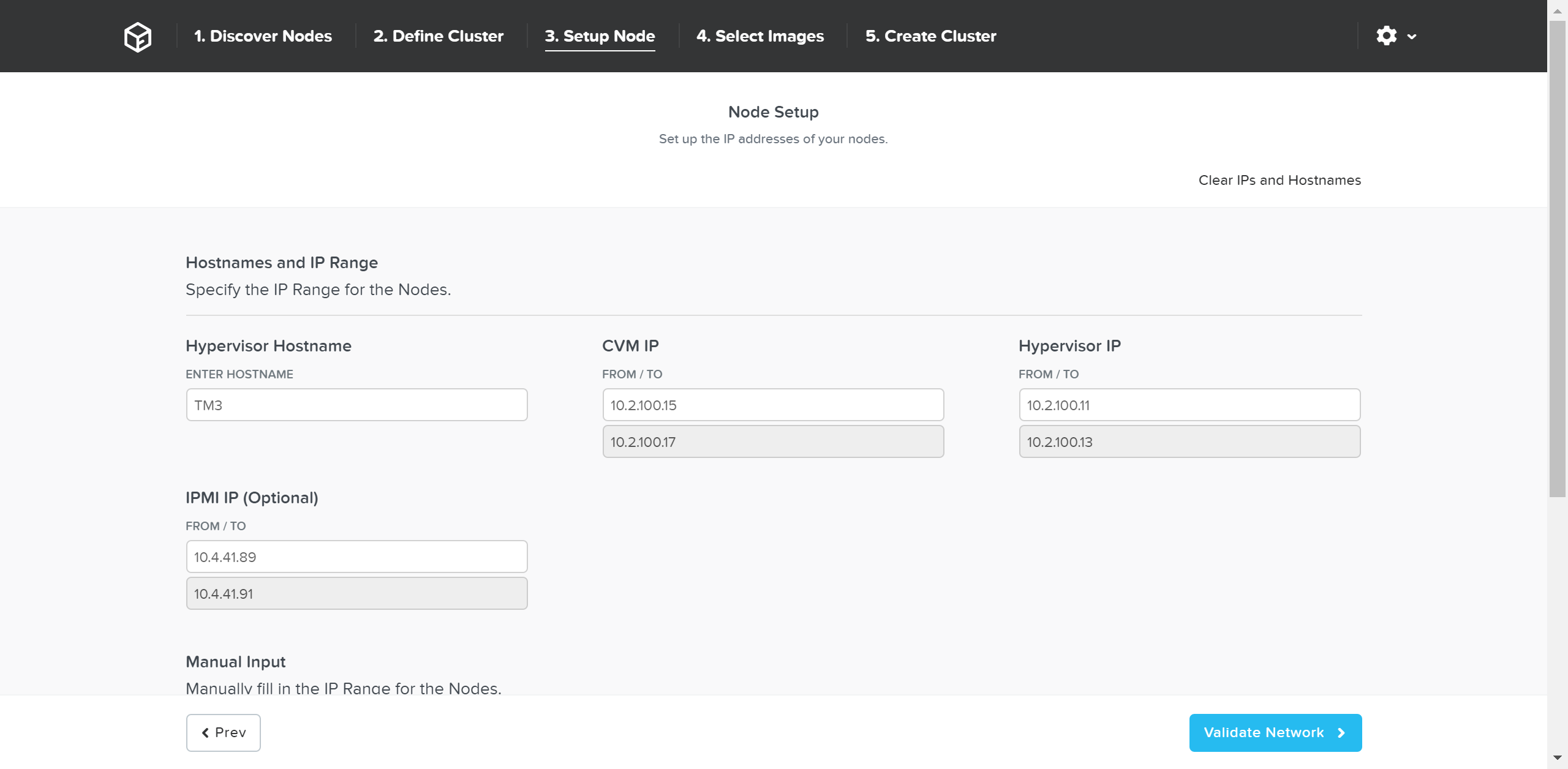
必要に応じてホスト名とIPアドレスを上書きします:
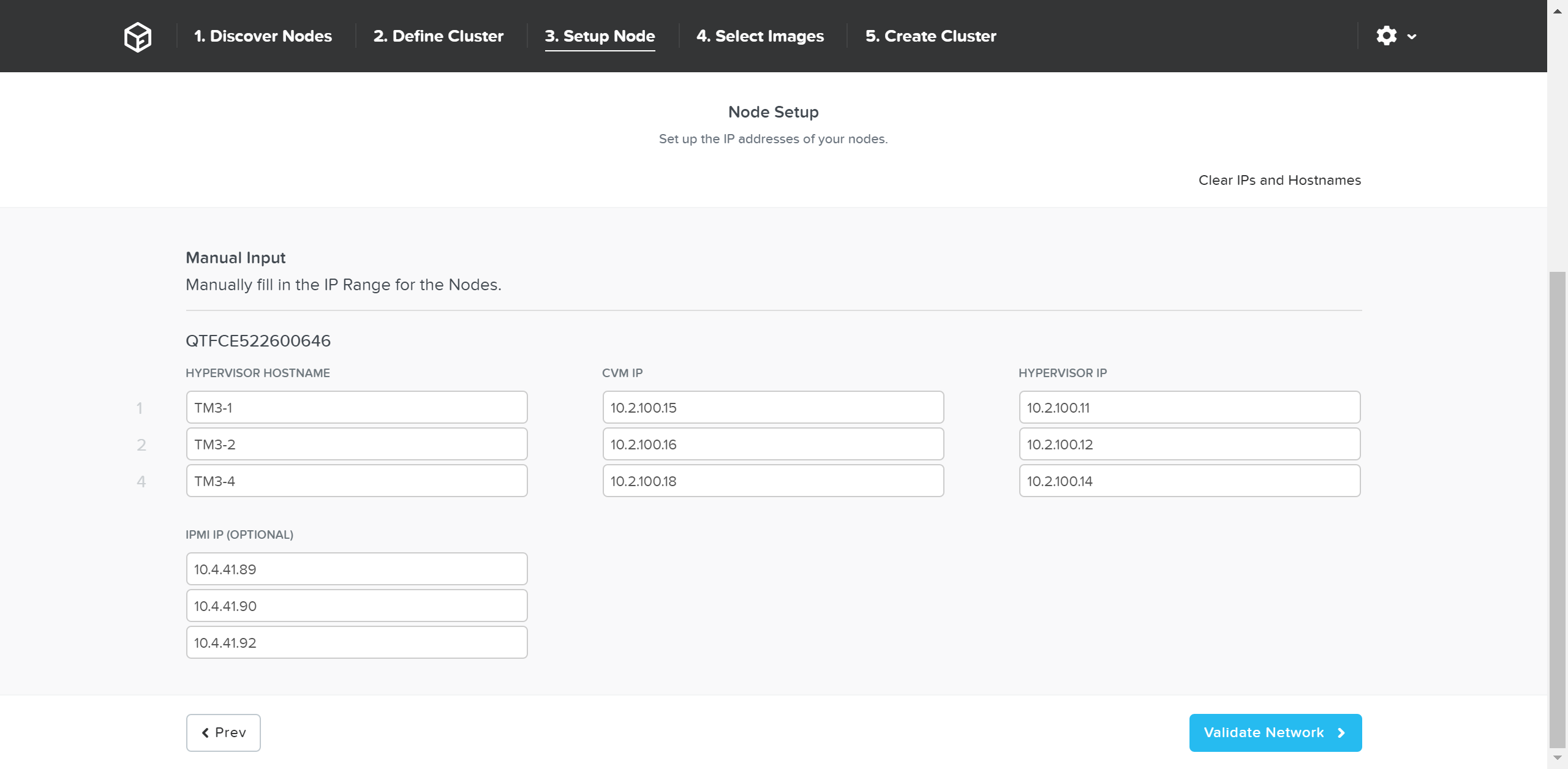
「Validate Network(ネットワークの検証)」をクリックし、ネットワーク設定を確認して次に進みます。 ここでは、IPアドレスに重複がないかを検証し、接続性を確認します。
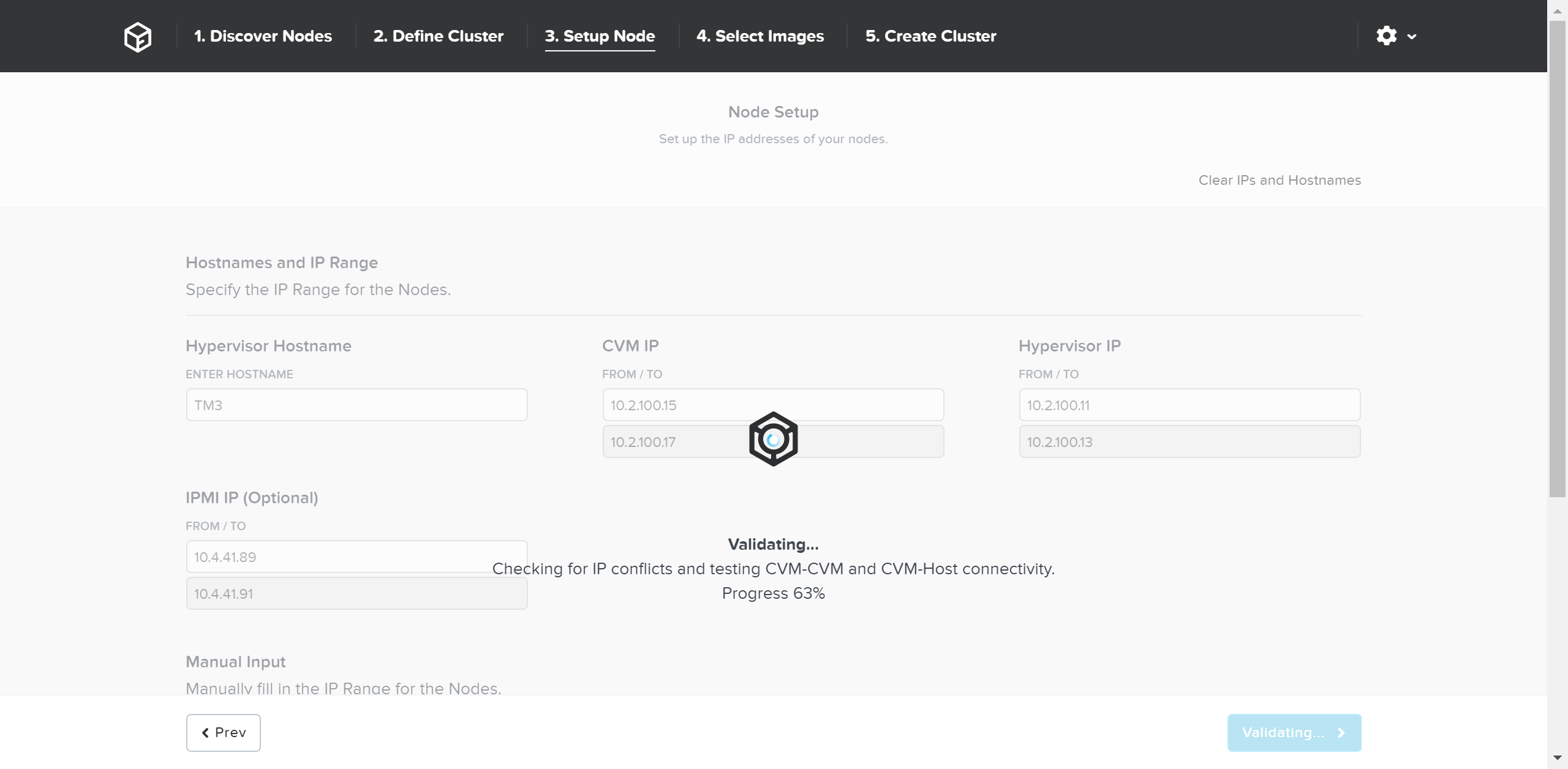
ネットワークの検証が正常に終了したら、次に必要なインストーラーイメージを選択します。
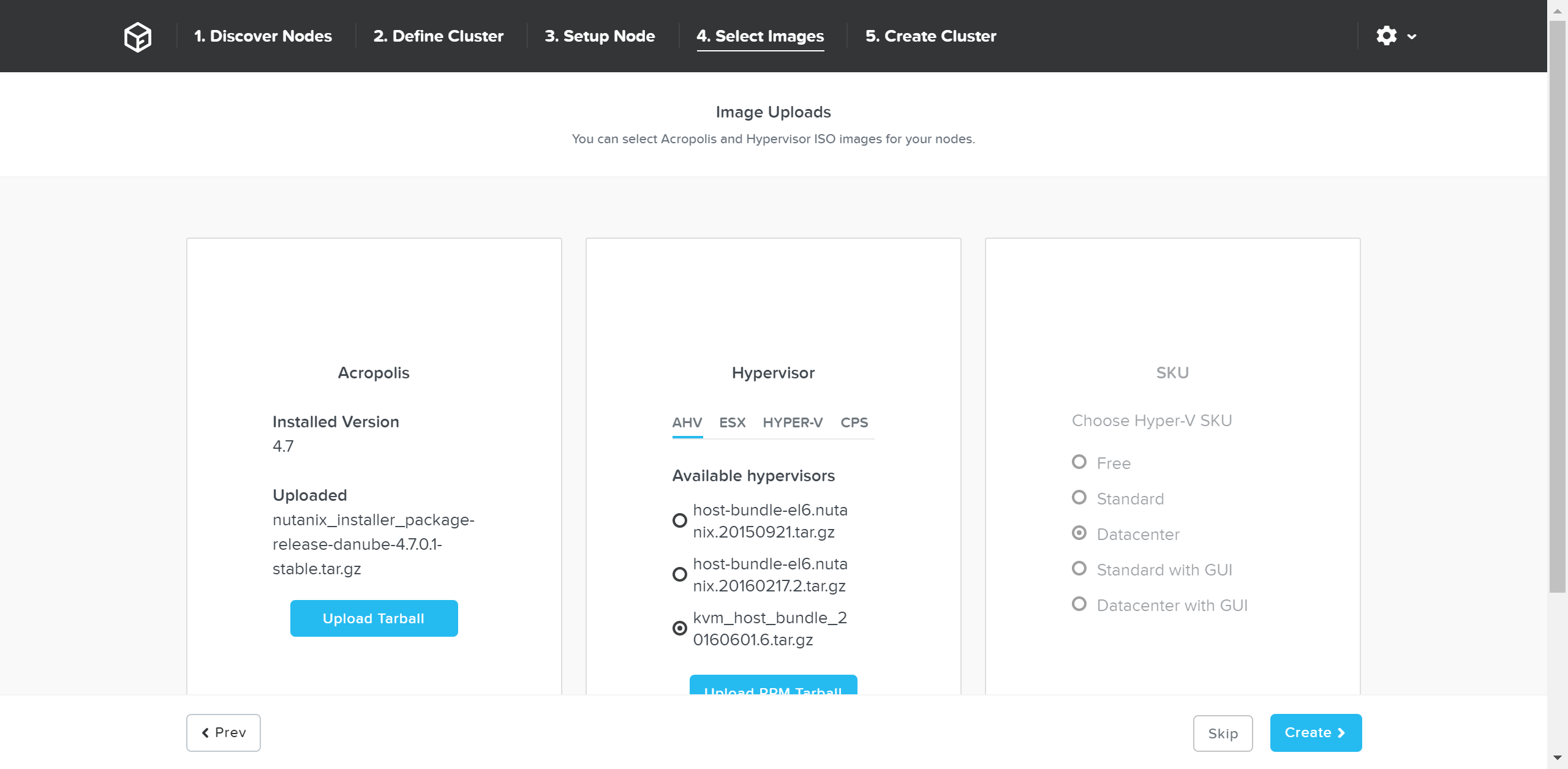
CVM上の現状のAOSを新しいバージョンにアップグレードするためには、ポータルからダウンロードし、tarball(.tar.gz ファイル)をアップロードします。 必要なAOSイメージを入手したらハイパーバイザーを選択します。
AHVの場合、そのイメージはAOSイメージに含まれています。 その他のハイパーバイザーの場合には、必要なハイパーバイザーのインストーラーイメージをアップロードする必要があります。
注意: AOSとハイパーバイザーのバージョンの組み合わせが、互換表 (リンク) に掲載されたものであることを確認してください。
必要なイメージが揃ったら、「Create(作成)」をクリックします:
イメージングが不要な場合、「Skip(スキップ)」をクリックすれば、イメージング工程を省略することができます。これによってハイパーバイザーあるいはNutanixクラスタが再イメージされることはありませんが、クラスタの設定(IPアドレスなど)は必要です。
次にFoundationは(必要に応じて)イメージングを行い、クラスタ作成プロセスに進みます。
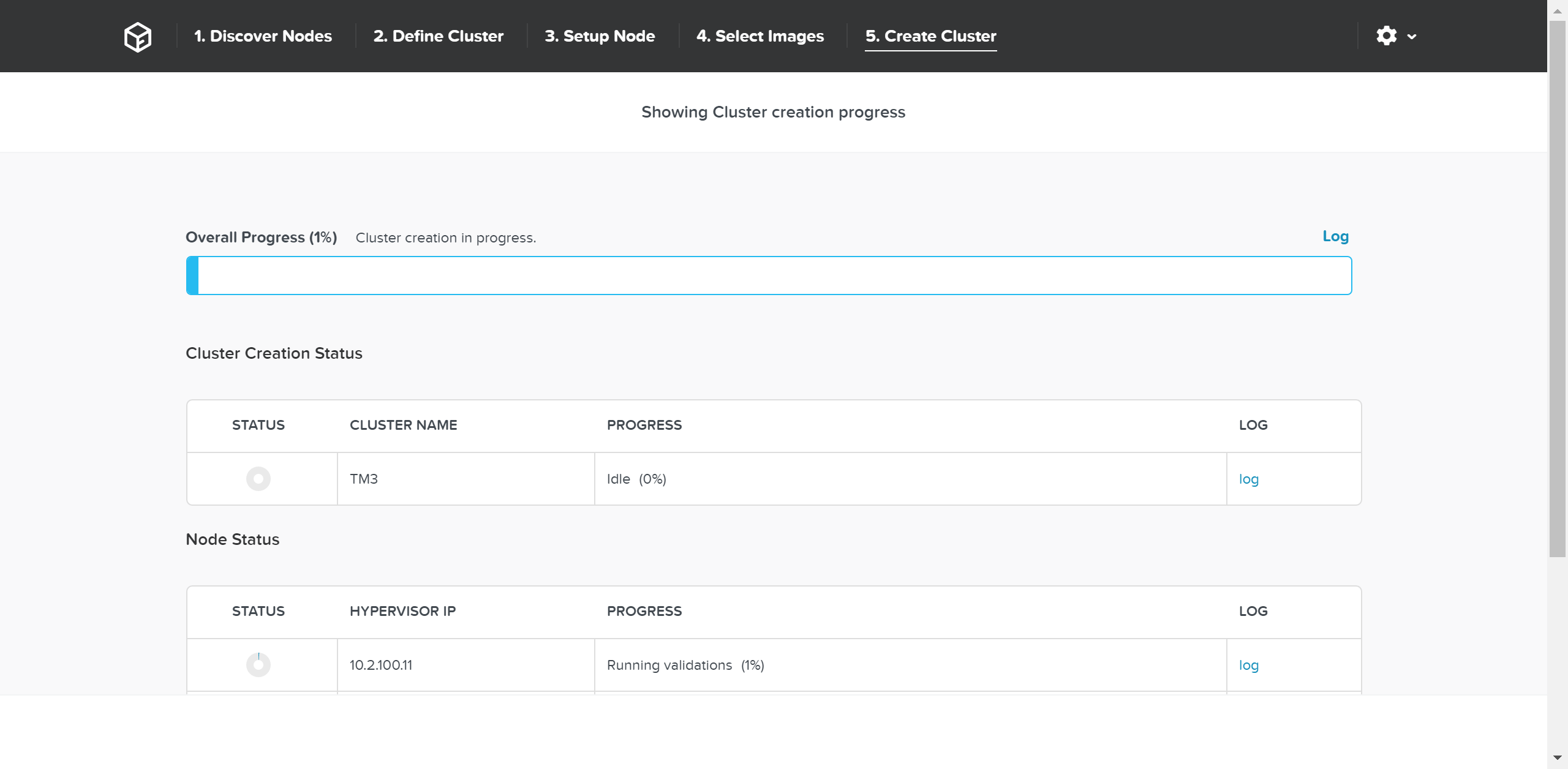
作成が成功すると、完了スクリーンが表示されます:
これでCVMまたはクラスタIPにログインし、Nutanixプラットフォームを利用できるようになりました!
ドライブの分割
本セクションでは、様々なストレージデバイス(パフォーマンス - NVMe/SSD、キャパシティ - SSD/HDD)がどのように分割および、パーティショニングされ、Nutanixプラットフォームで利用されるかを説明します。
注意: 説明で使用されているキャパシティは、10進法のギガバイト (GB) ではなく、すべて2進法のギガバイト (GiB) を使って表現されています。 また、ファイルシステムのためのドライブのフォーマッティングや、関連するオーバーヘッドも考慮に入れた値になっています。
パフォーマンス ディスク デバイス
パフォーマンス ディスク デバイスは、ノードで最もパフォーマンスの高いデバイスです。 これらは、NVMe、またはNVMeとSSDデバイスの混合で構成できます。 重要なものは、以下のように格納されます:
- Nutanix Home(CVMコア)
- メタデータ(Cassandra / AESストレージ)
- OpLog(永続的書き込みバッファ)
- エクステントストア(永続的ストレージ)
以下に示す図は、Nutanixノードのパフォーマンスデバイスの分割例です:
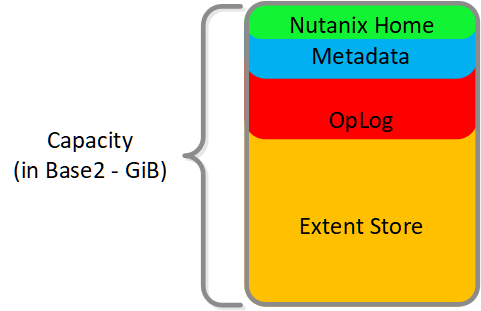
図の大きさは、実際の値の大きさと一致しているわけではありません。 残りの(Remaining)GiBキャパシティは、上から下方向に数値を計算していった残りで見積ります。 例えば、OpLogで使用可能な残りのGiBを計算する場合は、フォーマット済みSSDのキャパシティから、Nutanix HomeとCassandraのキャパシティを差し引いた値になります。
Nutanix Homeは可用性確保のため最初の2つのSSDにミラーされ、そして2つのデバイスに60GiBを予約します。
AOS 5.0の場合、Cassandraは、各ノードのSSD間(現在、最大4つまで)で、1つのSSDあたり15GiBの初期予約領域(メタデータの容量が増加した場合、一部のStargate SSDを使用可能)と一緒に共有されます。 デュアルSSDシステムの場合、メタデータはSSD間でミラーされます。 SSDあたりのメタデータ予約領域は15GiBとなります(デュアルSSDは30GiB、4つ以上のSSDの場合は60GiB)。
AOS 5.0より前は、Cassandraはデフォルトで最初のSSDにあり、そのSSDに障害発生した場合はCVMが再起動されてCassandraストレージは2番目にあるものになります。 この場合のSSDあたりのメタデータ予約は、最初の2つのデバイスでは30 GiBです。
OpLogはすべてのSSDデバイスに分散され、1ノードあたり最大12までとなります (Gflag: max_ssds_for_oplog)。 NVMe デバイスが使用可能な場合、OpLogはSATA SSDではなくそちら(NVMe デバイス)に配置されます。
ディスクあたりのOpLog予約は、次の式を使用して計算できます:
- MIN(((Max cluster RF/2)*400 GiB)/ numDevForOplog), ((Max cluster RF/2)*25%) x Remaining GiB)
注意: リリース 4.0.1から、OpLogのサイズが動的に決定されるようになり、エクステントストアも動的に拡張されるようになりました。 ここで示す値は、OpLogが完全に使用されている状況を前提としています。
例えば、1TBのSSDデバイスが8つあるRF2(FT1)クラスタの結果は次のようになります:
- MIN(((2/2)*400 GiB)/ 8), ((2/2)*25%) x ~900GiB) == MIN(50, 225) == デバイスごとにOplogのために50GiB予約
RF3(FT2)クラスタでは下記のようになります:
- MIN(((3/2)*400 GiB)/ 8), ((3/2)*25%) x ~900GiB) == MIN(75, 337) == デバイスごとにOplogのために75GiB予約
1TBの4つのNVMeデバイスと8つのSSDデバイスによるRF2(FT1)クラスタの場合、結果は下記のようになります:
- MIN(((2/2)*400 GiB)/ 4), ((2/2)*25%) x ~900GiB) == MIN(100, 225) == デバイスごとにOplogのために100GiB予約
エクステントストアの容量は、他のすべての予約が計算された後の残り容量になります。
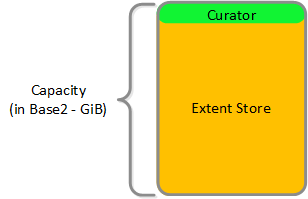
HDDデバイス
HDDデバイスは、基本的に大容量ストレージとして利用されるため、その分割はよりシンプルになります:
- Curator予約領域(Curatorストレージ)
- エクステントストア(永続的ストレージ)
Compute
AHV
AHVはNutanixのネイティブハイパーバイザーであり、CentOS KVMを基盤としています。 その基本機能を拡張し、HA、ライブマイグレーション、IPアドレス管理などの機能を追加しています。
AHVはMicrosoft Server Virtualization Validation Programの一環として認証されており、MicrosoftのOSやアプリケーションの実行が認証されています。
本書では、AHVのアーキテクチャーと機能について説明します。
チャプター
- AHVのアーキテクチャー
- Nutanix AHVの動作の仕組み
- AHVのアドミニストレーション
AHVのアーキテクチャー
AHVのノード アーキテクチャー
AHVを導入した場合、コントローラーVM(CVM)はひとつのVMとして稼動し、ディスクはPCIパススルーを使用するようになります。 これにより、PCIコントローラー(および付属デバイス)のパススルーが完全に実現され、ハイパーバイザーを迂回してCVMに直接繋がるようになります。 AHVは、CentOS KVMをベースに構築されています。 ゲストVM (HVM) に対しては、完全なハードウェアの仮想化を使用します。
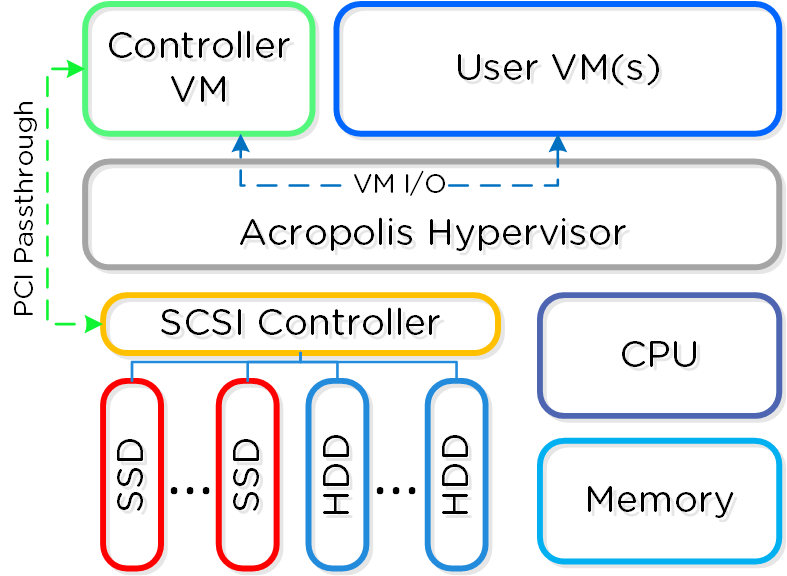
AHVは、CentOS KVMをベースに基本機能を拡張し、HAやライブ マイグレーションなどの機能を組み込んだものです。
AHVは、Microsoft Server Virtualization Validation Programの認定を受け、またMicrosoft OS やアプリケーションの稼動検証を受けています。
KVMアーキテクチャー
KVMの主要なコンポーネントは、以下に示す通りです:
- KVM-kmod
- KVMのカーネルモジュール
- Libvirtd
- KVMとQEMUを管理するためのAPI、デーモン、管理ツールです。AOSとKVM/QEMUはlibvirtdを経由して通信します
- Qemu-kvm
- 全ての仮想マシン(ドメイン)上で稼動するマシンエミュレータおよびバーチャライザです。AHV内で本コンポーネントは、ハードウェア アシステッドな仮想化に利用され、VMはHVMとして稼動します
以下に各コンポーネントの関連を示します:
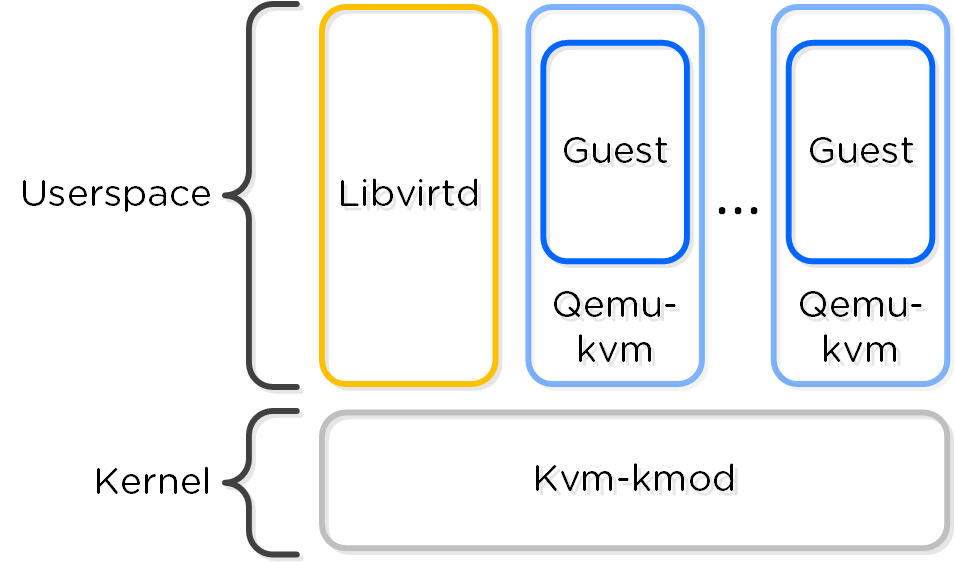
AOSとKVM/QEMUは、libvirtdを経由して通信します。
プロセッサ世代間の互換性
異なるプロセッサ世代間でVMを移動できるVMwareのEnhanced vMotion Capability (EVC) と同様に、AHVでは、クラスタ内の最も古いプロセッサの世代を特定し、全てのQEMUドメインをそのレベルで取扱います。これによって、AHVクラスタ内に異なる世代のプロセッサが混在している場合でも、ホスト間のライブマイグレーションが可能となります。
AHVの最大構成と拡張性
以下の最大構成と拡張制限が適用されます:
- 最大クラスタサイズ: 32
- VMあたりの最大vCPU数: 関連するAHVバージョンの Configuration Maximums ページを確認してください。
- VMあたりの最大メモリ: 4.5TBまたは使用可能な物理ノードメモリ
- 最大仮想ディスクサイズ: 64TB
- ホストあたりの最大VM数: 関連するAHVバージョンの Configuration Maximums ページを確認してください。
- クラスタあたりの最大VM数: 関連するAHVバージョンの Configuration Maximums ページを確認してください。
※64TBの最大仮想ディスクサイズは、Nutanixエンジニアリングによって内部的にテストされているサイズです。
上記はAHV 20230302.100173とAOS 6.8のものです。 他のバージョンについてはConfiguration Maximumsを参照してください。
コンピュート
ここからのセクションでは、ワークロード管理のためのNutanix AHVコンピューティングにおける主要機能の概要を説明します。
仮想マシンテンプレート
AHVには、簡単にクローンできるように単一vDiskのデータキャプチャにフォーカスしたイメージライブラリを常に持っていましたが、CPU、メモリ、そしてネットワークの詳細を設定するプロセスを完了するには、管理者からの入力が必要でした。 仮想マシンテンプレートは、この概念を次のレベルのシンプルなものにして、他のハイパーバイザーでテンプレートを利用したことがある管理者に馴染みのある仕組みを提供します。
AHVの仮想マシンテンプレートは既存の仮想マシンから作成され、CPU、メモリ、vDisk、そしてネットワークの詳細など、定義する仮想マシンの属性を受け継ぎます。 テンプレートは、展開時にゲストOSをカスタマイズするように構成でき、オプションとしてWindowsライセンスキーを提供できます。 テンプレートでは複数のバージョンを維持できるため、新しいテンプレートを作成する必要なく、オペレーティングシステムやアプリケーションパッチなどの更新を簡単に適用できます。 管理者はどのテンプレートのバージョンがアクティブか選択できるため、更新を事前にステージングしたり、必要に応じて以前のバージョンに戻すことができます。
メモリオーバーコミット
仮想化の主な利点の1つは、コンピューティングリソースをオーバーコミットできることであり、これにより、サーバーホスト上に物理的に存在するよりも多くのCPUを仮想マシンにプロビジョニングできます。 ほとんどのワークロードは、割り当てられたすべてのCPUを100%必要とはしないため、ハイパーバイザーは、CPUサイクルを必要とするワークロードに各時点で動的に割り当てることができます。
CPUまたはネットワークリソースと同様に、メモリもオーバーコミットできます。 どの時点でも、ホスト上の仮想マシンでは、割り当てられたすべてのメモリを使用している場合も使用していない場合もあり、ハイパーバイザーは未使用のメモリを他のワークロードと共有できます。 メモリのオーバーコミットによって、未使用のメモリを組み合わせて必要とする仮想マシンに割り当てることで、管理者は各ホストにより多くの仮想マシンをプロビジョニングできるようになります。
AOS 6.1では、追加のメモリと仮想マシン密度が必要なテストや開発のような環境で、管理者が柔軟に対応できるようにするオプションとしてメモリオーバーコミットをAHVにもたらします。 オーバーコミットはデフォルトで無効になっており、仮想マシン単位で定義できるため、クラスタ上の仮想マシンのすべてまたはサブセットのみで共有できます。
VMアフィニティポリシー
異なる種類のアプリケーションには、仮想マシンを同じホストで実行する必要があるか、または別のホストで実行する必要があるかを指示する要件があります。 これは通常、パフォーマンスもしくは可用性の利点のために行われます。 アフィニティ制御により、仮想マシンがどこで実行されるかを管理できるようになります。 AHVには、2種類のアフィニティ制御があります:
- 仮想マシン-ホスト アフィニティ
- 仮想マシンをホストまたはホストのグループに厳密に結び付けると、仮想マシンはそのホストまたはグループでのみで実行されます。 アフィニティは、ソフトウェアライセンスまたは仮想マシンアプライアンスが関係するユースケースで特に適用できます。 このようなケースでは、多くの場合でアプリケーションを実行できるホスト台数を制限したり、仮想アプライアンスを単一のホストに縛り付けしたりする必要があります。
- アンチアフィニティ
- AHVでは、与えられたリストの仮想マシンを同じホスト上で実行しないように宣言できます。 アンチアフィニティは、クラスタ化された仮想マシンまたは分散アプリケーションを実行している仮想マシンを異なるホスト上で実行するメカニズムを提供し、アプリケーションの可用性と復元力を向上させます。 仮想マシンの分離配置よりも仮想マシンの可用性を優先するため、クラスタが制約された際には、システムはこのタイプのルールを無効化します。
仮想Trusted Platform Module(vTPM)
TPMテクノロジーは、暗号化処理を扱う際のセキュリティとプライバシーを強化するように設計されています。 TPMの目的は、情報ストレージを不正アクセスから確実に保護することです。 主な用途はシークレットの保存であり、適切な承認なしにシークレットにアクセスすることを困難にします。
Trusted Computing Groupでは、TPMをコンピューターのマザーボードに半田付けされた専用ハードウェアチップとして概説しており、これはベアメタル デプロイメントで効果的に機能します。 AHVやESXiなどのハイパーバイザーを使用する仮想化環境では、物理TPMチップのアプローチは、次の制限により、単一のハードウェア構成で実行される複数のゲストOSをサポートするように拡張できません。
- キー ストレージ - 物理TPMチップで利用可能なストレージには、おおよそ3つの一時キーを保存できます。
- TPMでの隔離 - TPMチップは、同一物理デバイス上で実行される複数のゲストOS間の分離や、隔離を提供しません。
仮想化環境でのスケーリングの問題に対処するために、ハイパーバイザー ベンダーは仮想TPM(vTPM)と呼ばれるハイパーバイザー レベルのソフトウェアを実装しており、これはTrusted Computing GroupのTPM仕様に準拠しています。 vTPMは、ハイパーバイザー上の仮想マシン ゲストごとにプライベートTPMインスタンスを作成して、物理TPMチップと同様の機能でこれらのTPM仕様をエミュレートします。 vTPMを使用すると、それぞれの仮想マシン ゲストが独自のキー ストレージを持つことができ、同じ物理サーバー上で実行されている他のゲストから隔離されます。 この隔離を維持するために、vTPMはサーバー上のハードウェア物理TPMチップを使用しません。
各ハイパーバイザー ベンダーは、vTPMインスタンスを外部アクセスから保護する責任を負います。 たとえばNutanix AHVでは、仮想マシン間の隔離を確保し、Mantleと呼ばれる安全な分散シークレット サービスを使用してvTPMデータを暗号化し、不正アクセスや改ざんを防ぎます。
ライブ マイグレーション
ライブ マイグレーションを使用すると、管理者が手動で、または自動プロセスによって移動が開始されたかに関わらず、仮想マシンが稼働中のままワークロードを中断することなく、システムが仮想マシンをあるホストから別のホストへ移動できます。 ライブ マイグレーションは、メンテナンス操作、ADSのワークロード バランシング、ノード拡張、または管理者によるリクエストによってトリガーされ、クラスタ ノードで定期的に発生します。
また、ライブ マイグレーションを使用して仮想マシンを同じ場所、または別の場所にある別の物理クラスタに移行して、ワークロードのリバランス、メンテナンス作業の実施、または計画停止の回避ができます。 クラスタ間でのライブ マイグレーションの場合は、5ミリ秒の遅延を持つネットワークを推奨しますが、クラスタ間で最大40ミリ秒の遅延までサポートしています。
仮想マシンのライブ マイグレーションには、いくつかの段階があります:
- 宛先ホスト上に、仮想マシンのプレースホルダーを作成する
- 移動元の仮想マシンのメモリを、宛先の仮想マシンのプレースホルダーに繰り返しコピーする
- 移動元のホストで、仮想マシンを一時停止する
- 移動元の仮想マシンから宛先仮想マシンのプレースホルダーに、最終的な仮想マシンの状態をコピーする
- 継続的な接続を確保するために、ネットワーク スイッチを更新する
- 宛先ホストで、仮想マシンを再開する
- 一時停止した仮想マシンを移動元から削除する
ステップ2の、仮想マシンのメモリのコピー は、特定の反復回数(執筆時点では50回)まで繰り返しできます。 仮想マシンはまだ起動中であるため、AHVは各反復のコピー プロセスの間、アクティブに変更されている仮想マシンのメモリを追跡します。 反復が完了すると、AHVは、まだ宛先にコピーする必要がある変更されたメモリの量と、ネットワーク経由でのメモリ転送の実際の速度を分析して、別の反復が必要か、もしくは移行を次のステップに進めるかを決定します。 移行を成功させるには、仮想マシン内のメモリ量よりもメモリを変更する速度の方が重要であるため、AHVは仮想マシンのスピードを積極的に管理して、次の反復で送信する必要があるメモリ量を削減します。
ステップ3の、移行元ホスト上の仮想マシンの一時停止は、残りのメモリを300ミリ秒以内に転送できることをAHVが検出した場合にのみ発生し、非常に短い期間の後に仮想マシンが宛先ホスト上で応答することが保証されます。 これは最大のスタン時間です。 最後の反復後に残りのメモリをこのウィンドウ内で転送できない場合、移行は「収束失敗」のエラーで中止される可能性があります。 移行は、ADS、ホストの退避、または管理者が別の移行を手動でトリガーすることによって、自動的に再試行される場合があります。
ステップ5の、ネットワーク スイッチの更新は、仮想マシンの起動中にサブネット上のすべてのデバイスにRARPブロードキャスト ネットワーク パケットを送信することによって実行されます。 これにより外部ネットワーク スイッチが、仮想マシンが現在実行されている場所を認識し、パケットを適切にルーティングできるようになり、たとえば移行中にTCP接続が失われないようにします。
Generation ID(VM-GenerationID)
Generation IDを使用して仮想マシンの識別子にアクセスし、ライセンスまたは機能の検証のために仮想マシンがクローンまたは複製されたかどうかを検証するさまざまなアプリケーションがあります。
AOS 6.7以降のAHVでは、作成された仮想マシンごとにGeneration IDを作成しており、これには、その仮想マシン内で実行されているアプリケーションがアクセスできます。 アプリケーションは、正しいGeneration IDが存在するかどうかに基づいて、どのように動作するかを決定できます。
これが重要となる注目すべき例の1つはWindowsドメイン コントローラーの場合で、適切な保護策なしで誤ってクローンやロールバックをすると問題が発生する可能性があります。 Generation IDはこの情報を仮想マシンに提供するメカニズムであり、アプリケーションによるこれらの制限の確認と強制を可能にします。
Advanced Processor Compatibility
Advanced Processor Compatibility(APC)は、アップグレードを効率化し、クラスタを最新世代のCPUに移行することを支援します。 クラスタはもはや、最低限の共通基準CPUに制限されることはありません。 仮想マシンが利用可能なCPU機能を正確に識別し利用できるようになり、移行が改善されます。
APCは、いくつかの異なる方法で柔軟性を提供します。 まず、クラスタは、一貫したCPUプレゼンテーションをゲスト仮想マシンに提供してレベルを合わせることができ、これはデフォルトの動作です。 また、ハードウェアの異なる世代へのオンデマンドでのクロスクラスタ ライブ マイグレーションを実行するために、仮想マシンごとにベースラインとなるCPUモデルの設定もできます。
自動クラスタ選択(Automatic Cluster Selection)
自動クラスタ選択により、Nutanix管理者は最小限の管理オーバーヘッドでクラウドのような体験を提供することが容易になります。 多くの組織は、単一のPrism Centralインスタンスで管理される複数のクラスタを持つ汎用環境を有していますが、異なるクラスタの利用状況は、これまで管理者によって手動で管理する必要がありました。
自動クラスタ選択は、仮想マシンが作成される際に、リソースの可用性、ホストのアフィニティ、プロジェクトの仕様、およびイメージ配布ポリシーに基づいて、最適なクラスタをインテリジェントに決定します。 この機能により、新しい仮想マシンが展開される際に、リソースがクラスタ間で自動的にバランスされることが保証されます。 自動クラスタ選択は、貴重な時間を節約し、インフラストラクチャー全体で最大のパフォーマンスと利用効率を確保するために、ワークロードを均等に分散させることにも役立ちます。
Acropolis Dynamic Scheduler(ADS)
Acropolis Dynamic Scheduler(ADS)は、AHVスタックの主要なコンポーネントです。 ADSは、ホストのホットスポット(CPUとストレージの使用率が高いホスト)の解決、高可用性の保証の維持、リソースを解放するための仮想マシン配置の最適化、管理者が定義したポリシーの適用など、多くの操作での仮想マシンの移行と配置を担当します。 ADSは常にバックグラウンドで実行され、インフラストラクチャーを継続的に監視して最適化します。
ADSに含まれる主要機能:
- 最初の仮想マシン配置 - 仮想マシンのAHVホストを選択し、必要に応じてクラスタをデフラグメントして、新しい仮想マシンで十分なリソースが利用できるようにする
- 動的ホットスポットの緩和 - 各ホストを監視し、ホットスポットが検出された場合に、そのホットスポットを解決します
- バックグラウンド ポリシーの適用 - たとえば、仮想マシン-ホスト アフィニティ ポリシーや、仮想マシン-仮想マシン アンチアフィニティ ポリシーを遵守するために仮想マシンを移動する
- 高可用性(HA)保証の強制 - HAの保証が有効になっている場合、ADSは実行中のシステム内で仮想マシンを移動し、個々のホストの障害後に、各ホスト上のすべての仮想マシンを確実に復元できるようにする
- 動的なGPU管理 - NVIDIA GPUをサポートし、システム内で稼働している仮想マシンに基づいて、特定のvGPUプロファイルを提供する
- 上記のケースに対処するために、移動コストに基づいて修復プランを作成する
ADS はホットスポットの緩和に重点を置き、コストを最小限に抑える修復プランを立てるため、積極的な負荷分散シナリオで必要になる仮想マシンの移動量よりも少ない結果になります。
ホットスポット緩和の例 - サンプル プラン
次の例のFigure 1は、ホストが利用可能なCPU容量の90%を使用していることを示しています。 CPUホットスポットのしきい値は85%であるため、ADSは仮想マシンの移動が必要であると認識します。
Figure 2では、ADSは8GBの仮想マシンのうち1つを、3番目のホストから2番目のホストに移動し、最初のホスト上にある仮想マシンの1つが移動するのに十分なスペースを確保するプランを算出します。
どの仮想マシンをより簡単に移動できるかを決定するために、最初のホスト上にある仮想マシンのメモリ量が考慮されます。 Figure 3の最終状態では、最も低コストの移動として、最初のホスト上にある2つの仮想マシンのうち、小さい方の仮想マシンが3番目のホストに移動することが示されています。
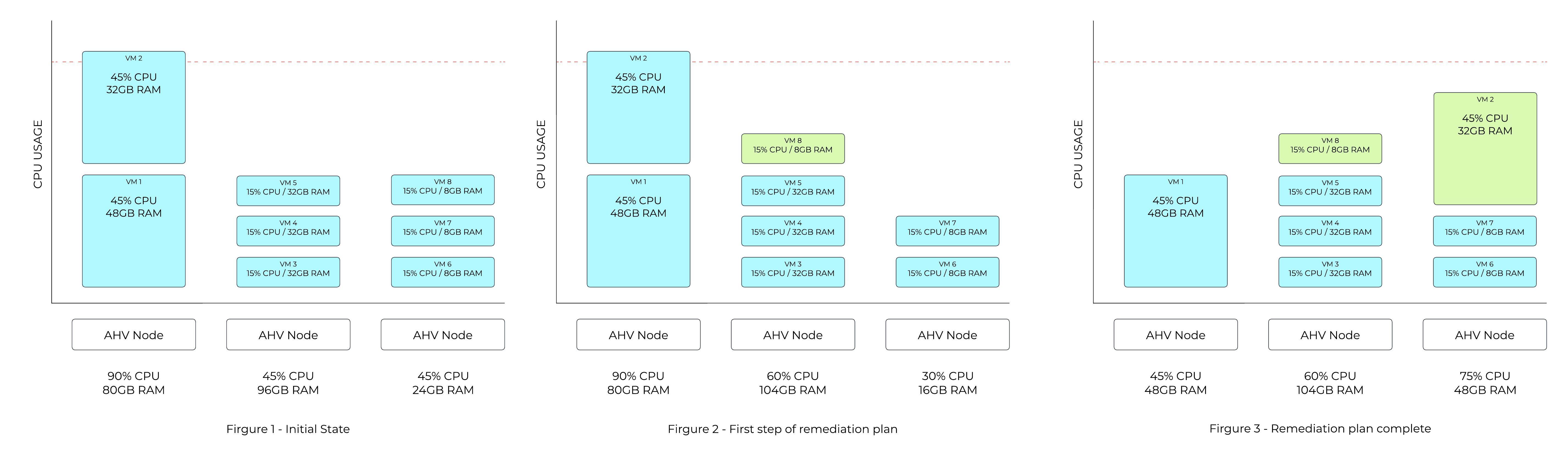
ホットスポットの検出と修復プランのコスト最小化の両方には複数の側面が考慮されるため、ADSのプランは通常これより複雑になります。
AHVのネットワーク
AHVは、全てのVMネットワークに対してOpen vSwitch (OVS) を活用しています。VMネットワークは、PrismやaCLIから設定することが可能で、各VM NICは、Tapインターフェイスに接続されます。
以下に、OVSアーキテクチャーの概念構成を示します:
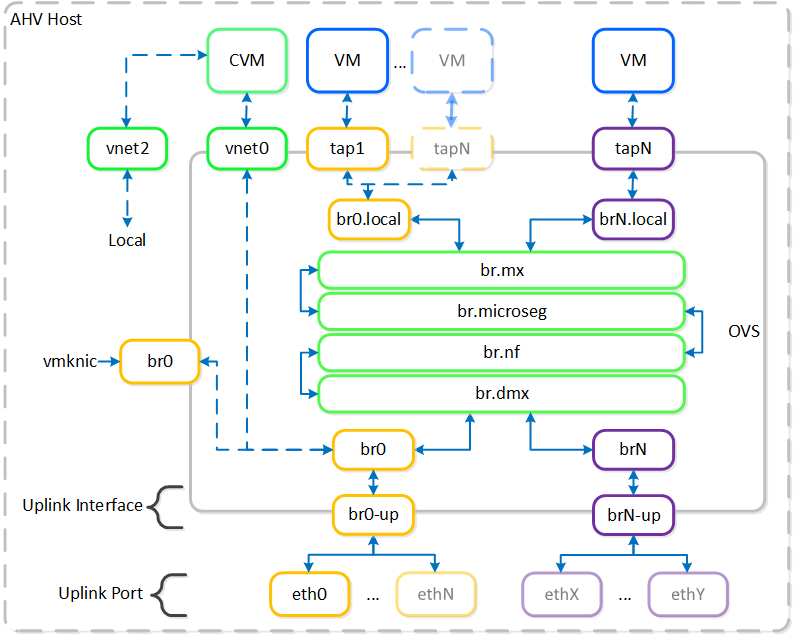
上記の画像には、いくつかの種類のコンポーネントが表示されています。
Open vSwitch(OVS)
OVSとは、Linuxカーネルに実装され、複数台のサーバー仮想化環境で動作するように設計されたオープンソースのソフトウェアスイッチです。 デフォルトでは、OVSはMACアドレステーブルを維持するレイヤー2ラーニングスイッチのように動作します。 ハイパーバイザーホストとVMはスイッチの仮想ポートに接続します。
OVSは、VLANタグ、Link Aggregation Control Protocol(LACP)、ポートミラーリング、Quality of Service(QoS)など、多くの一般的なスイッチの機能をサポートしています。 各AHVサーバーはOVSインスタンスを持ち、すべてのOVSインスタンスが結合して単一の論理スイッチを形成します。 ブリッジと呼ばれる構造は、AHVホストにあるスイッチのインスタンスを管理します。
ブリッジ
ブリッジとは、物理と仮想ネットワークインターフェイス間のネットワークトラフィックを管理する仮想スイッチとして機能します。 デフォルトのAHV構成には、br0と呼ばれるOVSブリッジとvirbr0と呼ばれるネイティブLinuxブリッジが含まれています。 virbr0 Linuxブリッジは、CVMとAHVホスト間の管理およびストレージ通信を運送します。 他のすべてのストレージ、ホスト、およびVMネットワークのトラフィックはbr0 OVSブリッジを通過します。 AHVホスト、VM、および物理インターフェイスは、ブリッジへの接続に「ポート」を使用します。
ポート
ポートとは、仮想スイッチへの接続を表す、ブリッジに作成された論理構造です。 Nutanixでは、internal、tap、VXLAN、ボンドを含む、いくつかのポートタイプを使用します。
- internalポート(デフォルトブリッジであるbr0と同じ名前のもの)は、AHVホストへのアクセスを提供します。
- tapポートは、VMに提供される仮想NICのブリッジ接続として機能します。
- VXLANポートは、Acropolisが提供するIPアドレス管理機能で使用されます。
- ボンドポートは、AHVホストの物理インターフェイスにNICチーミングを提供します。
ボンド(bond)
ボンドポートは、AHVホスト上の物理インターフェイスを束ねます。 デフォルトでは、br0-upという名前のボンドがbr0ブリッジに作成されます。 ノードをイメージングすると、すべてのインターフェイスは単一のボンド内に配置されます。これは、Foundationでのイメージング処理の要件によるものです。 デフォルトのボンド(AHVホストではbr0-up)に対して、(一般的なLinuxでは)bond0という名前がしばしば用いられますが、 Nutanixは、インターフェイスをブリッジbr0のアップリンクとして迅速に識別できるように、名前はbr0-upのまま使用することを推奨します。
OVSのボンドでは、active-backup、balance-slb、balance-tcpといった、いくつかの負荷分散モードが設定できます。 ボンドに対してLACPも有効化できます。 「bond_mode」の設定はインストール中に指定されないためデフォルトはactive-backupであり、これは推奨構成です。
アップリンクのロードバランシング
前のセクションで簡単に説明したように、ボンドアップリンク間でトラフィックを分散できます。
以下のボンドモードが使用できます:
- active-backup
- デフォルトの構成で、単一のアクティブなアダプターを経由してすべてのトラフィックを送信します。 アクティブなアダプターが使用できなくなると、ボンド内の別のアダプターがアクティブになります。 スループットは単一のNICの帯域幅に制限されます。 (推奨構成)
- balance-slb
- ボンド内のアダプター間で、VM NICごとに分散します(例えば、VM Aの持つnic1がeth0、nic2がeth1)。 VMのNICあたりのスループットは単一のNICの帯域幅に制限されますが、n個のNICを持つVMは「n * アダプター帯域幅」を活用できます(ボンド内のVMのNICと物理アップリンクアダプターの数が同じであると想定すると)。 注:マルチキャストトラフィックに関して注意事項があります。
- balance-tcp / LACP
- ボンド内のアダプター間で、VM NICのTCPセッションごとで分散します。 NICごとのスループットは、ボンドの最大帯域幅(物理アップリンクアダプター数 * 速度)に制限されます。 Link Aggregationが必要で、そしてLACPが必要な場合に使用されます。
ボンドの詳細については、(Nutanix AHV Networking Best Practices を参照してください。
VM NICの種類
AHVは、以下のVMネットワークインターフェイスの種類をサポートします:
- Access(デフォルト)
- Trunk(AOS 4.6以上)
デフォルトで、VMのNICはAccessインターフェイスとして生成されますが、(ポートグループ上のVMのNIC同様に)VMのOSにTrunkインターフェイスとして提示することも可能です。 Trunk設定されたNICはプライマリVLANをタグなしで送信し、追加のすべてのVLANをタグ付けしてVM上の同じvNICで送信します。 これは、VMにvNICを追加せずに複数のネットワークを接続する場合に役立ちます。
Trunkインターフェイスは、以下のコマンドで追加することができます:
vm.nic_create <VM_NAME> vlan_mode=kTrunked trunked_networks=<ALLOWED_VLANS> network=<NATIVE_VLAN>
例:
vm.nic_create fooVM vlan_mode=kTrunked trunked_networks=10,20,30 network=vlan.10
サービスチェーン
AHVサービスチェーン(service chaining)によって、全てのトラフィックをインターセプトし、パケット処理機能(NFV、アプライアンス、仮想アプライアンスなど)に対してネットワークパスの延長として透過的に渡すことができます。
サービスチェーンの一般的な使用例:
- ファイアウォール(例えば、Palo Altoなど)
- IDS/IPS/ネットワークモニター(例えば、パケットキャプチャー)
サービスチェーンには、2つの方式があります:
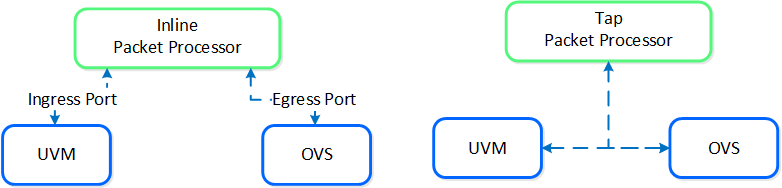
- インライン (Inline) パケット処理
- OVSを流れるパケットをインラインでインターセプト
- パケットの変更、許可/拒否が可能
- 一般的な適用例: ファイアウォール
-
タップ (Tap) パケットプロセッサ
- パケットフローにタップして読み込みを行い、パケットを検査
- 一般的な適用例: IDS、IPS、ネットワーク監視
全てのサービスチェーン処理は、Flowのマイクロセグメンテーション ルールが適用された後、かつパケットがローカルOVSから出る前に完了します:
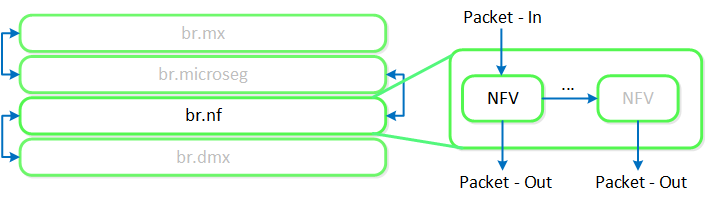
説明: 複数のパケットプロセッサを、1つのチェーンに繋ぎ合わせることも可能です。 サービス チェーンは、Acropolisがネットワーク スタックを制御する場合のみ適用されます。 サービス チェーンは現在、Network ControllerベースのVLANまたはVPCではサポートされていません。
Network Controller
Network Controllerは、Flow Virtual NetworkingとVPCのオーバーレイ サブネットを有効化するために、AOS 6.0でリリースされました。 AOS 6.7で、NutanixはNetwork Controllerを強化し、ゲスト仮想マシンを接続するVLAN-backedサブネットのサポートを追加しました。 Network Controllerが有効になると、Acropolisリーダーによって管理される既存のVLANを説明するために、新しいサブネット ラベルとしてVLAN Basicが作成されます。 Network Controllerによって管理されるサブネットにはラベルがなく、シンプルにVLANと呼ばれます。
サポートされる構成
主要ユースケース:
- Network ControllerベースVLANサブネットの追加機能を備えたAHVネットワーキング
- Flow Virtual NetworkingのVPCオーバーレイ サブネット
- Network Controllerが有効なVLANベース サブネットのマイクロセグメンテーション
- VPCオーバーレイ サブネットでのマイクロセグメンテーション
管理インターフェイス:
- Prism Central(PC)
サポートされている環境:
- オンプレミス:
- AHV
- Nutanix Cloud Clusters(NC2)
- NC2 on Azure
Network Controllerが有効化されたVLANの前提条件:
- Prism Central 2023.3
- AOS 6.7
- AHV 9
- MSPの有効化
アップグレード:
- LCMに含まれる
プロからのヒント
Network Controllerのスケーラビリティを最大にするには、Prism CentralをExtra large(X-Large)サイズで展開します。
実装の構造
Network Controller(以前のAtlas Network Controller)は、Flow Virtual Networking VPCと、AHV内のNetwork Controllerが有効なVLAN-Backedサブネットによって使用される仮想ネットワーク スタックを制御します。 Network Controllerにより大規模な構成が可能になり、複数のPrism Elementクラスタに存在するサブネットなどの新機能が利用できるようになります。 このネットワーク スタックにより、将来的なネットワークとネットワーク セキュリティの機能が使用できるようになります。 拡張された機能により、OVSベースのアーキテクチャーで使用されていたものとは異なるいくつかの構造があります。
Network Controllerは、Prism Centralから、VLAN、オーバーレイ サブネット、IPアドレス プール、そしてセキュリティ ポリシーを集中管理するために使用されます。 Network Controllerは Prism Central 上で実行されます。
Network Control Plane
Network Controllerは、Network Control Planeをプログラムしてパケットの処理方法を決定します。 Control Planeには、Open Virtual Network(https://www.ovn.org/en/architecture/)を使用しています。 brAtlasという名前の新しい仮想スイッチが、すべてのAHVホストに作成されます。
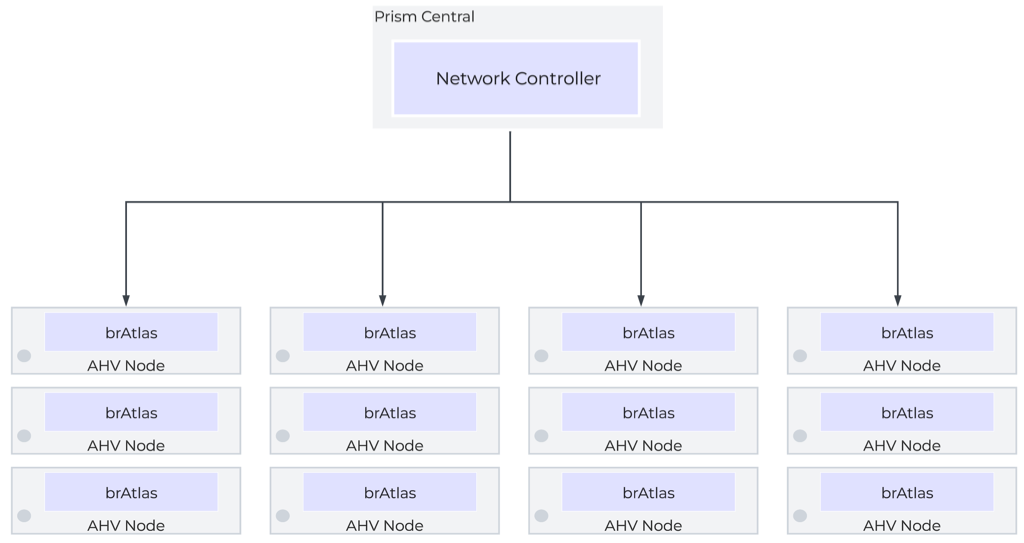
ネットワーク ブリッジ
Network Controllerで使用されるブリッジの種類は2つあり、それはbrAtlasとbr0です。
brAtlas
brAtlasブリッジは、すべてのAHVホストに作成される仮想スイッチで、Network Controllerによって管理されます。 VPCおよびNetwork ControllerによるVLANに接続されたゲスト仮想マシンは、tapインターフェイスを介してbrAtlasに接続します。
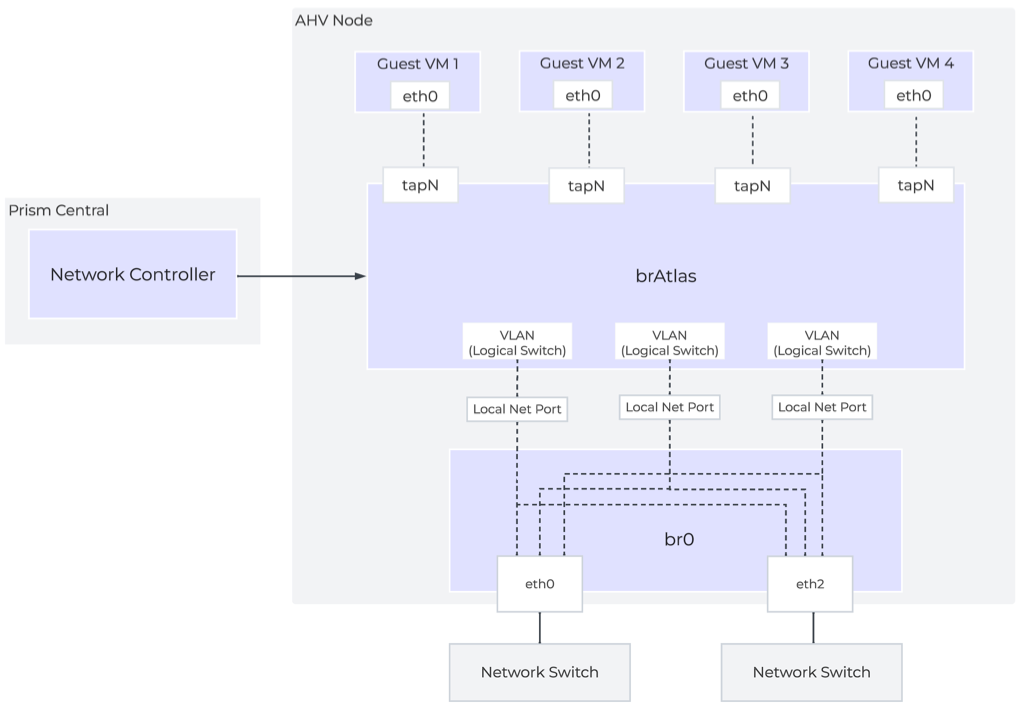
br0
br0ブリッジは、brAtlasのレイヤー2スイッチとして機能し、物理ネットワークと接続するアップリンク ブリッジです。 必要に応じて、複数のアップリンク ブリッジを使用できます。 これらの追加のアップリンク ブリッジは、同じ命名規則に従い、br0、br1、br2といった名前になります。
VLANと論理スイッチ(Logical Switch)
ゲスト仮想マシンのVLANタグ付けのために、すべてのVLANがbrAtlas内のLogical Switchにマッピングされます。 それぞれのLogical Switchには、br0などのアップリンク仮想スイッチに接続するLocal Net Portが関連付けられます。 Local Net Portは、Logical Switchと物理ネットワーク間の接続ポイントです。
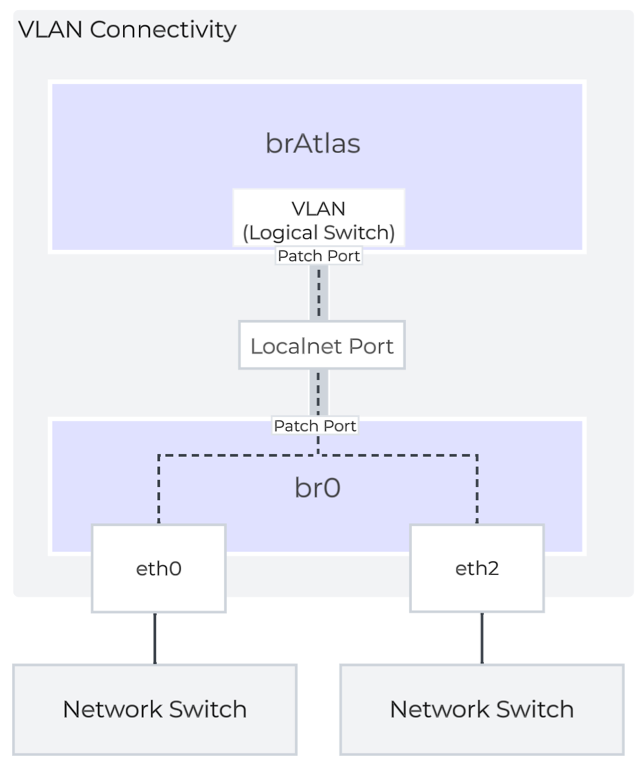
Local Net Portは、brAtlasとbr0間のPatch Portペアで構成されます。 Network Controllerが有効なVLAN-backedサブネットは、brAtlasのLogical Switchにマッピングされます。
Nutanix AHVの動作の仕組み
ストレージI/Oパス
AHVは、ESXiやHyper-Vのような従来のストレージ スタックを使用してはいません。 全てのディスクは、ロー(raw)SCSIブロックデバイスとしてVMに渡されます。 これによってI/Oパスを軽量化および最適化することができます。
注意
AOSは、エンドユーザーに対してkvm、virsh、qemu、libvirtおよびiSCSIを抽象化する形で、全てのバックエンド構成を処理します。 これによってユーザーは、PrismやaCLIを使って、そのスタックより上のみを意識すればよくなります。 なお以下は、情報提供を目的とした説明であるため、マニュアル操作でvirshやlibvirtに触らないことを推奨します。
各AHVホストには、iSCSIリダイレクター デーモンが常駐し、NOP OUTコマンドを使用してクラスタのStargateに関するステータスチェックを行います。
iscsi_redirectorログ(AHVホストの/var/log/に存在)によって、各Stargateの稼動状態を確認することができます:
2017-08-18 19:25:21,733 - INFO - Portal 192.168.5.254:3261 is up
...
2017-08-18 19:25:25,735 - INFO - Portal 10.3.140.158:3261 is up
2017-08-18 19:25:26,737 - INFO - Portal 10.3.140.153:3261 is up
注意: ローカルのStargateは、内部アドレス192.168.5.254で確認できます。
以下の内容を見ると、iscsi_redirectorが127.0.0.1:3261でリスニングしていることが分かります:
[root@NTNX-BEAST-1 ~]# netstat -tnlp | egrep tcp.*3261 Proto ... Local Address Foreign Address State PID/Program name ... tcp ... 127.0.0.1:3261 0.0.0.0:* LISTEN 8044/python ...
QEMUは、iSCSIリダイレクターがiSCSIターゲットポータルとなるよう設定されます。ログインリクエストがあるとリダイレクターが起動され、iSCSIログインは、正常なStargate(通常はローカルにある)にリダイレクトされます。
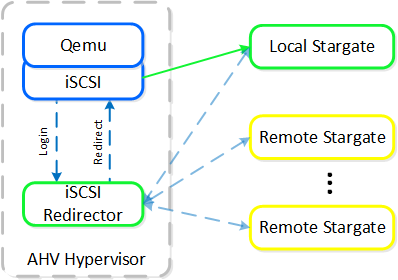
XMLのドメインを確認すると、その構成が分かります:
<devices> ... <disk type='network' device='lun'> <driver name='qemu' type='raw' cache='none' error_policy='report' io='native'/> <source protocol='iscsi' name='iqn.2010-06.com.nutanix:vmdisk-16a5../0'> <host name='127.0.0.1' port='3261'/> </source> <backingStore/> <target dev='sda' bus='scsi'/> <boot order='1'/> <alias name='scsi0-0-0-0'/> <address type='drive' controller='0' bus='0' target='0' unit='0'/> </disk> ... </devices>
推奨するコントローラータイプは、virtio-scsi(SCSIデバイスのデフォルト)です。 IDEも使用できますが、ほとんどの場合、お薦めできません。Windowsでvirtioを使用する場合には、virtioドライバー、Nutanixモビリティドライバー、またはNutanix Guest Toolsがインストールされている必要があります。 最新のLinuxディストリビューターは、virtioをプリインストールして出荷しています。
... <controller type='scsi' index='0' model='virtio-scsi'> <driver max_sectors='2048'/> <alias name='scsi0'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x03' function='0x0'/> </controller> ...
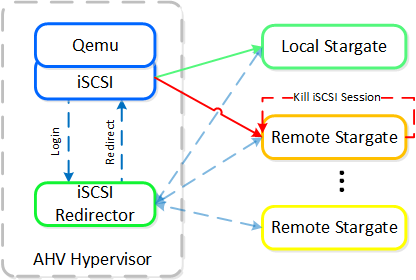
稼動中のStargateが停止した(NOP OUTコマンドにレスポンスできない)場合、iSCSIリダイレクターは、ローカルのStargateを障害として判断します。そして、QEMUがiSCSIログインを再試行した時に、リダイレクターは、ログインオペレーションを他の正常なStargateにリダイレクトします。
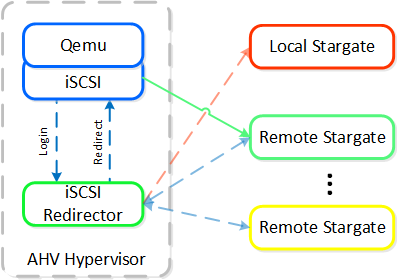
ローカルのStargateが復旧(かつNOP OUTコマンドにレスポンスを開始)した場合、iSCSIリダイレクターは、リモートStargateへのiSCSIセッションを終了します。 QEMUは、iSCSIログインを再度試み、同ログインはローカルのStargateにリダイレクトされます。
従来のI/Oパス
全てのハイパーバイザーやOSと同様、ユーザー空間とカーネル空間のコンポーネントが相互にやり取りを行って、1つの処理を実行しています。 以下を読む前に「ユーザー空間とカーネル空間」のセクションを参照し、お互いがどういった関係でやり取りをしているかを理解することをお勧めします。
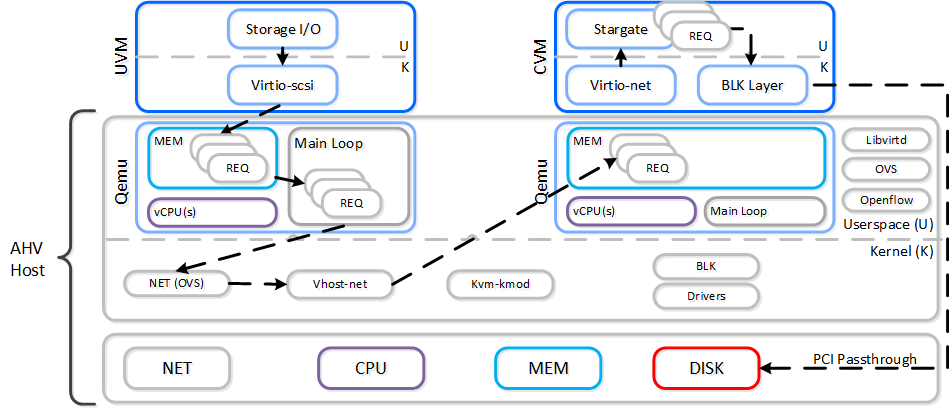
VMがI/Oを実行する場合、以下の処理が行われます(理解しやすくするため、一部の手順は省略してあります):
- VMのOSが仮想デバイスに対してSCSIコマンドを実行
- Virtio-SCSIがリクエストを受け取り、ゲストのメモリに保存
- QEMUメインループがリクエストを処理
- Libiscsiが各リクエストを検査して転送
- ネットワーク層がリクエストをローカルCVMに転送(ローカルCVMが利用できない場合は外部のCVM)
- Stargateがリクエストを処理
以下に、このフローの例を示します:
ドメインのXMLに着目すると、qemu-kvmエミュレータが使用されていることが分かります。
... <devices> <emulator>/usr/libexec/qemu-kvm</emulator> ...
またAHVホストを見ると、ローカルブリッジとIPを使用している正常なStargateを使って、qemu-kvmがセッションを確立しています。 外部との通信のため、外部ホストとStargate IPが使用されています。 注意: 1ディスクあたりのセッション数は、1つとなります(PID 24845をご覧ください)。
[root@NTNX-BEAST-1 log]# netstat -np | egrep tcp.*qemu Proto ... Local Address Foreign Address State PID/Program name tcp ... 192.168.5.1:50410 192.168.5.254:3261 ESTABLISHED 25293/qemu-kvm tcp ... 192.168.5.1:50434 192.168.5.254:3261 ESTABLISHED 23198/qemu-kvm tcp ... 192.168.5.1:50464 192.168.5.254:3261 ESTABLISHED 24845/qemu-kvm tcp ... 192.168.5.1:50465 192.168.5.254:3261 ESTABLISHED 24845/qemu-kvm ...
メインループがシングルスレッドになっていたり、libiscsiがすべてのSCSIコマンドを検査したりするなど、このパスには幾つか非効率な部分が存在します。
Frodo I/Oパス(別名AHV Turbo Mode)
ストレージテクノロジーは、Nutanixと同様に進化を続け、その効率性をさらに高めています。 Nutanix自身の手でAHVやスタックを完全にコントロールできるようになった今こそ、絶好の機会です。
手短に言えば、Frodoはより優れたスループットや低レイテンシーの実現、さらにCPUのオーバーヘッドを減らすため、AHV向けに特別に最適化されたI/Oパスなのです。
プロからのヒント
FrodoはAOS 5.5.X以降でパワーオンされたVMにおいてデフォルトで有効になります。
VMがI/Oを実行する場合、以下の処理が行われます(理解し易くするため、一部の手順は省略してあります):
- VMのOSが仮想デバイスに対してSCSIコマンドを実行
- Virtio-scsiがリクエストを受け取り、ゲストのメモリに保存
- Frodoがリクエストを処理
- カスタムlibiscsiがiscsiヘッダーを付加して転送
- ネットワーク層がリクエストをローカルCVMに転送(ローカルCVMが利用できない場合は外部のCVM)
- Stargateがリクエストを処理
以下に、このフローの例を示します:
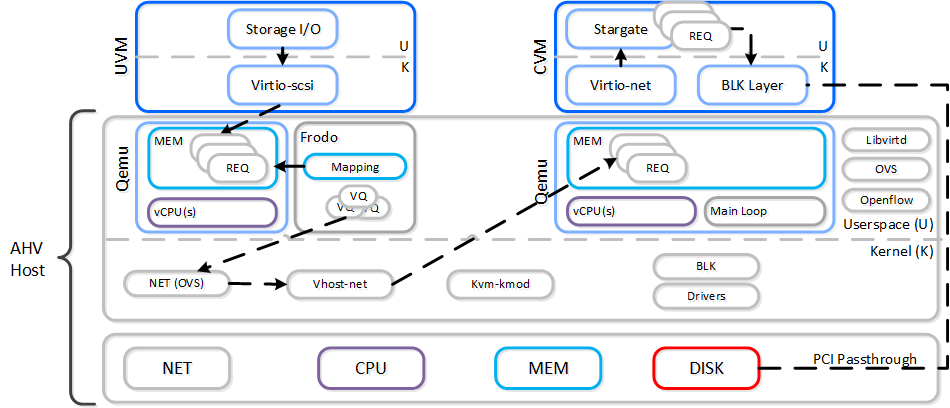
以下のパスは、いくつかの重要な点を除いて、従来のI/Oと変わりが無いように見えます:
- Qemuのメインループを、Frodo(vhost-user-scsi)に置き換える
- Frodoは複数の仮想キュー (VQ) をゲスト(vCPUあたり1つ)に提供
- マルチスレッドを使用して、複数のvCPU VMに対応
- LibiscsiをNutanix独自のより軽いバージョンに置き換える
パフォーマンスが向上するのみでなく、ゲストからはディスクデバイスに複数のキューが存在しているように見えます。 I/O処理のCPUオーバーヘッドが25%も低下したり、Qemuに比べパフォーマンスが3倍になったりした例もあります! 他のハイパーバイザーに比べても、I/O処理のCPUオーバーヘッドを最大3倍減らすことができます。
AHVホストを見ると、それぞれのVM(qemu-kvmプロセス)に対してfrodoプロセスが存在することが判ります。
[root@drt-itppc03-1 ~]# ps aux | egrep frodo ... /usr/libexec/qemu-kvm ... -chardev socket,id=frodo0,fd=3 \ -device vhost-user-scsi-pci,chardev=frodo0,num_queues=16... ... /usr/libexec/frodo ... 127.0.0.1:3261 -t iqn.2010-06.com.nutanix:vmdisk... ...
またドメインのXMLがfrodoを使用していることも判ります:
... <devices> <emulator>/usr/libexec/frodo</emulator> ...
プロからのヒント
Frodoのマルチスレッド / マルチコネクションの利点を活かすためには、VMが立ち上がった際に、1つのVMにつき2つ以上のvCPUを割り当てることが必要となります。
これは、以下のように特徴付けられます:
-
1 vCPU UVM:
- 1ディスクデバイスあたり1 Frodoスレッド / セッション
- 2以上の vCPU UVM:
- 1ディスクデバイスあたり2 Frodoスレッド / セッション
以下では、ローカルブリッジとIPを使用している正常なStargateを使って、Frodoがセッションを確立しています。外部との通信のため、外部ホストとStargate IPが使用されています。
[root@NTNX-BEAST-1 log]# netstat -np | egrep tcp.*frodo Proto ... Local Address Foreign Address State PID/Program name tcp ... 192.168.5.1:39568 192.168.5.254:3261 ESTABLISHED 42957/frodo tcp ... 192.168.5.1:39538 192.168.5.254:3261 ESTABLISHED 42957/frodo tcp ... 192.168.5.1:39580 192.168.5.254:3261 ESTABLISHED 42957/frodo tcp ... 192.168.5.1:39592 192.168.5.254:3261 ESTABLISHED 42957/frodo ...
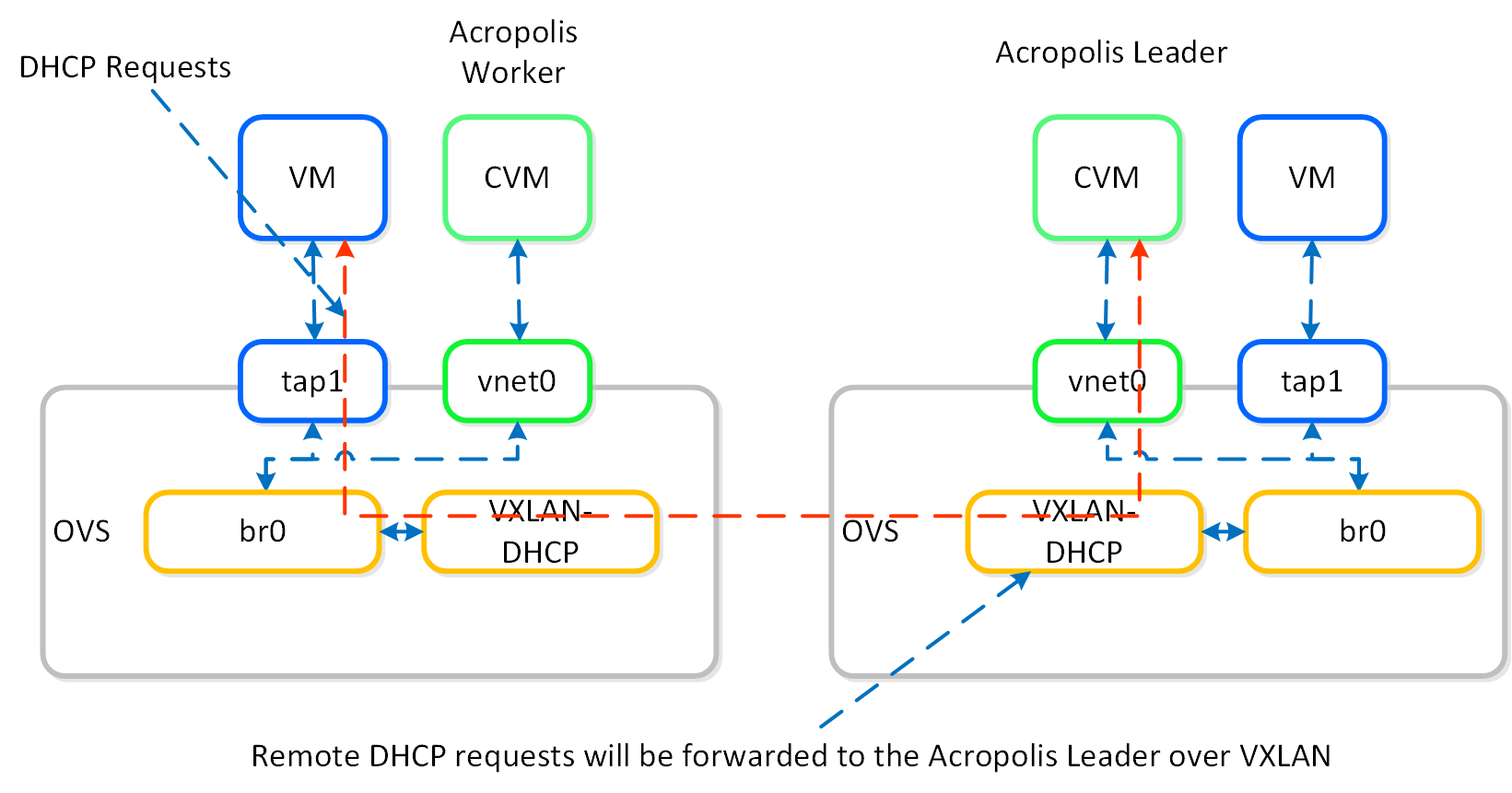
IPアドレスの管理
Acropolis IPアドレス管理 (IPAM) により、DHCPスコープを構成し、VMに自動的にIPアドレスを割り当てることができます。この機能は、VXLANとOpenFlowルールを使用してDHCPリクエストに割り込みを行い、DHCPレスポンスによりレスポンスを返します。
以下は、Acropolisリーダーがローカルで稼動している場合の、Nutanix IPAMを使用したDHCPリクエストのオペレーション例です:
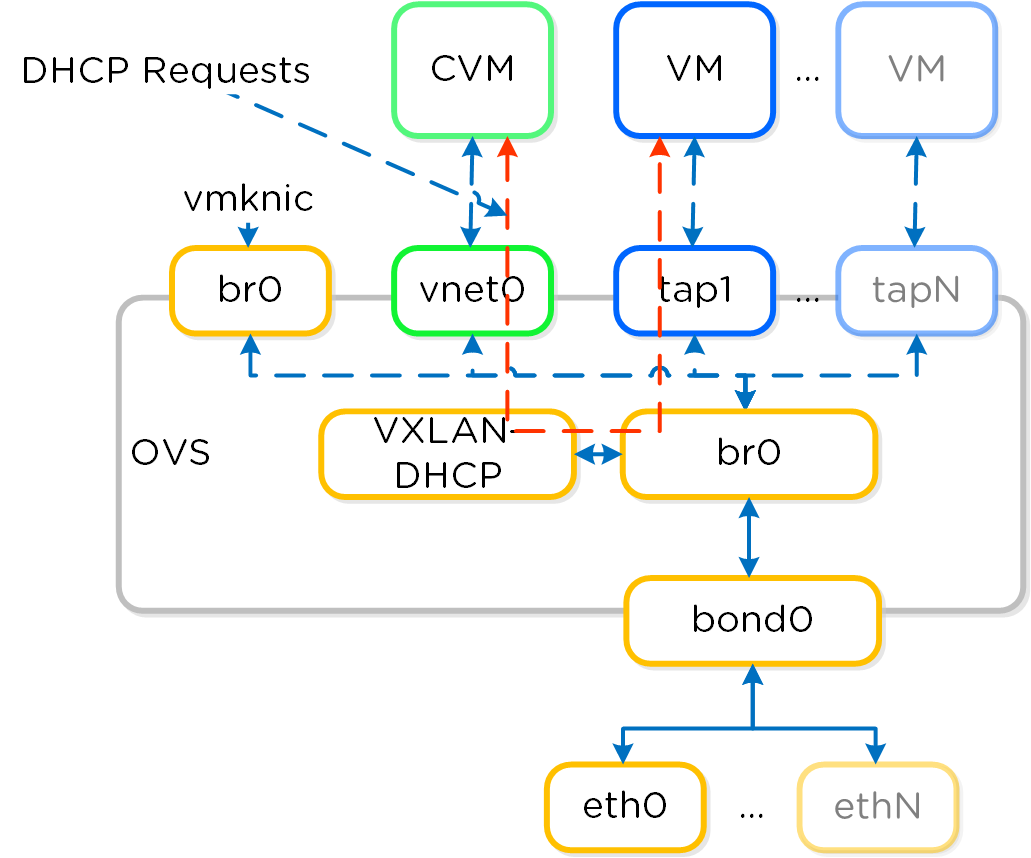
Acropolisリーダーがリモートで稼動している場合には、ネットワークを超えたリクエストを処理するために、同じVXLANトンネルが使用されます。
既存のDHCP / IPAM ソリューションも使用することが可能です。
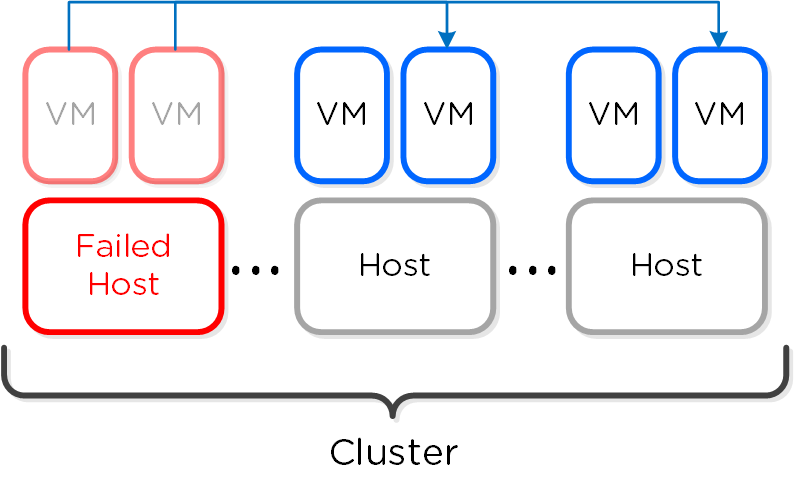
VMの高可用性 (HA)
AHV VM HAは、ホストやブロックに障害が発生した場合に、VMの可用性を確保するための機能です。 ホストに障害が発生した場合、そのホストで稼動していたVMは、クラスタ内の他の正常なノードに移動し再起動されます。 Acropolisリーダーがこの役割を担っています。
Acropolisリーダーは、クラスタ内全てのホスト上のlibvirtへの接続状況をモニターし、ホストのヘルスチェックを行っています:
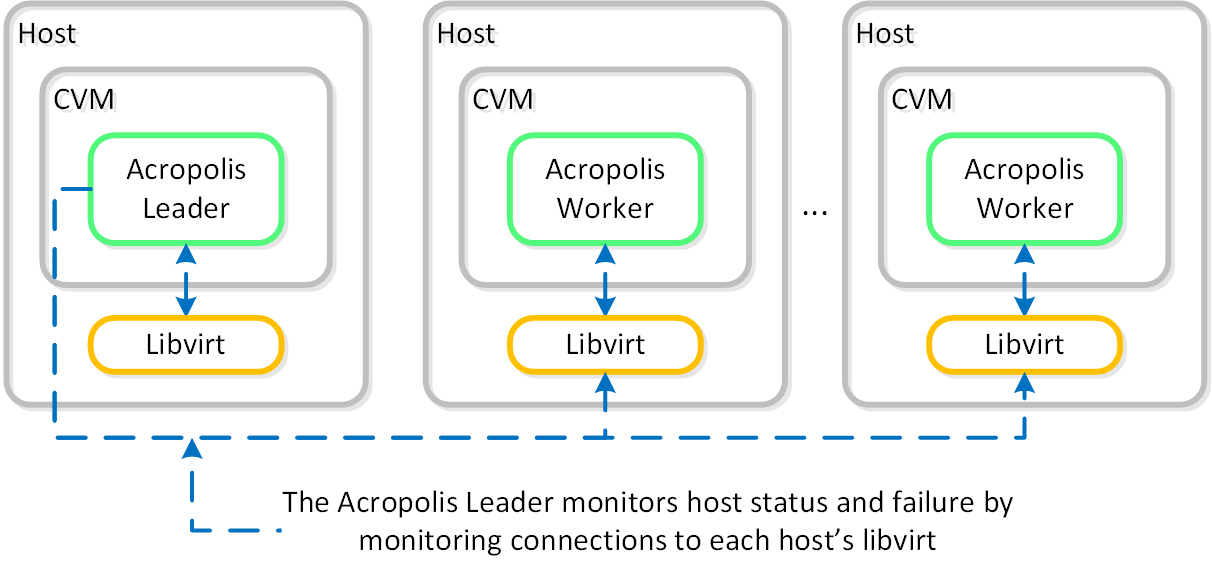
libvirtの接続がダウンすると、HAによる再起動へのカウントダウンが開始されます。 libvirtの接続がタイムアウト期間内での再確立に失敗すると、Acropolisは切断されたホストで起動されていたVMを再起動します。 この場合、VMは120秒以内に再起動されるはずです。
Acropolisリーダーが分割された場合、またはネットワーク隔離された場合、さらに、障害が発生した場合には、クラスタ内の正常のノードが新しいAcropolisリーダーとして選定されます。 クラスタが分割された場合(例えば、Xノードが他のYノードに通信不能)には、クォーラムを持った方が動作を継続し、VMはそのノードで再起動されます。
VM HAには主に2つのモードがあります:
-
デフォルト (Default)
- AHVベースのNutanixクラスタをインストールした際に、デフォルトで含まれる設定不要のモードです。 AHVホストが使用できなくなった場合、障害の発生したAHVホストで稼動していたVMは、利用可能なリソースに応じて、残りのホストで再起動されます。 残りのホストに十分なリソースが存在しない場合には、停止したすべてのVMが再起動されるとは限りません。
-
保証 (Guarantee)
- このモードは、クラスタ全体のAHVホストでスペースを予約しておき、ホストに障害が発生した場合にAHVクラスタの他のノードで、すべての停止したVMを再起動できるようにするものです。 保証モードを有効化する際には「Enable HA(HAを有効化)」チェックボックスを選択します。 予約されたメモリ量と、障害に絶えられるAHVホストの数がメッセージ表示されます。
リソース予約
VM HAを保証 (Guarantee) モードにすると、システムはVMのためにホストのリソースを予約します。 予約されるリソースの量は、以下のように要約することができます:
- 全てのコンテナがRF2 (FT1) の場合
- 1つの「ホスト」に相当するリソース
- RF3 (FT2) のコンテナが存在する場合
- 2つの「ホスト」に相当するリソース
ホストのメモリ容量に差がある場合、システムは最大のメモリ容量をもつホストを基準に、ホストあたりの予約量を決定します。
5.0以降のリソース予約
リリース5.0より前には、ホストとセグメントベース両方の予約をサポートしていました。 リリース5.0以降は、セグメントベースの予約のみとなり、これは保証HAモードが選択されると自動的に設定されます。
予約セグメントは、クラスタの全てのホスト全体にリソースを分散させます。 この場合それぞれのホストは、HAのために予約されたメモリを共有することになります。 これによって、ホストに障害が発生した場合でも、VMを再起動するための十分なフェイルオーバー容量をクラスタ全体で確保することができます。
以下の図は、予約セグメントの状態を示したものです:
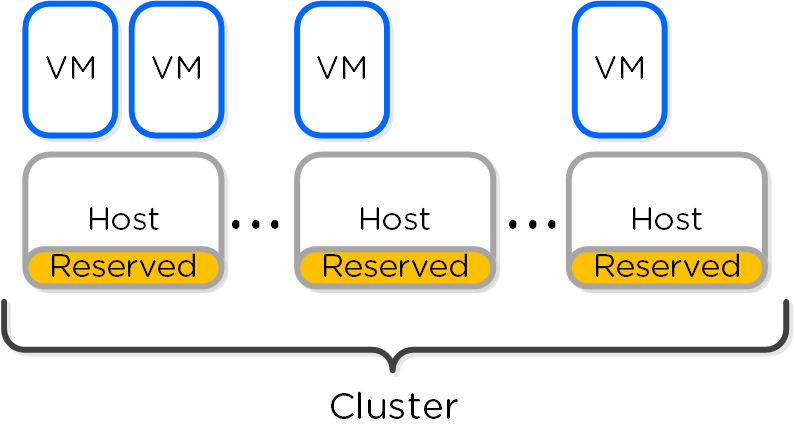
ホストに障害が発生すると、VMはクラスタに残った正常なホストを使って再起動されます。
予約セグメントの計算
予約セグメントの総数と1ホストあたりの予約量は、システムが自動的に計算します。
必要な予約量の算出は、良く知られた「ナップサック問題」の解法に集約します。 最適な解は、NP困難 (NP-hard、指数関数的)ですが、実用的には発見的解法でも最適解に近いものを得ることができます。 Nutanixは、こうしたアルゴリズムの1つであるMTHMを採用しています。 Nutanixは、今後も配置アルゴリズムの改善に努めて参ります。
AHVのアドミニストレーション
AHV コマンドリファレンス
OVSアップリンクの表示
説明: ローカルホストのOVSアップリンクを表示
manage_ovs show_uplinks
説明: クラスタ全体のOVSアップリンクを表示
allssh "manage_ovs show_uplinks"
OVSインターフェイスの表示
説明: ローカルホストのOVSインターフェイスを表示
manage_ovs show_interfaces
説明: クラスタ全体のインターフェイスを表示
allssh "manage_ovs show_interfaces"
OVSスイッチ情報を表示
説明: スイッチ情報を表示
ovs-vsctl show
OVSブリッジ一覧
説明: ブリッジ一覧を表示
ovs-vsctl list br
OVSブリッジ情報の表示
説明: OVSポート情報を表示
ovs-vsctl list port br0
ovs-vsctl list port <bond>
OVSインターフェイス情報の表示
説明: インターフェイス情報を表示
ovs-vsctl list interface br0
ブリッジのポート/インターフェイスを表示
説明: ブリッジのポートを表示
ovs-vsctl list-ports br0
説明: ブリッジのインターフェイスを表示
ovs-vsctl list-ifaces br0
ブリッジにポートを追加
説明: ブリッジにポートを追加
ovs-vsctl add-port <bridge> <port>
説明: ブリッジにボンドポートを追加
ovs-vsctl add-bond <bridge> <port> <iface>
OVSのボンド詳細を表示
説明: ボンド詳細を表示
ovs-appctl bond/show <bond>
例:
ovs-appctl bond/show bond0
ボンドモードを設定してボンドにLACPを構成
説明: ポートのLACPを有効化
ovs-vsctl set port <bond> lacp=<active/passive>
説明: 全ホストのbond0を有効化
for i in `hostips`;do echo $i; ssh $i source /etc/profile > /dev/null 2>&1; ovs-vsctl set port bond0 lacp=active;done
ボンドのLACP詳細を表示
説明: LACPの詳細を表示
ovs-appctl lacp/show <bond>
ボンドモードを設定
説明: ポートにボンドモードを設定
ovs-vsctl set port <bond> bond_mode=<active-backup, balance-slb, balance-tcp>
OpenFlow情報を表示
説明: OVS openflowの詳細を表示
ovs-ofctl show br0
説明: OpenFlowのルールを表示
ovs-ofctl dump-flows br0
QEMU PIDと上位情報を取得
説明: QEMU PIDを取得
ps aux | grep qemu | awk '{print $2}'
説明: 指定したPIDの上位指標値を取得
top -p <PID>
QEMUプロセスに対してアクティブなStargateを取得
説明: 各QEMUプロセスのストレージI/Oに対するアクティブなStargateを獲得
netstat -np | egrep tcp.*qemu
AHVの指標値としきい値
近日公開!
AHVのトラブルシューティングと高度な管理
iSCSIリダイレクターログの確認
説明: 全ホストのiSCSIリダイレクターログを確認
for i in `hostips`; do echo $i; ssh root@$i cat /var/log/iscsi_redirector;done
単独ホストの例
ssh root@<HOST IP>
cat /var/log/iscsi_redirector
Stolen (Steal) CPUのモニター
説明: CPUのSteal時間(Stolen CPU)をモニター
topを起動して %st(以下ではボールド表示)を探す
Cpu(s): 0.0%us, 0.0%sy, 0.0%ni, 96.4%id, 0.0%wa, 0.0%hi, 0.1%si, 0.0%st
VMネットワークリソースのステータスをモニター
説明: VMリソースのステータスをモニター
virt-topを起動
virt-top
vSphere
NutanixはVMware ESXiをサポートしており、vSphere上で仮想環境を実行しながら、Nutanixの分散ストレージ ファブリックを活用できます。 また、NutanixはESXi仮想マシンの作成および管理をPrismから直接行うこともサポートしており、これによりVMware仮想インフラストラクチャーを管理するための単一の管理画面を提供します。
本書では、VMware ESXi上で動作するNutanixについて技術的な詳細を掘り下げていきます。
チャプター
- VMware vSphereのアーキテクチャー
- NutanixにおけるvSphereの動作の仕組み
- VMware ESXiのアドミニストレーション
VMware vSphereのアーキテクチャー
ESXiのノード アーキテクチャー
ESXiを導入した場合、コントローラーVM (CVM) はVMとして稼動し、ディスクはVMダイレクトパスI/Oを使用するようになります。これによって、PCIコントローラー(および付属デバイス)のパススルーが完全に可能となり、ハイパーバイザーを迂回してCVMに直接繋がるようになります。
ESXiの最大構成と拡張性
以下の最大構成と拡張制限が適用されます:
- 最大クラスタサイズ:48
- VMあたりの最大vCPU数: 256
- VMあたりの最大メモリ: 6TB
- 最大仮想ディスクサイズ: 62TB
- ホストあたりの最大VM数: 1,024
- クラスタあたりの最大VM数: 8,000(HAが有効な場合、データストアあたり2,048)
注意: vSphere 7.0とAOS 6.8時点の情報です。 他のバージョンについてはAOSのConfiguration MaximumsとESXのConfiguration Maximumsを参照してください。
プロからのヒント
ESXiホストでベンチマークを行う場合、常にESXiホストのパワーポリシーを「ハイパフォーマンス(High performance)」に設定してテストを行います。 これで P-States および C-States を無効化し、テスト結果を人為的に制限しないようにします。
ESXiのネットワーク
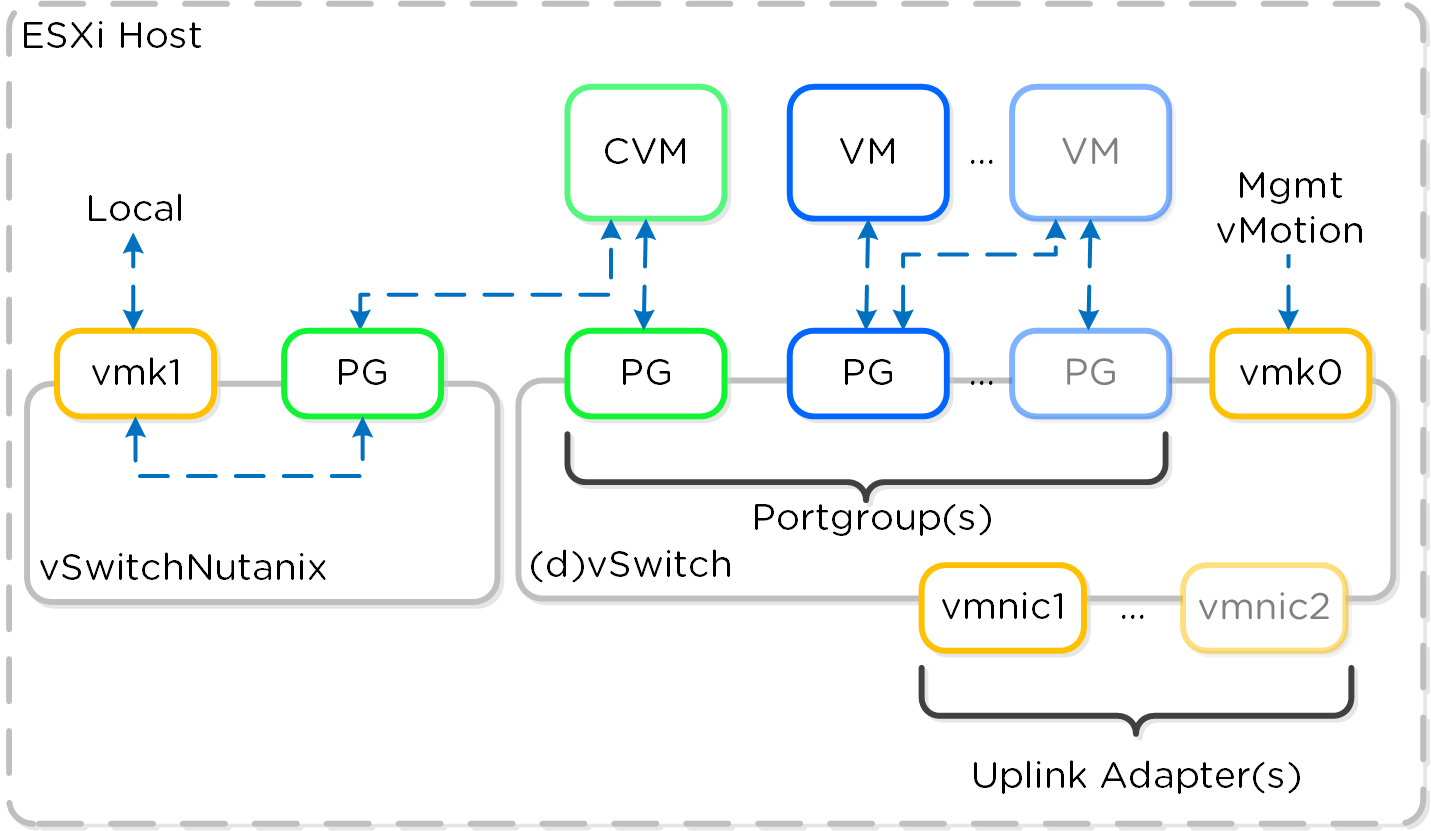
各ESXiホストにはローカルvSwitchがあり、Nutanix CVMとホストの、ホスト内部通信に使用されます。 外部やVMとの通信には、標準のvSwitch(デフォルト)またはdvSwitchが使用されます。
ローカルvSwtich(vSWitchNutanix)は、Nutanix CVMとESXiホスト間の通信のためのものです。 ホスト上のこのvSwitchにはVMkernelインターフェイス(vmk1-192.168.5.1)があり、CVMにはこの内部スイッチのポートグループにバインドされるインターフェイス(svm-iscsi-pg - 192.168.5.2)があります。 これが基本的なストレージの通信パスになります。
外部接続するvSwitchは、標準のvSwitch(標準仮想スイッチ)またはdvSwitch(分散仮想スイッチ)です。 これはESXiホストとCVMの外部インターフェイスをホストすると同時に、ホスト上のVMに使用されるポートグループもホストします。 外部のvmkernelインターフェイスは、ホスト管理やvMotionなどに使用されます。 外部CVMインターフェイスは、他のNutanix CVMとの通信に利用されます。 トランク上でVLANが有効になっていれば、必要に応じてポートグループが作成できます。
以下は、vSwitchアーキテクチャーの概念的な構造を図示したものです:
アップリンクとチーミングポリシー
デュアルToRスイッチを使用して、スイッチHAのために、両スイッチをクロスしたアップリンク構成をとることを推奨します。システムは、デフォルトでアップリンクインターフェイスをアクティブ/パッシブモードで使用します。アップストリームのスイッチアーキテクチャーが、アクティブ/アクティブなアップリンクインターフェイス(例えば、vPCやMLAGなど)に対応していれば、より高いネットワークスループットを得るためにこれを使用することができます。
NutanixにおけるvSphereの動作の仕組み
アレイオフロード - VAAI
Nutanixプラットフォームは、VMware API for Array Integration(VAAI)をサポートし、ハイパーバイザーのタスクをアレイにオフロードすることができます。 ハイパーバイザーが「仲介役」を果たす必要がなくなるため、より効率的になります。 現在Nutanixでは、「フルファイルクローン(full file clone)」、「ファストファイルクローン(fast file clone)」および「リザーブスペース(reserve space)」プリミティブを含む、NAS向けVAAIプリミティブをサポートしています。 各種プリミティブの優れた説明がこちらにあります: http://cormachogan.com/2012/11/08/vaai-comparison-block-versus-nas/
フルクローンとファストファイルクローンの場合、DSFの「ファストクローン」が完了すると、 (re-direct on writeを使って)各クローンに対する書き込み可能なスナップショットが生成されます。 各クローンは自身のブロックマップを持っているので、チェーンの深さを気にする必要はありません。 VAAIを使用するか否かは、以下の要素で決まります。
- スナップショットありのVMのクローン → VAAIは使用しない
- スナップショットなしの未稼動のVMのクローン → VAAIを使用
- 異なるデータストア/コンテナに対するVMのクローン → VAAIは使用しない
- 稼動中のVMのクローン → VAAIは使用しない
VMware Viewの場合、次の方針になります:
- View Full Clone(スナップショットありのテンプレート) → VAAIは使用しない
- View Full Clone(スナップショットなしのテンプレート) → VAAIを使用
- View Linked Clone (VCAI) → VAAIを使用
VAAIの動作は、Activity Traceページの「NFS Adapter」を使って確認できます。
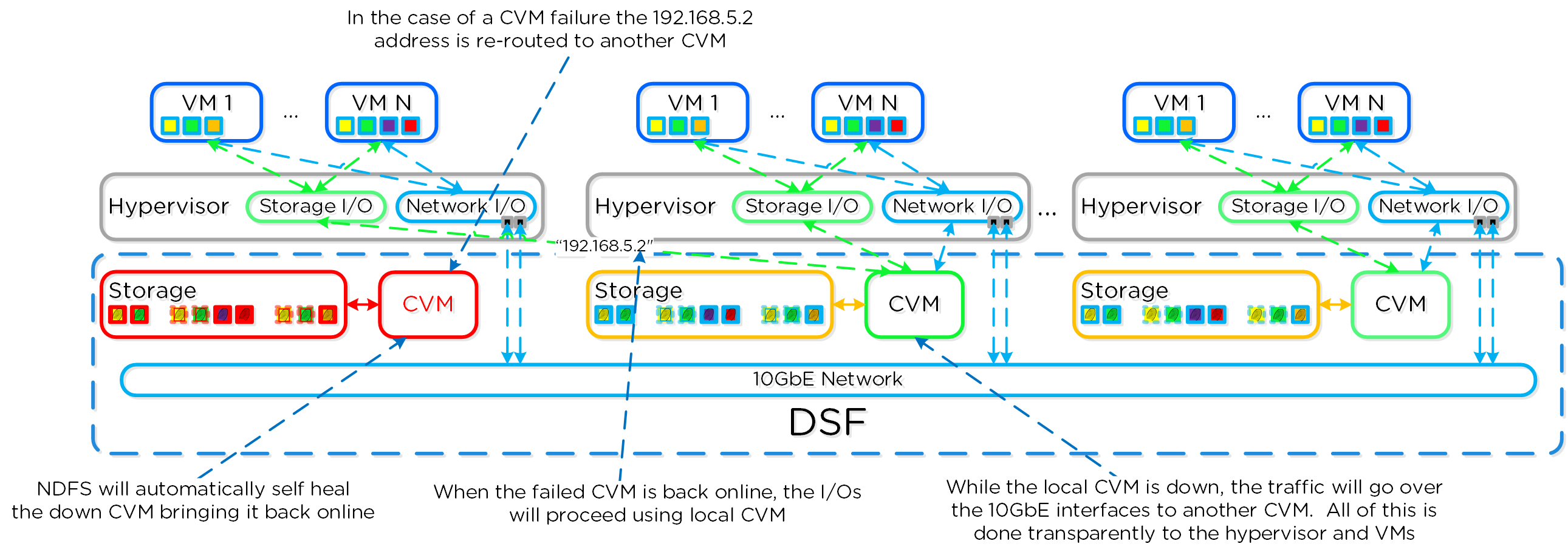
CVM Autopathing(Ha.pyとしても知られる)
本セクションでは、CVMの「障害」がどのように処理されるかについて説明します(コンポーネントの障害対応については、後日説明を追加します)。 ここではCVMの「障害」とは、ユーザーによるCVMの停止、CVMのローリングアップグレードなど、CVMを停止させる全てのイベントを含みます。 DSFには自動パス切りかえ(autopathing)と呼ばれる機能があり、ローカルCVMが利用不可になった場合、I/Oはクラスタ上の異なるCVMによって透過的に処理されます。 ハイパーバイザーとCVMは、専用のvSwitch(詳細は前述参照)上のプライベートの192.168.5.0ネットワークを使って通信します。 つまり、全てのストレージI/Oは、CVMの内部IPアドレス(192.168.5.2)を使って行われるということです。 CVMの外部IPアドレスは、リモートレプリケーションやCVMの通信に使用されます。
以下にこの状態を図示しました:
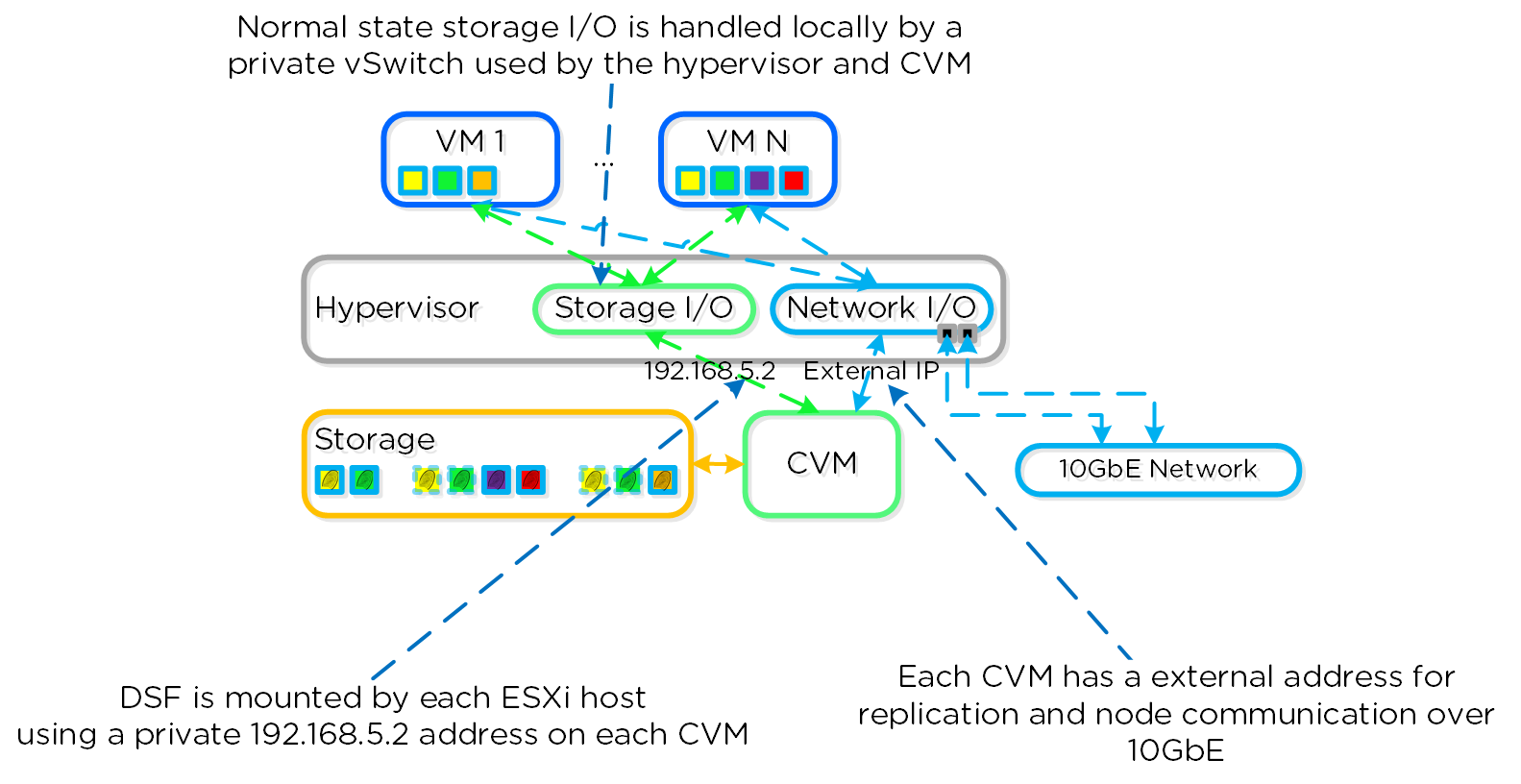
ローカルCVMで障害が発生した場合、それまでローカルCVMにホストされていたローカルの192.168.5.2アドレスは使用不可能になります。DSFは自動的にこの障害を検知し、10GbE経由でI/Oをクラスタ内の異なるCVMにリダイレクトします。この経路変更は、そのホストで稼動するハイパーバイザーやVMに対して透過的に行われます。つまり、CVMが停止しても、VMは引き続きDSFにI/Oが可能だということです。ローカルCVMが復旧して利用可能になると、経路は透過的に元にもどされ、トラフィックはローカルCVMから提供されるようになります。
以下は、CVM障害時にどういった動きをするか図示したものです:
VMware ESXiのアドミニストレーション
仮想マシンの管理
基本的な仮想マシン管理操作は、ハイパーバイザーの管理インターフェイスを使用せずに、Prismから直接実行できます。 NutanixノードをvCenterインスタンスに追加し、vCenterをNutanixクラスタに登録(Settings → vCenter Registration)すると、Prismからダイレクトに次の操作が実行できるようになります:
- 仮想マシンの作成、クローン、設定の編集、削除
- NICの作成、削除
- ディスクの接続、削除
- 仮想マシンの電源操作(パワーオン/パワーオフ、リセット、ゲストシャットダウン、ゲスト再起動、サスペンド)
- 仮想マシン コンソールの開始
- 仮想マシンゲストツールの管理(VMware ToolsまたはNutanix Guest Tools)
ESXi コマンドリファレンス
ESXiクラスタ アップグレード
説明: CLIとカスタム オフライン バンドルを使用した、ESXiホストの自動アップグレードを実行
- Nutanix CVMに、アップグレード オフライン バンドルをアップロード
- Nutanix CVMにログイン
- アップグレードを実行
cluster --md5sum=bundle_checksum --bundle=/path/to/<offline_bundle> host_upgrade
例:
cluster --md5sum=bff0b5558ad226ad395f6a4dc2b28597 --bundle=/tmp/VMware-ESXi-5.5.0-1331820-depot.zip host_upgrade
ESXiホストサービスの再起動
説明: 各ESXiホストサービスを順次再起動
for i in `hostips`;do ssh root@$i "services.sh restart";done
ESXiホストの「Up」状態にあるNICを表示
説明: ESXiホストの「Up」状態にあるNICを表示
for i in `hostips`;do echo $i && ssh root@$i esxcfg-nics -l | grep Up;done
ESXiホストの10GbE NICとそのステータスを表示
説明: ESXiホストの10GbE NICとそのステータスを表示
for i in `hostips`;do echo $i && ssh root@$i esxcfg-nics -l | grep ixgbe;done
ESXiホストのアクティブなアダプターを表示
説明: ESXiホストのアクティブ、スタンドバイ、未使用状態にあるアダプターを表示
for i in `hostips`;do echo $i && ssh root@$i "esxcli network vswitch standard policy failover get --vswitch-name vSwitch0";done
ESXiホストのルーティングテーブルを表示
説明: ESXiホストのルーティングテーブルを表示
for i in `hostips`;do ssh root@$i 'esxcfg-route -l';done
データストアでVAAIが有効化されているかを確認
説明: データストアでVAAIが有効化されているか、サポートされているかを確認
vmkfstools -Ph /vmfs/volumes/<Datastore Name>
VIBの許容レベル(Acceptance Level)をコミュニティサポートに設定
説明: VIBのアクセプタンスレベルをCommunitySupportedに設定し、サードパーティのVIBをインストール可能にする
esxcli software acceptance set --level CommunitySupported
VIBのインストール
説明: 署名確認なしでVIBをインストール
esxcli software vib install --viburl=/<VIB directory>/<VIB name> --no-sig-check
# または
esxcli software vib install --depoturl=/<VIB directory>/<VIB name> --no-sig-check
ESXiのramdiskスペースを確認
説明: ESXi ramdiskの空きスペースを確認
for i in `hostips`;do echo $i; ssh root@$i 'vdf -h';done
pynfsログのクリア
説明: 各ESXiホストのpynfsログをクリア
for i in `hostips`;do echo $i; ssh root@$i '> /pynfs/pynfs.log';done
Hyper-V
NutanixはMicrosoft Hyper-Vをサポートしており、Hyper-V上で仮想環境を実行しながら、Nutanixの分散ストレージ ファブリックを活用することができます。
本書では、Hyper-V上で動作するNutanixについて技術的な詳細を掘り下げていきます。
チャプター
- Microsoft Hyper-Vのアーキテクチャー
- NutanixにおけるHyper-Vの動作の仕組み
- Microsoft Hyper-Vのアドミニストレーション
Microsoft Hyper-Vのアーキテクチャー
Nutanix Hyper-Vクラスタが生成されると、Hyper-Vホストは、指定されたWindows Active Directoryドメインに自動的に参加する形になります。 これらのホストは、VM HAのためフェイルオーバークラスタに組み入れられます。 以上が完了すると、それぞれのHyper-VホストとフェイルオーバークラスタにADオブジェクトが作られます。
Hyper-Vのノード アーキテクチャー
Hyper-Vを導入した場合、コントローラーVM (CVM) は、VMとして稼動しディスクはディスクパススルーを使用して提供されます。
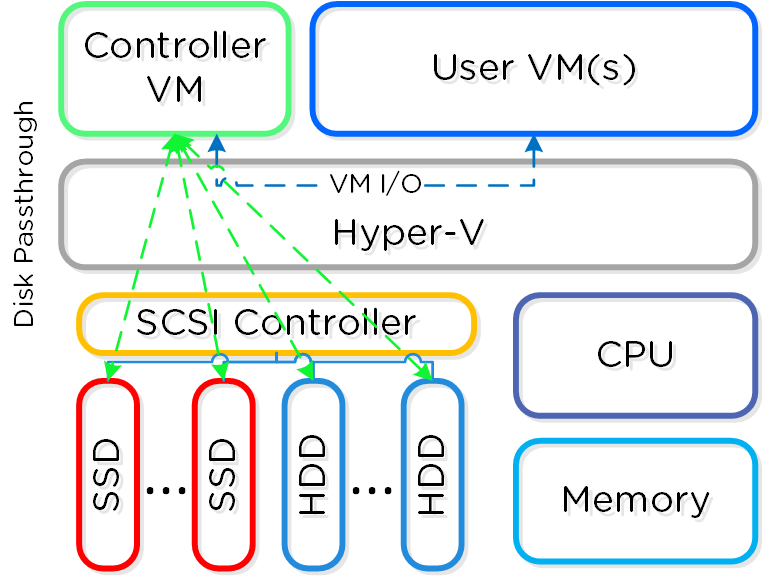
Hyper-Vの最大構成と拡張性
以下の最大構成と拡張制限が適用されます:
- 最大クラスタサイズ: 16
- VMあたりの最大vCPU数: 64
- VMあたりの最大メモリ: 1TB
- 最大仮想ディスクサイズ: 64TB
- ホストあたりの最大VM数: 1,024
- クラスタあたりの最大VM数: 8,000
注意: Hyper-V 2012 R2とAOS 6.6時点の情報です。 他のバージョンについてはConfiguration Maximumsを参照してください。
Hyper-Vのネットワーク
各Hyper-Vホストには、内部限定の仮想スイッチがあり、Nutanix CVMとホスト間の通信に使用されます。外部やVMとの通信には、外部仮想スイッチ(デフォルト)または論理スイッチが使用されます。
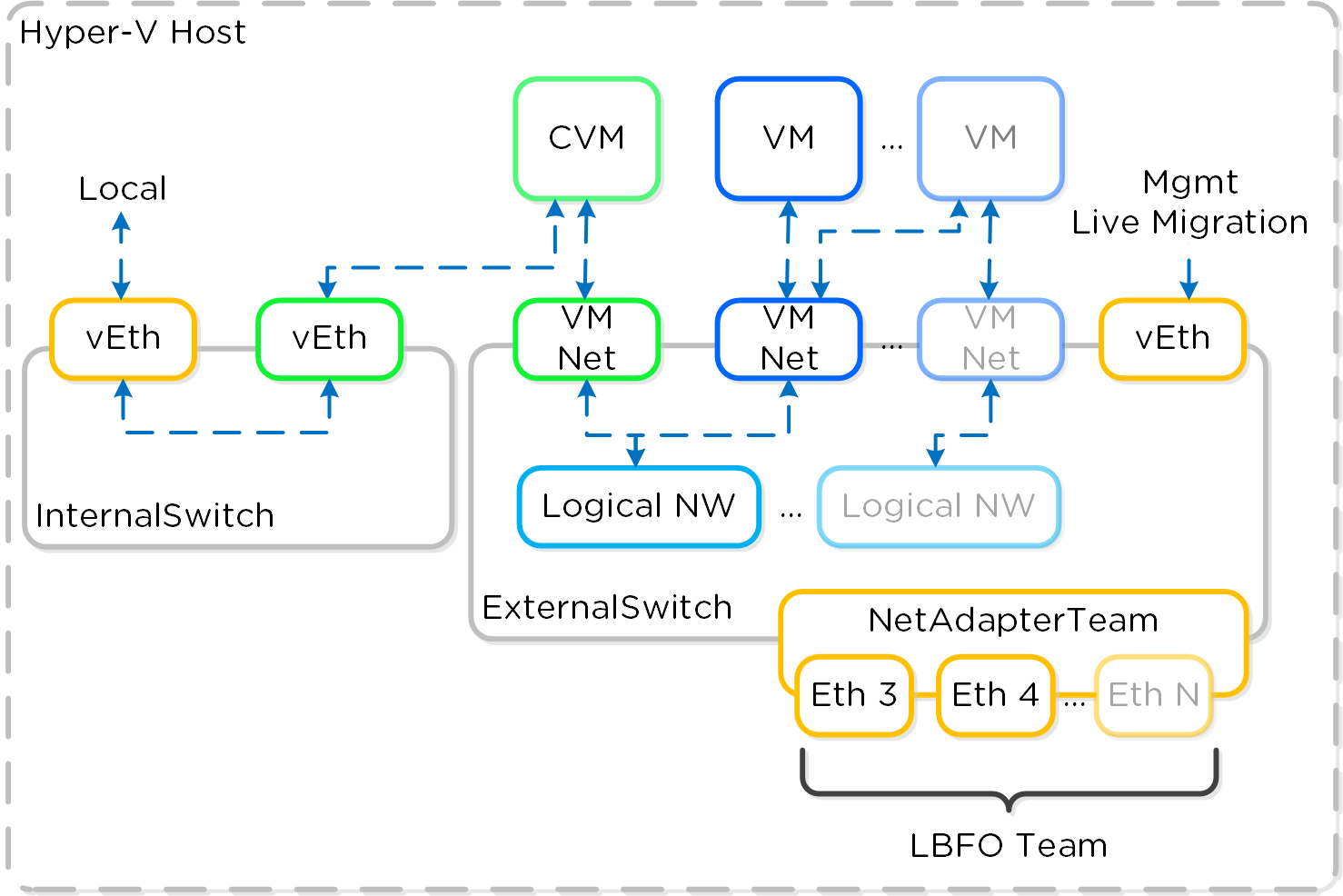
内部スイッチ (InternalSwitch) は、CVMとHyper-Vホスト間のローカル通信のためのものです。ホストは、内部スイッチ (192.168.5.1) 上に仮想イーサネットインターフェイス (vEth) を持ち、CVMは内部スイッチ (192.168.5.2) 上にvEthを持っています。これが基本的な通信パスとなります。
外部vSwitchは、標準的な仮想スイッチまたは論理スイッチでかまいません。外部vSwitchは、Hyper-VホストとCVMに加え、ホスト上のVMに使用される論理およびVMネットワークのためのインターフェイスをホストします。外部vEthインターフェイスはホスト管理、ライブマイグレーションなどに用いられます。外部CVMインターフェイスは、他のNutanix CVMとの通信に使用されます。トランク上でVLANが有効になっていれば、論理およびVMネットワークはいくつでも作成することができます。
以下は、仮想スイッチアーキテクチャーの概念的な構造を図示したものです:
アップリンクとチーミングポリシー
デュアルToRスイッチを使用し、スイッチHAのために両スイッチをクロスしたアップリンク構成をとることを推奨します。システムは、デフォルトで特別な構成を必要としないスイッチ非依存モードでLBFOチームを形成します。
NutanixにおけるHyper-Vの動作の仕組み
アレイオフロード - ODX
Nutanixプラットフォームは、Microsoft Offloaded Data Transfers(ODX)をサポートし、ハイパーバイザーのタスクをアレイにオフロードすることができます。 ハイパーバイザーが「仲介役」を果たす必要がなくなるため、より効率的になります。 現在Nutanixは、フルコピー(full copy)やゼロイング(zeroing)とSMBのためのプリミティブをサポートしています。 しかし、「ファストファイル (fast file)」クローン処理(書き込み可能なスナップショットを使用)が可能なVAAIとは異なり、ODXにはフルコピーを行うための同等なプリミティブが存在しません。 このため、現在nCLI、RESTまたはPowerShellコマンドレットから起動できるDSFクローン機能を利用する方がより効果的です。 現在のところ、ODXは以下の処理に使用されます。:
- DSF SMBシェア上でのVM内のまたはVMからVMへのファイルコピー
- SMBシェアファイルコピー
SCVMMライブラリ(DSF SMBシェア)からテンプレート導入
注意: シェアは、ショートネーム(つまりFQDNではない)を使用して、SCVMMクラスタに追加する必要があります。 これを簡単に行うには、クラスタのhostsファイル(つまり10.10.10.10 nutanix-130)にエントリーを追加します。
ODXは以下の処理には使用できません:
- SCVMMによるVMのクローン
- SCVMMライブラリ(非DSF SMBシェア)からテンプレート導入
- XenDesktopクローンの導入
ODXの稼動状態は、Activity Traceページの「NFS Adapter」を使って確認できます(SMB経由で実行されますが、NFSです)。 vDiskのコピー状態は「NfsWorkerVaaiCopyDataOp」、ディスクのゼロイング(zeroing)状態は「NfsWorkerVaaiWriteZerosOp」で表示されます。
Microsoft Hyper-Vのアドミニストレーション
Hyper-Vの重要なページ
近日公開!
Hyper-V コマンドリファレンス
複数のリモートホストでコマンドを実行
説明: 特定のまたは複数のリモートホストで PowerShellを実行
$targetServers = "Host1","Host2","Etc"
Invoke-Command -ComputerName $targetServers {
<COMMAND or SCRIPT BLOCK>
}
使用可能なVMQオフロードを確認
説明: 指定したホストで使用可能なVMQオフロードの数を表示
gwmi -Namespace "root\virtualization\v2" -Class Msvm_VirtualEthernetSwitch | select elementname, MaxVMQOffloads
特定のプリフィックスに一致するVMのVMQを無効化
説明: 特定のVMに対するVMQを無効化
$vmPrefix = "myVMs"
Get-VM | Where {$_.Name -match $vmPrefix} | Get-VMNetworkAdapter | Set-VMNetworkAdapter -VmqWeight 0
特定のプリフィックスに一致するVMのVMQを有効化
説明: 特定のVMに対するVMQを有効化
$vmPrefix = "myVMs"
Get-VM | Where {$_.Name -match $vmPrefix} | Get-VMNetworkAdapter | Set-VMNetworkAdapter -VmqWeight 1
特定のプリフィックスに一致するVMを起動
説明: 特定のプリフィックスに一致するVMを起動
$vmPrefix = "myVMs"
Get-VM | Where {$_.Name -match $vmPrefix -and $_.StatusString -eq "Stopped"} | Start-VM
特定のプリフィックスに一致するVMをシャットダウン
特定のプリフィックスに一致するVMをシャットダウン
$vmPrefix = "myVMs"
Get-VM | Where {$_.Name -match $vmPrefix -and $_.StatusString -eq "Running"}} | Shutdown-VM -RunAsynchronously
特定のプリフィックスに一致するVMを停止
特定のプリフィックスに一致するVMを停止
$vmPrefix = "myVMs"
Get-VM | Where {$_.Name -match $vmPrefix} | Stop-VM
Hyper-VホストRSSの設定の確認
説明: Hyper-VホストRSS (Receive Side Scaling) の設定の確認
Get-NetAdapterRss
WinshとWinRMのコネクティビティの確認
説明: WinshとWinRMのコネクティビティおよびステータスを、サンプルクエリを発行して確認。コンピューターシステムオブジェクトを返さない場合はエラーと判断。
allssh 'winsh "get-wmiobject win32_computersystem"'
Hyper-Vの指標値としきい値
近日公開!
Hyper-Vのトラブルシューティングと高度な管理
近日公開!
Backup / DR Services
確実なバックアップ戦略を持つことは、インフラストラクチャー設計において不可欠です。 本書では、ポリシー駆動型のバックアップ、DR、およびランブックによる自動化を提供するNutanix Disaster Recoveryの詳細について説明します。
チャプター
- Nutanix Disaster Recovery (ポリシー駆動型DR / ランブック)
Nutanix Disaster Recovery (ポリシー駆動型DR / ランブック)
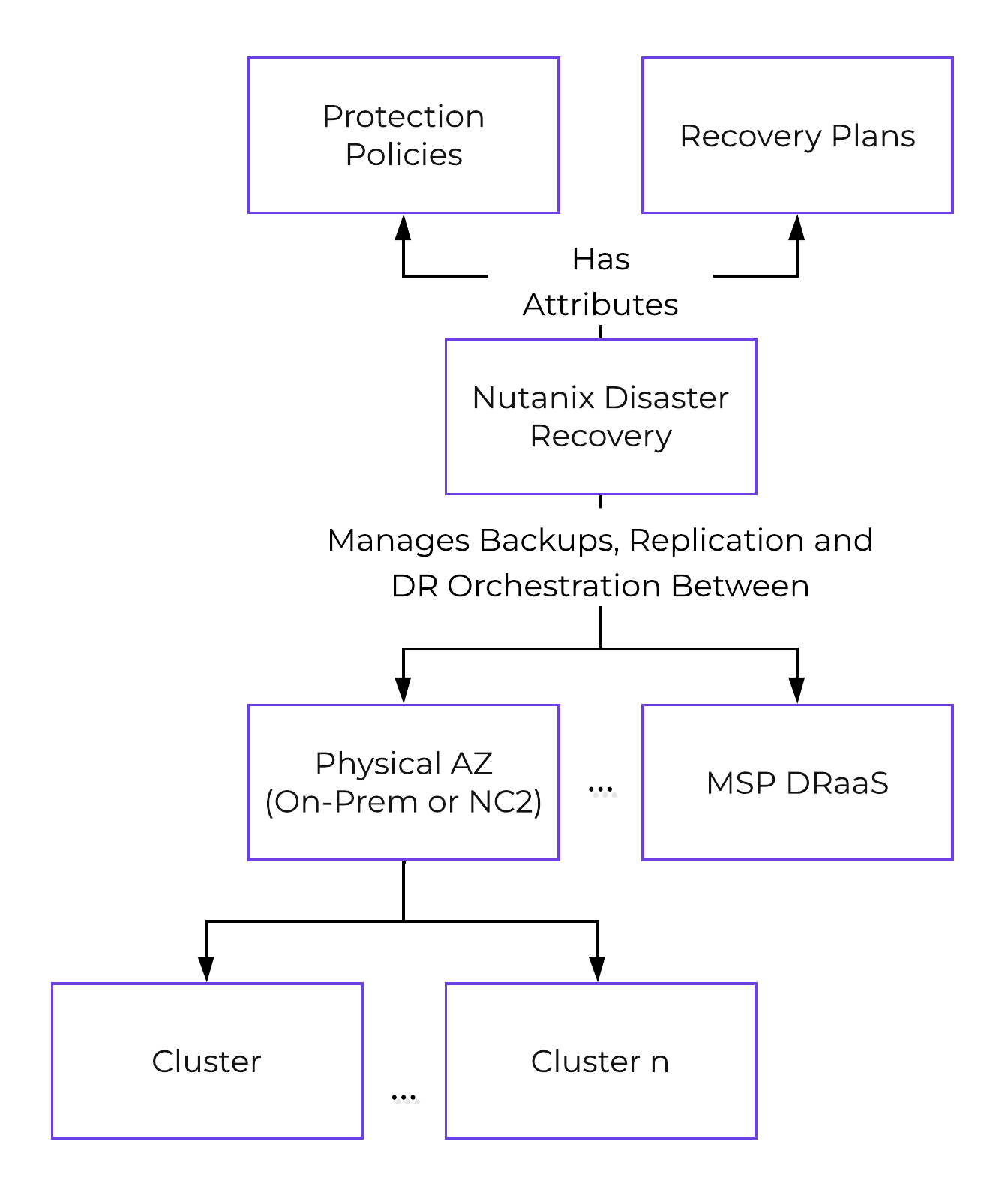
Nutanix Disaster Recoveryの機能では、Prism Central(PC)に構成された、ポリシー駆動型のバックアップとDR、およびランブックによる自動化サービスを提供します。 この機能は長年にわたりAOSで利用可能でありPEで設定される、ネイティブDRおよびレプリケーション機能を基盤としており、それを拡張するものです。 レプリケーションなどに活用されている実際のバックエンドメカニズムの詳細については、「AOS」の「バックアップと災害復旧」セクションを参照してください。
サポートされる構成
ソリューションは以下の構成に適用できます(リストは不完全な場合があります。サポートされているものの完全なリストについては、ドキュメントを参照してください):
主なユースケース:
- ポリシーベースのバックアップとレプリケーション
- ランブックによるDR自動化
- DRaaS(マネージド サービス プロバイダーによる)
管理インターフェイス:
- Prism Central (PC)
サポートされている環境:
-
オンプレミス:
- AHV
- ESXi
- クラウド:
- NC2(AWS と Azure)
- MST(パイロットライトまたはゼロコンピュート)
アップグレード:
- AOSの一部
互換性のある機能:
- AOSの事業継続およびDR機能
主な用語
このセクション全体で使用される主な用語、以下のように定義されています:
- 復旧時点目標(RPO:Recovery Point Objective)
- 障害が発生した場合の許容可能なデータ損失を指します。 例えば、1時間のRPOが必要な場合は、1時間ごとにスナップショットを作成します。 復旧では、最大1時間前のデータをリストアします。 同期レプリケーションの場合、通常はRPOが0になります。
- 目標復旧時間(RTO:Recovery Time Objective)
- 障害発生からサービスの復旧までの期間を指します。 例えば、障害が発生してから30分でバックアップを戻して稼働状態にする必要がある場合、RTOは30分になります。
- リカバリーポイント(Recovery Point)
- 復元のポイントであり、別名はスナップショット。
実装の構造
Nutanix Disaster Recoveryには、いくつかの重要な構成要素があります:
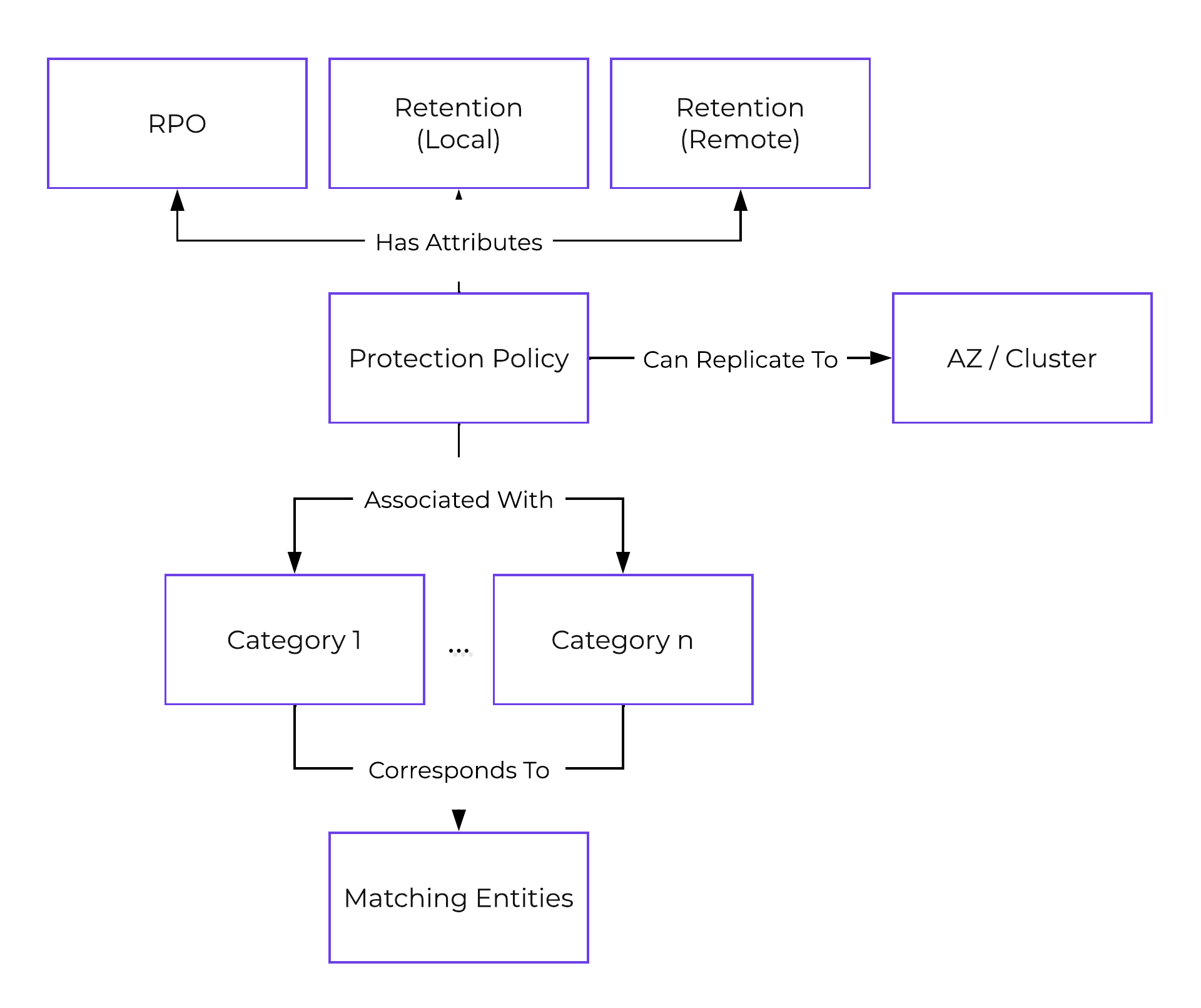
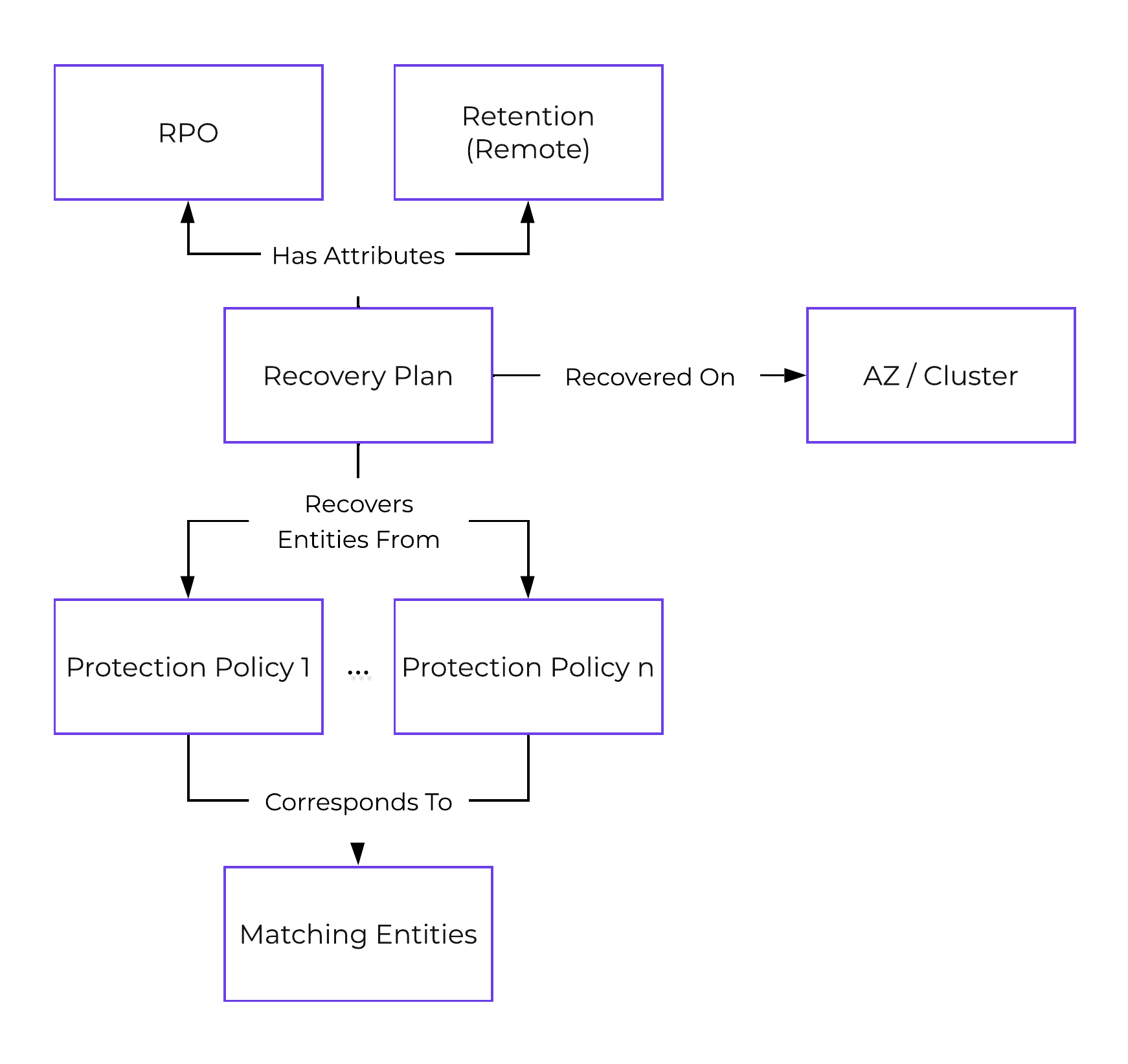
保護ポリシー(Protection Policy)
- 主な役割: カテゴリを割り当てる、バックアップとレプリケーションのポリシー
- 説明: 保護ポリシーは、RPO(スナップショット頻度)、リカバリー先の場所(リモートクラスタ)、スナップショット保持(ローカルクラスタ対リモートクラスタ)、そして割り当てるカテゴリを定義します。 保護ポリシーを使用すると、すべてがカテゴリレベルで適用されます(デフォルトでは、Any / Allに適用できます)。 これは、仮想マシンを選択する必要がある保護ドメイン(Protection Domain)とは異なります。
下記の図は、保護ポリシーの構造を示します:
リカバリープラン
- 主な役割: DR ランブック
- 説明: リカバリープランは、パワーオンの順序(カテゴリまたは仮想マシン/VGを指定可能)およびネットワークのマッピング(プライマリ、リカバリおよびテストサイトにおける、フェイルオーバーとフェイルバック)を定義するランブックです。 これはSRMを利用することと同義です。 注: リカバリープランを構成する前に、保護ポリシーを構成する必要があります。 これは、復旧のためには、データがリカバリサイトに存在する必要があるために必要です。
以下の図は、リカバリープランの構造を示します:
リニア保持ポリシー(Linear Retention Policy)
- 主な役割: リカバリーポイントの保持ポリシー
- 説明: リニア保存ポリシーは、保持するリカバリーポイントの数を指定します。 例えば、RPOが1時間で、保持が10に設定されている場合、10時間(10 x 1時間)のリカバリーポイント(スナップショット)を保持します。
ロールアップ保持ポリシー(Roll-up Retention Policy)
- 主な役割: リカバリーポイントの保持ポリシー
-
説明: ロールアップ保持ポリシーは、RPOと保存期間に応じて「ロールアップ」スナップショットを作成します。
例えば、RPOが1時間で保持期間が5日に設定されている場合、1日保持の1時間ごとの、そして5日間の最新の日次リカバリーポイントが保持されます。
ロジックは次のようになります:
- 保持期間がn日の場合、RPOは1日で、n日分の最新のリカバリーポイントを保持します。
- 保持期間がn週間の場合、RPOは1日で、1週間分の日次リカバリーポイント、n個の最新の週次リカバリーポイントを保持します。
- 保持期間がnか月の場合、RPOは1日で、1週間分の日次リカバリーポイント、1か月分の週次リカバリーポイント、nか月間の月次リカバリーポイントを保持します。
- 保持期間がn年の場合、RPOは1日で、1週間分の日次リカバリーポイント、1か月分の週次リカバリーポイント、1年間の月次リカバリーポイント、n個の最新の年次リカバリーポイントを保持します。
リニア保持ポリシー対ロールアップ保持ポリシー
保持期間が短い小さなRPOウィンドウや、常に特定のRPOウィンドウに復旧できるようにする必要がある場合には、リニア保持ポリシーを使用します。
保持期間が長いものにはロールアップ保持ポリシーを使用します。 柔軟性が高く、スナップショットのエージングやプルーニングを自動処理すると同時に、運用開始時むけの期間の細かいRPOを提供します。
以下に、Nutanix Disaster Recoveryの構成の概要を示します:
使用方法と構成
このセクションでは、Nutanix Disaster Recoveryを構成して利用する方法について説明します。
おおまかなプロセスは、以下の手順となります:
- アベイラビリティ ゾーン(AZ)に接続する
- 保護ポリシーを構成する
- リカバリープランを構成する
- 実行またはテストとしての、フェイルオーバーとフェイルバック
アベイラビリティ ゾーンへの接続
最初の手順は、別のAZに接続することで、これはオンプレミスのAZ、またはクラウドにあるNC2です。
PCで「Availability Zones」を検索するか、「管理」→「Availability Zones」に移動します:
「アベイラビリティ ゾーンに接続」をクリックして、アベイラビリティ ゾーン タイプ(「DRaaS Domain」またはPCインスタンスである「Physical Location」)を選択します。
PCまたはDRaaS Domainの資格情報を入力し、「接続」をクリックします。
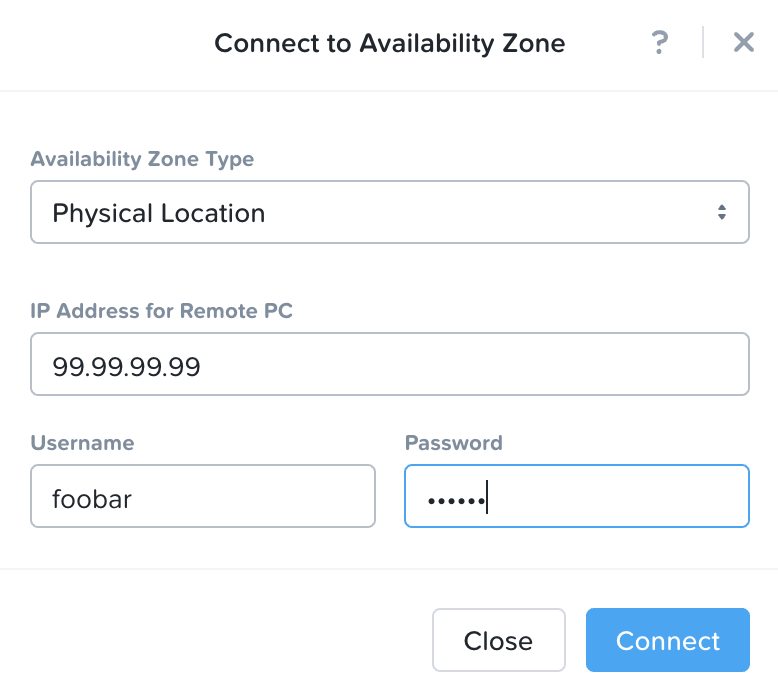
接続されたAZが表示され、使用できるようになります。
保護ポリシーの構成
PCで「Protection Policies」を検索するか、「Data Protection」→「Protection Policies」に移動します。
「Create Protection Policy」をクリックします。
設定したい名前を入力し、ソースのAZとクラスタを選択して 「保存」をクリックします。 リカバリーロケーションのAZとクラスタを選択して、「保存」をクリックします。
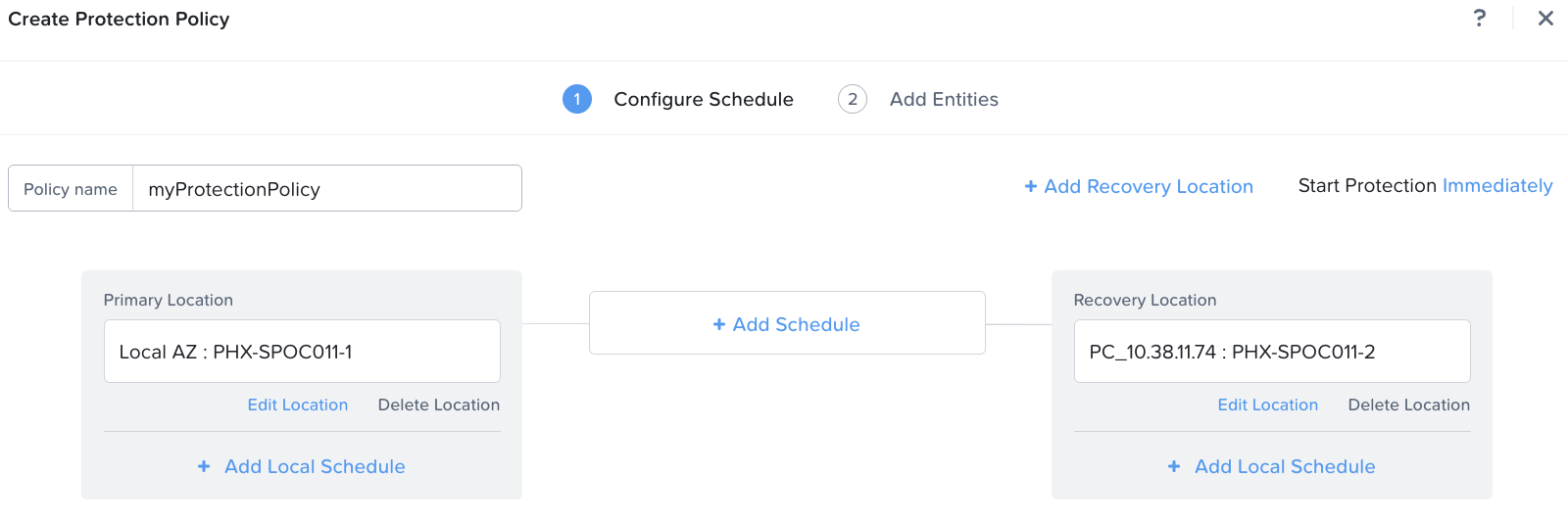
プライマリとリカバリーロケーションの間にある「Add Schedule」をクリックし、スナップショットやレプリケーションの頻度、保持期間、その他の詳細を追加します。
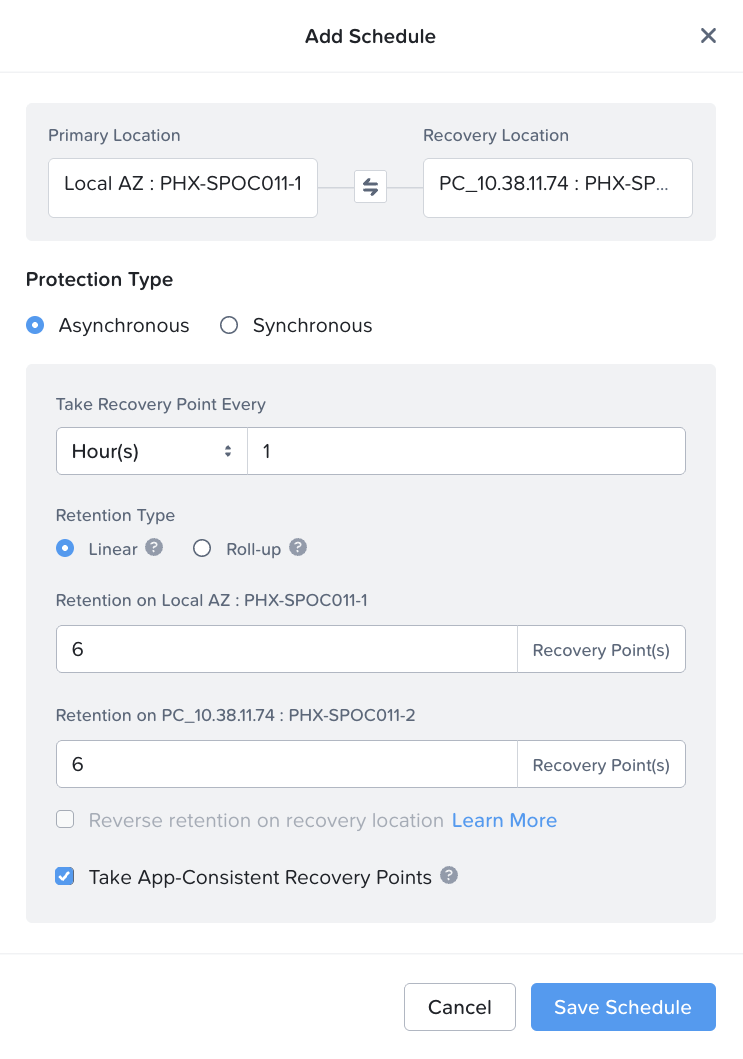
次に、ポリシーを適用するカテゴリを選択します。
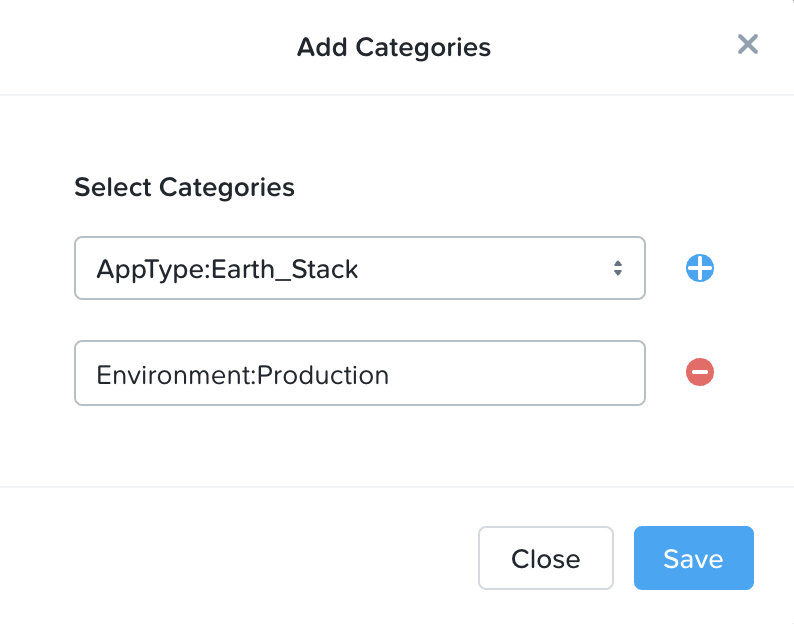
「作成」をクリックすると、新しく作成された保護ポリシーが表示されます。

リカバリープランの構成
PCで「リカバリー プラン」を検索するか、「Data Protection」→「Recovery Plans」に移動します。
最初の起動時に、最初のリカバリープランを作成するための画面が表示されます。
ドロップダウンを使用して「リカバリーロケーション」を選択します:
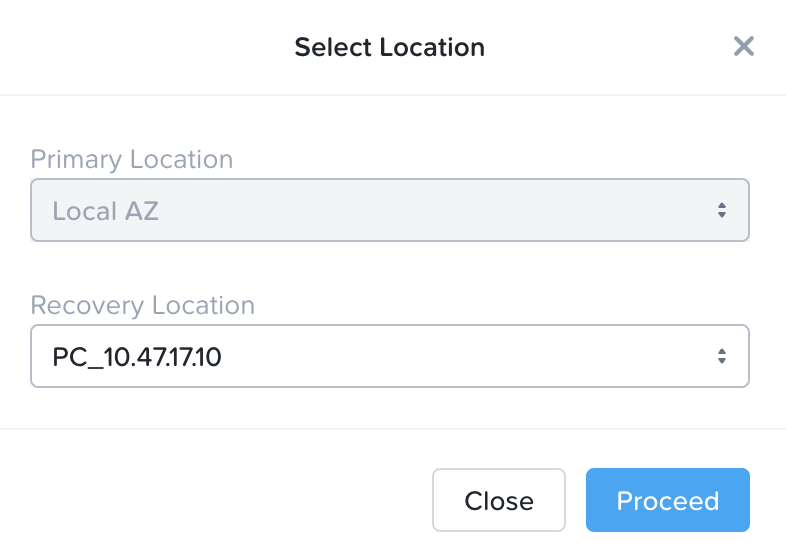
注:これは、DRaaS DomainのAZまたはPhysical AZ(対応する管理対象クラスタを持つPC)のいずれかです。
リカバリープランの名前と説明を入力し、「次へ」をクリックします。
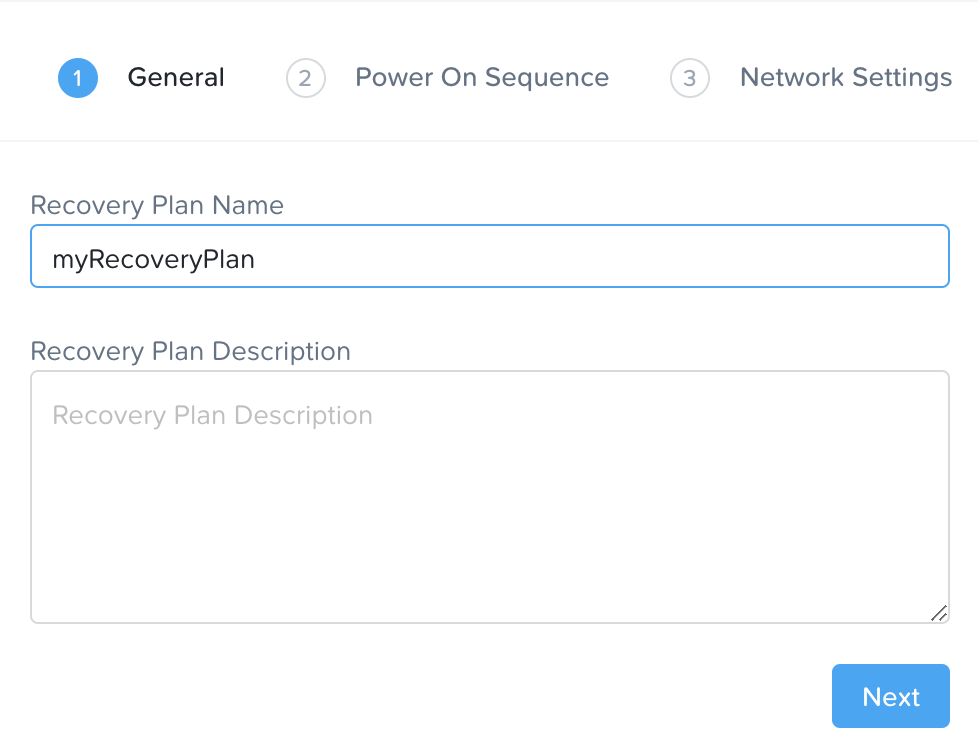
次に「+ VM(s)」をクリックして、パワーオンのシーケンスを指定します。
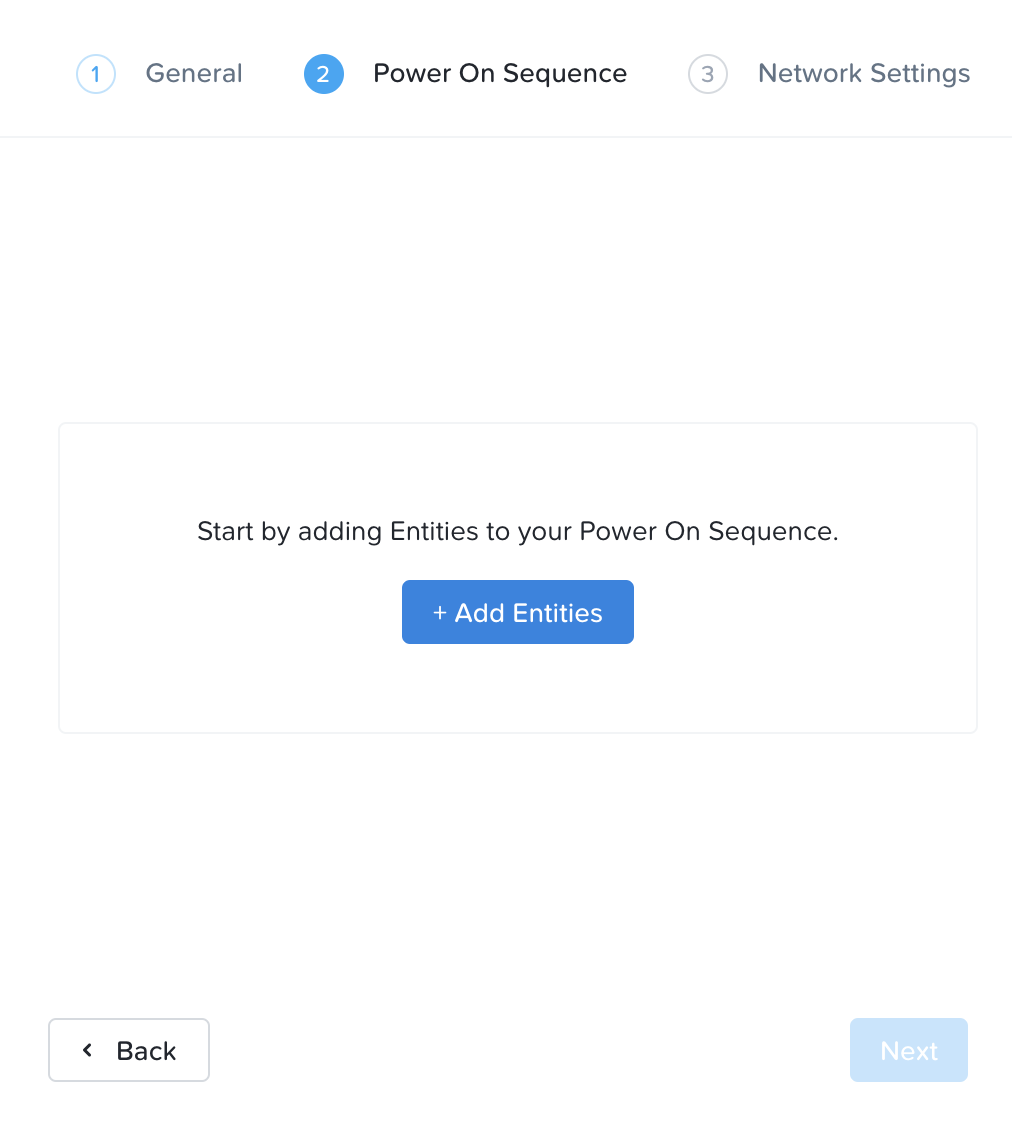
仮想マシン名またはカテゴリを検索して、各ステージに追加します。
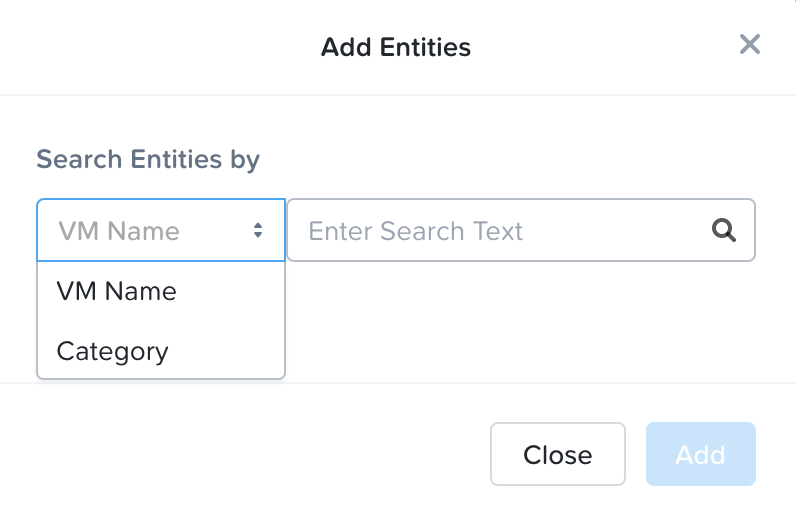
各ステージのPower On Sequenceが適切になったら、「次へ」をクリックします。
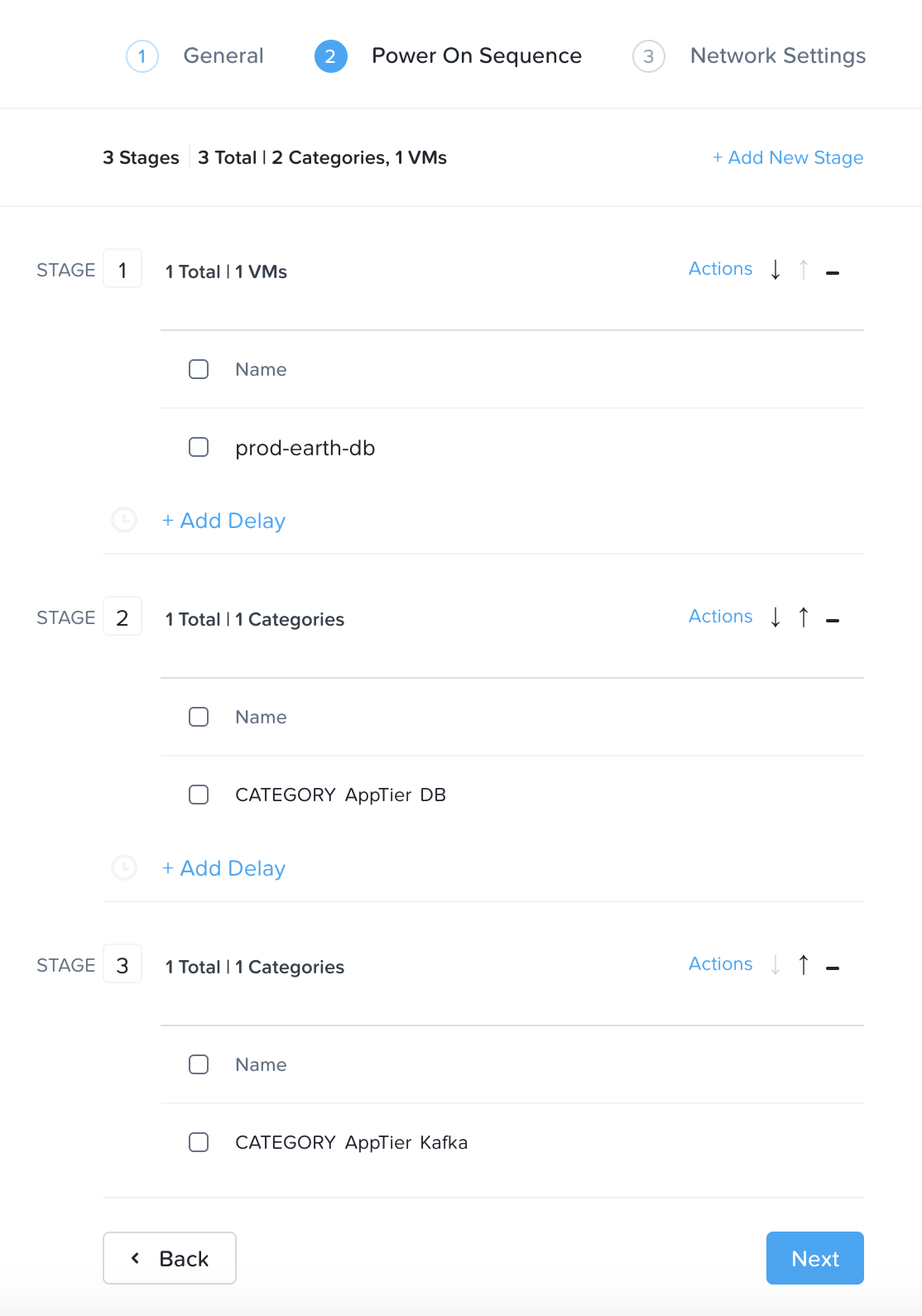
パワーオンのシーケンス
Power On Sequenceを決定するときは、次のようにステージ設定する必要があります:
- Stage 0: Core サービス (AD、DNSなど)
- ステージ1: ステージ0サービスに依存し、ステージ2サービスに必要なサービス(例えばDB層)
- ステージ2: ステージ1サービスに依存し、ステージ3サービスに必要なサービス(例えばApp層)
- ステージ3: ステージ2サービスに依存し、ステージ4サービスに必要なサービス(例えばWeb層)
- ステージ4-N: 依存関係に基づいて繰り返す
次に、ソースとターゲットの環境の間でネットワークをマッピングします。
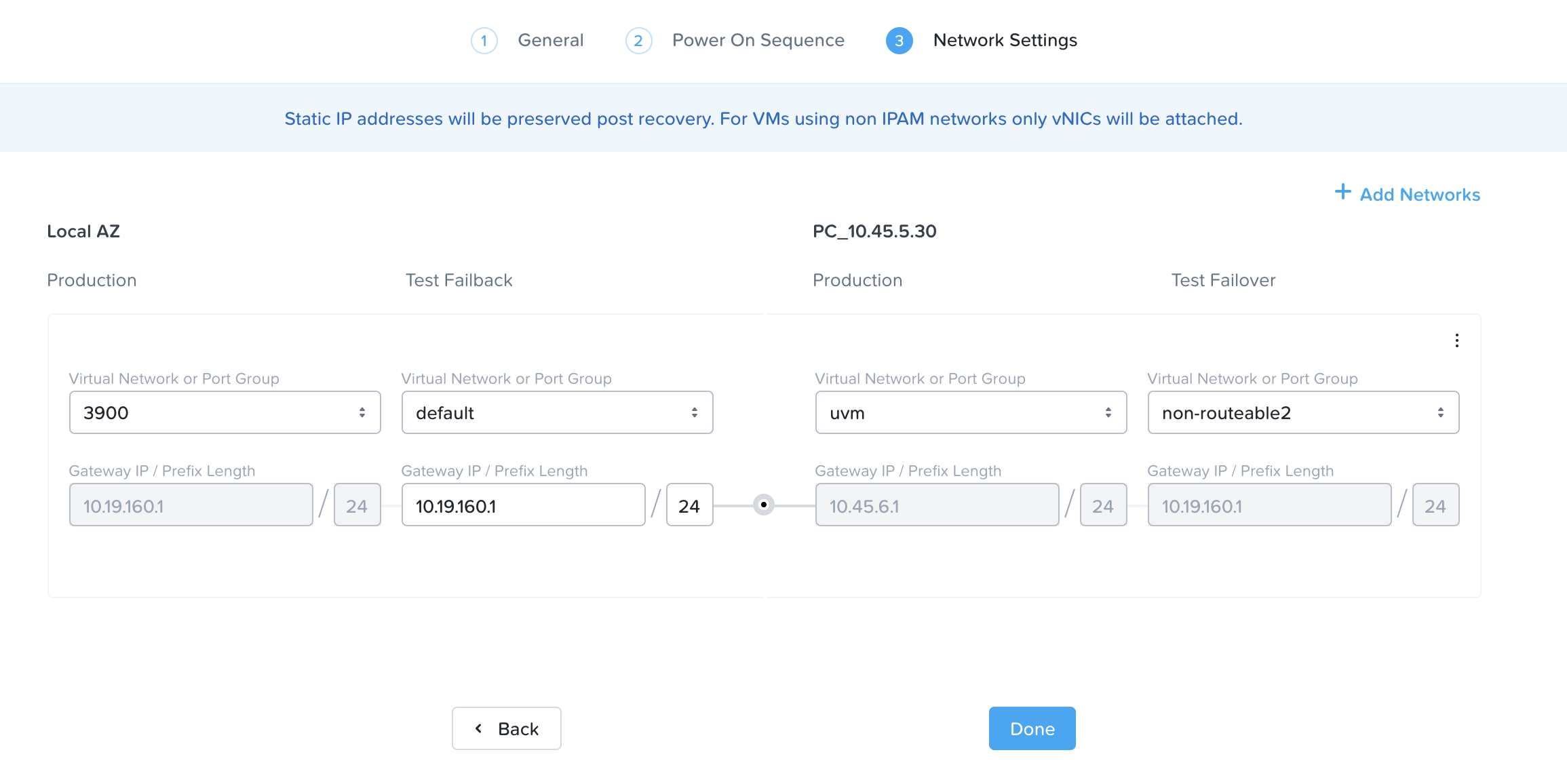
フェイルオーバーおよびフェイルバックのネットワーク
ほとんどの場合で、テストネットワークには、ルーティング不可能な、または分離されたネットワークを使用します。 これにより、SIDの重複、ARPエントリーなどの問題が発生しなくなります。
Nutanixへの移行
Nutanix Move
Nutanix Move(または単にMove)は、仮想マシン(VM)やファイル サーバーを最小限のダウンタイムで移行する、クロス ハイパーバイザー モビリティ ソリューションです。 MoveはNutanixの顧客に無料で提供されており、Nutanix Support Portal からダウンロードできます。
仮想マシン移行の手法
Moveを使用することで、インフラストラクチャー中心(Infrastructure Centric)の移行とアプリケーション中心(Application Centric)の移行を選択できます。
- インフラストラクチャー中心の移行は、従来のインフラストラクチャーとNutanix Cloud Platformが同じVLANにアクセスできる場合に適しています。
- アプリケーション中心の移行は、アプリケーションや、そのアプリケーションをサポートするすべてのサーバー(ファイル サーバーやデータベースなど)を移行したい場合に適しています。
Nutanix Moveに関する詳細は、以下のリソースをご覧ください:
- Nutanix.com の、アプリケーションのクラウド移行 ソリューション ページ
- デモ: Nutanix Move Overview
本書では、以下のチャプターでNutanix Moveのアーキテクチャーと移行について解説します。
チャプター
- 仮想マシンの移行
- 仮想マシン移行のアーキテクチャー
- ファイル サーバーのマイグレーション
仮想マシンの移行
Note
Nutanix Moveを使用した仮想マシン移行のハンズオンに興味がありますか? Nutanix Test Driveで試してみましょう!
https://www.nutanix.com/test-drive-migrate-applicationsNutanix Moveは、ESXiやHyper-Vなどのさまざまなハイパーバイザーから、またはAWS EC2、VMware Cloud(VMC)on AWS、Microsoft Azureから、Nutanix Cloud Platformに仮想マシンを移行できます。 サポートされている移行の最新リストについては、Move User Guide をご確認ください。
Moveでは、仮想マシンの移行にむけて、さまざまな移行プランを作成できます。 以下は、仮想マシン移行プランのベスト プラクティスです。
仮想マシン移行のベスト プラクティス
- 移行対象となる仮想マシンのグループ化
- 複数のホストから並列で移行
- 移行プランごとに最大50台の仮想マシン
- ESXiの移行では、最大100台の仮想マシンをサポート
- スケジュールの最適化
- カットオーバー前に仮想マシンのデータを事前にシードする
- カットオーバーは初回の事前シードから1週間以内に実行する
- シード期間が長くなると、ソース仮想マシンでのディスク使用量が増加する可能性がある
- ゲストOSでの準備
- 仮想マシンの準備が失敗する2つの主な理由:UACとWinRM
- 仮想マシンの準備に関する問題をトラブルシュートするために、マニュアルモードに切り替える
- データベースサーバーの移行
- Moveは、同等(Like-for-Like)の移行をサポートしている
- データベース サーバーの移行はベスト プラクティスに従う必要があり、リプラットフォームが必要になる場合があります。
- Moveはデータベースの移行が可能ですが、移行後にベスト プラクティスを適用する必要があります。
仮想マシン移行のアーキテクチャー
Moveのアーキテクチャー
Nutanix Moveは、通常はターゲットとなるAHVクラスタにホストされる、仮想マシン アプライアンスです。 Nutanix Moveは複数のソフトウェア サービスによって構成されており、次の主要なソフトウェア コンポーネントに分類できます。
- 管理サーバー
- 管理サーバーは、ソースおよびターゲットクラスタの情報、移行プランの詳細、および現在のステータスを保持します。 また、APIやUIを使用して移行プランを作成および管理できます。
- ソースおよびターゲットのエージェント
- ソース エージェントは、プラットフォーム固有(ESXi、Hyper-V、AHV、またはクラウド)のソフトウェア コンポーネントであり、ディスク リーダーを通じて移行のコピー リクエストをスケジュールします。 これはソース クラスタと仮想マシンの詳細を収集しており、管理サーバーのUIを使用して移行する仮想マシンを選択する際に役立ちます。
- ディスクのリーダーとライター
- ディスク リーダー プロセスは、ソース固有のAPIを使用してデータを読み取り、ディスク ライター プロセスと連携して未完のコピー操作を完了します。 ディスク リーダーは、コピー操作のチェックポイントを作成して障害を処理し、必要に応じて操作を再開します。
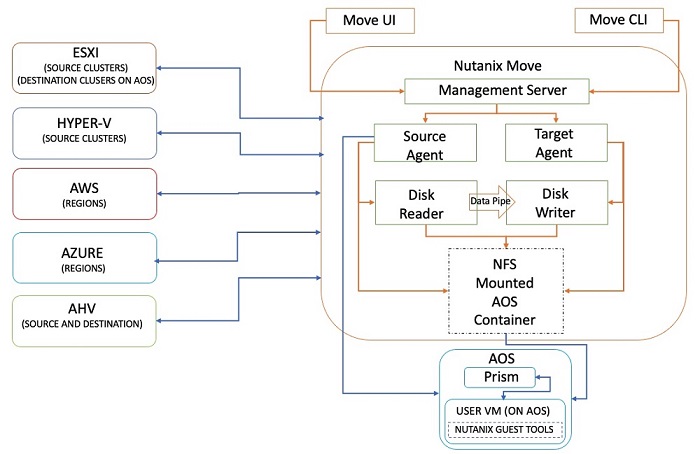
Moveが使用する各ソース環境のアーキテクチャーはわずかに異なりますが、Nutanixはその実装の違いをユーザーから見えないようにしています。
Nutanix Move for ESXi
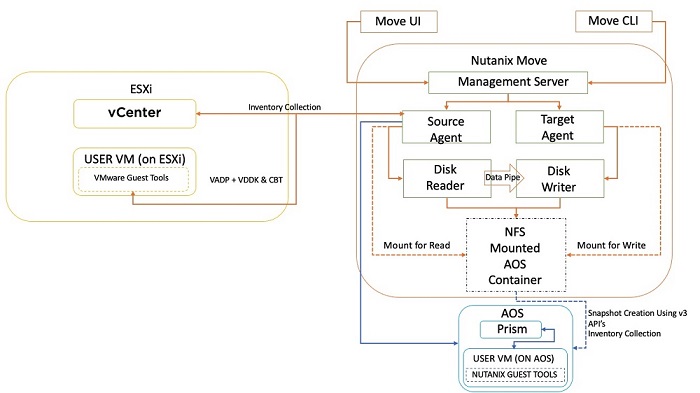
Nutanix Move for ESXiのアーキテクチャーでは、インベントリの収集にvCenterを使用し、データ移行にはvSphere Storage API for Data Protection(VADP)、Virtual Disk Development Kit(VDDK)、Changed Block Tracking(CBT)を使用します。
Nutanix Move for Hyper-V
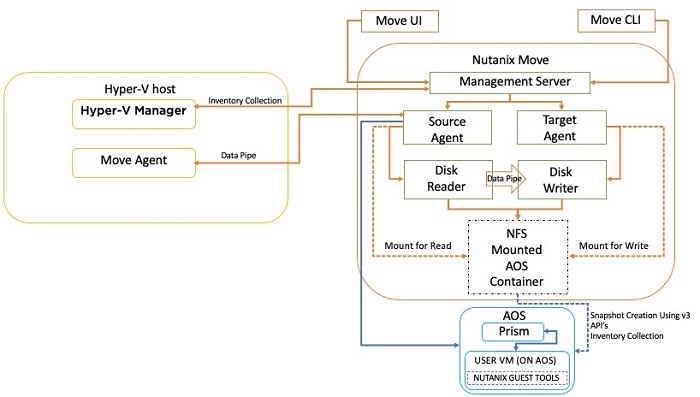
Nutanix Move for Hyper-Vのアーキテクチャーでは、Hyper-Vクラスタを構成する各Hyper-Vサーバーにエージェントが配置されています。 そして、エージェントを使用してデータを移動し、インベントリの収集にはHyper-V Managerを使用します。
Nutanix Move for AWS
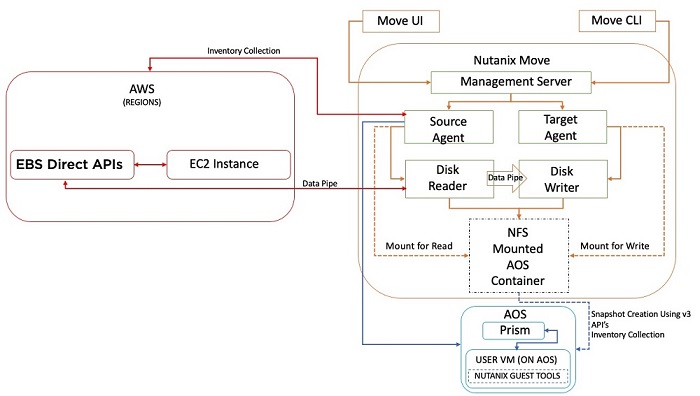
Nutanix Move for AWSのアーキテクチャは、他の環境でのMoveとは多少異なります。 AWSを環境として追加すると、Moveアプライアンスはインベントリ収集のためにAWSに接続し、データ移行にはElastic Block Store (EBS) direct APIを使用します。 Moveは、以前のバージョンで行っていたようにエージェント仮想マシンを作成しなくなりました。
Nutanix Move for Azure
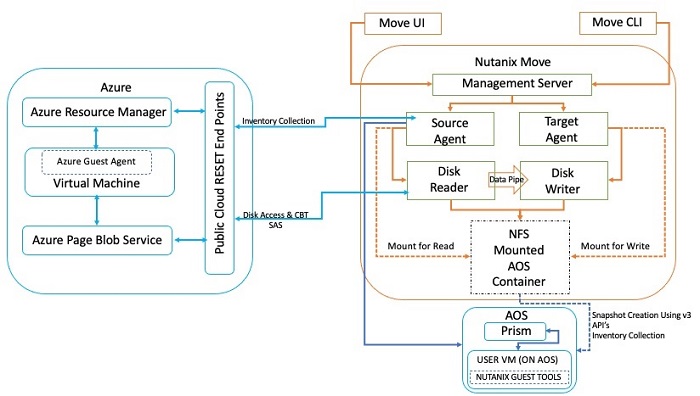
Nutanix Move for Azureのアーキテクチャは、インベントリの収集やストレージへのアクセスにAzure REST APIを使用する点で、Move for AWSのアーキテクチャと類似しています。
ファイル サーバーの移行
ファイル サーバー移行のアーキテクチャー
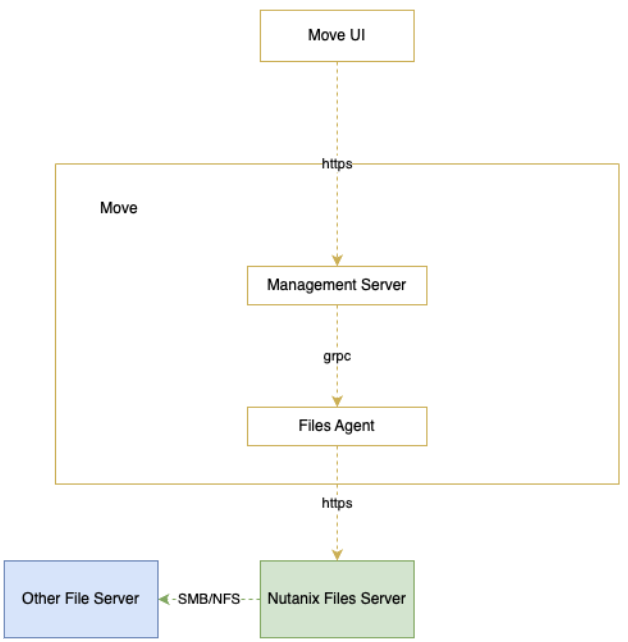
- Move はコントロールプレーンです。
- Nutanix Filesはデータプレーンです。
- MoveはNutanix Files v4 APIを使用してファイルの移行をオーケストレーションし、Nutanix FilesはSMBまたはNFSを使用してソースからデータをコピーします
- 同じMoveアプライアンスで、ファイルと仮想マシンの両方の移行を実行できます。
前提要件
Moveによるファイル移行の前提要件
- Moveバージョン5.0以降が、ファイル移行をサポートしています。
- Moveから移行先のNutanix Filesサーバーに、TCPポート9440を介して接続できる必要があります。
移行先Nutanix Filesサーバーの前提要件
- Nutanix Files 4.4以降(Migration APIのサポートはFiles 4.4で追加されました)
- ユーザー名とパスワードが設定されているAPIユーザーを作成します。
- ソースとなるサーバーへのNFS/SMBによるネットワーク アクセスは、ターゲットのNutanix Filesサーバーから行います。
- Target share should not have MaxSize (storage limit) configured ターゲット共有には、maxSizeGib(ストレージ制限)が構成されていない必要があります
SMBソース(ファイル サーバーから)の前提要件
- Backup Operatorsグループ ユーザーのユーザ名とパスワードが必要。
- SMBバージョン2以降であること。
NFSソースの前提要件
- 移行対象の共有でroot squashが無効であること。
- 移行対象の共有でAUTH_SYSがサポートされていること。
- NFS V3がサポートされていること。
ベスト プラクティス
- 現在、5つの同時移行が許可されています。 そのため、並行して移行できる共有/共有パスは5つまでです。
- 少数の移行を実行し、それらを完了してから他の移行を開始してください。 これにより、カットオーバー時間が最短になります。
- Moveは、24時間ごとに増分同期を実行します。
- カットオーバーを開始する前に、ソースの共有を読み取り専用モードにする必要があります。 カットオーバー中に、Moveは最終の同期を実行して移行を完了します。
- 移行プランを一時停止しても、進行中の同期がある場合は、他の移行のために並列パイプを解放しません。 進行中の同期が完了してから、移行を一時停止することをお勧めします。
トラブルシュート
サポート バンドルの収集
UIからMoveサポート バンドルをダウンロードする。
UIからリアルタイム ログをダウンロードする。
filtersで、filesagentとmgmtserverを選択する。
ログ ファイルの場所
- /opt/xtract-vm/logs

ファイル移行のためのMoveサービスは、filesagentです。
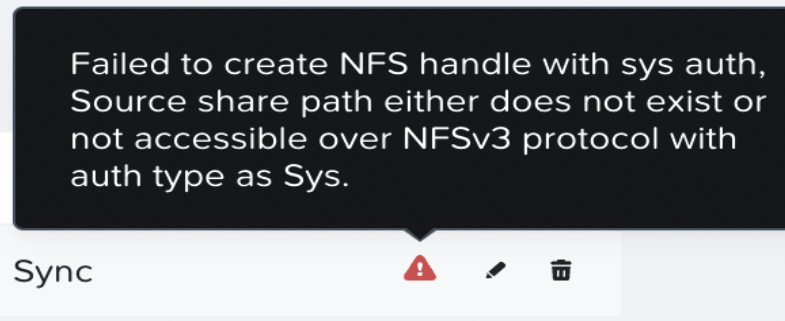
ユーザー権限が原因でSMB共有の移行が失敗した場合、次のようなメッセージが表示されます。
- 解決策: ユーザーをBackup Operatorsグループに追加する。
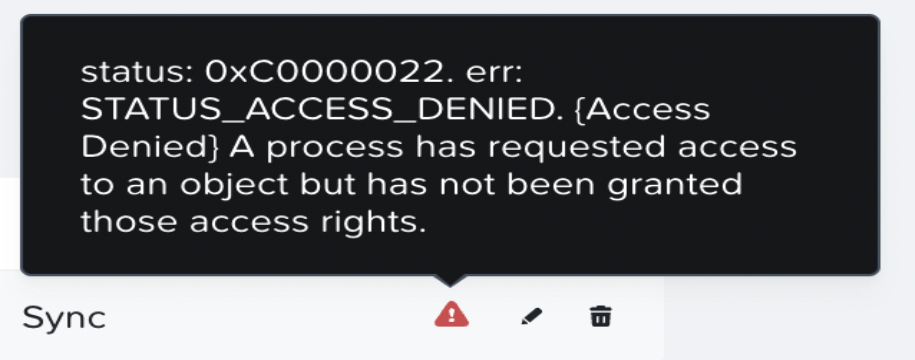
NFS移行が、認証タイプsysが構成されていないために失敗します。
- 解決策: 認証をSYSTEMに変更する。
Storage
Unified Storage Services
当初、Nutanixは仮想マシン データのための最適化されたストレージ サービスを提供することに焦点を当てていました。 その後、Nutanix Volumesの導入によって、任意のオペレーティン グシステムがストレージ システムにアクセスできるように拡張し、これにより共有ディスクや、ベアメタル環境からの接続(あるいはゲストOSのiSCSIイニシエーター接続)のようなユースケースで使用できます。 さらにNutanix Filesの導入で、プラットフォームを高可用性のファイルサーバーとして使用する機能を提供できるように拡張しました。 最後に、Nutanix Objectsでは、S3準拠のAPIで使用できる、非常にスケーラブルなオブジェクトストレージを提供します。
本書では、これらのストレージ サービスの各機能について詳しく解説します。
チャプター
- Volumes (ブロックサービス)
- Files (ファイルサービス)
- Objects(オブジェクトサービス)
Volumes (ブロックサービス)
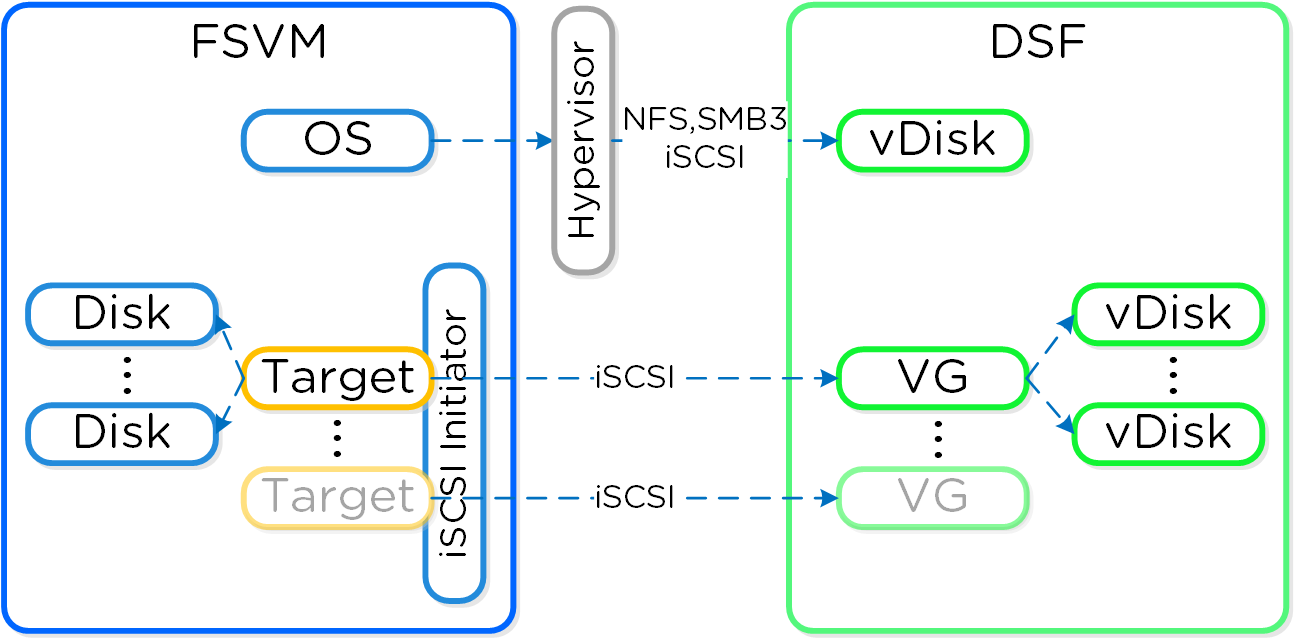
Nutanix Volumesは、バックエンドにあるDSFストレージを、iSCSI経由で外部ユーザー(ゲストOS、物理ホスト、コンテナなど)に提供する機能です。
本機能によって、オペレーティングシステムは、DSFにアクセスしてストレージ機能を利用できるようになります。この導入シナリオにおいて該当OSは、ハイパーバイザーを経由することなく、Nutanixに直接アクセスすることになります。
Volumesの主要なユースケース:
- 共有ディスク
- Oracle RAC、Microsoft Failover Clusteringなど
- ファーストクラスのエンティティとしてのディスク
- 実行コンテキストが短命かつデータが重要な場合
- コンテナなど
- ゲスト内iSCSIイニシエータ
- ベアメタルのコンシューマ
- vSphere上のExchange(Microsoftのサポートのため)
資格要件を満たしたオペレーティングシステム
本ソリューションは、iSCSI仕様に準拠しており、QAによって以下のオペレーティングシステムが検証済みとなっています。
- Microsoft Windows Server 2008 R2, 2012 R2
- Red Hat Enterprise Linux 6.0+
Volumesの構成
Volumesは、以下のエンティティで構成されています:
- データサービスIP: iSCSIログイン リクエストで使用されるクラスタ全体のIPアドレス (4.7で導入)
- ボリュームグループ: iSCSIのターゲットで、集中管理、スナップショット、ポリシーアプリケーションの対象となるディスクデバイスのグループ
- ディスク: ボリュームグループ内のディスク(iSCSIターゲットのLUNとして見える)
- アタッチメント: ボリュームグループに対する特定のイニシエータIQNアクセスを許可
- シークレット: CHAP/Mutal CHAPの認証情報に使用するシークレット
注意: バックエンドでは、VGのディスクは単にDSF上のvDiskとなります。
前提
設定を行う前に、セントラルディスカバリ / ログインポータルとして機能するデータサービスIPを設定する必要があります。
設定は「Cluster Details(クラスタ詳細)」ページから行います。(歯車アイコン -> Cluster Details)
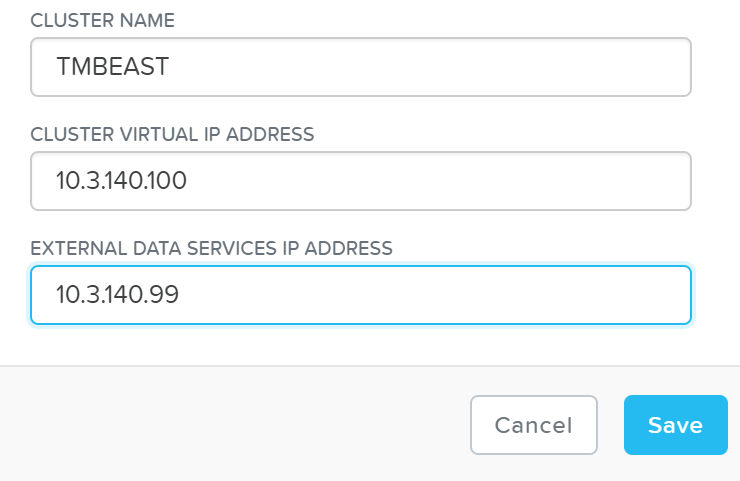
nCLI / API経由でも設定が可能です:
ncli cluster edit-params external-data-services-ip-address=<DATA SERVICES IP ADDRESS>
ターゲットの作成
Volumesを使用するためには、まずiSCSIのターゲットとなる「Volume Group(ボリュームグループ)」を作成する必要があります
「Storage(ストレージ)」ページの右側にある「+ Volume Group(ボリュームグループの追加)」をクリックします:
VG詳細を設定するメニューが表示されます:
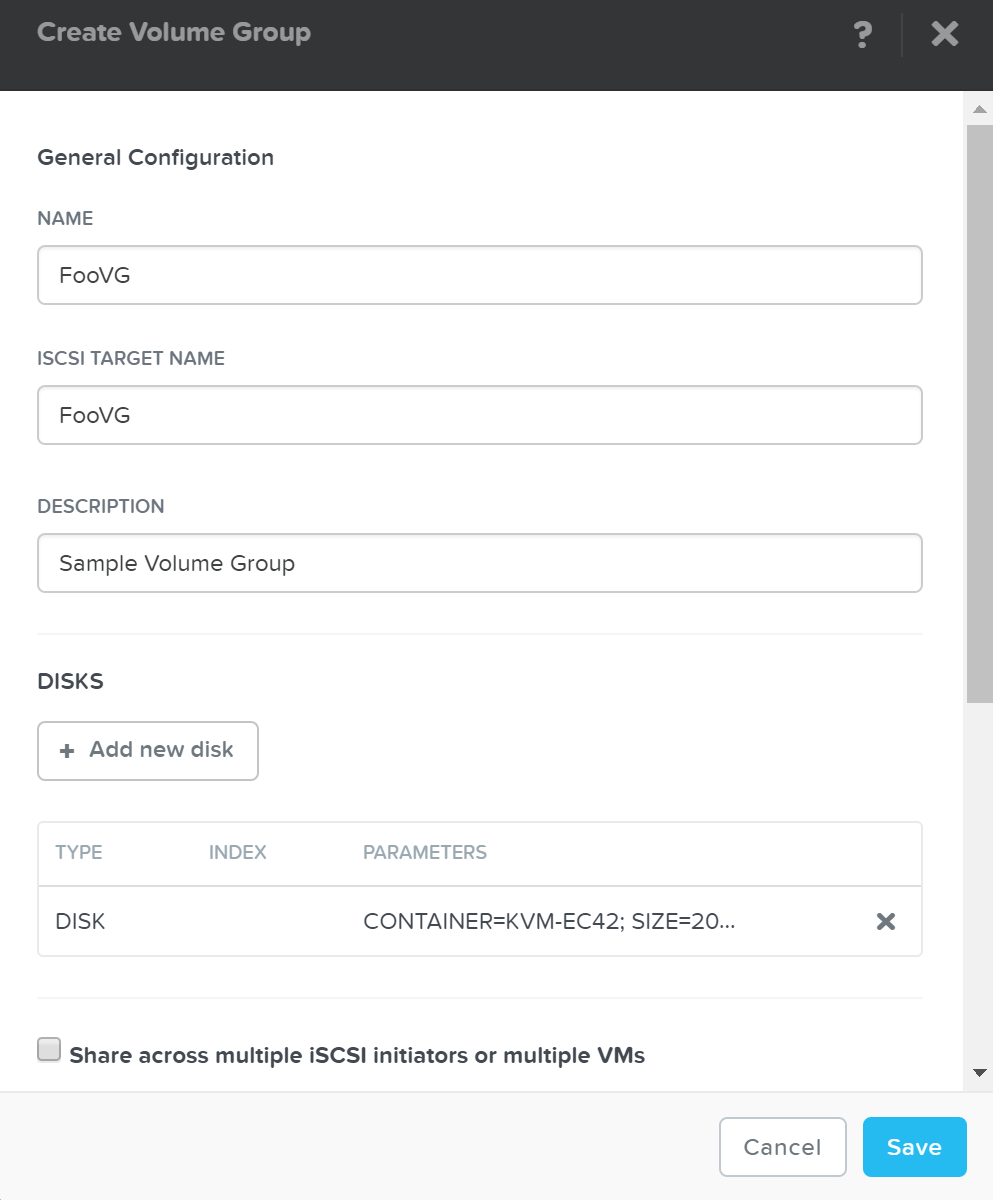
次に「+ Add new disk(ディスクの追加)」をクリックして、ターゲット(LUNとして見える)にディスクを追加します。
メニューが表示されたら、ターゲットとなるコンテナとディスクサイズを選択します:
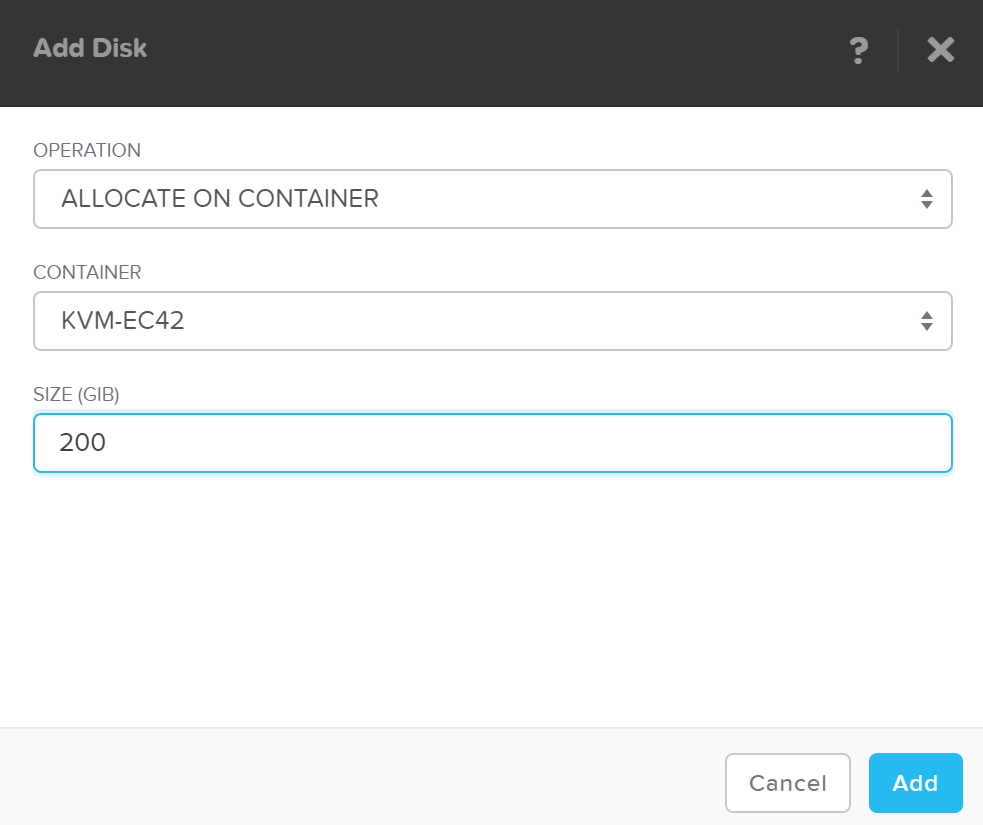
「Add(追加)」をクリックし、必要に応じて繰り返しディスクを追加します。
詳細を設定し、ディスクを追加したら、ボリュームグループをVMまたはイニシエータIQNにアタッチします。これによって、VMがiSCSIターゲットにアクセスできるようになります(未知のイニシエータからのリクエストは拒否されます):
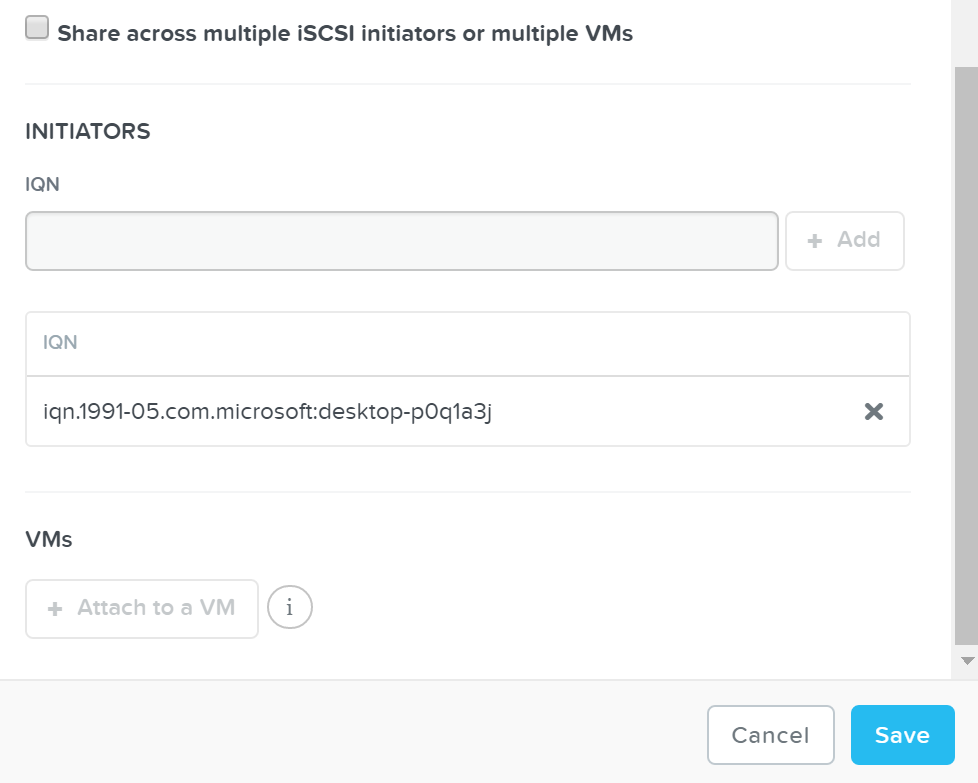
「Save(保存)」をクリックします。これでボリュームグループの設定は完了です!
aCLI / API経由でも、同様の対応が可能です:
VGの作成
vg.create <VG Name>
VGにディスクを追加
vg.disk_create <VG Name> container=<CTR Name> create_size=<Disk size, e.g. 500G>
イニシエータIQNをVGにアタッチ
vg.attach_external <VG Name> <Initiator IQN>
パスの高可用性 (HA)
前述の通り、データサービスIPはディスカバリに使用されます。 これによって、個々のCVM IPアドレスを知る必要なく、1つのアドレスのみを使用できます。
データサービスIPは、現状のiSCSIリーダーに割り当てられます。 障害が発生すると、新しいiSCSIリーダーが選択され、データサービスIPが割り当てられます。 これにより、ディスカバリポータルは常時使用可能な状態になります。
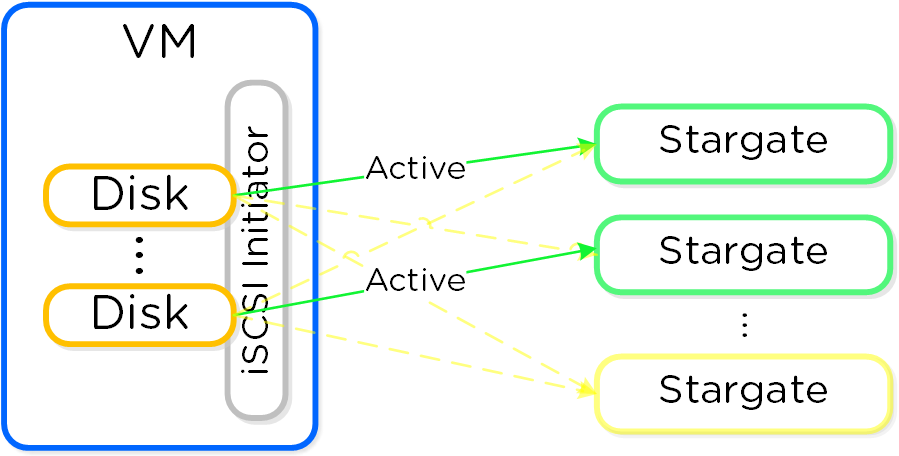
iSCSIイニシエータは、データサービスIPによりiSCSIターゲットポータルとして設定されます。ログインリクエストが発生すると、プラットフォームはiSCSIログインを正常なStargateにリダイレクトします。
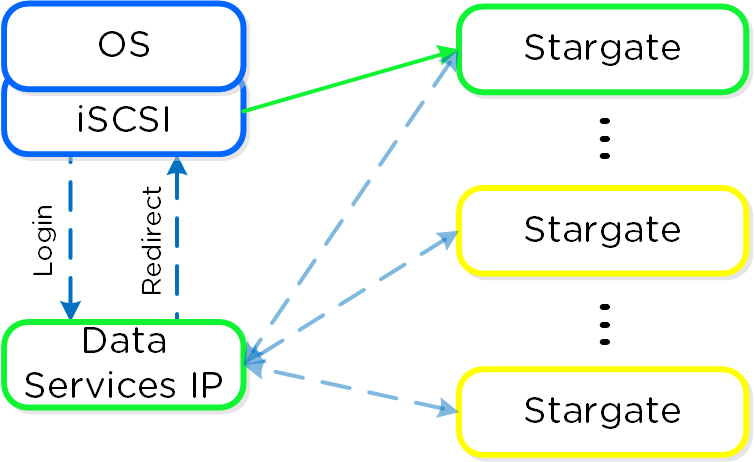
アクティブの(アフィニティがある) Stargateに障害が発生すると、イニシエータはデータサービスIPデータサービスIPへのiSCSIログインをリトライし、別の健全なStargateにリダイレクトされます。
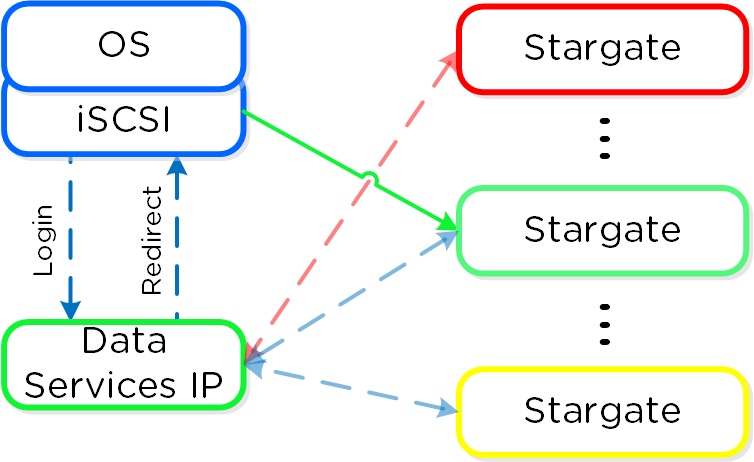
アフィニティがあるStargateが復旧して安定すると、現状アクティブとなっているStargateはI/Oを休止し、アクティブなiSCSIセッションを切断します。イニシエータが再度iSCSIログインを試みると、データサービスIPはそれをアフィニティがあるStargateにリダイレクトします。
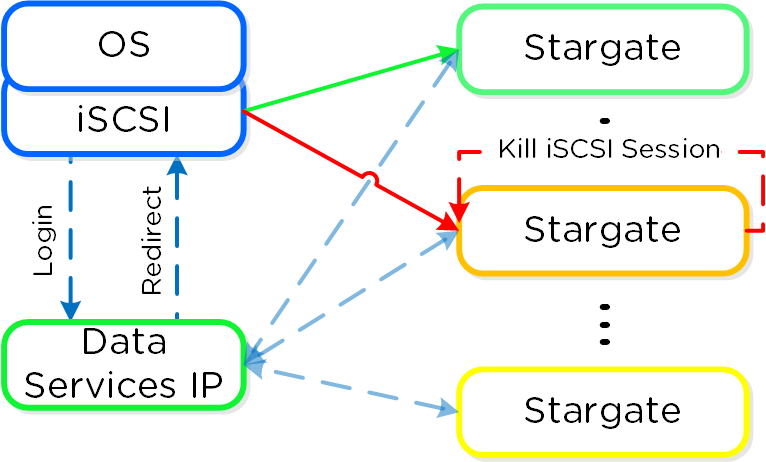
ヘルス監視とデフォルト
DSFに対するメカニズムと同様に、VolumesにZookeeperを使用して、Stargateのヘルス状態を監視します。
フェイルバックのデフォルト間隔は120秒となっています。つまり、元々接続していたStargateが2分間以上健全な状態を保てば、セッションを休止して切断するということです。他のログインも、接続中のStargateに戻されます。
この仕組みによって、パスのHAのためのクライアント側マルチパス(MPIO)設定はもはや必要ありません。 ターゲットに接続する場合、MPIOを有効化するために「Enable multi-path(マルチパスを有効化)」にチェックを入れる必要はありません。
マルチパス
iSCSIプロトコルに準拠するためには、イニシエータとターゲット間で1つターゲットに1つのiSCSIセッション(TCP接続)となる必要があります。つまり、Stargateとターゲットが、1:1の関係になるということです。
4.7では、1つのアタッチイニシエータに対して32(デフォルト)の仮想ターゲットが自動生成され、ボリュームグループ (VG) に追加された各ディスクデバイスに割り当てられます。これにより、1つのディスクデバイスに対して、1つのiSCSIターゲットが提供されます。以前は、複数のVGをそれぞれのディスクに対して作成することで実装を行っていました。
aCLIやAPIでVGの詳細を見てみると、各アタッチメントに対して、32の仮想ターゲットが作成されていることが分かります:
attachment_list { external_initiator_name: "iqn.1991-05.com.microsoft:desktop-foo" target_params { num_virtual_targets: 32 } }
例として、3つのディスクデバイスを追加したVGを作成しました。クライアントでディスカバリを実行すると、それぞれのディスクデバイスに対する個々のターゲットが確認できます。(サフィックスは -tgt[int])
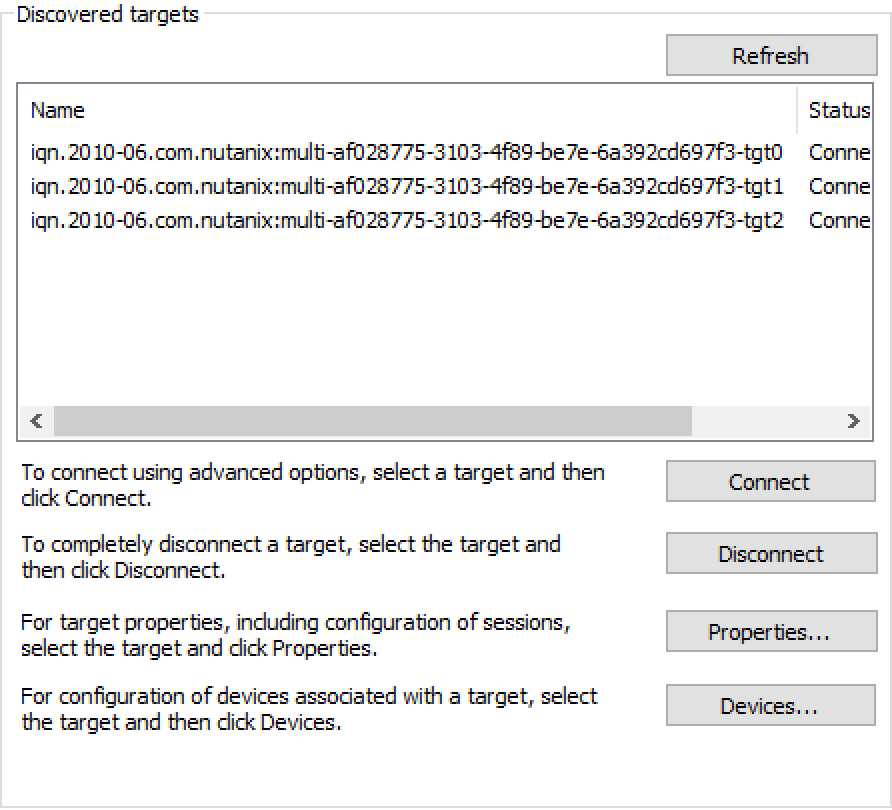
これでディスクデバイスは、自身のiSCSIセッションを持つことになり、これらのセッションは複数のStargateでホストすることが可能であるため、拡張性やパフォーマンスの向上につながります:
iSCSIセッションが確立されている間(iSCSIログイン)、各ターゲットに対するロードバランシングが発生します。
アクティブパス
以下のコマンドを使って、仮想ターゲットをホストしている、有効なStargateを確認することができます(ホストしているStargateのCVM IPを表示):
Windows
Get-NetTCPConnection -State Established -RemotePort 3205
Linux
iscsiadm -m session -P 1
AOS 4.7では、簡単なハッシュ関数を使用してクラスタノード全体にターゲットを分散しています。 AOS 5.0では、これがDynamic Schedulerに統合され、必要に応じて再バランスを取るようになっています。 また、どのノードを使用するかについては、該当ノードが正常である限り自由に設定を行うことができます。
SCSI UNMAP (TRIM)
Volumesでは、SCSI T10仕様にあるSCSI UNMAP (TRIM) コマンドをサポートしています。 このコマンドを使用することで、削除済みブロックのスペース再利用が可能となります。
Files (ファイルサービス)
Nutanix Filesによって、Nutanixプラットフォームを高可用性ファイルサーバーとして利用することができます。 ユーザーは、単一のネームスペースにホームディレクトリやファイルをストアできます。
サポート対象構成
本ソリューションでは、以下の構成をサポートしています(一部のみを掲載しています。完全なリストについてはドキュメントをご覧ください):
-
主なユースケース:
- ホームフォルダー / ユーザープロファイル
- ファイル ストレージ
- メディア リポジトリ
- 永続コンテナ ストレージ
-
管理インターフェイス:
- Prism Element (PE)
- Prism Central (PC)
-
ハイパーバイザー:
- AHV
- ESXi
-
アップグレード:
- Prism
-
互換性のある機能:
- Nutanix スナップショットとDR
- ファイル共有レベルのレプリケーションとDR(Smart DR)
- S3準拠ストレージへのファイル階層化(Smart Tier)
- Windowsの「以前のバージョン」 (WPV:Windows Previous Versions)を含む、ファイルレベルスナップショット
- セルフサービスリストア
- CFTバックアップ
-
ファイルプロトコル:
- SMB 2
- SMB 3
- NFS v4
- NFS v3
Files の構成要素
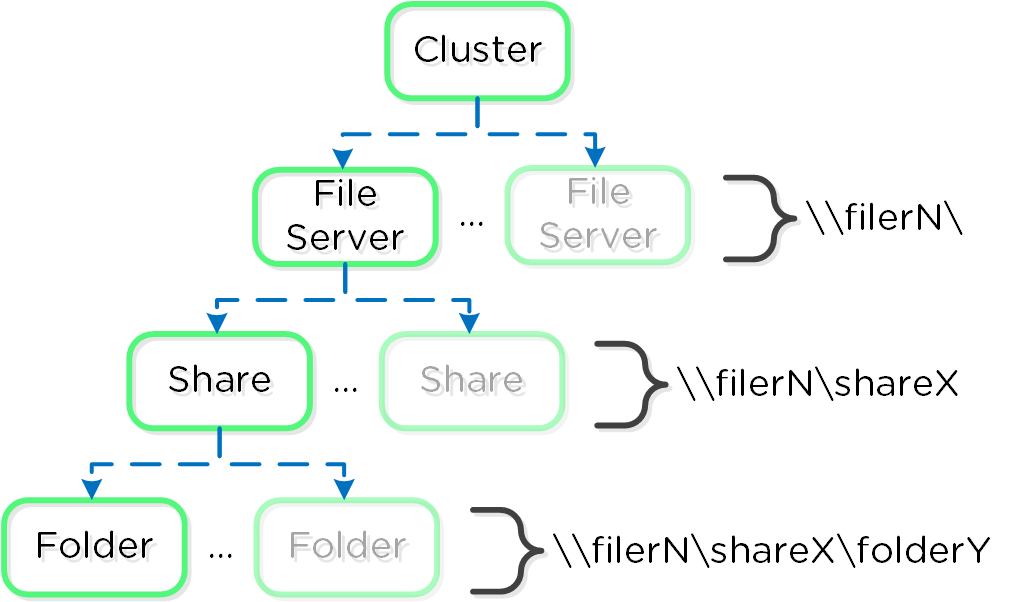
本機能は、いくつかのハイレベルな要素から構成されています:
-
ファイルサーバー
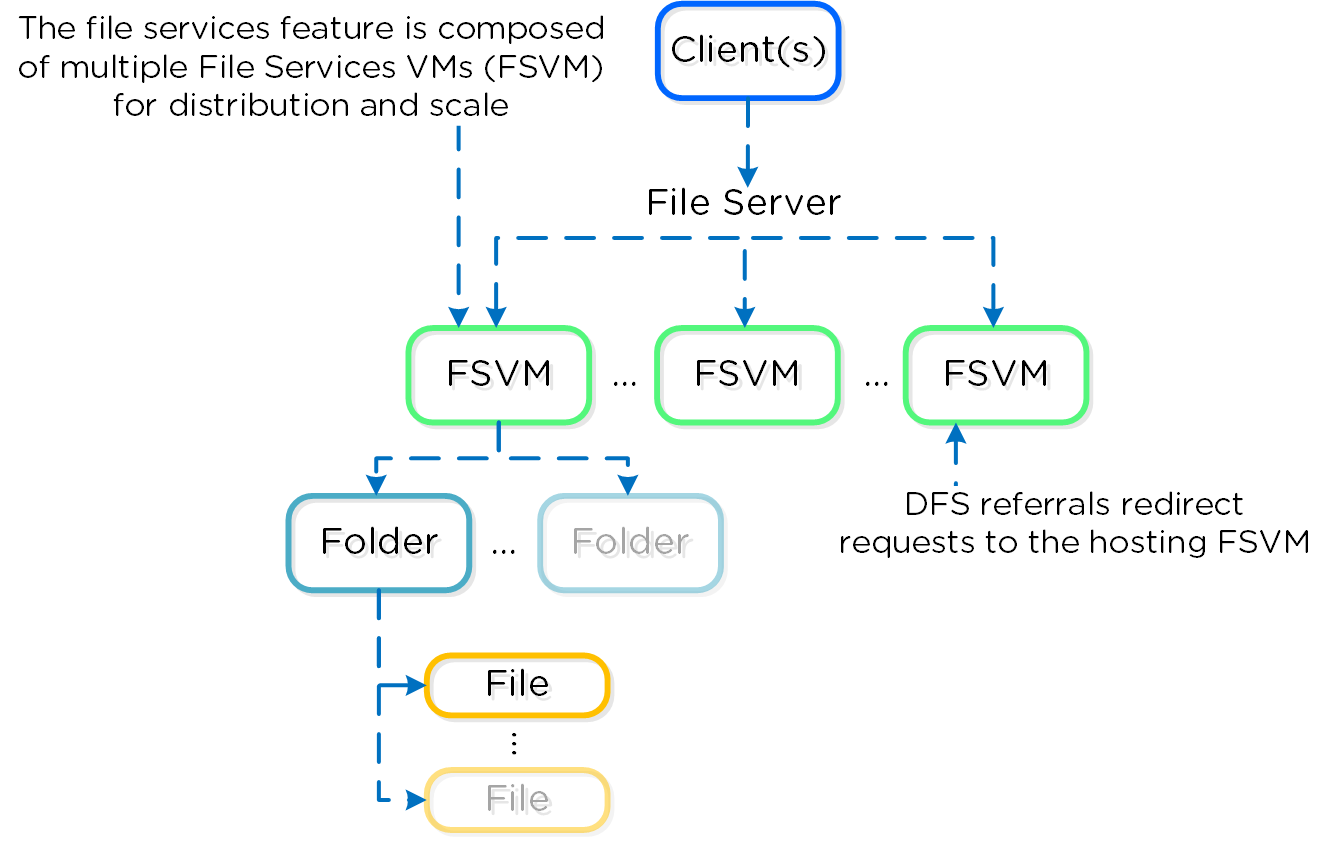
- ハイレベルな名前空間(namespace)。 各ファイルサーバーは、それぞれのFiles VM(FSVM)を持っています
-
シェア
- シェア (Share) には、ユーザーがアクセスできます。ファイルサーバーは、複数のシェアを持つことができます(部門別シェアなど)
-
フォルダー
- ファイルストレージのためのフォルダー。フォルダーは、FSVM全体で共有されます
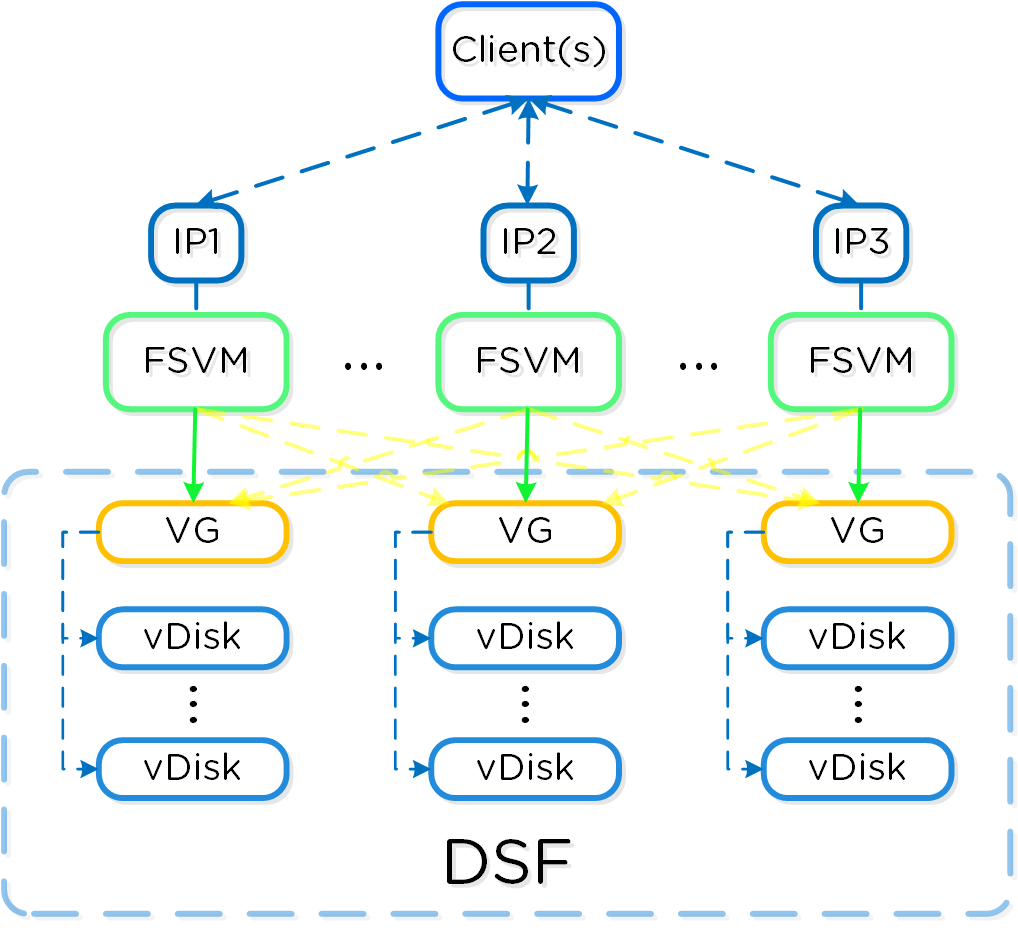
下図は、構成要素の連関についての概要を示したものです:
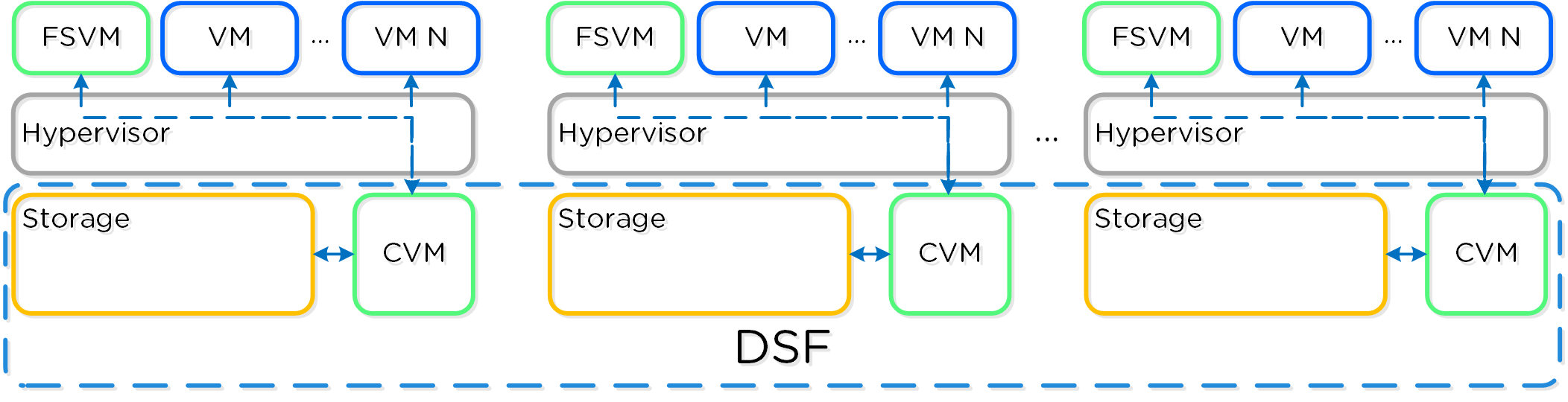
Nutanix Filesでは、Nutanixプラットフォームと同じ分散メソドロジーを踏襲することで、可用性と拡張性を保証しています。ファイルサーバーには、少なくても3つのFSVMが設定されます。
以下にコンポーネントの詳細を示します:
FSVMは、論理的なファイルサーバー インスタンスとして統合され、Filesクラスタと呼ばれることもあります。 ひとつのNutanixクラスタには、複数のFilesクラスタを作成できます。 FSVMは、設定プロセスの途中で透過的にデプロイされます。
下図は、AOSプラットフォームにおけるFSVMの詳細を示したものです:
認証と権限
Nutanix Files機能は、Microsoft Active Directory(AD)およびDNSと完全に連携を取ることができます。 このため、ADに関する全てのセキュアな認証と権限管理機能の活用が可能となります。 共有許可、ユーザーやグループの管理については、従来のWindows MMCを使用して実施されます。
インストレーションプロセスの途中で、以下のAD / DNSオブジェクトが生成されます:
- ファイルサーバーのためのADコンピューターアカウント
- ファイルサーバーと各FSVMのためのADサービスプリンシパル名 (SPN)
- ファイルサーバーが全てのFSVMを示すDNSエントリー
- 各FSVMのためのDNSエントリー
ファイルサーバー生成のためのADの権限
ファイルサービスを導入し、ADおよびDNSオブジェクトを生成するためには、ドメイン管理者または同等の権限を持ったユーザーアカウントを使用する必要があります。
高可用性 (HA)
各FSVMは、Volumes APIを使って、ゲスト内からのiSCSI経由でデータ ストレージにアクセスします。 これにより、FSVMに障害が発生した場合でも、iSCSIターゲットへの接続が可能となります。
以下にFSVMストレージの概要を示します:
CVM が使用できなくなった場合 (アクティブ パスのダウンなど)、iSCSIリダイレクションを使用してターゲットを別のCVMにフェイルオーバーしてI/O処理を引き継ぎます。
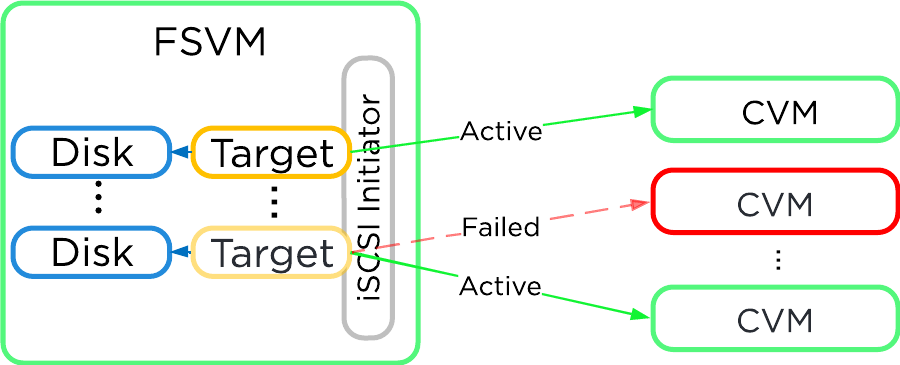
ローカルCVMが復旧して正常稼動すると、こちらがアクティブパスであると認識され、ローカルI/Oを提供するようになります。
通常の運用環境では、各FSVMのパッシブ接続されたデータストレージとの通信は、それぞれのVGとの通信によって実現されます。 それぞれのFSVMは、クライアントがDFS Referral(分散ファイルシステム紹介)プロセスの一部としてFSVMと通信するためのIPを持ちます。 DFS Referralプロセスが共有フォルダーをホストしている正しいIPに接続するため、クライアントが個別のFSVMのIPを認識する必要がありません。
FSVMに「障害」(メンテナンスや電源断など)が発生すると、該当FSVMのVGとIPは、他のFSVMに引き継がれて高可用性を維持します。
以下に、障害FSVMのIPとVMに関する引き継ぎの流れを示します:
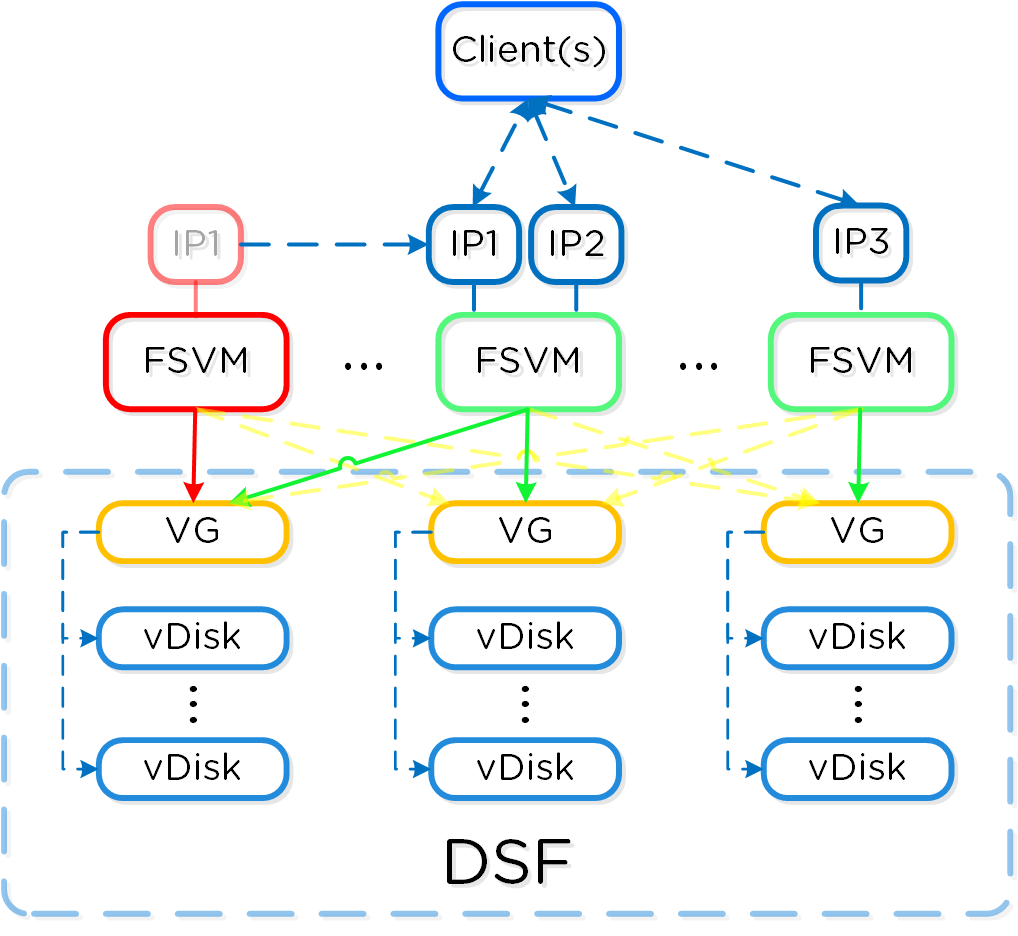
障害のあったFSVMが復旧し安定すると、再度IPとVGを取得してクライアントI/Oの処理を継続します。
Objects(オブジェクトサービス)
Nutanix Objectsは、S3準拠のAPIを介して非常にスケーラブルで耐久性のあるオブジェクトサービスを提供します(S3の補足情報: LINK)。 Nutanix ObjectsがNutanixプラットフォーム上にデプロイされると、圧縮、消失訂正符号 (Erasure Coding)、レプリケーションなどのAOS機能を利用できます。 ObjectsはAOS 5.11で導入されました。
サポートされる構成
ソリューションは以下の構成に適用できます(以下のリストは一部です。全てを確認する際には、ドキュメントをご覧ください):
-
主なユースケース:
- コンプライアンスレベルのWORM機能を持つバックアップターゲット
- 医療画像保管伝送システム(PACS/VNA)のためのアーカイブターゲット、Eメール、長期間バックアップ
- データレイクを含むビッグデータ、AI/MLワークロード、分析、機械からのログ記録、SIEM、Pub/Sub
- DevOps、クラウドネイティブ、コンテンツのリポジトリ、Kubernetes
-
管理インターフェイス:
- Prism Central (PC)
-
ハイパーバイザー:
- N/A - Nutanix MSPで実行(MSPがサポートするハイパーバイザーに依存)
-
アップグレード:
- LCM
-
主な機能:
- WORM
- バージョニング
- 訴訟ホールド(Legal Hold)
- マルチプロトコル
- ストリーミングレプリケーション
- マルチパートアップロード
- 高速なコピー
- S3 Select
-
サポートされているプロトコル:
- S3 (version 4)
- NFSv3
Nutanix Microservices Platform (MSP)
Nutanix Objectsは、Nutanix Microservices Platform(MSP)を活用して実行される最初のコア サービスの1つです。
Nutanix MSPは、Identity and Access Management(IAM)やロードバランシング(LB)といった、Objectsのコンポーネントに関連付けられたコンテナとプラットフォームサービスをデプロイするための共通フレームワークとサービスを提供します。
主な用語
次のこのセクション全体で使用される主要な用語は、以下のように定義されています:
-
バケット
- ユーザーに公開された組織単位であり、オブジェクトを含む。(ファイルサーバーでのファイルの共有とみなせる)。 デプロイメントには、複数のバケット(例えば、部門、区画など)を含めることができ、通常はそうなる。
-
Object
- API(GET / PUT)をインターフェイスとするストレージとアイテムの実際の単位(blob)。
-
S3
- アマゾン ウェブ サービス(AWS)で導入された、元のオブジェクトサービスを説明する用語であり、現在はオブジェクトサービスの同義語として使用されている。 S3は、プロジェクト全体で高度に活用されている、オブジェクトAPIの定義にも使用される。
- ワーカーVM
- さまざまなコンテナ化されたObjectsのサービスをホストする、オブジェクトストアの展開中に作成された仮想マシン。 これらは、Objectsノードとも呼ばれる。
- Objectsブラウザー
- ユーザーがWebブラウザーでオブジェクトストアのインスタンスを直接起動し、バケットおよびオブジェクトレベルの操作を実行できるようにするユーザーインターフェイス(UI)。
この図は、概念構造のマッピングを示します:
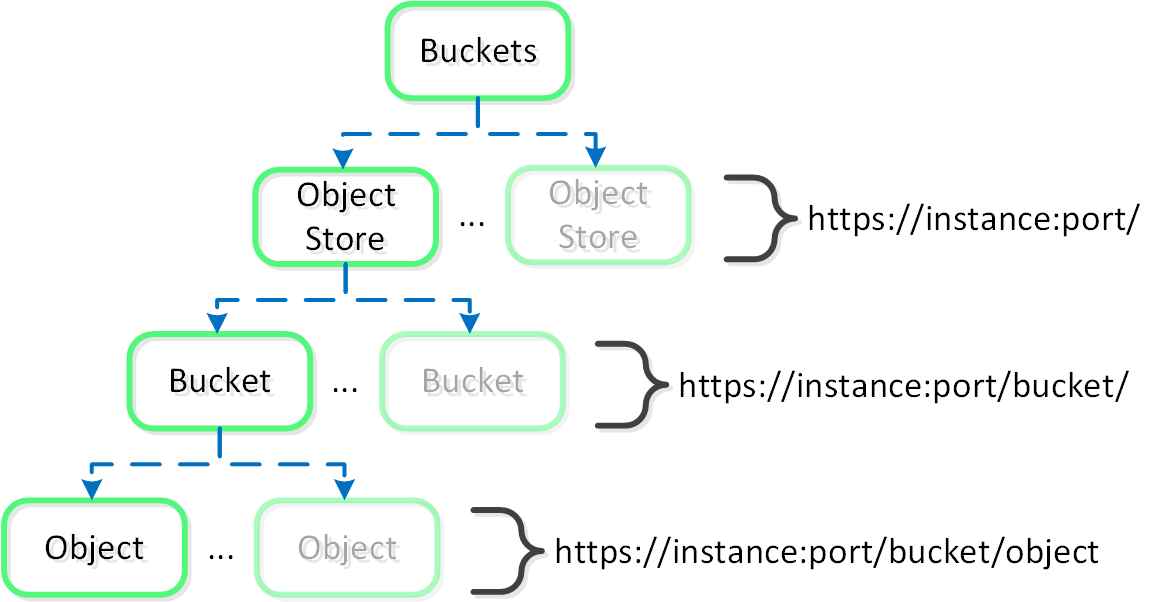
Objectsの構成
この機能は、いくつかの大まかな構成要素で構成されています:
-
ロードバランサー
- ロードバランサーはNutanix MSPの一部であり、サービスおよびデータ リクエストのプロキシとして働きます。 これによりサービスの高可用性が確保され、オブジェクトコンテナ間の負荷分散が行われます。
-
サービスマネージャー
- サービスマネージャーは、すべてのUIリクエストのエンドポイントとして機能し、オブジェクトストアのインスタンスを管理します。 また、インスタンスから統計を収集する役割もあります。
-
メタデータサーバー
- メタデータサーバーは、Nutanix Objectsのデプロイに関する、すべてのメタデータ(例えば、バケット、オブジェクトなど)を格納します。 メタデータサーバーのパフォーマンスを強化するため、NutanixはChakrDBを開発しましたが、これはRocksDBを活用したKey-Valueストアであり、ストレージにNutanix Volumesを使用します。
-
オブジェクトコントローラー
- 自社で構築したデータパスエンジンであり、オブジェクトデータを管理し、メタデータの更新をメタデータサーバーと調整します。 Storage Proxy APIを介してStargateとのインターフェイスになります。
-
リージョンマネージャー
- リージョンマネージャーは、DSF上にあるすべてのオブジェクトストレージ情報(リージョンなど)を管理します。
-
リージョン
- リージョンは、オブジェクトと、それに対応するNutanix vDiskでの場所の高レベルでのマッピングを提供します。 vDisk ID、オフセット、および長さと同様のものです。
-
Atlasサービス
- Atlasサービスは、MapReduceフレームワークをベースにしており、オブジェクトへのライフサイクルポリシーの適用とガベージコレクション、階層化などを担当します。
- S3アダプター
- Objects 3.2は自社で構築されてすべてが新しくなっており、S3アダプターはS3 APIを提供し、S3クライアントからの認可だけでなくAPIリクエストも処理します。 これらはオブジェクトコントローラー向けに変換され、処理されます。
この図は、Objectsのサービス アーキテクチャーの詳細を示します:
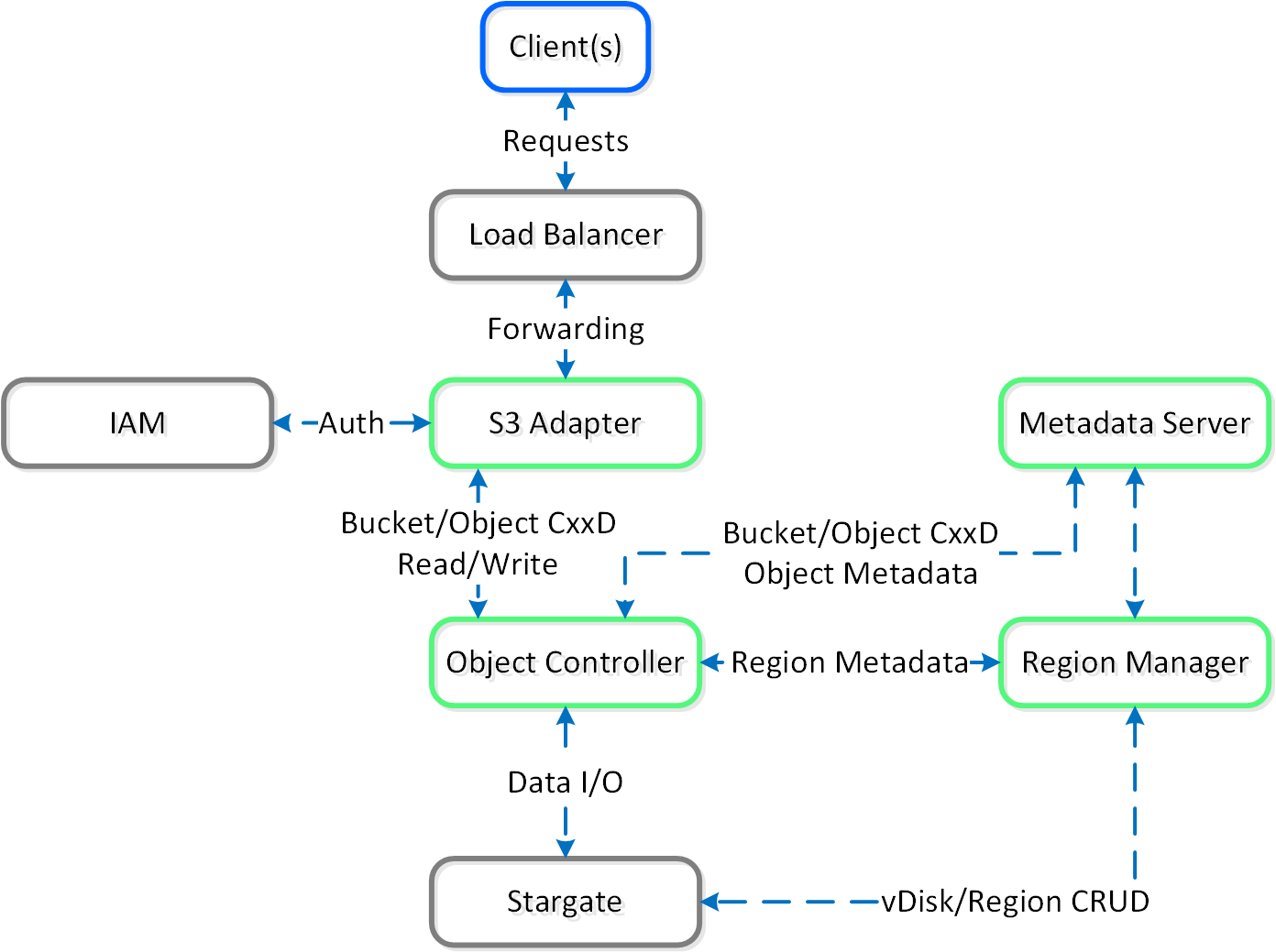
Objects固有のコンポーネントは、Nutanix Greenで強調されています。 オブジェクトには「上書き」の概念がないため、CRUD(Create/Replace/Update/Delete)ではなくCxxD(Create/x/x/Delete)です。 一般的なオブジェクトの「上書き」の方法は、新しいリビジョンを作成するか、新しいオブジェクトを作成してそのオブジェクトをポイントすることです。
オープンソースコンポーネント
Nutanix Objectsは、オープンソースコンポーネントを活用しつつ、有機的なイノベーションの連携により構築されています。 これにより当社の製品がより堅牢で効率的になり、お客様のビジネスに最適なソリューションを提供できると確信しています。
オープンソースライセンスの開示に関する詳細についてはこちらをご覧ください: LINK
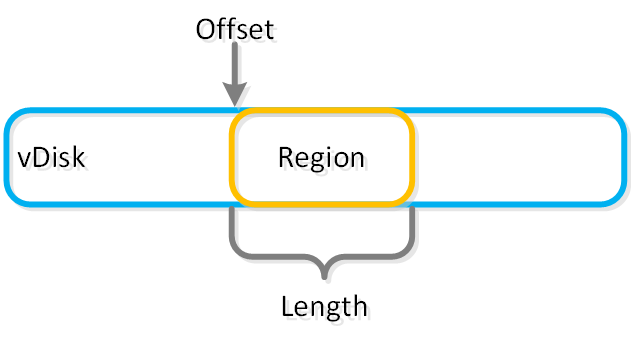
オブジェクトストレージとI/O
オブジェクトは、リージョンと呼ばれる論理構造に格納されます。 リージョンは、vDisk上の固定長セグメントの領域です。
この図は、vDiskとリージョンの関係についての例を示します:
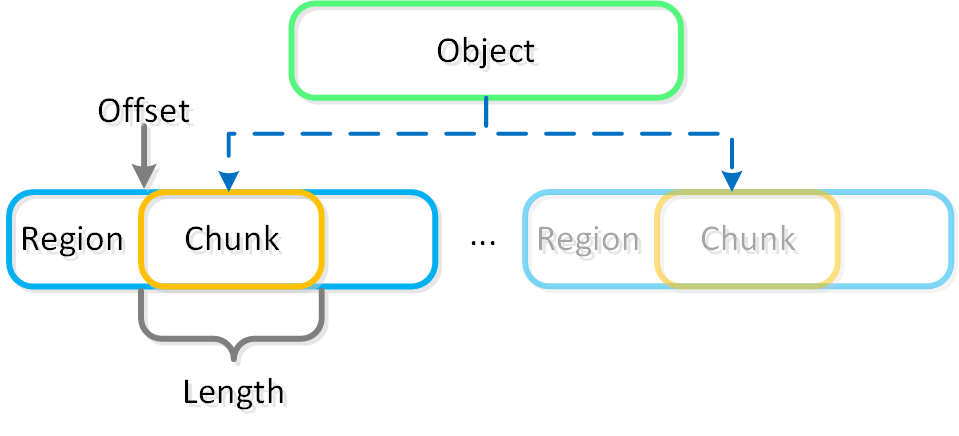
小さいオブジェクトは単一のリージョンのチャンク(リージョンID、オフセット、長さ)に収まる場合がありますが、大きいオブジェクトはリージョンをまたいでストライプ化されることがあります。 ラージオブジェクトが複数のリージョンにストライプ化されている場合、それらのリージョンを複数のvDiskでホストして、複数のStargateにて同時に利用できます。
この図は、オブジェクト、チャンク、リージョンの関係についての例を示します:
オブジェクトサービス機能は、Nutanixプラットフォームと同じ分散方式によって、可用性と拡張性を保証します。 Objectsのデプロイでは、最低3台のオブジェクトVMがデプロイされます。
AOS (Storage for Compute VMs)
Acropolis - アクロポリス - 名詞 - データプレーン
ストレージ、サーバー、仮想化プラットフォーム
Acropolis Operating System(AOS)はコア ソフトウェア スタックであり、ハイパーバイザー(オンプレミスまたはクラウド上で動作する)とワークロードの間に抽象化レイヤーを提供します。 これは、ストレージサービス、セキュリティ、バックアップおよび災害復旧、他にも多くの機能を提供します。
本書では、これらの機能とAOSのアーキテクチャーについて説明します。
チャプター
- AOSのアーキテクチャー
- セキュリティ
- ストレージ
- サービス
- バックアップとディザスタリカバリ
- AOSのアドミニストレーション
AOSのアーキテクチャー
Acropolis Operating System(AOS)は、プラットフォーム上で実行されているワークロードやサービスによって利用される中核的な機能を提供します。 これには、ストレージサービス、アップグレードといったものが含まれますが、これらに限定されません。
この図は、様々なレイヤーにおけるAOSの概念的性質のイメージを示しています:
Nutanixでは、全てを分散するという設計方針に基づき、この考え方を仮想化とリソース管理の分野にまで拡張しました。 AOSは、ワークロードやリソースを管理、プロビジョニング、運用するためのバックエンド サービスです。 目的は、稼動しているワークロードをNutanixがサポートするリソース(ハイパーバイザー、オンプレミスやクラウドなど)から分離して抽象化し、運用する1つの「プラットフォーム」を提供しようというものです。
これによって、ワークロードをハイパーバイザー、クラウド プロバイダーやプラットフォーム間でシームレスに移動させることが可能となります。
VM管理の対象となるハイパーバイザー
AOS 4.7現在、VM管理機能がサポートするハイパーバイザーは、AHVとESXiに限定されていますが、将来的には拡大される予定です。 但し、Volumes APIとREADオンリーの操作は、現在でも全てがサポートされています。
Acropolisサービス
Acropolisワーカーは、全てのCVM上で、タスクのスケジューリング、実行、IPAMなどを行う選出されたAcropolisリーダーと共に稼動します。 他のリーダーを持つコンポーネントと同様、Acropolisリーダーに障害が発生した場合は、新しいリーダーが選出されます。
各機能の役割を以下に示します:
- Acropolisリーダー
- タスクのスケジューリングと実行
- 統計の収集とパブリッシング
- ネットワーク コントローラー(ハイパーバイザー用)
- VNCプロキシ(ハイパーバイザー用)
- HA(ハイパーバイザー用)
- Acropolisワーカー
- 統計の収集とパブリッシング
- VNCプロキシ(ハイパーバイザー用)
以下は、Acropolisリーダーとワーカーの関係を概念的に図示したものです:
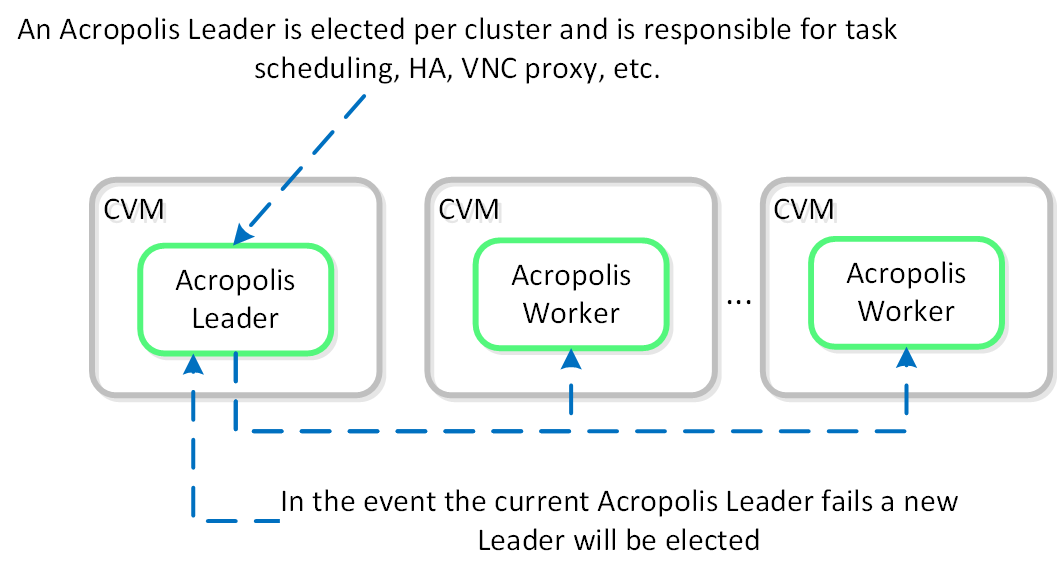
Dynamic Scheduler
リソースを効果的に使うためには、リソースの効率的なスケジューリングが重要となります。 AOS Dynamic Schedulerでは、サーバー使用状態(CPU/メモリ)を根拠にした従来のスケジューリング方法を拡張し、より正確な決定ができるようになっています。 ここでは、サーバーのみでなくストレージやその他の状態を見て、VMやボリューム(ABS)のプレースメント判断を行います。 これにより、リソースを効果的に使用し、エンドユーザーのパフォーマンスを最適化することができます。
リソースのスケジューリングは、2つの主要な部分に分かれます:
-
初期プレースメント
- 起動時に対象をどこでスケジューリングするかを決定
-
実行時の最適化
- 実行時の測定基準に従ってワークロードを移動
オリジナルのAOS Schedulerが最初にリリースされた際には、初期プレースメントのみを考慮していました。 AOS 5.0でのリリースにより、AOS Dynamic Schedulerは、実行時にもリソースの最適化が図られるよう拡張されました。
以下にスケジューラーのアーキテクチャーの概要を示します:
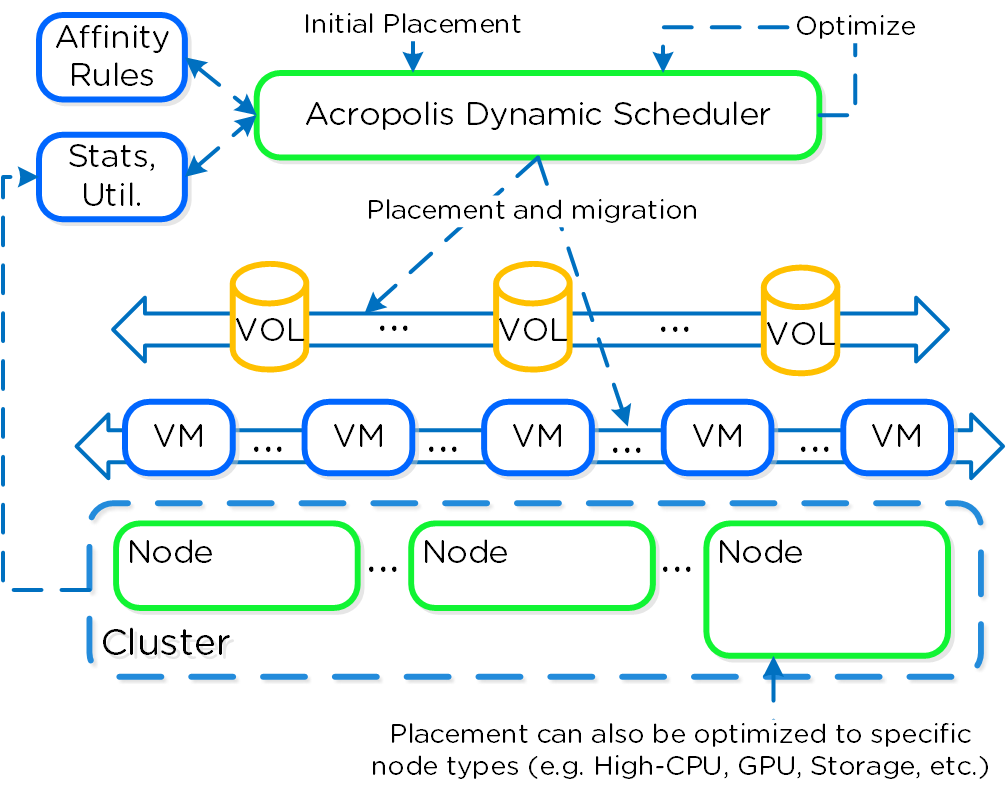
ダイナミックスケジューラー (Dynamic Scheduler) は、終日稼動し続けてプレースメントの最適化を行います (現在は15分毎 | Gflag: lazan_anomaly_detection_period_secs)。 推定要求値は、平滑化アルゴリズムを使って使用状況の遷移を計算します。 ワークロードの移動判断に推定要求値を使用することで、使用率のスパイク(一瞬の数値の跳ね上がり)に引きずられないようにします。
リソース最適化のための異なるアプローチ
既存のスケジューリングや最適化のためのプラットフォーム(VMware DRS、Microsoft PRO)を見ると、 全てワークロードのバランシングや、クラスタリソースに対するVMの配置平滑化に焦点を当てています。
注意: バランスの悪さをいかに積極的に解消するかは、バランシングの設定によります。 (例えば、manual -> none, conservative -> some, aggressive -> more)
例えば、クラスタ内に3つのホストがあり、それぞれの使用率が50%、5%、5%だと想定します。 典型的なソリューションは、ワークロードをリバランスして、それぞれが ~20%となるように調整します。 なぜでしょうか?
私達が行おうとしているのは、リソースの競合が発生しないようにすることであり、非対称性を解消することではありません。 リソースの競合がなければ、ワークロードを「バランシング」する積極的な理由は存在しません。実際に、ワークロードの不必要な移動を行おうとすると、必要な追加処理(メモリの転送、キャッシュの再ローカライズ等)が発生し、リソースを消費することになります。
AOS Dynamic Schedulerでは、この問題に対応すべく、非対称性の発生ではなく想定したリソース競合が発生した場合に限りワークロードを移動させています。
注意: DSFは、ホットスポットの発生を回避したり、リビルドの速度を上げたりするために、データをクラスタ全体に均一に分散させるという異なる方法を取っています。 DSFに関するより詳細な内容については、「ディスクバランシング」セクションをご覧ください。
ADSは起動時に、クラスタ全体でVM初期プレースメントのバランシングを行います。
プレースメントの決定
以下の要因によってプレースメントの決定が行われます:
-
サーバーの使用状況
- Nutanixは、各ノードのサーバーの使用状況をモニターしています。 あるノードのCPU使用率がしきい値(現在は、ホストCPUの85% | Gflag: lazan_host_cpu_usage_threshold_fraction)を超えると、 ワークロードのバランスを取るため、(複数の)VMをそのホストから他へ移行します。 ここで重要なのは、移行が実施されるのはコンテンション(リソース競合)が発生している場合に限定されるという点です。 仮にノードの使用率が偏っている場合(例えば3ノードが10%で、他の1ノードが50%)でも、コンテンションが発生していなければ、何のメリットも無いため移行は発生しません。
-
ストレージのパフォーマンス
- ハイパーコンバージド プラットフォームであるため、サーバーとストレージリソースは同時に管理されています。スケジューラーは、各ノードのStargateプロセスのCPU使用率を監視しています。Stargateの使用率がしきい値に達すると(現在は、CPUの85%がStargateに使用された場合 | Gflag: lazan_stargate_cpu_usage_threshold_pct)、ホットスポットの発生を回避するため、リソースを(複数の)ホスト間に分散させます。VMとABSボリュームのいずれについても、ホットなStargateの発生を避けるため移行させることが可能です。
-
(アンチ)アフィニティルール
- 特定のリソースをどこでスケジュールするかについては、環境内の他のリソースの状況を基に、アフィニティまたはアンチ アフィニティルールによって決定します。例えば、ライセンスの関係で複数のVMを同じノードで動かしたいケースがあります。この場合には、それぞれのVMが同じホストに配置 (affine) されます。また、可用性確保のために複数のVMを異なるホストで動かしたい場合には、それぞれのVMは別のホストに配置(anti-affine)されます。
スケジューラーは、前述のルールに従ってワークロードが最適なプレースメントとなるよう最善を尽くします。システムには、移行が過度に発生しないよう制限が設けられています。これによって、移行がワークロードに悪影響を及ぼさないようにしています。
移行完了後、その「効果」をシステムが判定して実際のメリットを確認します。この学習モデルによって自己最適化が可能となり、移行判定のための妥当性をより向上させることができます。
セキュリティ
セキュリティは、Nutanixプラットフォームのコアとなる部分であり、常に注意が払われています。 Nutanix Security Development Lifecycle(SecDL)は、開発プロセスの全てのステップで採用されています。 システムは、工場から出荷された時点でセキュリティが確保された状態にあり、 プラットフォームのNutanixによって制御されている部分は、箱から出したときに安全な状態で、エンドユーザーが後からセキュリティを「強化する」必要はありません。
セキュリティについて考えるとき、私たちは本当に達成しようとしているものは3つの核となること(CIAトライアドと呼ばれる)です:
- 機密性(Confidentially)
- 不正アクセスを防止することで、データを安全に保護する
- 完全性(Integrity)
- 不正な変更を防止することで、データの一貫性と正確性を確保する
- 可用性(Availability)
- 認可されたユーザーが回復力と冗長性のあるデータにアクセスできるようにする
これは単純な説明に簡略化でき、つまりは、ユーザーが悪意のある人を排除しながら仕事をできるようにします。 セキュリティを設計するときは、以下の図で強調されているいくつかの重要な領域を考慮する必要があります:
以降のセクションでは、前掲の図の各セクションを分類します。
システムと構成のセキュリティ
一覧:
- 既知の脆弱性へのパッチ適用と削除
- 強力なパスワードを強制し、デフォルトのアカウントを削除する
- 権限とユーザー特権を構成する
- 使用していないポートやプロトコルを閉じる
- 自動化し、ベースラインを確保する
従来、人々は「ハードニング(hardening)」と呼ばれる手法でシステム(OS +アプリ)のセキュリティを参照しています。 これは、ベースラインと呼ばれる特定の標準に構成することで、システムを安全にするプロセスです。
DoD(アメリカ国防総省)のIT組織(DISA)には、STIGと呼ばれるサンプルのハードニングガイドがあります(詳細は以降にあるSCMAセクションを参照してください)。 これには、ディレクトリのアクセス許可、ユーザーアカウント管理、パスワードの複雑さ、ファイアウォール、その他の多くの構成設定などが含まれます。
システムがその標準に設定されると「安全」と見なされますが、それはプロセスの始まりにすぎません。 システムのセキュリティは、その寿命を通して維持する必要があるものです。 例えば、標準のハードニングベースラインが確実に満たされるようにするには、構成自動化ツールを使用する必要があります。 これにより、システムは常にベースラインの「望ましい状態」を満たします。
Nutanixは、このセクションの後半で説明する、自身で開発したSCMAと呼ばれるツールを使用してCVMとAHVハイパーバイザーに対してこれを保証しています。
データのセキュリティ
一覧:
- データへの安全なアクセス制御
- 常にバックアップを取得する
- データの暗号化と鍵の安全な管理
データはあらゆるビジネスの中核であり、間違いなく会社の最も貴重な資産です。 セキュリティについて考えるとき、データのアクセシビリティ、品質、および盗難回避を確保することに焦点をあてる必要があります。
アクセシビリティの概念においては、意思決定を行うためにシステムとデータへのアクセスが常に必要です。 「ランサムウェア」と呼ばれる最近の攻撃手法は、データ暗号化によってデータにアクセスする能力を脅かし、ユーザーがアクセスを取り戻すための身代金を要求します。 これはさまざまな方法で回避できますが、バックアップの重要性を強調することにもなります。
データの品質についても、多くの決定またはアクションが依存するため重要な項目です。 例えば、攻撃者がシステムにアクセスすることで、悪意のある注文をしたり、配送先住所を自身の場所に変更して商品を流用したりします。 これは、データをクリーンな状態に保つために、ロギングとチェックサム確認が非常に重要となりうるところです。
最後に重要なことは、データをどのように安全または強固なものにするかです。 これは一般的に、暗号化によって行われ、データ復号化キーがない場合にはデータが役に立たなくなります。 この場合、誰かが暗号化されたファイルまたはディスクデバイスを盗むと、元となるデータにはアクセスできなくなります。
ネットワークのセキュリティ
一覧:
- 信頼できる、または信頼できないネットワークをセグメント化する
- 境界およびセグメント間のファイアウォール
- IDPSを活用した異常検出
ネットワークは、攻撃者がシステムにアクセスするために使用する典型的な通信経路です。 これには、境界セキュリティ(例えば、外部ファイアウォール)や、内部への侵入防止および検出が含まれます。
他の優れた設計と同様に常にセキュリティの層があるべきで、 同じことがネットワークにも当てはまります。 高セキュリティのネットワークを信頼できるネットワークからセグメント化する必要があり、それらを信頼できないネットワーク(例えば、業務やWi-Fiネットワーク)から保護します。 オフィスのローカルネットワークがセキュアであると想定することは決して安全ではありません。
複数層のネットワークを持つことにより、最も信頼されていないネットワークにアクセスする誰かが、安全なネットワークに向けて作業することをより困難にすることができます。 このプロセスにおいて、優れたIDPSシステムは、異常なアクセスや、nmapのようなスキャンツールを検出できます。
認証と認可
一覧:
- 可能な場合はMFAや2FAを使用する
- 詳細な権限を使用する
認証とは、Active Directoryやその他のIDP(IDプロバイダー)などの信頼できるソースによって、ユーザーの身元を認証することです。 MFA(多要素認証)や2FAのようなツールは、認証しようとしているユーザーがその人自身であることについて、さらに保証を追加します。
身元が確認されたら、次は、ユーザーが行うことが許可されているかどうか、ユーザーが何にアクセスできるかを決定します。これは認可の部分です。 ユーザーfooは、barでのxとy、basでのyとzを行うことを認可されているといったものです。
コンプライアンスとモニタリング
一覧:
- コンプライアンスは継続的な活動
- 監視し、異常を探す
コンプライアンスとは、一般的にPCIやHIPAAのような特定の認定をするときに参照されるものです。 しかし、これはハードニングガイドや基準へのコンプライアンスを満たすことにまで拡張されます。 例えば、STIGはハードニングのベースラインとなるサンプルですが、各企業では追加のポリシーやルールを設けている場合があります。 安全なシステムを確保するためには、システムがこれらのポリシーを満たし、コンプライアンスを遵守した状態にしておかなければなりません。
伝統的に、コンプライアンスは遡及的に確認され、かなり手動によるプロセスです。 これは絶対に間違ったアプローチだと思います。 コンプライアンスは、潜在的な脅威ベクタ確実に制限したり、開いている可能性のあるものを閉じたりする唯一の方法であり、常に確保しなければならないものです。
ここでは、構成管理の自動化(別名は、desired state configuration - DSC)を処理するツールが重要なピースです。 これらにより、構成や設定が常にベースラインまたは目的の状態に設定されます。
監視と侵入のテストは、このコンプライアンスを検証および保証するために重要です。 Nessus、Nmap、metasploitのようなツールを使用して、システムのセキュリティをテストできます。 これらのテスト中、監視および検出システムは、これらを検出してアラート通知をする必要があります。
人間
一覧:
- 教育、教育、教育
- 強力な慣行と練習を強制する(例えば、コンピューターのロック)
どのシステムにおいても、人間は伝統的に最も弱いリンクです。 ユーザーがフィッシング攻撃やソーシャルエンジニアリングに陥らないようにするには、トレーニングと教育が重要です。 ユーザーが何を探すべきかを確実に把握して、不明な場合は既知のリソースを案内する必要があります。
教育の1つの方法は、実際にフィッシング攻撃をシミュレートすることであり、彼らに質問を投げかけることで何を探すべきかを学習できます。 また、ロック解除した状態やパスワードを書き留めたままでコンピューターを離れない、といった他のポリシーも強制する必要があります。
認証と認定
Nutanixでは、スタック(オンプレミスおよびオフプレミス)の部分にわたり次のようなセキュリティ認証や認定を有しています:
-
コモンクライテリア(CC - Common Criteria*)
- コモンクライテリアは、政府機関市場(主に国防や機密機関関係)に対してコンピューターを販売する企業が、ただ1つの標準に従えば済むよう策定されたものです。 CCはカナダ、フランス、ドイツ、オランダ、英国および米国によって作成されました。
- *これは2020年3月現在では再認定中です。
-
セキュリティ技術導入ガイド(Security Technical Implementation Guides - STIGs)
- DOD IAおよびIAイネーブルなデバイスやシステムのための実装基準です。 1998年以来、DISA Field Security Operations (FSO) は、セキュリティ技術導入ガイド(STIG)を提供することで、DoD(米国国防総省)のセキュリティ システムの改善において重要な役割を果たしてきました。 STIGには、情報システムやソフトウェアが不正なコンピューター攻撃に対して脆弱性をさらさないよう、「厳重監視」するための技術指針が含まれています。
-
FIPS 140-2
- FIPS 140-2 基準は、暗号化のための情報テクノロジー セキュリティ適格性認定プログラムであり、取扱注意ではあるが機密ではない(SBU - sensitive but unclassified)政府機関や規制対象業界(金融やヘルスケア業界など)の情報の収集、蓄積、転送、共有および配布に関わる自社製品の認定を求める民間企業ベンダーによって作成されたものです。
- NIST 800-53
- NIST 800-131a
- ISO 27001
- ISO 27017
- ISO 27018
自動セキュリティ設定管理(SCMA - Security Configuration Management Automation)
Nutanixのセキュリティ エンジニアリング チームは、特定時点でしか対応できなかったセキュリティベースラインのチェックを刷新し、導入ライフサイクルのあらゆる局面を通じて、クラスタ内の全てのCVM/AHVホストが継続的なモニタリングを行い、ベースラインに対する自己修復をできるようにしました。 これによって、セキュリティ基準(STIG)に記載された全てのセキュリティベースラインのコンポーネントチェックが可能となり、未準拠となっている部分を検知して、ユーザーに影響を及ぼすことなく、サポートされたセキュリティ設定に戻すことができます。 SCMAはデフォルトで有効化されるので、有効化のための作業は不要です。
アドホックなSCMAの実行
SCMAは、設定済みスケジュール(デフォルト:一時間毎)に従って実行されますが、オンデマンドで実行することも可能です。SCMAツールは、以下のコマンドを使ってCVMから実行することができます。
1台のCVMでの実行
sudo salt-call state.highstate
すべてのCVMでの実行
allssh "sudo salt-call state.highstate"
Nutanix Command Line Interface (nCLI) を使用することで、様々な設定が可能となり、厳しいセキュリティ要件にも対応することができます。
CVMセキュリティ設定
以下のコマンドは、クラスタ全体にSCMAポリシーを設定するためにnCLIに追加されたコマンドです。該当コマンドとその機能を以下に示します:
CVMセキュリティ設定の表示
ncli cluster get-cvm-security-config
このコマンドは、現状のクラスタ設定内容を出力します。デフォルトの出力内容は以下の通りです:
Enable Aide : false Enable Core : false Enable High Strength P... : false Enable Banner : false Enable SNMPv3 Only : false Schedule : DAILY
それぞれは以下のように定義されています:
- Aide
- 「Advanced Intrusion Detection Environment」の定期実行を有効にします。
- Core
- 問題がある、もしくは SCMA が修正できない場合に、スタック トレースを作成します。
- High Strength Passwords
- 高い強度のパスワードを強制します。minlen(最小文字列)=15、difok(前回パスワードとは異なる文字数)=8、remember(過去何世代と異なるものにするか)=24。
- Banner
- カスタム ログイン バナーを有効化します。
- SNMPv3 Only
- SNMPv2の代わりに、SNMPv3を強制します。
CVMログインバナーの設定
このコマンドを使うことで、Nutanix CVMにログインする際に、DoD(米国防総省)の同意内容 (DoD knowledge of consent) に関するログインバナーを表示するかどうかを設定できます。
ncli cluster edit-cvm-security-params enable-banner=[yes|no]
- デフォルト: no
カスタムログインバナー
デフォルトでは、DoD同意内容バナーが使用されます。カスタムのバナーを使用したい場合は、以下の手順に従います(いずれのCVMについてもNutanixユーザーとして実行)。
- 既存バナーのバックアップを取得
- viを使って既存バナーを編集
- 上記手順を全てのCVMに対して実施するか、または変更済みバナーを他の全てのCVMに対してSCP実行
- 上記コマンドを使用してバナーを有効化
sudo cp -a /srv/salt/security/KVM/sshd/DODbanner /srv/salt/security/KVM/sshd/DODbannerbak
sudo vi /srv/salt/security/KVM/sshd/DODbanner
CVMパスワードの強度設定
このコマンドで、高強度パスワードポリシー (minlen=15,difok=8,remember=24) の適用を有効化または無効化できます。
ncli cluster edit-cvm-security-params enable-high-strength-password=[yes|no]
- デフォルト: no
Advanced Instruction Detection Environment (AIDE) の設定
このコマンドで、週次に実行するAIDEサービスを有効化または無効化できます。
ncli cluster edit-cvm-security-params enable-aide=true=[yes|no]
- デフォルト: no
SNMPv3限定の設定
このコマンドで、SNMPv3限定トラップを有効化または無効化できます。
ncli cluster edit-cvm-security-params enable-snmpv3-only=[true|false]
- デフォルト: false
SCMAスケジュールの設定
このコマンドでSCMAの実行頻度を設定できます。
ncli cluster edit-cvm-security-params schedule=[HOURLY|DAILY|WEEKLY|MONTHLY]
- デフォルト: HOURLY
ハイパーバイザーのセキュリティ設定
以下のコマンドは、SCMAポリシーをクラスタ全体に設定するためにnCLIに追加されたコマンドです。該当コマンドと機能を以下に示します:
ハイパーバイザーのセキュリティ設定を表示
ncli cluster get-hypervisor-security-config
このコマンドは、現状のクラスタの設定内容を出力します。デフォルトの出力内容は以下の通りです:
Enable Aide : false Enable Core : false Enable High Strength P... : false Enable Banner : false Schedule : DAILY
ハイパーバイザー ログインバナーの設定
このコマンドを使うことで、Nutanixハイパーバイザーにログインする際に、DoD(米国防総省)の同意内容 (DoD knowledge of consent) に関するログインバナーを表示するかどうかを設定できます。
ncli cluster edit-hypervisor-security-params enable-banner=[yes|no]
- デフォルト: no
ハイパーバイザー パスワード強度設定
このコマンドで、高強度パスワードポリシー (minlen=15,difok=8,remember=24) の適用を有効化または無効化できます。
ncli cluster edit-hypervisor-security-params enable-high-strength-password=[yes|no]
- デフォルト: no
Advanced Instruction Detection Environment (AIDE) の設定
このコマンドで、週次に実行されるAIDEサービスを有効化または無効化できます。
ncli cluster edit-hypervisor-security-params enable-aide=true=[yes|no]
- デフォルト: no
SCMAスケジュールの設定
このコマンドで、SCMAの実行頻度を設定できます。
ncli cluster edit-hypervisor-security-params schedule=[HOURLY|DAILY|WEEKLY|MONTHLY]
- デフォルト: HOURLY
クラスタ ロックダウン
クラスタ ロックダウン (Cluster lockdown) は、パスワードベースのCVMアクセスを無効化、またはキーベースのアクセスのみを有効化する機能です。
クラスタ ロックダウンの設定内容については、歯車アイコンのメニューにあるPrismから確認することができます:
現在の設定内容が表示され、アクセスに必要なSSHキーを追加、削除することができます:
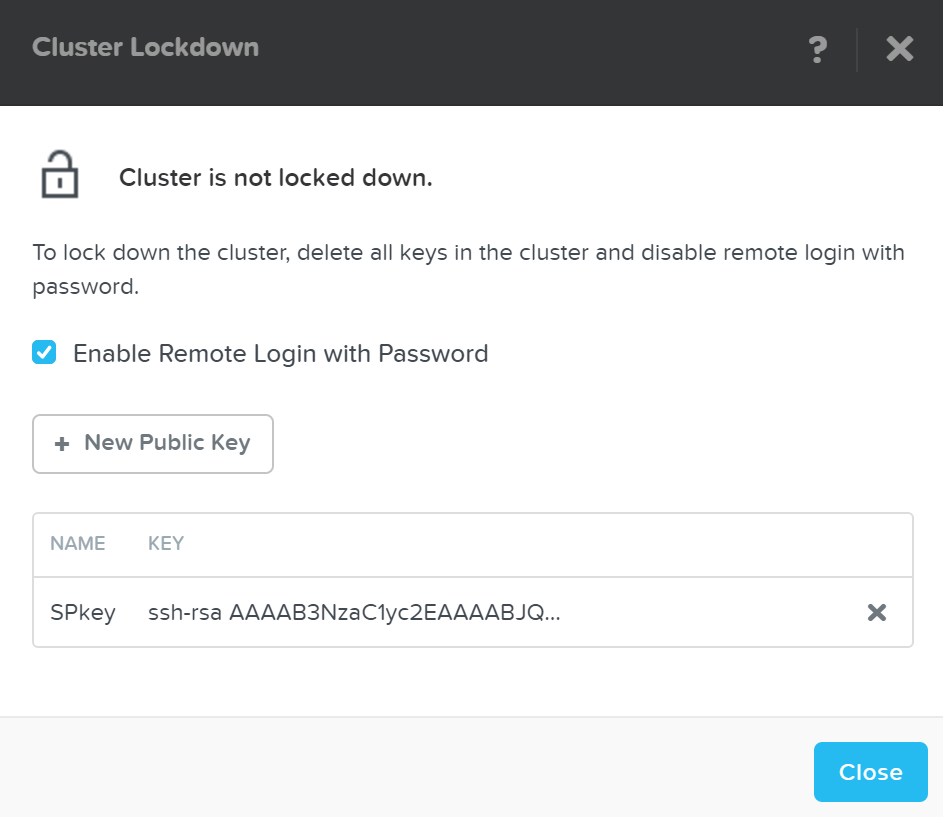
キーを追加するためには「New Public Key(新規パブリックキー)」ボタンをクリックし、キーの詳細内容を入力します:
SSHキーの処理
SSHキーを生成するためには、次のコマンドを実行します:
ssh-keygen -t rsa -b 2048
これで2つのキーペアが作成され、2つのファイルが生成されます:
- id_rsa(プライベートキー)
- id_rsa.pub(パブリックキー: クラスタにキーを追加する場合に使用します)
キーを作成し、これを使ってアクセスできることが確認されれば、「Enable Remote Login with Password(パスワードを使ったリモートログインを有効化する)」のチェックを外し、 パスワードベースのログインを無効化することが可能となります。確認のポップアップが表示されたら、「OK」をクリックしてロックダウンを有効化します。
データ暗号化とキー管理
データの暗号化とは、許可を受けた人のみがデータを理解でき、許可を受けていない人には意味不明なものにするためのデータのエンコード方法です。
例えば、メッセージを1人だけに送信する必要がある場合には、メッセージ(平文)を暗号(キー)で暗号化して、暗号化されたメッセージ(暗号文)を送信できます。 仮に、このメッセージが攻撃側に盗まれたり盗聴されたりしても、暗号化されたメッセージを、キーを使って復号化できなければ、暗号文を目にするだけとなります。 正しい相手がメッセージを受け取ると、送り手が提供したキーを使ってメッセージを復号化することができます。
データの暗号化には、いくつかの方法が存在します:
- 共通鍵暗号方式(プライベートキーを使った暗号化):
- 暗号化と復号化に同じキーを使用します
- 例: AES、PGP*、Blowfish、Twofishなど
- 公開鍵暗号方式(パブリックキーを使った暗号化):
- 暗号化と復号化に別々のキー(それぞれパブリックキーとプライベートキー)を使用します
- 例: RSA、PGP* など
注意: PGP(またはGPG)は、パブリックキーとプライベートキーの両方を使用します。
データの暗号化は、主に次のような状況で使用されます:
- 転送中のデータ(In-transit): 2つの関係者の間で転送されるデータ(ネットワーク経由のデータ転送など)
- 保管時のデータ(At-rest): 静的なデータ(デバイスに保存されているデータなど)
Nutanixは、ネイティブなソフトウェアベースの暗号化によって、(SEDの有無にかかわらず)転送中*、および保存時における暗号化の両方を解決します。 SEDのみをベースとした暗号化では、Nutanixは保管時のデータ暗号化を解決します。 *注:転送中の暗号化は、現在、Nutanixクラスタ内のデータRFに適用できます。
以下のセクションでは、Nutanixのデータ暗号化の方法と、キー管理オプションについて説明します。
データの暗号化
Nutanixは、主に3つの方法でデータの暗号化をサポートしています:
- AOS 5.5でリリースされた、ネイティブなソフトウェアベースの暗号化 (FIPS-140-2 Level-1)
- 自己暗号化ドライブ (SED: Self-encrypting Drives) の利用 (FIPS-140-2 Level-2)
- ソフトウェア + ハードウェアによる暗号化
暗号化は、ハイパーバイザーのタイプに応じて、クラスタまたはコンテナ単位で設定することが可能です:
- クラスタ単位の暗号化:
- AHV、ESXi、Hyper-V
- コンテナ単位の暗号化:
- ESXi、Hyper-V
注意: SEDを使用する場合、物理デバイスが自ら暗号化を行うため、暗号化の設定はクラスタ単位となります。
クラスタの暗号化の状況は、設定メニュー(歯車アイコン)から「Data-at-Rest Encription(保存データの暗号化)」を選択して確認できます。 ここで現在の状況確認と、暗号化の設定(現在有効化されていない場合)を行うことができます。
こちらは、クラスタ単位で暗号化が有効になっている例です:
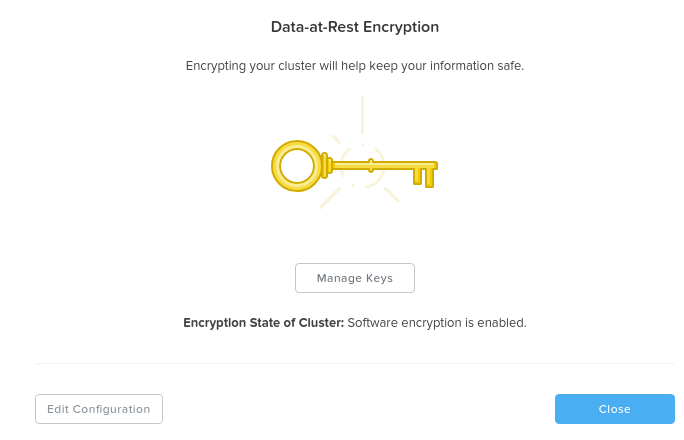
この例では、一覧にある特定のコンテナで暗号化が有効になっています:
「edit configuration(設定の編集)」ボタンをクリックすれば、設定を有効化または変更することができます。 暗号化に使用されているKMSの設定、または現在使用中のKMSのタイプを設定するメニューが表示されます。
外部のKMSを使用している場合は、このメニューのCSRリクエスト処理を使って、証明書を承認のためCA(認証局)に渡すことができます。
ネイティブなソフトウェアベースの暗号化
Nutanixのソフトウェア暗号化機能によって、保存データをAES-256でネイティブに暗号化することができます。 また、KMIPまたはTCG準拠の外部KMSサーバー(VormetricやSafeNetなど)や、AOS 5.8で発表されたNutanixネイティブのKMSともやり取りが可能です(以下に詳細)。 また、ソフトウェアによる処理の影響を最小限に抑えるため、システムはIntel AES-NIアクセラレータを使用して暗号化と復号化を行っています。
データが(OpLogやエクステントストアに)書き込まれると、チェックサムの境界でディスクに書き込まれる前に暗号化されます。 これは、データがローカルで暗号化され、そして暗号化されたデータがRFによってリモートのCVMに複製されることも意味します。
暗号化は、ディスクにデータが書き込まれる直前に実施されます。
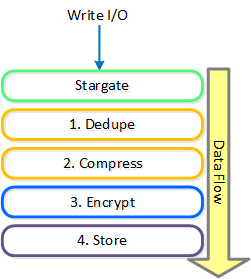
暗号化とデータ効率
重複排除と圧縮を行った後に暗号化を行うため、これらの手段によるスペースの節約状態はそのまま維持されます。 簡単に言えば、重複排除と圧縮の比率は、データを暗号化してもしなくてもまったく同じだということです。
チェックサムの境界でディスクから読み込まれた暗号化データは、復号化されてゲストに返されます。 復合化/暗号化をチェックサムの境界ごとに実施することで、読み込み増幅 (Read Amplification、余分な追加読み込み処理) が発生することはありません。 また、Intel AES-NIによって処理がオフロードされるため、パフォーマンスやレイテンシーにほとんど影響を与えることがありません。
SED Based Encryption
アーキテクチャーの概要を以下に図示します:
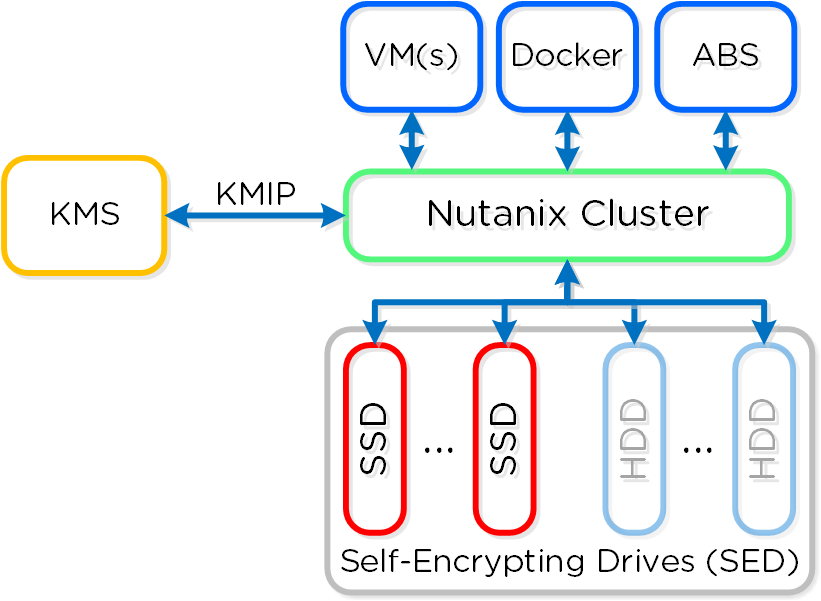
SED暗号化は、ストレージデバイスを安全な状態 (secured) または非安全な状態 (un-secured) のいずれかの状態にある、「データバンド (data bands)」に分解することで機能します。 Nutanixの場合には、ブートとNutanix Homeのパーティションを明示的に暗号化します。 全てのデータデバイスとバンドについては、Level-2に適合するよう、bit数の長いキー(big keys)を使った高度な暗号化が行われます。
クラスタが起動すると、KMSサーバーとのやり取りを行い、ドライブのロックを解除するためのキーを入手します。 安全性を確保するため、クラスタでキーをキャッシュすることはありません。コールドブートやIPMIリセットの場合、ノードはKMSサーバーをコールバックし、ドライブのロックを解除する必要があります。 CVMのソフトブートでは、この状況は発生しません。
キー管理 (KMS)
Nutanixは、他の専用KMSソリューションが提供する場合と同等の、キー管理機能(ローカルキー管理 - LKM)とストレージ機能(AOS 5.8から)をネイティブに提供しています。 これにより、専用のKMSソリューションが不要となり、システム環境をシンプル化できますが、外部のKMSのサポートも継続しています。
前のセクションで説明したように、キー管理はあらゆるデータ暗号化ソリューションにとって極めて重要な部分です。 非常にセキュアなキー管理ソリューションは、スタック全体で複数のキーを使用しています。
ソリューションで使用されるキーには、3つの種類があります:
- データ暗号化キー (DEK)
- データの暗号化に使用するキーです
- キー暗号化キー (KEK)
- DEKの暗号化に使用する暗号化キーです
- マスター暗号化キー (MEK)
- KEKの暗号化に使用する暗号化キーです
- ローカルキーマネージャーを使用している場合にのみ有効です
以下の図で、それぞれのキーの関係とKMSオプションを説明します。
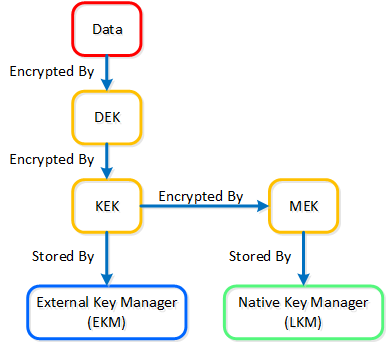
ローカルキーマネージャー (LKM) サービスは、すべてのNutanixノードに分散され、各CVMでネイティブに稼動します。 このサービスでは、FIPS 140-2暗号モジュールを(承認のもと)使用し、あらゆるキーの管理(キーの更新、キーのバックアップなど)をエンドユーザーに透過的に行うことができます。
データ暗号化の設定を行う場合、「Cluster’s local KMS(クラスタのローカルKMS)」を選択すれば、ネイティブのKMSを使用することができます:
マスターキー (MEK) は、シャミアの秘密分散法を使って分割され、クラスタのノード全体に保存されることで、耐障害性とセキュリティが確保されます。 キーを再構成する際には、Nをクラスタのノード数とした場合、最低でも ROUNDUP(N/2) (ノード数を2で割って小数点以下を切り上げた数)のノードが必要になります。
キーのバックアップとローテーション
暗号化を有効にした場合、データ暗号化キー (DEK) のバックアップを取っておくことをお勧めします。 バックアップを取った場合、強力なパスワードを設定し、安全な場所に保管するようにしてください。
KEKとMEKのローテーション(キー更新)をシステムで行うことが可能です。 マスターキー (MEK) を毎年自動的にローテーションするほか、必要に応じていつでもローテーションすることができます。 ノードを追加または削除した場合も、マスターキーのローテーションが行われます。
ストレージ
Nutanix AOSストレージは、ハイパーバイザーから集中ストレージアレイのように見えるスケールアウト ストレージ テクノロジーですが、全てのI/Oをローカルで処理することで最大のパフォーマンスを発揮します。 ノードがどのように分散システムを形成するかについての詳細は、次のセクションで説明します。
データ ストラクチャー
AOSストレージは、以下の要素で構成されています:
ストレージ プール
- 主な役割: 物理デバイスのグループ
- 説明: ストレージ プールは、クラスタのPCIe SSD、SSD、HDDデバイスを含む物理ストレージ デバイスのグループです。 ストレージ プールは、複数のNutanixノードにまたがることができ、クラスタの拡大に合わせ拡張することができます。 ほとんどの構成で単一のストレージ プールが使用されます。
コンテナ
- 主な役割: VM/ファイルの集合
- 説明: コンテナは、ストレージ プールの論理的なセグメントであり、VMまたはファイル (vDisk) のグループを含みます。 コンテナ レベルで複数の構成オプション(例えばRF)の利用が可能ですが、その適用は個別のVM/ファイル レベルになります。 通常コンテナは、データストアと1対1の関係になります(NFS/SMBの場合)。
vDisk
- 主な役割: vDisk
- 説明: vDiskは、AOS上の512KB以上のファイルで.vmdkファイルおよび仮想マシン ハードディスクを含みます。 vDiskは、論理的には「ブロックマップ」で作られたvBlockで構成されます。
最大AOS vDiskサイズ
AOS/Stargate側でvDiskのサイズに理論的な制限を加えることはありません。 AOS 4.6では、vDiskサイズは64ビット符号付整数を使ったバイト単位で表現されていました。 つまり、論理的なvDiskの最大サイズは、2^63-1 または 9E18 (9 Exabytes) となります。 この値を下回る制限があるとすれば、それはESXiの最大vmdkサイズなど、クライアント側の問題になります。
以下は、AOSとハイパーバイザーの関係を図示したものです:
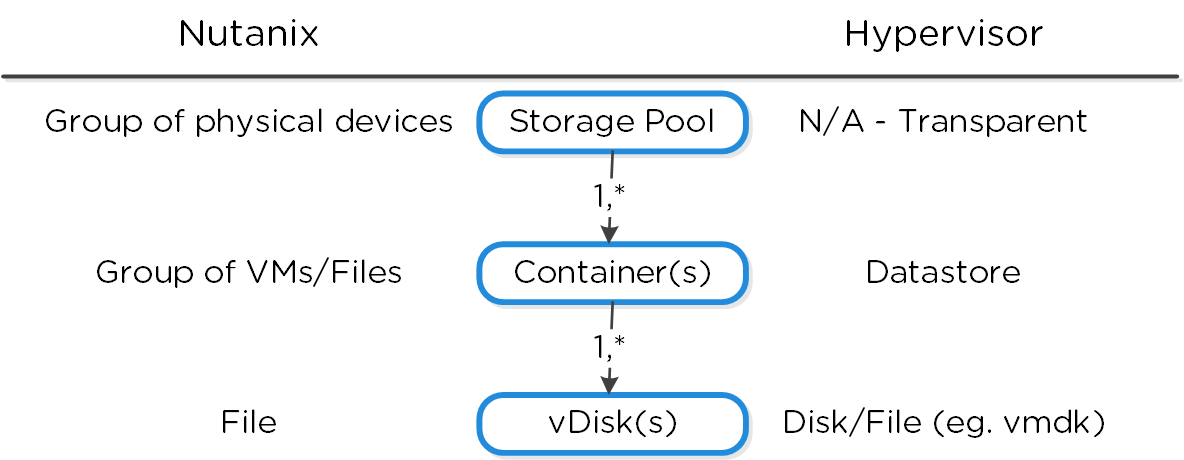
vBlock
- 主な役割: 1MBのvDiskアドレス空間のチャンク
- 説明: vBlockとは、vDiskを構成する仮想アドレス空間の1MBのチャンクのことです。 例えば、100MBのvDiskは100 x 1MBのvBlockを持ち、vBlock 0は0~1MB、vBlock 1は1~2MBといったものになります。 これらのvBlockはエクステントにマッピングされて、エクステントグループとして、ディスク上のファイルとして保存されます。
エクステント
- 主な役割: 論理的に連続したデータ
- 説明: エクステントは、論理的に連続した1MBのデータであり、n個(ゲストOSのブロックサイズに依存)の連続ブロックで構成されます。 細かな操作と効率を向上するため、エクステントは、サブエクステント(またはスライス)単位でWRITE/READ/MODIFYが可能です。 エクステントのスライスは、READまたはキャッシュされるデータ量に応じて、キャッシュに移される際にトリムされる場合があります。
エクステント グループ
- 主な役割: 物理的に連続したストアド データ
- 説明: エクステント グループは、1MBまたは4MBの物理的に連続したストアド データです。 データは、CVMがオーナーであるストレージ デバイス上のファイルとしてストアされます。 エクステントは、パフォーマンス向上のため、ノード/ディスク間でストライピングされるよう、動的にエクステント グループに分散されます。
- 注意:AOS 4.0の場合、データ重複排除機能に応じて、エクステント グループを1MBまたは4MBに設定できます。
以下は、前述の構成要素と各ファイルシスムの対応関係を図示したものです:
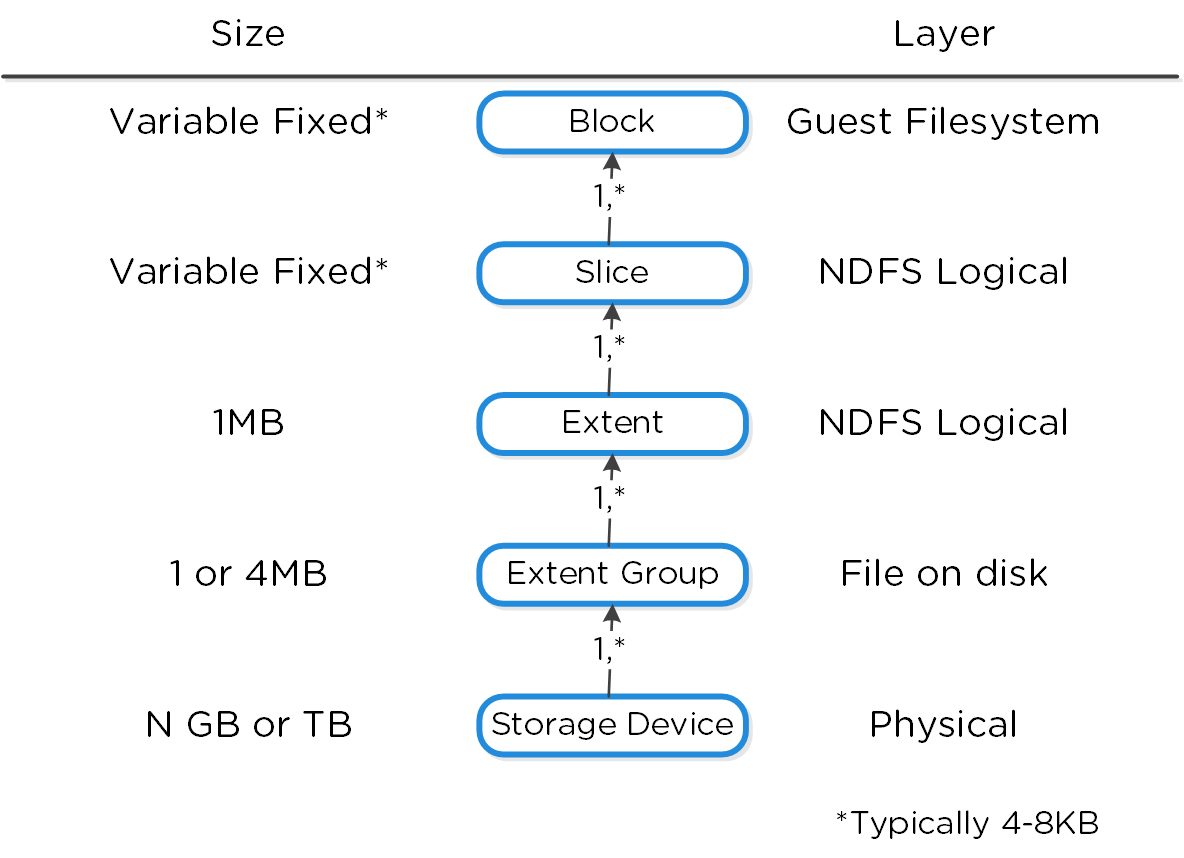
これらのユニットの関係は、以下のように図示することもできます:
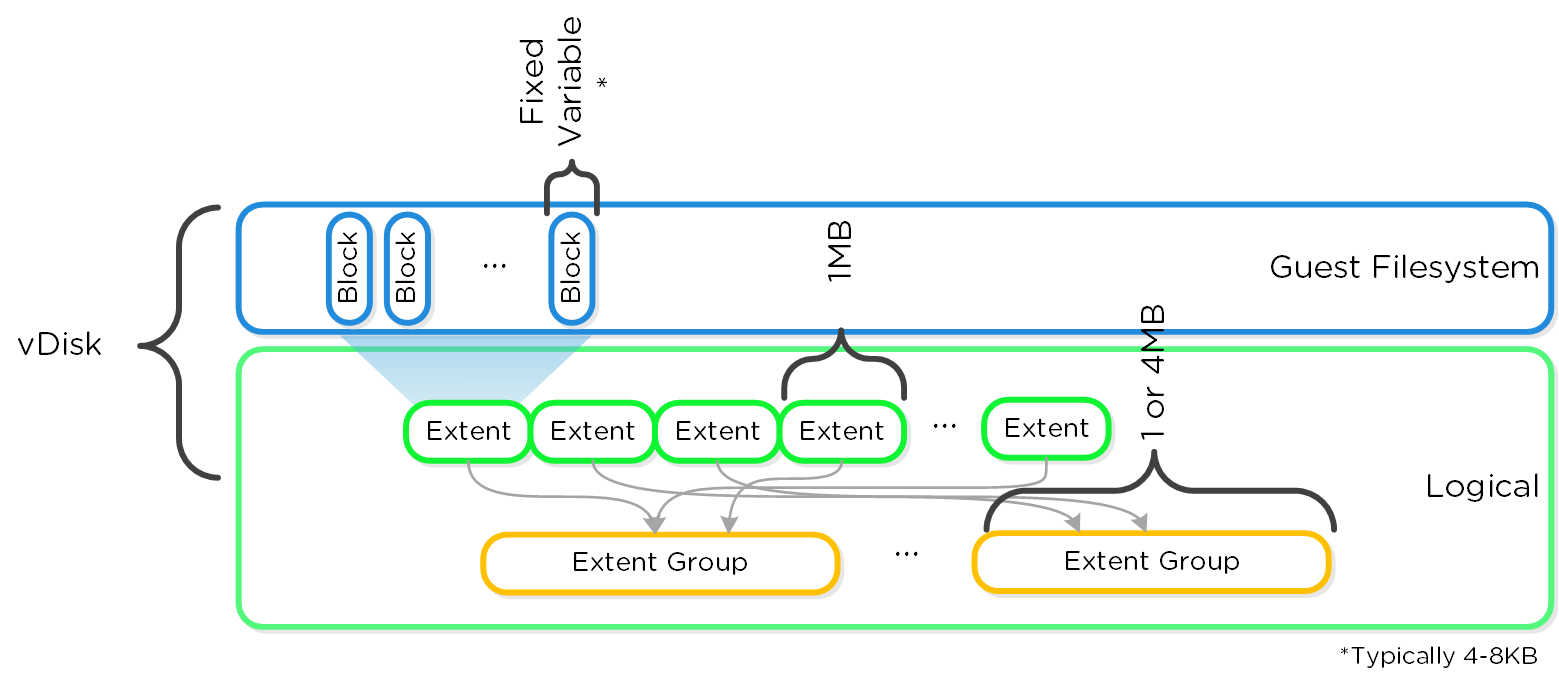
I/Oパスとキャッシュ
ビデオによる解説はこちらからご覧いただけます: LINK
一般的なハイパーコンバージドなストレージI/Oパスは、以下の層に分類できます:
- ゲストOS(UVM)から仮想ディスク
- これはNutanixでも変更されていません。 ハイパーバイザーに応じて、ゲストOSはデバイスドライバーを使用して仮想ディスクデバイスと通信します。 ハイパーバイザーによって、virtio-scsi(AHV)、pv-scsi(ESXi)などになります。 仮想ディスク(例えば、vmdk、vhdなど)についても、ハイパーバイザーによって異なります。
- ハイパーバイザーからAOS(CVM経由)
- ハイパーバイザーとNutanix間の通信は、CVMとハイパーバイザーのローカルインターフェイスで、標準的なストレージプロトコル(例えば、iSCSI、NFS、SMBv3)によって行われます。 この時点で、すべての通信はホストに対してローカルです(I/Oがリモートになるシナリオもあります。例えば、ローカルCVMのダウンなど)。
- Nutanix I/Oパス
- これはハイパーバイザーとUVMに対してすべて透過的であり、Nutanixプラットフォームにネイティブなものです。
NutanixのI/Oパスは、以下のコンポーネントで構成されています:
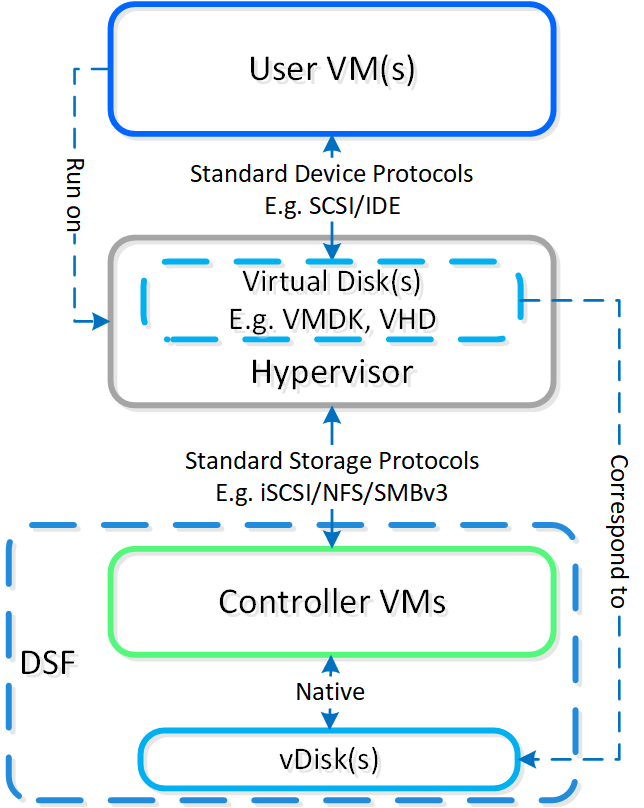
通信とI/O
CVM内では、StargateプロセスがすべてのストレージI/Oリクエストと、他のCVMや物理デバイスとの相互作用の処理を担当します。 ストレージデバイスコントローラーは直接CVMにパススルー接続されるため、すべてのストレージI/Oはハイパーバイザーをバイパスします。
以下の図は、これまでのI/Oパスの概要を示します:
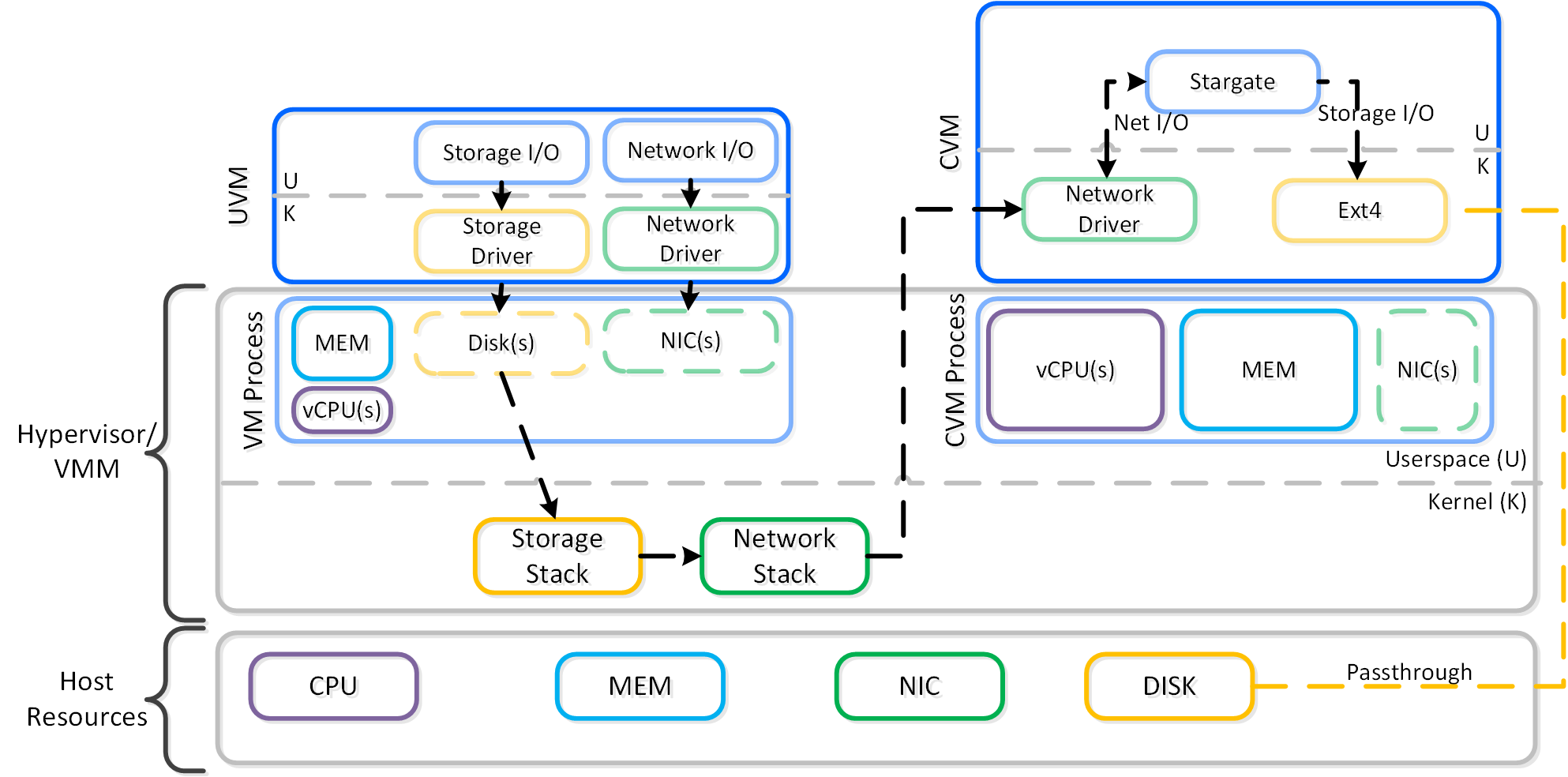
Nutanix BlockStore(AOS 5.18で出荷)はAOSの機能で、すべてがユーザー空間で処理される拡張可能なファイルシステムとブロック管理レイヤーを作成します。 これにより、デバイスからファイルシステムが排除され、ファイルシステムカーネルドライバーの呼び出しが削除されます。 新しいストレージメディア(例えば、NVMe)の導入により、 デバイスにはユーザー空間のライブラリが付属し、デバイスI/Oを直接処理(例えばSPDKで)することで、システムコール(コンテキストスイッチ)を行う必要がなくなりました。 BlockStoreとSPDKの組み合わせにより、すべてのStargateによるデバイスの相互作用がユーザー空間に移動し、コンテキストスイッチやカーネルドライバーの呼び出しが排除されました。
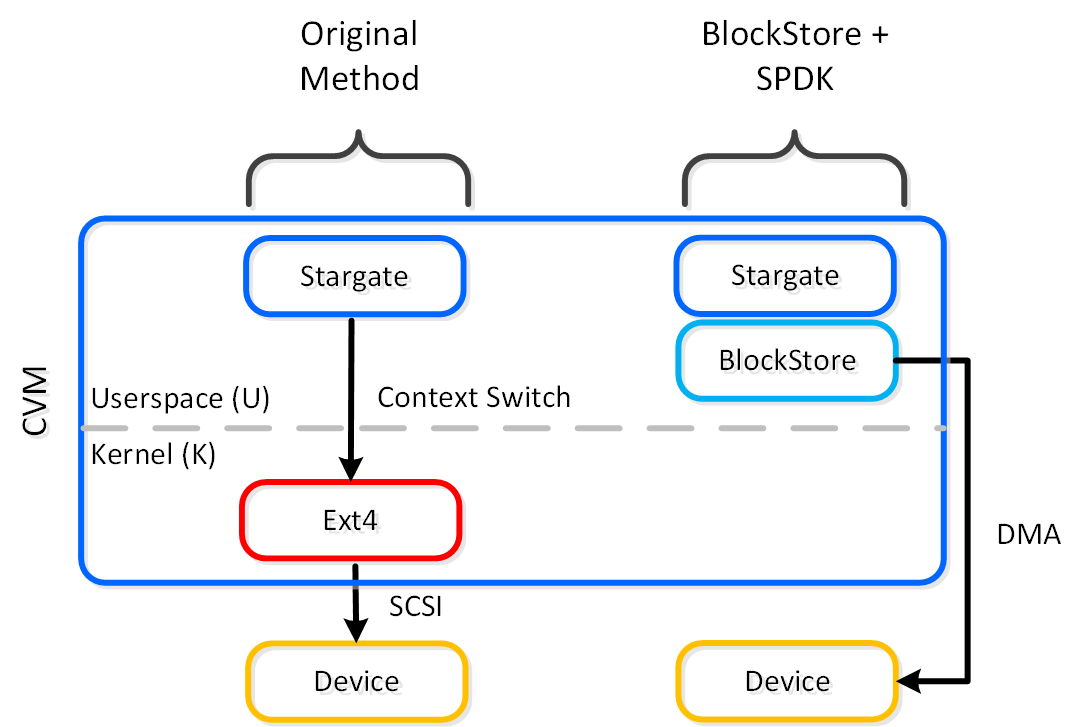
以下の図は、BlockStoreとSPDKを使用してアップデートされたI/Oパスの概要を示します:
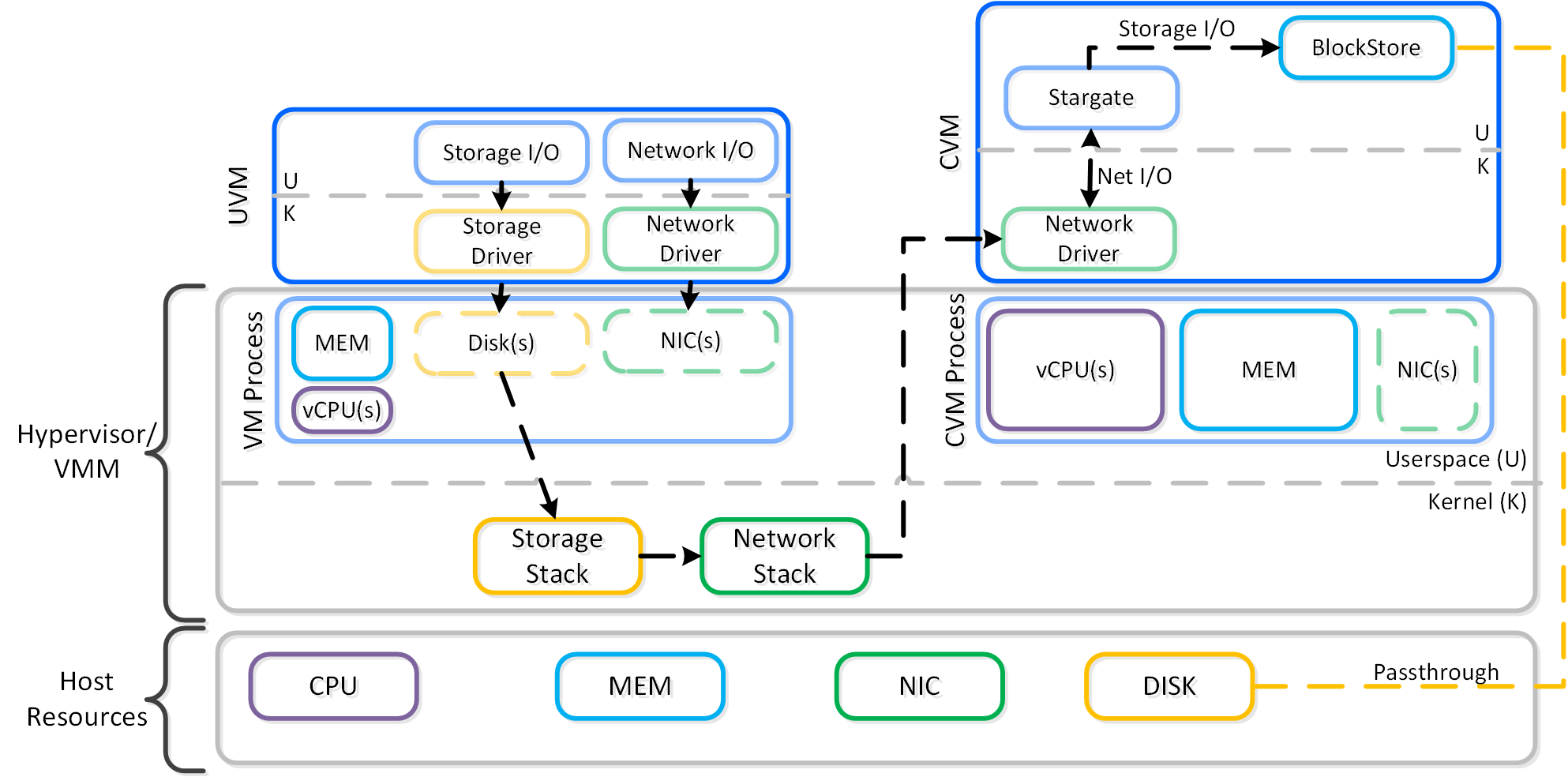
データ複製を実行するために、CVMはネットワークを介して通信します。 デフォルトのスタックでは、これはカーネルレベルのドライバーが呼び出されます。
しかし、RDMAを使用するとNICは割り込み処理を減らすためにハイパーバイザーをバイパスしてCVMにパススルー接続されます。 また、CVM内では、RDMAを使用するすべてのネットワークトラフィックは制御パスのみにカーネルレベルのドライバーを使用するため、実際のすべてのデータI/Oは、コンテキストスイッチなしでユーザー空間にて行われます。
以下の図は、RDMAを使用したI/Oパスの概要を示します:
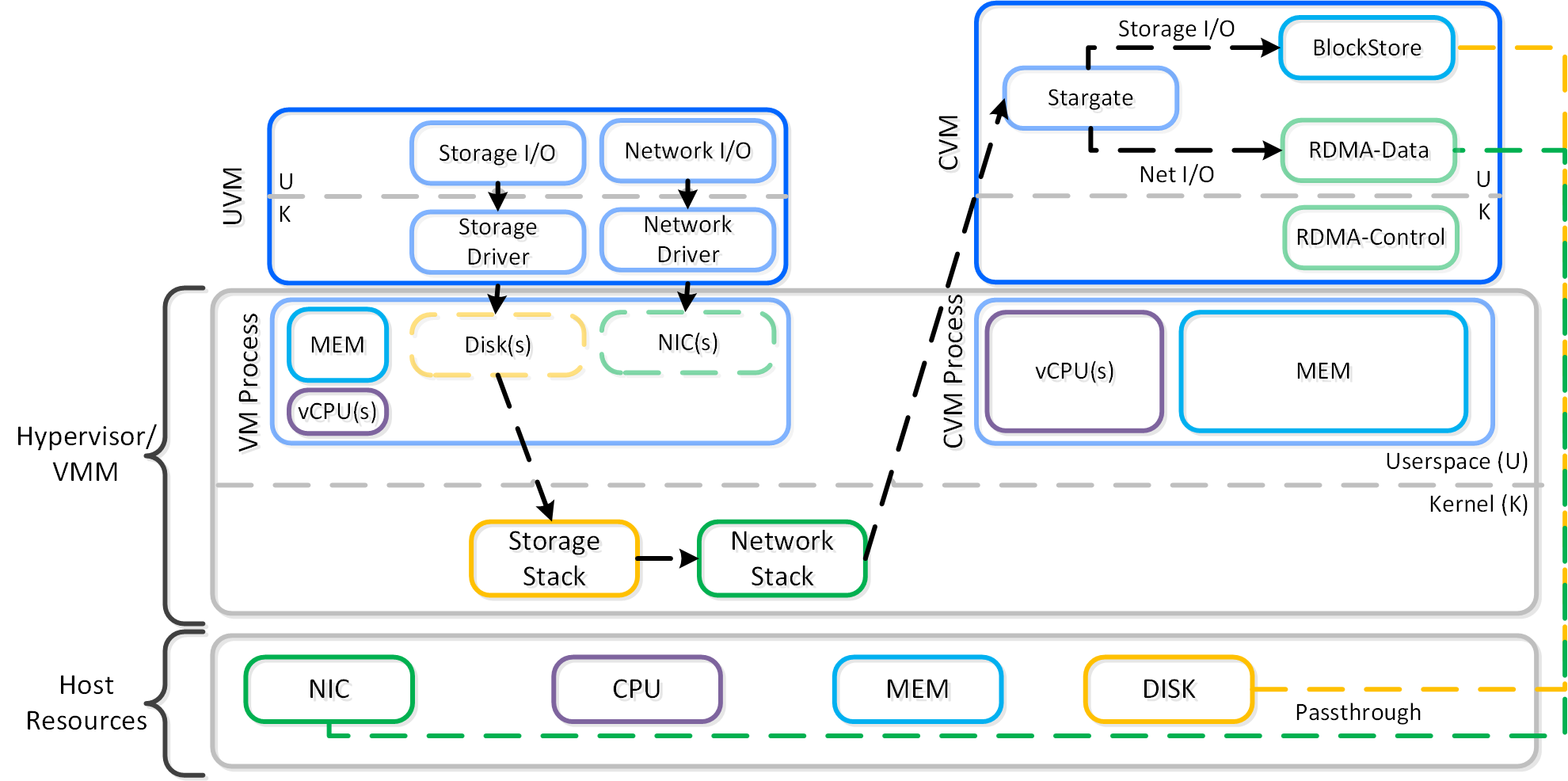
要約すると、拡張機能は以下のように最適化されます:
- PCIパススルーのデバイスI/Oはハイパーバイザーをバイパスします
- SPDKとBlockstoreは、カーネルストレージドライバーの相互作用を排除して、それらをユーザー空間に移動します
- RDMAはハイパーバイザーをバイパスして、すべてのデータ転送はCVMのユーザー空間で行われます
StargateのI/Oロジック
CVM内のStargateプロセスは、ユーザーVM(UVM)からの全てのI/O処理と永続化(RFなどによる)をハンドリングする責任を持ちます。 書き込みリクエストがStargateに届くと、そこには書き込み特性化の機能があり、突発的なランダム書き込みであればOpLog、持続的なランダム書き込みまたはシーケンシャルな書き込みであればエクステントストアに永続化します。 読み取りリクエストは、リクエストされた際にデータが存在する場所によって、OpLogまたはエクステントストアから読み取られます。
NutanixのI/Oパスは、以下の大まかなコンポーネントで構成されます:
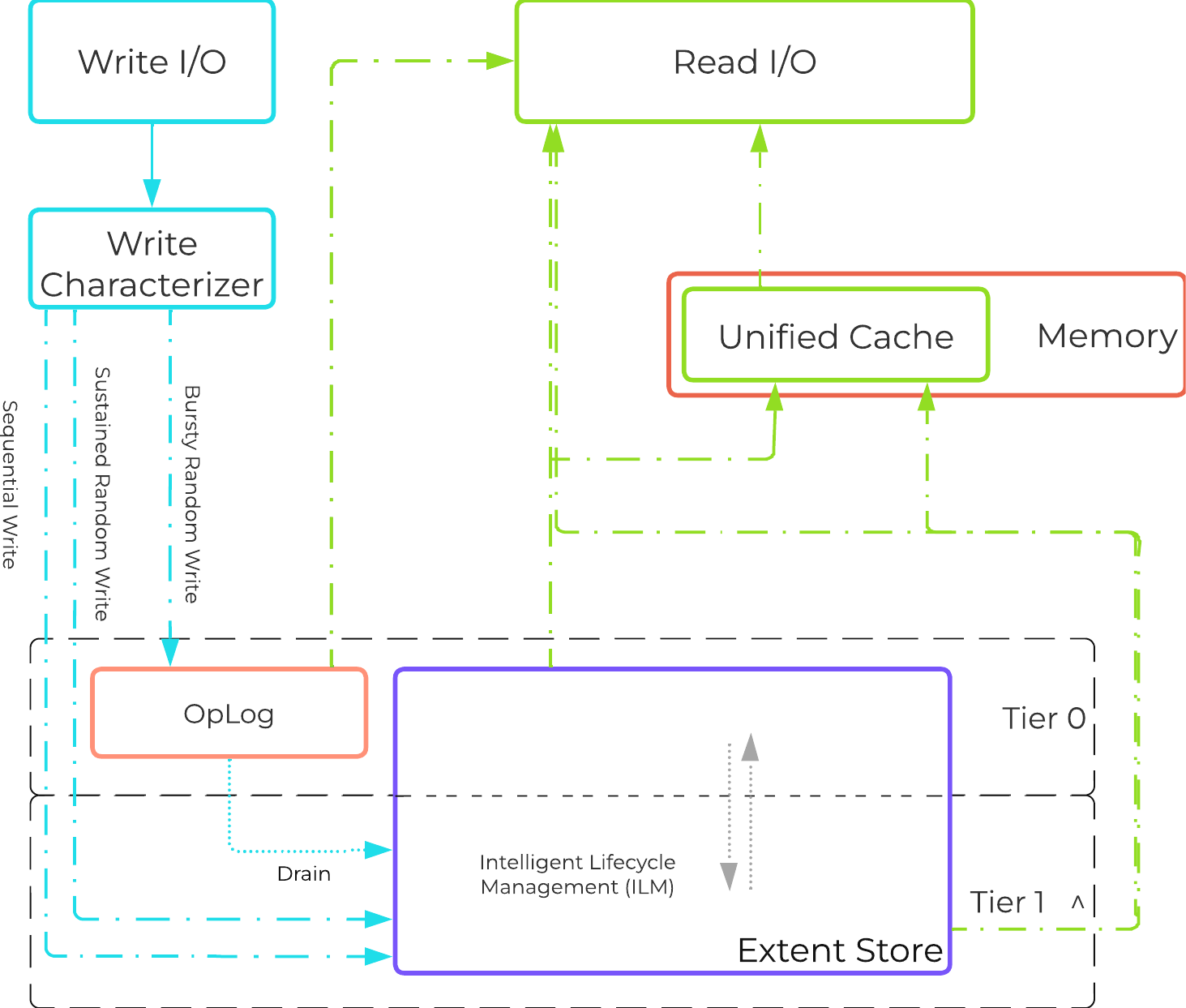
*AOS 5.10以降は、Autonomous Extent Store(AES)を使用して、必要条件が満たされたときにサステイン状態のランダムなワークロードを処理できます。
- オールフラッシュノード構成(All NVMe SSD、All SATA/SAS SSD、NVMe + SATA/SAS SSD)の場合、エクステントストアがSSDデバイスのみで構成され、フラッシュ層のみの存在となるため、ILM層は形成されません。
- Optaneが使用されている場合(例えば、Intel Optane + NVMe/SATA SSD)、最高パフォーマンスのメディアはTier 0になり、低パフォーマンスのメディアはTier 1になります。
- フラッシュとHDDを使用するハイブリッド構成のシナリオでは、フラッシュはTier 0で、HDDはTier 1になります。
- OpLogは、ハイブリッドクラスタでは常にSSD上にあり、Optane+NVMeのクラスタではOptaneとNVMe SSDの両方に存在します。
- データは、アクセスパターンに基づくIntelligent Lifecycle Management(ILM)によって層の間を移動されます。
OpLog
- 主な役割: 永続的なWRITEバッファ
- 説明:OpLogは、ファイルシステムジャーナルのような機能を持ち、大量のランダムWRITEを処理し、融合して(coalesce)、順次データをエクステントストアに送ります。 WRITE処理の場合、可用性を高める目的で、データの書き込みが完了する前にOpLogは異なるn個のCVMのOpLogに同期的にレプリケートされます。 全てのCVM OpLogが、レプリケーションを受ける対象となり、ロードに応じて動的に選択されます。 OpLogは、CVMのSSD層にストアされ、WRITE I/O、特にRANDOM I/Oワークロードに対して非常に優れたパフォーマンスを発揮します。 全てのSSDデバイスが、OpLogストレージの一部の処理を受け持ちます。 シーケンシャルなワークロードの場合、OpLogはバイパスされ、WRITEはエクステントストアに直接渡されます。 既に該当データがOpLogに存在し、エクステントストアに渡されていない場合、全てのREADリクエストは、エクステントストアにデータが渡るまでの間、OpLogから直接データを取得します。 その後、エクステントストア/コンテンツキャッシュからデータが提供されるようになります。 フィンガープリンティング(または重複排除)が有効化されているコンテナの場合、全てのWRITE I/Oは、ハッシュスキームを使用して採取されるため、コンテンツキャッシュ内のフィンガープリントを元に重複排除を行うことができます。
動的なOpLogサイジング
Oplogは共有リソースですが、それぞれのvDiskが平等に利用できるように、vDisk単位での割り当てが行われます。 AOS 5.19より前は、OpLogのサイズはvDiskごとに6GBに制限されていました。 AOS 5.19以降は、個々のvDiskのOpLogは、IOパターンの要求に従ってノードごとに使用されるOpLogインデックスメモリの上限まで、6GBを超えて拡張し続けることができます。 この設計上の決定により、I/Oの観点でアクティブなvDiskが少ない仮想マシンがある場合、アクティブでない他のvDiskを費やして、必要に応じてOpLogを拡張できるという柔軟性が得られます。
エクステントストア
- 主な役割: 永続的なデータストレージ
-
説明: エクステントストアは、AOSの永続的な大容量ストレージとして、すべてのデバイス層(Optane SSD、SATA SSD、HDD)に存在し、デバイス/層の追加を容易にできるよう拡張可能です。
エクステントストアに入っているデータは、次のいずれかです。
- A) OpLogから排出されたもの
- B) シーケンシャル/継続的な処理によりOpLogを経由せずに直接投入されたもの
シーケンシャルWRITEの属性付け
vDiskに対する1.5MB以上の未処理I/Oが残っている場合、WRITE I/Oはシーケンシャル処理であると見なされます(AOS 4.6の時点)。 この条件に該当する場合、データは既に整列済みの大きなかたまりとなっており、データを融合させることで生じるメリットがないため、OpLogを経由することなく、エクステントストアに対して直接I/Oが行われます。
これは次の Gflagによって制御されます:: vdisk_distributed_oplog_skip_min_outstanding_write_bytes.
大きなサイズ(例えば > 64K)を含む、その他すべてのI/OはOpLogによって処理されます。
自律型エクステントストア(AES:Autonomous Extent Store)
- 主な役割: 永続的なデータストレージ
- 説明: 自律型エクステントストア(AES)は、AOS 5.10で導入された、エクステントストアへのデータ書き込みおよび格納のための新方式です。 主にローカルおよびグローバルのメタデータ(詳細は以降の「拡張可能メタデータ」セクションを参照)を組み合わせて、メタデータのローカリティにより、より効率的なパフォーマンス維持を可能にします。 継続的なランダム書き込みのワークロードの場合、これらはOpLogをバイパスし、AESを使用してエクステントストアに直接書き込まれます。 バースト性のランダムなワークロードの場合は従来からのOpLogのI/Oパスを使用し、可能な場合はAESを使用してエクステントストアに排出します。 AOS 5.20 (LTS)時点では、オールフラッシュクラスタ上に新規作成されるコンテナでは、AESがデフォルトで有効になります。 そして、AOS 6.1(STS)以降で要件が満たされている場合には、ハイブリッド(SSD + HDD)クラスタで作成された新規コンテナではAESが有効になります。
ユニファイド キャッシュ(Unified Cache)
- 主な役割: 動的なREADキャッシュ
-
説明:ユニファイド キャッシュはデータ、メタデータ、そして重複排除で利用されるREADキャッシュで、CVMのメモリに存在します。
キャッシュに存在しない(または、特定のフィンガープリントが存在しない)データに対するREADリクエストが発生すると、データはエクステントストアから読み取られ、メモリに常駐するユニファイド キャッシュのシングルタッチプール
(single-touch pool)にも配置されます。そこでは、キャッシュから削除されるまでの間にLRU(least recently used)アルゴリズムを使用します。
続くREADリクエストは、マルチタッチプール(multi-touch Pool)に「移動」します(実際はデータが移動するのではなく、ただメタデータをキャッシュする)。
全てのマルチタッチプールに対するREADリクエストは、データをマルチタッチプールの最上部に移動させることになり、そこでは、新しいLRUカウンターが指定されます。
キャッシュサイズは、次の式で計算できます:
((CVM Memory - 12 GB) * 0.45)
例えば、32GBのCVMのキャッシュサイズは次のようになります:((32 - 12) * 0.45) == 9GB
以下は、ユニファイド キャッシュ の概要を図示したものです:
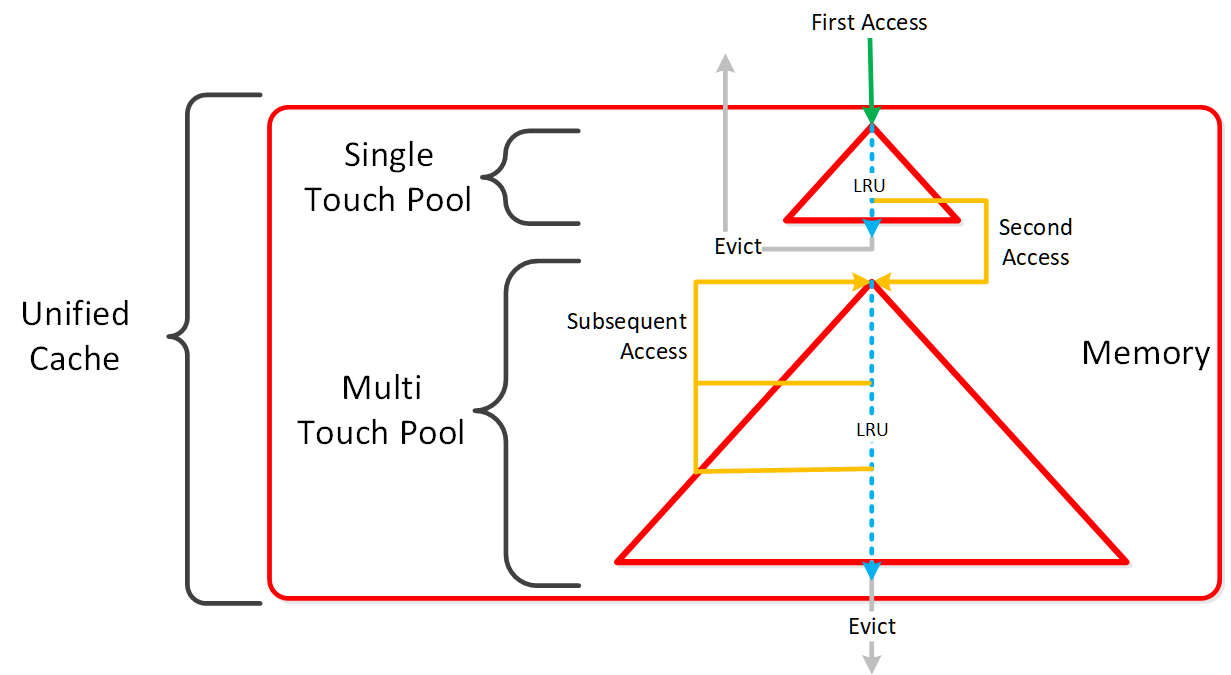
キャッシュの粒度とロジック
データは、4Kの粒度でキャッシュに格納され、全てのキャッシングはリアルタイムで行われます(例えば、データをディレイ処理したり、バッチ処理でデータをキャッシュに格納したりするようなことはありません)。
それぞれのCVMには、CVMがホストする(例えば同じノードで稼動するVMのような)独自に管理されたvDiskのためのローカルキャッシュがあります。vDiskがクローン(新しいクローンやスナップショットなど)されると、それぞれの新しいvDiskに個別にブロックマップが生成され、元のvDiskは変更不可とマークされます。これによって各CVMは、キャッシュコヒーレンシを保ちながら、元となるvDiskのキャッシュコピーをそれぞれに持つことが可能になります。
上書きが発生した場合、それは、VM自身のブロックマップにある新しいエクステントにリダイレクトされます。
単一vDiskのシャーディング
AOSは、大規模なアプリケーションのパフォーマンスを提供できるように設計および構築されています。 Stargateの内部では、I/Oは、vDiskコントローラーと呼ばれるものによって、作成されたvDiskごとに処理されています。 全てのvDiskは、Stargate内部でvDiskのI/Oを受け持つ、それ自身のvDiskコントローラーを取得します。 期待されていたのは、ワークロードやアプリケーションが複数のvDiskを持ち、それぞれがシステムとして高いパフォーマンスを駆動できる自身のvDiskコントローラースレッドを持つことでした。
このアーキテクチャーは、単一の大きなvDiskを持つ仮想マシンによる、従来のアプリケーションやワークロードの場合を除いて、よく機能していました。 これらの仮想マシンでは、AOSの機能を最大限に活用できていませんでした。 AOS 6.1以降では、vDiskコントローラーが機能拡張され、それぞれが自身のスレッドを持つコントローラーのシャードを作成することで、単一のvDiskへの要求が、現在では複数のvDiskコントローラーに分散されるようになりました。 複数のコントローラーへのI/O分散は、プライマリコントローラーによって行われ、外部とのやりとりでは単一のvDiskのように見えます。 その結果、単一のvDiskを効果的にシャーディングしてマルチスレッドにします。 この機能拡張と前述にあるBlockStoreやAESのような他のテクノロジーによって、AOSは、単一のvDiskを使用する従来型のアプリケーションに対しても、一貫した高いパフォーマンスを大規模に提供できます。
拡張可能メタデータ
YouTubeビデオによる解説はこちらからご覧いただけます:Tech TopX by Nutanix University: Scalable Metadata
メタデータは、インテリジェントなシステムの中心となるものですが、ファイルシステムやストレージアレイにとって非常に重要な存在となります。 「メタデータ」という用語についてわからないのであれば、本質的にメタデータは「データに関するデータ」です。 AOSという観点から、メタデータにはいくつかの重要な要素があります:
- 100%いかなる場合も一致すること(完全一致性)
- ACID準拠であること
- どんな規模にも拡張可能であること
- どんな規模でもボトルネックが発生しないこと(リニアに拡張できること)
AOS 5.10 以降のメタデータは、グローバルメタデータとローカルメタデータの2つの領域に分かれています(以前はすべてのメタデータがグローバルでした)。 これの動機は、「メタデータのローカリティ」を最適化し、メタデータ検索のためのシステムネットワークトラフィックを制限することです。
この変更の根拠は、すべてのデータがグローバルである必要はないということです。 例えば、すべてのCVMが、どの物理ディスク上に特定のエクステントが配置されているかを把握している必要はありません。 ただ、どのノードがそのデータを保持しているかのみ把握し、そしてそのノードが、データをどのディスクに保持しているのかを把握している必要があります。
これにより、システムに保存されるメタデータの量を制限(ローカルのみのデータのメタデータRFを排除)し、「メタデータのローカリティ」を最適化できます。
以下に、4ノードクラスタにおけるメタデータの追加/更新の例を図示します:
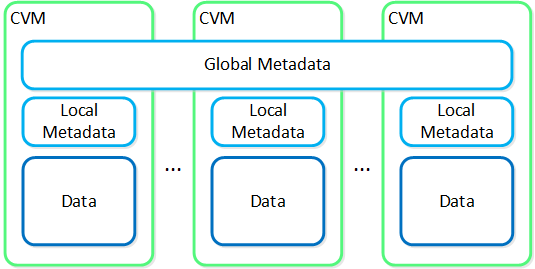
ローカルメタデータ
- 説明:
- ローカルノードでのみ必要な情報を含む、CVMごとのローカルメタデータストア。 これは、AOS 5.10で導入された自律型エクステントストア(AES)によって利用されます。
- ストレージのメカニズム:
- AES DB(Rocksdbベース)
- 格納されるデータの種類:
- 物理エクステントやエクステントグループの配置(例えば、egroupとディスクのマッピング)など
グローバルメタデータ
- 説明:
- すべてのCVMでグローバルに使用でき、クラスタ内のCVM全体にシャーディングされたメタデータ。 AOS 5.10より前のすべてのメタデータ。
- ストレージのメカニズム:
- Medusaストア(Cassandraベース)
- 格納されるデータの種類:
- vDiskブロックマップ、エクステントとノードのマッピング、時系列の統計情報、構成情報など
以下のセクションでは、グローバルメタデータによる管理方法について説明します:
前述のアーキテクチャーのセクションでも説明した通り、AOSはリング状のキーバリューストアを使用して他のプラットフォームデータ(例えばステータスデータなど)と同様に、不可欠なグローバルメタデータをストアしています。 グローバルメタデータの可用性と冗長性を確保するため、レプリケーション ファクタ(RF)が奇数になるように(例えば、3や5に)設定します。 メタデータに書き込みや更新が発生した場合、ロー(Row)データが該当するキーを持つリング上の特定ノードに書き込まれ、n個(nはクラスタサイズに依存)のノードにレプリケートされます。 データをコミットする前に、Paxosアルゴリズムを使って、過半数のノードでのデータ一致を確認します。 このようにして、プラットフォームにストアするデータやグローバルメタデータの完全一致性を確保します。
以下の図は、4ノードクラスタでのグローバルメタデータの挿入/更新処理について示します:
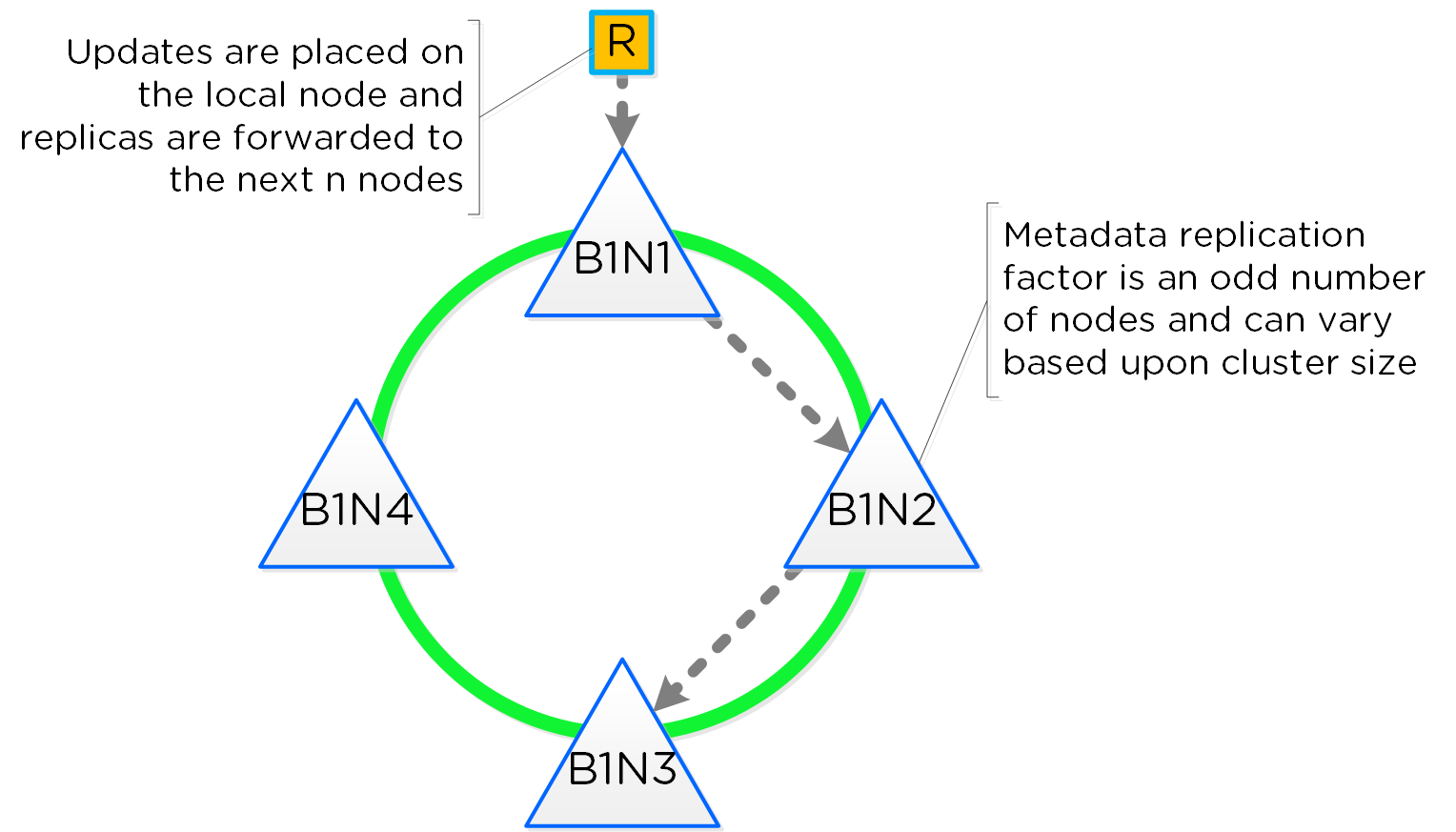
AOSのグローバルメタデータにとって、大規模な構成におけるパフォーマンスも重要な要素です。 従来のデュアルコントローラーや「リーダー/ワーカー」方式のモデルとは異なり、プラットフォーム全体のメタデータの管理をNutanixの各ノードが分担して実施します。 クラスタの全てのノードにメタデータを配置して操作できるようにすることで、従来のボトルネックを排除することができます。 クラスタサイズに変更を加える(つまりノードを追加あるいは撤去する)場合、キーの再配布を最小限に抑えるためのキーのパーティショニングに、コンシステントハッシュ法を使用します。 クラスタを拡張(例えば4ノードから8ノードに)する場合、新しいノードは、「ブロック アウェアネス」と信頼性を確保するため、リングを構成しているノードの間に追加されます。
以下に、グローバルメタデータの「リング」とその拡張方法を図示します:
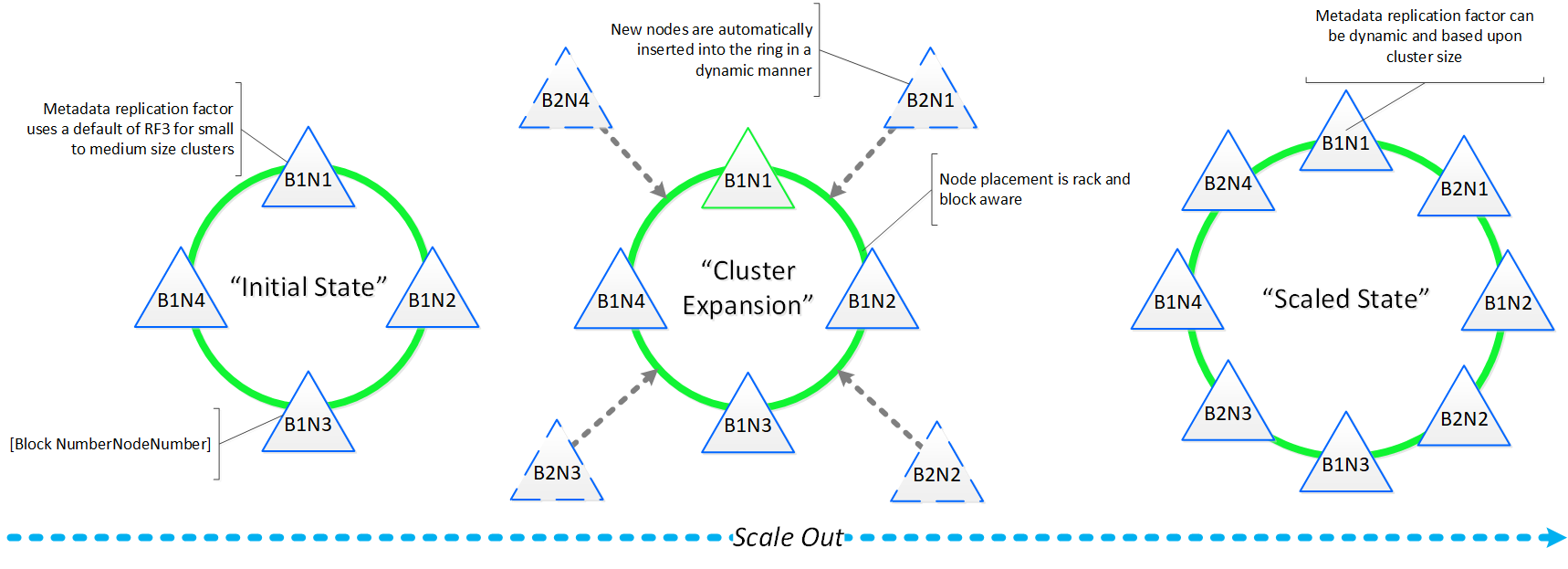
データ保護
ビデオによる解説はこちらからご覧いただけます:LINK
現在、Nutanixプラットフォームは、回復ファクタ (Resiliency Factor) あるいはレプリケーション ファクタ(RF - Replication Factor)と呼ばれる係数に加え、チェックサムを使用してノードまたはディスクの障害や破損時にデータの冗長性と可用性を確保するようになっています。 前述のように、OpLogは、取り込んだWRITEリクエストを低レイテンシーのSSD層で吸収するためのステージング領域として機能します。 データはローカルのOpLogに書き込まれると、ホストに書き込み完了のAckを返す前に、データを異なる1つまたは2つのNutanix CVMのOpLog(その数はRFに依存)に同期的にレプリケートします。 これにより、データは少なくとも2つまたは3つの独立した場所に存在することになり、フォールトトレランシーが確保されます。
注意:RF3の場合、メタデータがRF5となるため、最低でも5つのノードが必要となります。
OpLogのピアが一定単位毎(1GBのvDiskデータ)に選択され、全てのノードがこれに積極的に関与します。 どのピアが選択されるかという点については、複数の要因があります(例えばレスポンスタイム、業務、キャパシティの使用状況など)。 これによってフラグメンテーションの発生を防ぎ、全てのCVM/OpLogを同時に使用できるようになります。
データRFについては、Prismからコンテナレベルで設定を行います。 「ホットノード」の発生を防ぎ、リニアな拡張性能を維持するため、全てのノードをOpLogのレプリケーションに参加させます。 データが書き込まれている間にチェックサムが計算され、メタデータの一部としてストアされます。 その後データは、非同期的にエクステントストアに移され、RFが維持されていきます。 ノードやディスクに障害が発生した場合、データはクラスタ内の全ノードで再度レプリケートされ、RFを維持します。 データにREADが発生すると常に、データの正当性を確認するためチェックサムが計算されます。 チェックサムとデータが一致しない場合、当該データのレプリカが読み込まれ、不正なデータを置き換えます。
アクティブI/Oが発生しない場合でも一貫性を保つよう、データは継続的に監視されます。 ストレージのスクラブ処理は、エクステントグループを継続的にスキャンし、ディスクの使用率が低い時にチェックサムの検証を実施します。 これによって、ビットやセクターの毀損の発生からデータを保護します。
以下は、上記の解説を論理的に図示したものです:
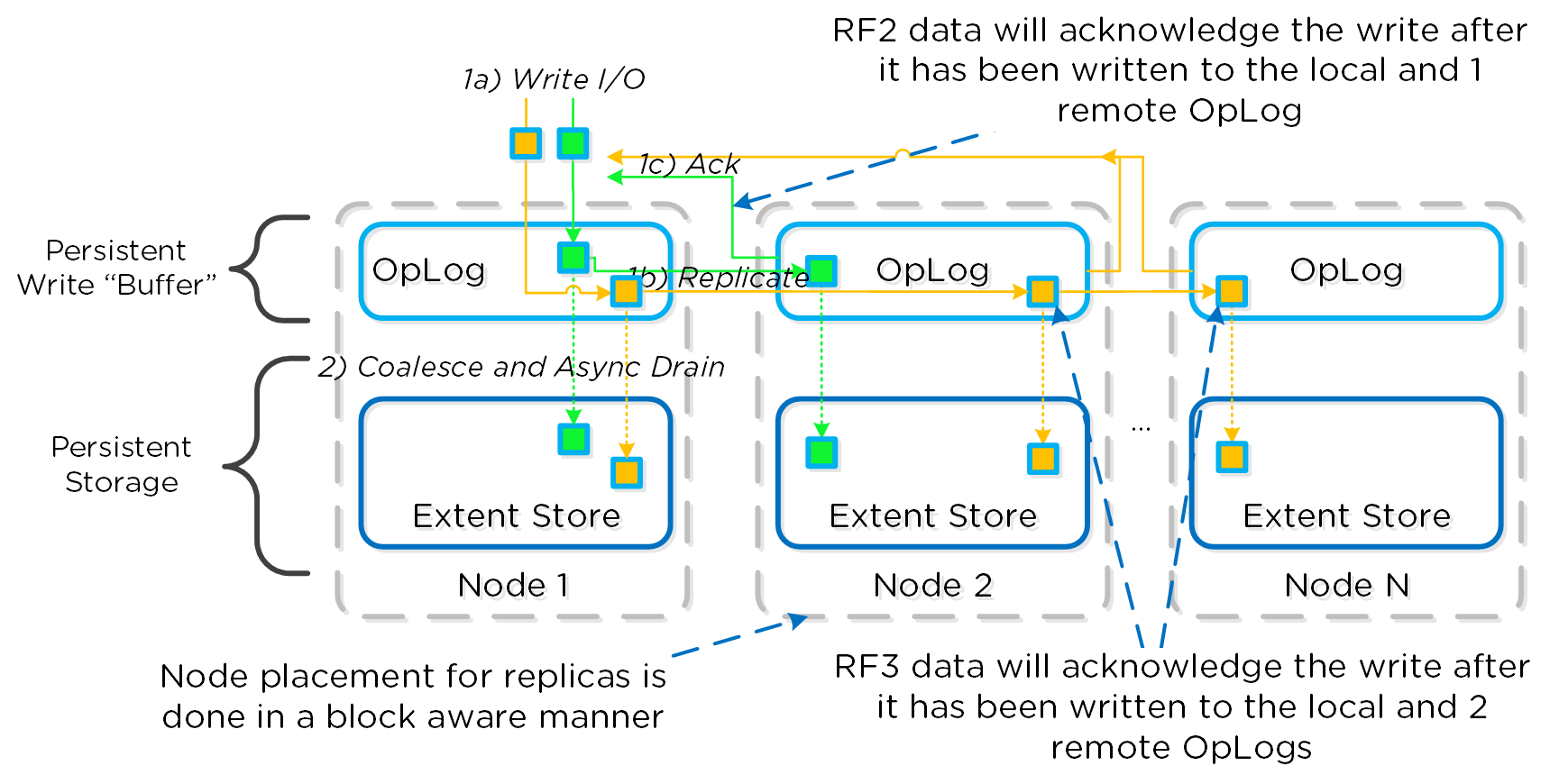
可用性ドメイン
ビデオによる解説はこちらからご覧いただけます:LINK
可用性ドメイン(またはノード/ブロック/ラック アウェアネス)は、コンポーネントやデータの配置を決定づける、分散システムにおける重要な要素です。 Nutanixは「ブロック」を、1、2または4つのサーバー「ノード」を含むシャーシ(筐体)として、「ラック」を1つ以上の「ブロック」を含む物理ユニットとして定義しています。
注意:ブロック アウェアネスな状態にするためには、最低3つのブロックが使用されている必要があります。 それ以外の場合はノード アウェアネスとなります。
Nutanixは現在、次のレベルまたはアウェアネスをサポートしています:
- ディスク(常に)
- ノード(常に)
- ブロック(AOS 4.5 以降)
- ラック(AOS 5.9 以降)
ブロック アウェアネスを確実に有効にするためには、ブロックを均一に配置することを推奨します。 一般的なシナリオと適用されるアウェアネスのレベルについては、本セクションの最後で説明します。 3ブロック必要となるのは、クォーラムを確保するためです。例えば3450は、4ノードで構成されるブロックです。 ブロック横断的にロールやデータを分散するのは、ブロックに障害が発生した場合やメンテナンスが必要な場合でも、システムを停止することなく稼動を継続できるようにするためです。
注意:ブロック内で唯一共有されているコンポーネントは、冗長構成のPSUとファンのみになります。
注: ラック アウェアネスでは、管理者がブロックを配置する「ラック」を定義する必要があります。
以下は、これがPrismでどのように構成されるかを示します:
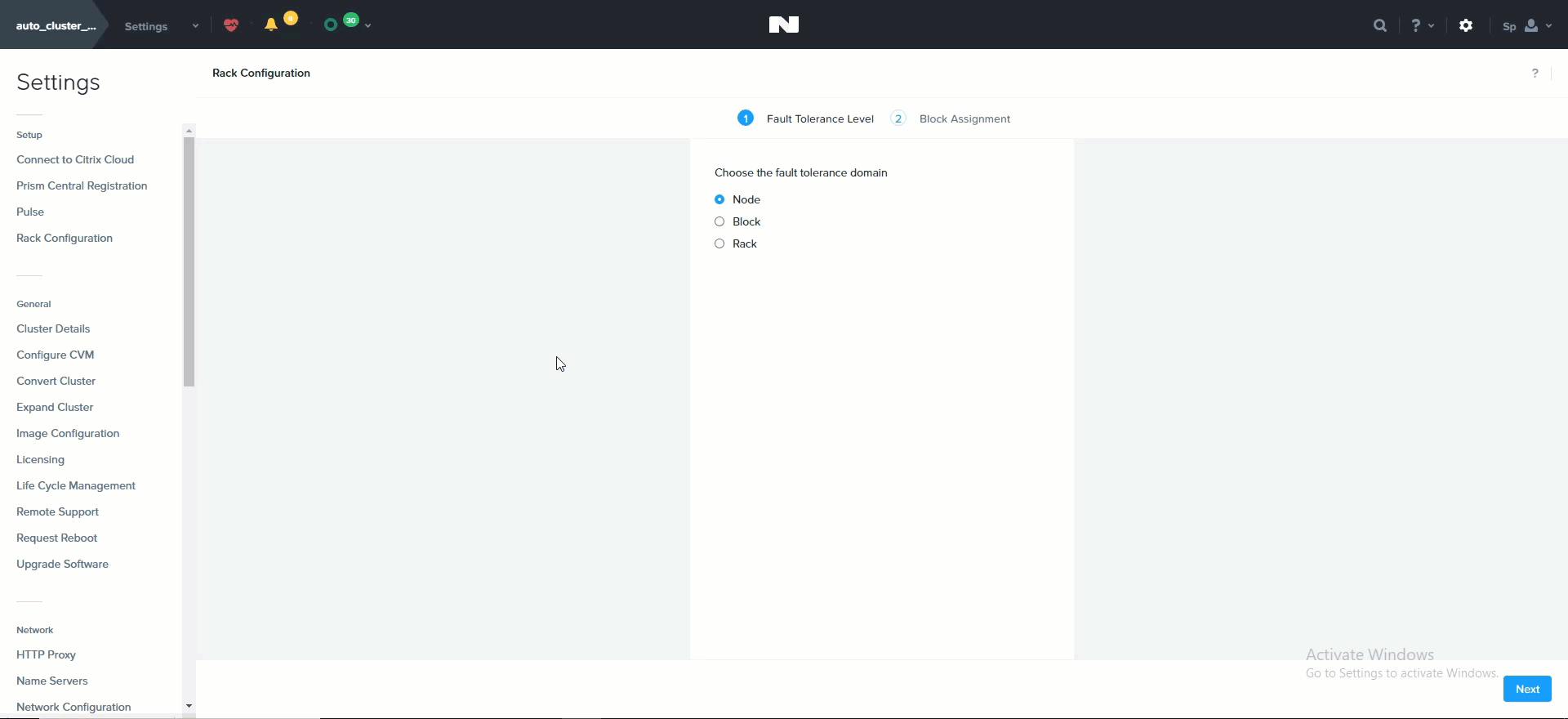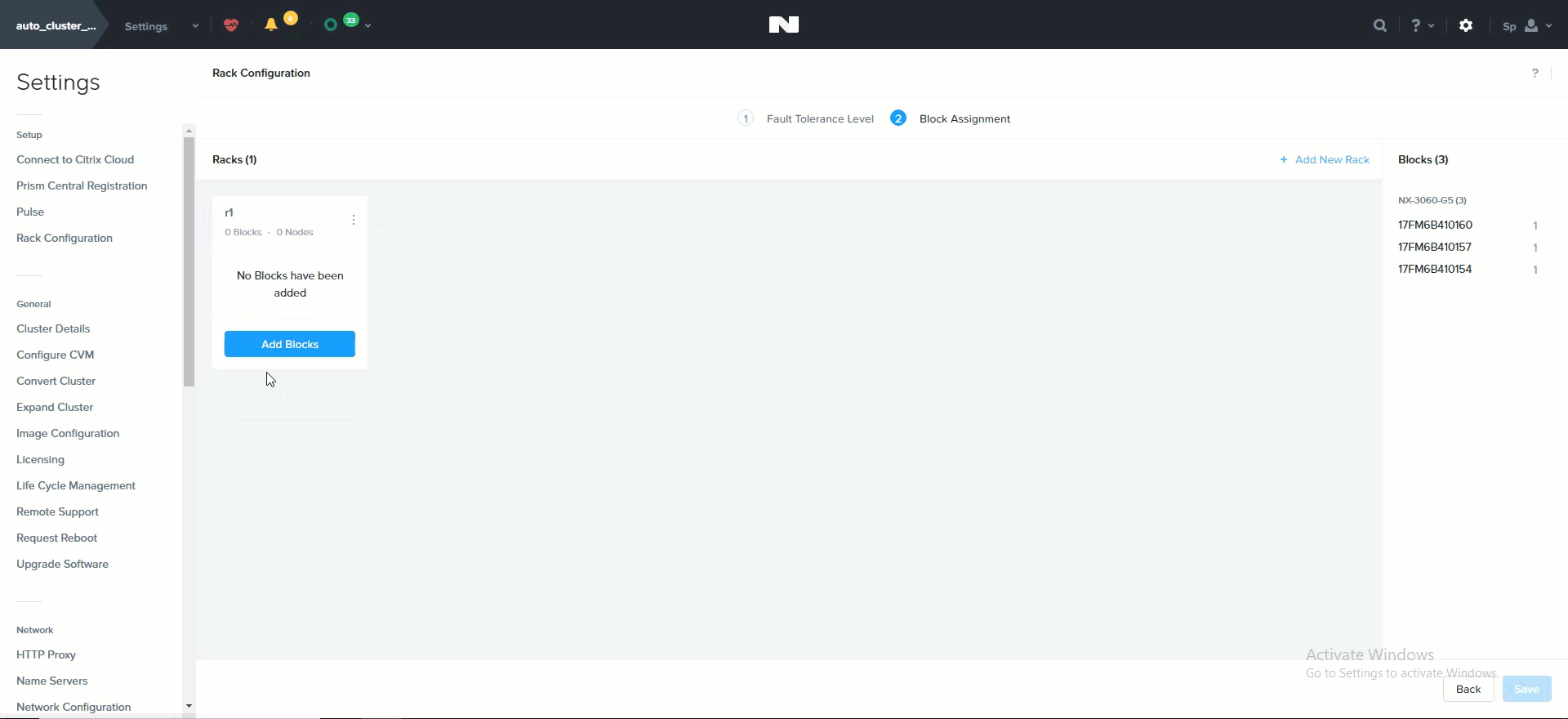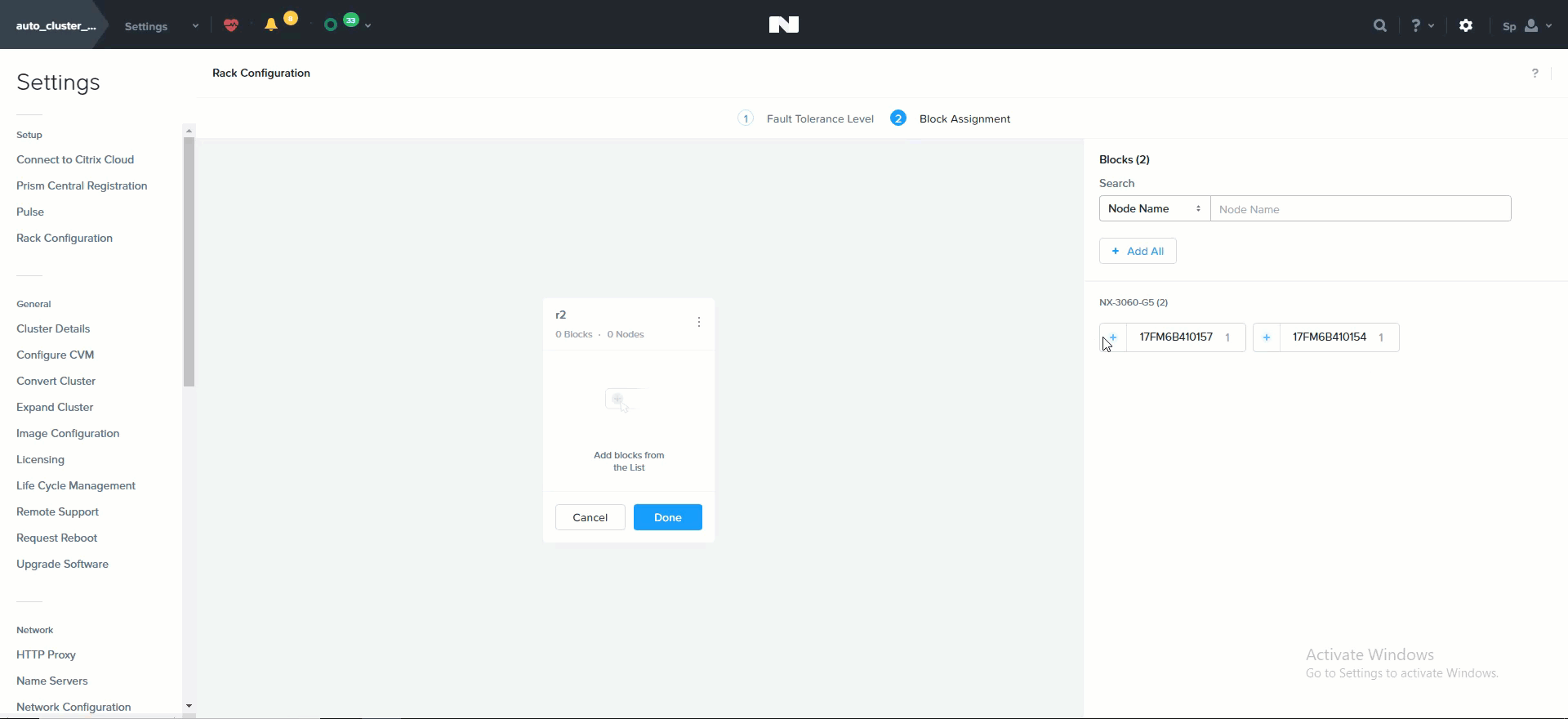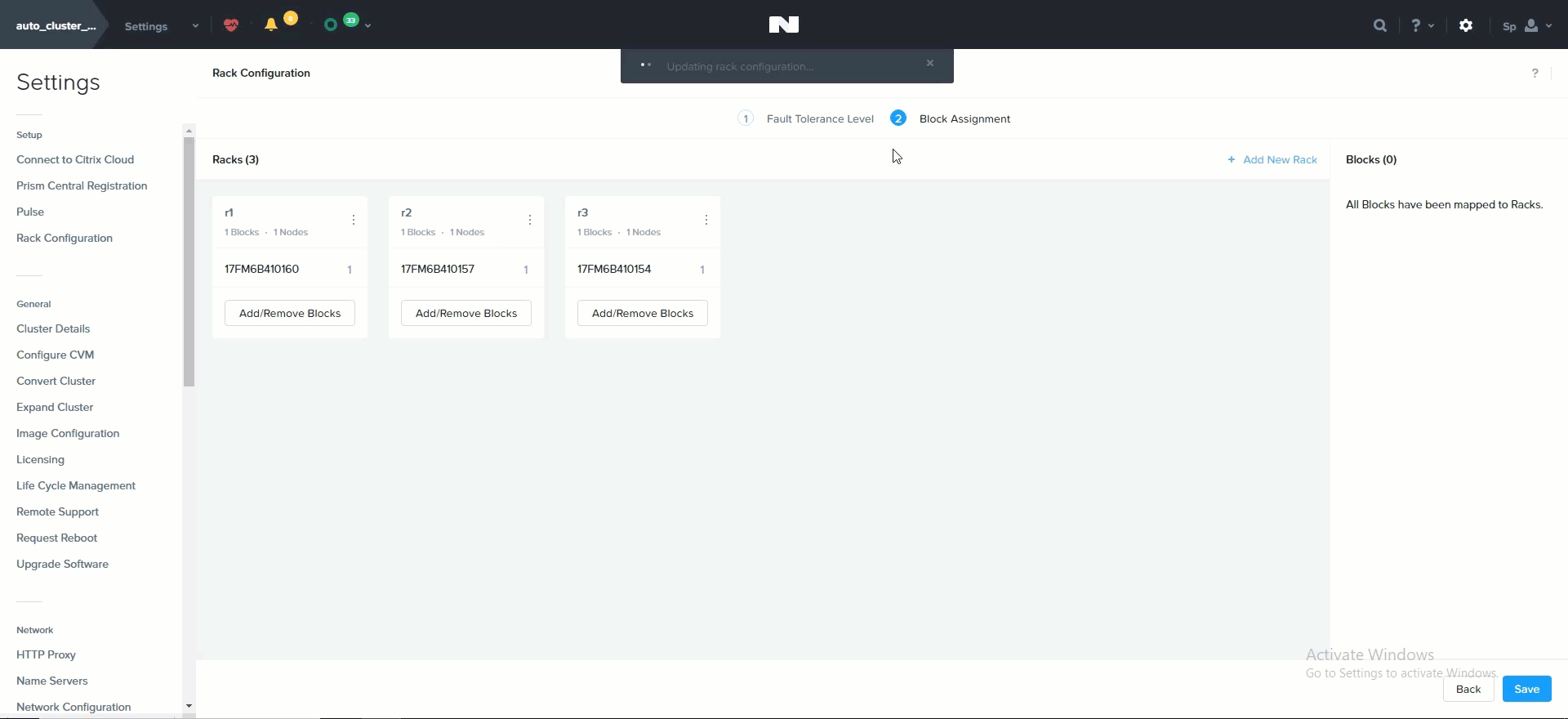
アウェアネスは、いくつかの重要な分野に分類されます:
- データ(VMデータ)
- メタデータ(Cassandra)
- 設定データ(Zookeeper)
データ
AOSによって、データのレプリカがクラスタ内の他の「ブロック/ラック」に書き込まれ、「ブロック/ラック」障害時や計画停止時でも、データは利用可能なままです。 これは、RF2とRF3の両方のシナリオで当てはまり、「ブロック/ラック」障害の場合も同様です。 考え方は、ノードに障害が発生した場合に備え、レプリカを異なるノードにレプリケーションしてデータを保護する「ノード アウェアネス」と同じです。 ブロックおよびラック アウェアネスは、「ブロック/ラック」停止した場合のデータの可用性を保証することにより、これをさらに拡張したものと言えます。
以下に、3ブロックの場合のレプリカの配置方法を図示します:
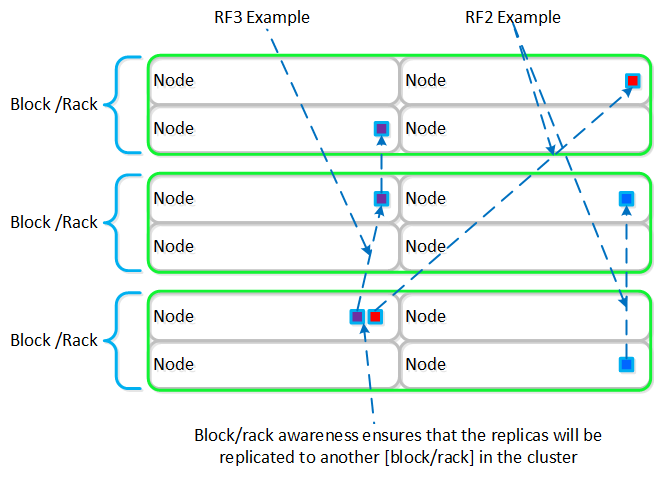
ブロック/ラックに障害が発生した場合でも、ブロック/ラック アウェアネスは維持され(可能であれば)、データブロックは、クラスタ内の異なるブロック/ラックにレプリケートされます。
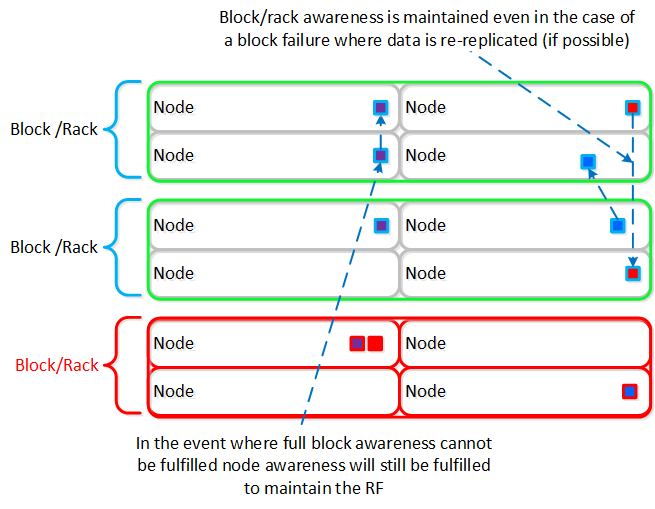
ラック/ブロック アウェアネス対メトロクラスタ
よくある質問として、クラスタを2つの場所(部屋、建物など)をまたぐように構成して、 ブロック/ラック アウェアネスを使用して、場所の障害に対する回復力を提供できるかどうかというものがあります。
理論的には可能ですが、これは推奨されるアプローチではありません。 まず、これで達成したいことについて考えてみましょう:
- 低いRPO
- 低いRTO(DRイベントではなくHAイベントにする)
最初のケースとして、0に近いRPOを達成しようとしている場合は、同期または同期に近い(near-synchronous)レプリケーションを利用することをお勧めします。 これにより、リスクの少ない同様のRPOを提供できます。
RTOを最小にするには、同期レプリケーション上でメトロクラスタを利用し、障害に対してDR復旧を実行する代わりにHAイベントとして処理します。
要約すると以下の理由により、同期レプリケーションやメトロクラスタリングを利用することが推奨されます:
- Sync Repやメトロクラスタリングを使用して同様の結果を達成して、リスクを回避し、障害ドメインを隔離しておくことができます。
- サポートされていない「ストレッチ」展開において2つの場所の間でのネットワーク接続がダウンした場合、クォーラムを維持する必要があるため、一方はダウンします (例えば、大多数の側はアップしたままとなります)。 メトロクラスタのシナリオでは、両側が独立して動作し続けることができます。
- データの可用性ドメインへの配置は、不均等なシナリオでのベストエフォートです。
- 両方のサイト間でのレイテンシーの追加やネットワーク帯域幅の減少は、「ストレッチ」展開のパフォーマンスに影響する可能性があります。
アウェアネスの条件とトレランス
一般的なシナリオとトレランスのレベルについて以下に説明します:
| 要求されるアウェアネスの種類 | FTレベル | EC有効か? | 最小ユニット | 同時故障への 耐性 |
|---|---|---|---|---|
| ノード | 1 | No | 3 ノード | 1 ノード |
| ノード | 1 | Yes | 4 ノード | 1 ノード |
| ノード | 2 | No | 5 ノード | 2 ノード |
| ノード | 2 | Yes | 6 ノード | 2 ノード |
| ブロック | 1 | No | 3 ブロック | 1 ブロック |
| ブロック | 1 | Yes | 4 ブロック | 1 ブロック |
| ブロック | 2 | No | 5 ブロック | 2 ブロック |
| ブロック | 2 | Yes | 6 ブロック | 2 ブロック |
| ラック | 1 | No | 3 ラック | 1 ラック |
| ラック | 1 | Yes | 4 ラック | 1 ラック |
| ラック | 2 | No | 5 ラック | 2 ラック |
| ラック | 2 | Yes | 6 ラック | 2 ラック |
AOS 4.5以降、ブロック アウェアネスはベストエフォートで実行され、厳しい実施条件などはありません。 これは、ストレージリソースが偏在(skew)している(ストレージが極端に大きいノードがある等)クラスタが、機能を無効にしないための措置です。 しかし、ストレージの偏在を最小に抑え、均一なブロックを用意する形が依然ベストプラクティスと言えます。
AOS 4.5より前のバージョンの場合、ブロック アウェアネスには以下の条件を満たすことが必要となります:
- 各ブロックのSSDまたは HDD層の数の相違が最大相違数を超える場合: ノード アウェアネス
- 各ブロックのSSDおよびHDD層の数の相違が最大相違数未満の場合: ブロック+ノード アウェアネス
(層の)最大相違数は、100 / (RF+1) として計算します
- 例えば、RF2の場合は33%、RF3の場合は25%となります
メタデータ
前述の「拡張可能メタデータ」のセクションで説明したように、Nutanixでは、メタデータや他の主要な情報をストアするために、Cassandraプラットフォームに大幅に手をいれています。 Cassandraは、リング状の構造を持ち、データの整合性と可用性を保つよう、リング内にn個のピア(peer)をレプリケーションしています。
以下は、12ノードクラスタのCassandraリングを図示したものです:
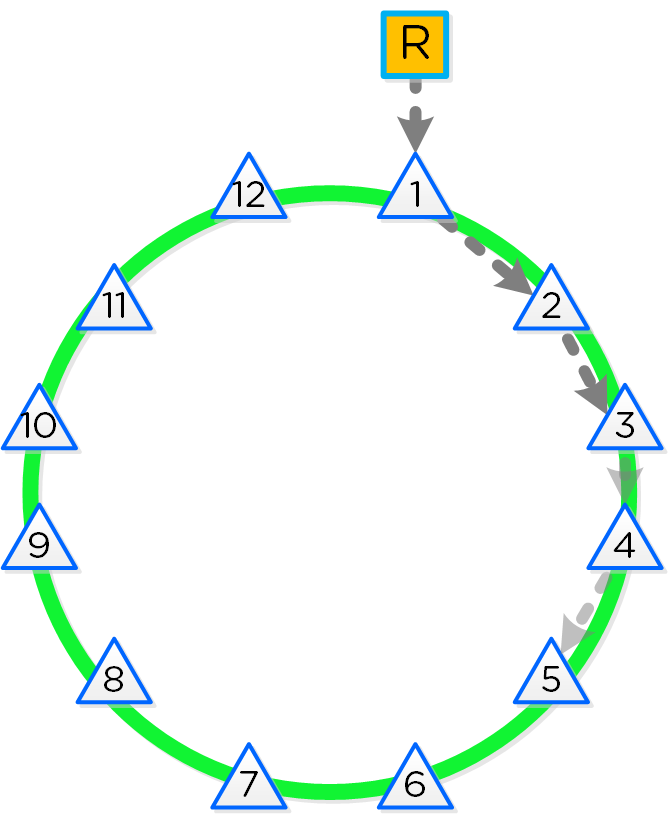
Cassandraのピアのレプリケーションは、リングを時計回りに移動しながら実施されます。 ブロック/ラック アウェアネスの場合、同じブロック/ラックにピアが2つ存在しないよう、ブロック/ラック間に分散されます。
以下は、上記のリングをブロック/ラックベースの表現に置き替えた内容を図示しています:
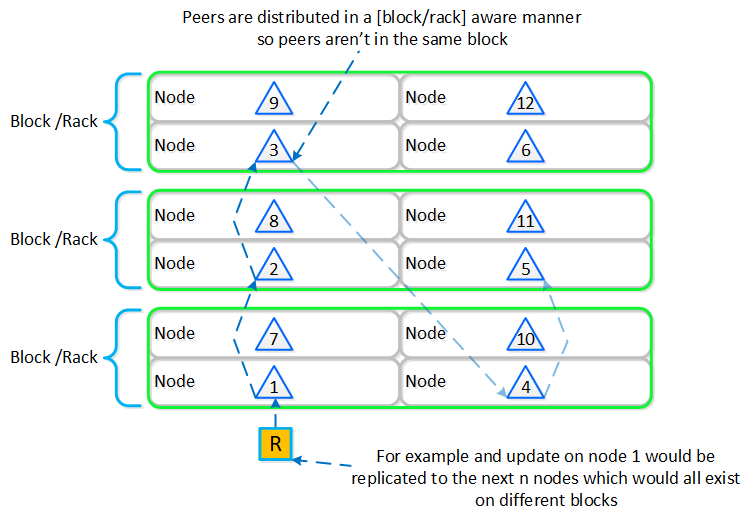
ブロック/ラック アウェアの特性により、ブロック/ラックに障害が発生しても、最低2つのデータコピー(メタデータRF3、さらに大規模なクラスタではRF5も可能)が存在することになります。
以下は、リングを形成する全ノードのレプリケーショントポロジーを図示したものです(やや複雑ですが):
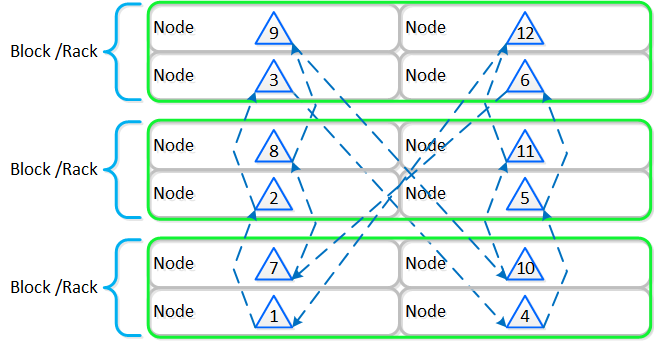
メタデータ アウェアネスの条件
以下に、一般的なシナリオと適用されるアウェアネスのレベルを示します:
- FT1(データ RF2 / メタデータ RF3)がブロック アウェアとなる条件:
- ブロック数 >=3 であること
- Xを、最大ノードを持つブロックのノード数とします。残りのブロックには最低でも合計2Xのノード数が必要です。
-
例:2、3、4および2つのノードを持つ4つのブロックの場合
- 最大ノードを持つブロックのノード数は4なので、残り3ブロックで 2x4=8 ノードを持つ必要があります。 この場合の残りのブロックのノード数合計は7なので、ブロック アウェアとはなりません。
-
例: 3、3、4および3つのノードを持つ4つのブロックの場合
-
最大ノードを持つノードのノード数は4なので、残り3ブロックで 2x4=8 ノードを持つ必要があります。
この場合の残りのブロックのノード数合計は9
なので、最小必要値を上回り、ブロック アウェアになります。
-
最大ノードを持つノードのノード数は4なので、残り3ブロックで 2x4=8 ノードを持つ必要があります。
この場合の残りのブロックのノード数合計は9
-
例:2、3、4および2つのノードを持つ4つのブロックの場合
- FT2(データ RF3 / メタデータ RF5)がブロック アウェアとなる条件:
- ブロック数 >=5 であること
- Xを、最大ノードを持つブロックのノード数とします。残りのブロックには合計最低でも4Xのノード数が必要です。
-
例: 2、3、4、2、3および3つのノードを持つブロックの場合
- 最大ノードを持つブロックのノード数は4なので、残り3ブロックで 4x4=16 ノードを持つ必要があります。 この場合の残りのブロックのノード数合計は13なので、ブロック アウェアになりません。
-
例: 2、4、4、4、4および4つのノードを持つブロックの場合
- 最大ノードを持つノードのノード数は4なので、残り3ブロックで 4x4=16 ノードを持つ必要があります。 この場合の残りのブロックのノード数合計は18なので、最小必要値を上回りブロック アウェアになります。
-
例: 2、3、4、2、3および3つのノードを持つブロックの場合
設定データ
Nutanixは、Zookeeperを使用してクラスタの基本的な設定データをストアしています。 この機能ついてもまた、ブロック/ラックに障害が発生した場合の可用性を維持するため、ブロック/ラック アウェアな方法で分散が行われています。
以下は、ブロック/ラック アウェアな方法で3つのZookeeperノードに分散された場合を例示したものです:
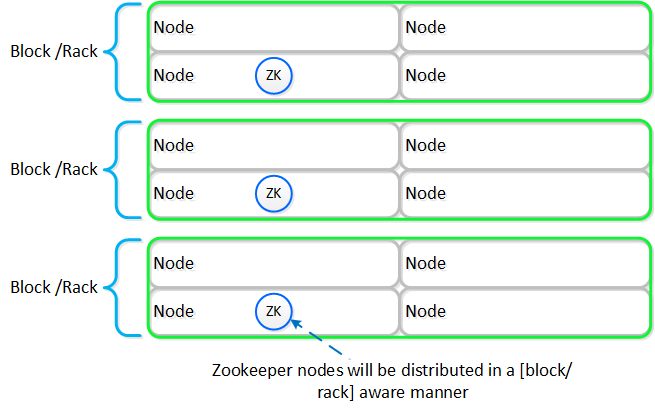
ブロック/ラックに障害発生した場合、つまりZookeeperの1ノードが停止した場合、Zookeeperの役割は、以下に示すようにクラスタ内の他のノードに引き継がれます:
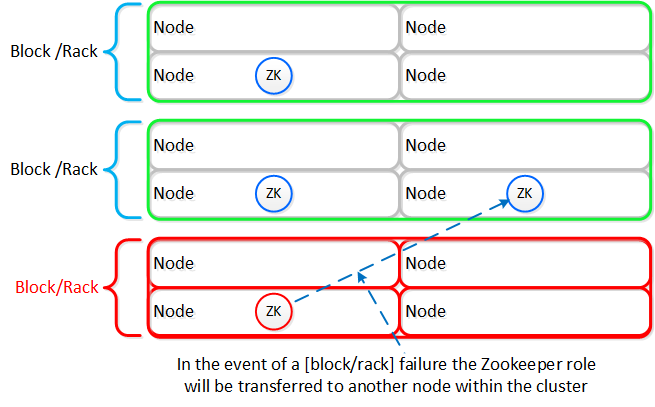
ブロック/ラックがオンラインに復帰した場合、ブロック/ラック アウェアネスを維持するためZookeeperの役割は元に戻されます。
注意: AOS 4.5より前のバージョンでは、この移行は自動的に実行されずマニュアルでの対応となります。
データパスの回復性能
AOSや従来のストレージプラットフォームの最も重要なコンセプトではないにしても、その信頼性と回復性能は最も重要な要素です。
Nutanixでは、ハードウェアの信頼性に重点を置いた従来のアーキテクチャーとは異なるアプローチを採用しています。 Nutanixは、ハードウェアがいずれは障害を起こすことを前提にしています。 従ってシステムは、このような障害に対して的確に、そして稼動を維持したままで対処できるようデザインされています。
注意: これはハードウェアの品質の問題ではなくコンセプトの変化です。 NutanixのハードウェアおよびQAチームは、徹底的な品質チェックと審査プロセスを実施しています。
前のセクションで説明した通り、メタデータおよびデータは、クラスタのFTレベルに基づくRFを使って保護されています。5.0では、FTレベルとしてFT1とFT2がサポートされ、それぞれがメタデータRF3とデータRF2に、またはメタデータRF5とデータRF3に対応しています。
メタデータの共有方法に関する詳細については、前述の「拡張可能メタデータ」セクションをご覧ください。また、データがどのように保護されるかに関する詳細は、前述の「データ保護」セクションをご覧ください。
通常状態におけるクラスタのデータレイアウトは、以下に示すようになります:
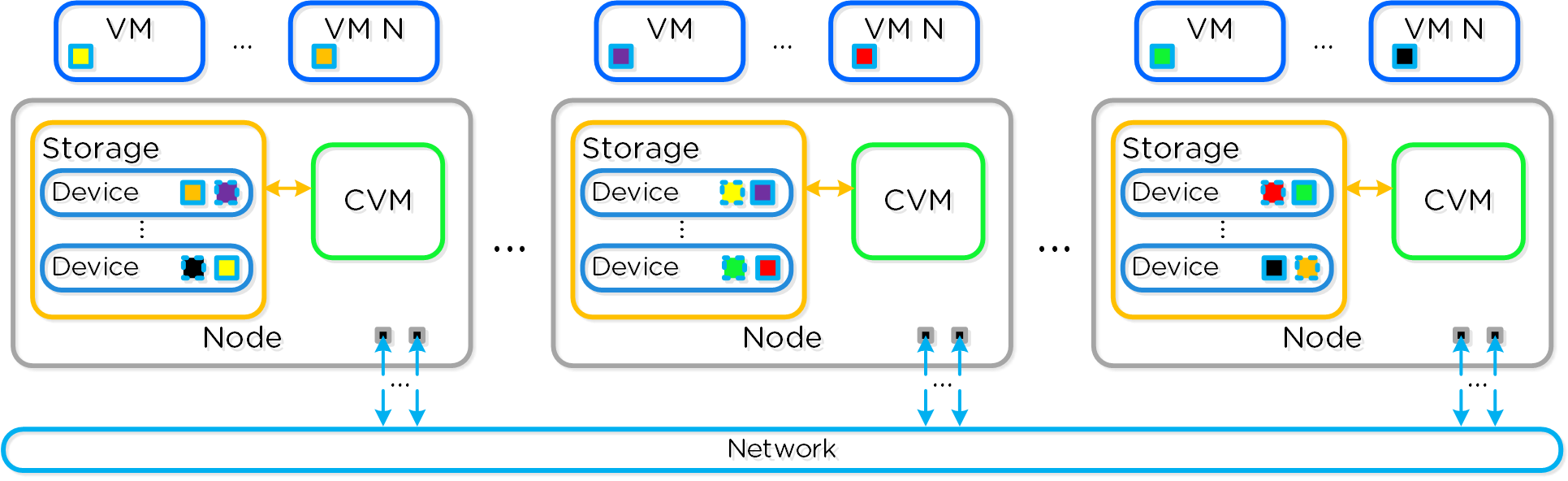
図に示す通り、VM/vDiskのデータがノード間に分散したディスクおよび関連するストレージデバイス上に、2つまたは3つコピーされています。
データ分散の重要性
メタデータおよびデータを全てのノードとディスクデバイスに分散させることで、通常のデータ投入や再保護処理の際に最大のパフォーマンスを発揮できるようになります。
データがシステムに投入されると、プライマリとセカンダリのコピーがローカルおよび他の全てのリモートノードにコピーされます。これによってホットスポットの発生(ノードやディスクのスローダウン)を回避し、一定のWRITEパフォーマンスを得ることができます。
ノードを再度保護する必要があるディスクやノード自体に障害が発生した場合、クラスタの全能力を使ってリビルドを実施します。(障害発生ディスクのデータ検索およびレプリカの存在場所を特定するための)メタデータのスキャンは、CVM全体で均等に分散する形で実施されます。データのレプリカが特定できると、正常なCVMとディスクデバイス(SSDとHDD)、さらにホストネットワークのアップリンクを同時に使用してデータをリビルドします。
例えば、4ノードのクラスタでディスク障害が発生した場合、それぞれのCVMは、25%のメタデータのスキャンとリビルドを実施します。10ノードのクラスタの場合であれば、それぞれのCVMが10%、さらに50ノードのクラスタの場合であれば、それぞれのCVMは、2%分を担当することになります。
重要点: Nutanixは、データを均一に分散することによって一定のパフォーマンスを維持し、遙かに優れた再保護処理を実施できるようになっています。そして、これはクラスタ全体の処理(例えば、消失訂正符号や圧縮、重複排除など)にも適用されます。
HAのペアを使用したり、データの全てのコピーを単一のディスクに保存したりしている他のソリューションの場合には、ミラーノードやディスクが切迫した状態となった際(重いI/Oやリソース競合の発生などの際)に、フロントエンドでパフォーマンス問題が発生する可能性があります。
また、データを再保護する必要のある場所で障害が発生すると、単一のコントローラーやノードの単一のディスクリソース、そして単一のノードのアップリンクによって制約を受けることになります。 テラバイト級のデータを再度レプリケートしなければならない場合には、ローカルノードのディスクやネットワークのバンド幅について大きな制約を受けることになり、その間に別の障害が発生すると、データを喪失してしまう危険性が高まることになります。
想定される障害レベル
AOSは分散システムとして、コンポーネント、サービス、そしてCVMの障害に対処するよう設計されていますが、障害は幾つかのレベルに分類できます:
- ディスク障害
- CVMの「障害」
- ノード障害
いつリビルドが始まるのか?
予期しない障害が発生した場合(正常に機能していない場合はプロアクティブにオフラインにして)、即座にリビルドプロセスを開始します。
60分待機しててリビルド開始し、その期間中に1つのコピーのみ維持する一部の他ベンダーとは異なり (非常に危険であり、何らかの障害が発生するとデータロスにつながる可能性があります)、 潜在的に高いストレージ使用率を犠牲にして、そのリスクを取るつもりはありません。
これができる理由は次の仕組みによります。 a)メタデータの粒度で、 b)書き込みRFのピアを動的に選択し(障害が発生している間、すべての新しいデータ(例えば、新しい書き込み/上書き)は構成された冗長性を維持します)、 c)リビルド中にオンラインに戻ってくるデータは検証されたら再収容できます。 このシナリオでは、データが「過剰複製」される可能性がありますが、Curatorスキャンが開始されると、過剰複製されたコピーが削除されます。
ディスク障害
ディスクが削除された場合、障害が発生した場合、応答がない場合、またはI/Oエラーが発生した場合には、ディスク障害と位置付けられます。 StargateのI/Oエラーやデバイス障害頻度が一定のしきい値を超えると、ディスクがオフライン状態にあると判断します。 この状態になると、HadesがS.M.A.R.Tを実行してデバイスの状態をチェックします。テストにパスすれば、ディスクはオンライン状態にあると認識し、そうでなければオフラインのままの状態とします。 Stargateが複数回(現在は1時間に3回)ディスクのオフラインを認識すると、S.M.A.R.Tのテストにパスしていても、ディスクはオンライン状態から外されます。
VMの影響:
- HAイベント: なし
- I/O障害: なし
- レイテンシー:影響なし
ディスク障害が発生した場合、Curatorスキャン(MapReduceフレームワーク)が直ちに実施されます。 そして、メタデータ(Cassandra)をスキャンし、障害が発生したディスクがホストしていたデータおよび、レプリカをホストしているノード / ディスクを検索します。
「再レプリケーション」が必要なデータを発見した場合、クラスタ内のノードに対してレプリケーションの指示を行います。
この処理の間に、Drive Self Test (DST) が不良ディスクに対して実行され、SMARTのログでエラーを監視します。
以下は、ディスク障害と再保護の例になります:
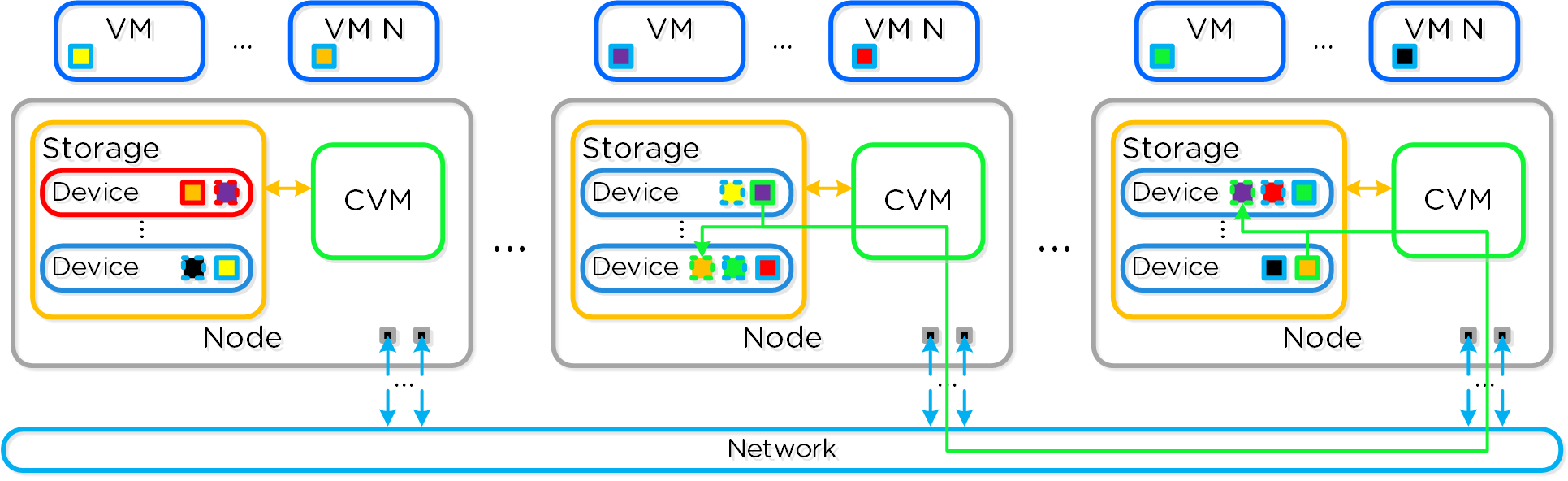
ここで重要となるのは、Nutanixの場合、データは全てのノード、CVM、ディスクにまたがって分散およびレプリケートされることと、全てのノード、CVM、ディスクが再レプリケーションに関わるということです。
このように、クラスタ全体の処理能力をフル活用することで、データ保護機能の再生に向け必要となる時間を大幅に削減することが可能となり、また、クラスタの規模が大きくなるほど再生が高速になります。
ノード障害
VMの影響:
- HAイベント:あり
- I/O障害:なし
- レイテンシー:影響なし
ノードに障害が発生した場合、VMのHAイベントにより、仮想化クラスタ全体の他のノードでVMの再起動が行われます。VMが再起動されると、I/Oは通常通りの形でローカルCVMによって処理され、VMはI/O処理を継続します。
前述のディスク障害と同様に、Curatorスキャンは、該当するノードでそれまでホストされていたデータに対応するレプリカを検索します。レプリカが見つかると、全てのノードが再保護に参加します。
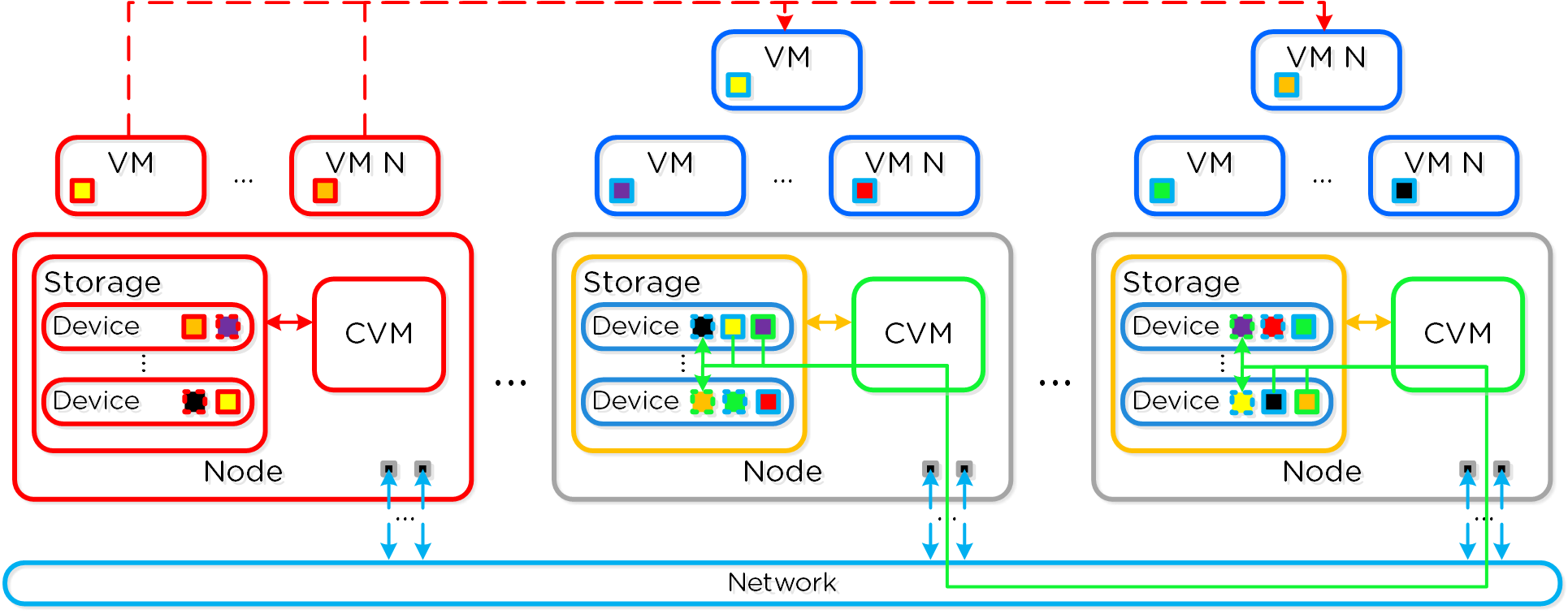
ノードが長時間(AOS 4.6の場合30分間)停止した状態のままである場合、停止したCVMはメタデータリングから削除されます。ノードが復旧し一定時間経過して安定した後、停止していたCVMはリングに戻されます。
プロからのヒント
データの回復機能状態(resiliency state)については、ダッシュボードページのPrismから確認することができます。
回復機能状態は、cliでも確認できます:
ノードのステータス
ncli cluster get-domain-fault-tolerance-status type=node
ブロックのステータス
ncli cluster get-domain-fault-tolerance-status type=rackable_unit
これで最新の状態が表示されますが、データを更新するためにCuratorパーシャルスキャンを実行することもできます。
CVMの「障害」
CVMの「障害」は、CVMが一時的に使用できなくなるようなCVMの動作と見なすことができます。該当システムは、こうした障害を透過的に処理するよう設計されています。障害が発生した場合、I/Oはクラスタ内の別のCVMにリダイレクトされます。但し、実際の仕組みはハイパーバイザーによって異なります。
ローリングアップグレードは、実際にこの機能を利用して、CVMを一度に一つアップグレードし、クラスタ全体で繰り返します。
VMの影響:
- HAイベント: なし
- I/O障害:なし
- レイテンシー: ネットワークに高いI/O負荷を与える可能性あり
CVMに「障害」が発生した場合、該当するCVMが提供していたI/Oはクラスタ内の他のCVMに転送されます。 ESXiやHyper-Vは、HA.py(「Happy」に似ている)を使用したCVM Autopathing(CVM自動パス設定)と呼ばれるプロセス経由でこれを処理します。 CVM Autopathingは、内部アドレス(192.168.5.2)に向けられたトラフィックの転送パスを、クラスタの他のCVMの外部IPアドレスに向け変更します。 これにより、データストアは完全な状態を保つことができ、ただI/Oサービスを提供するCVMがリモートになるという違いのみになります。
ローカルのCVMが復旧して安定すると、転送パスは撤回され、ローカルCVMが全ての新しいI/Oを引き継いで処理します。
AHVは、プライマリなパスをローカルCVMとして、他の2つのパスをリモートに設定するというiSCSIマルチパスを使用しています。プライマリパスに障害が発生すると、残りのパスの1つがアクティブになります。
ESXiやHyper-VのAutopathingと同様、ローカルCVMが復旧すると、プライマリパスが役割を引き継ぎます。
レジリエントキャパシティ
使用されている用語の復習です:
- 障害/可用性ドメイン(FD): レプリカが配置されるエンティティの論理的なグループです。 ノード数が3以上のNutanixクラスタでは、ノードがデフォルトのドメインになります。 これは、可用性ドメインのセクションを参照してください。
- レプリケーションファクター(RF): データ可用性のために、クラスタ上で維持されるデータのコピー数。
- 障害耐性(FT:Fault Tolerance): 障害が発生したエンティティのデータが完全にリビルドされることを保証する、クラスタで扱える構成されたFDでのエンティティの障害数です。
レジリエントキャパシティは、可用性/障害ドメイン内でのFT障害の発生後に、自己修復能力で要求されたレプリケーションファクター(RF)に回復する最中の、最小状態の可用性/障害ドメインで利用可能なストレージ容量です。 簡単に言うと、「レジリエントキャパシティ = クラスタ全体の容量 - FT障害からリビルドするために必要な容量」です。
レジリエントキャパシティの例
同一構成のノードで構成されたクラスタの容量
- 構成された可用性ドメイン: ノード
- 最小の可用性ドメイン: ノード
- FT=1
- RF=2
- ノードの容量: 10TB、10TB、10TB、10TB
- レジリエントキャパシティ = (40-10)*0.95 = 28.5TB。95%は、Stargateが読み取り専用モードになりユーザーの書き込みを実行できなくなるしきい値です。
同一構成ではないノードで構成されたクラスタの容量
- 構成された可用性ドメイン: ブロック(1 ノード/ブロック)
- 最小の可用性ドメイン: ノード
- FT=1
- RF=2
- ノードの容量: 10TB、10TB、40TB、40TB
- レジリエントキャパシティ = 40 * 0.95 = 38TB。95%は、Stargateが読み取り専用モードになりユーザーの書き込みを実行できなくなるしきい値です。
この場合のレジリエントキャパシティは60TBではなく40TBであり、理由としては、40TBのブロックを失うと、クラスタにはノード可用性ドメイン(障害ドメイン)があるためです。 このレベル(ノード障害ドメイン)で2つのデータコピーを維持するには、使用可能容量は40TBであり、この場合のレジリエントキャパシティは全体で40TBになります。
容量と障害ドメインの観点から、クラスタは同一かつ均一の構成に保つことをお勧めします。
AOS 5.18以降は、レジリエントキャパシティがPrism ElementのStorage Summaryウィジェットに灰色の線で表示されます。 しきい値は、クラスタの使用容量がレジリエントキャパシティに到達したときに、エンドユーザーに警告するように設定できます。 デフォルトでそれは75%に設定されています。
Prismでは、管理者がノードごとでの復元力を理解しやすくするように、ノードごとに詳細なストレージ使用率を表示することもできます。 これは、ストレージ分散が偏っているクラスタで役立ちます。
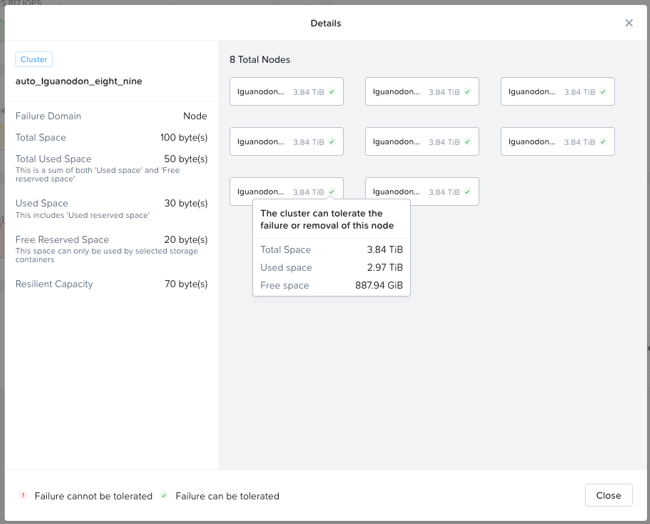
クラスタの使用量がクラスタのレジリエントキャパシティを超えると、そのクラスタは障害に耐えられず、障害から回復できなくなる可能性があります。 レジリエントキャパシティは構成された障害ドメインによるものであるため、クラスタは下位の障害ドメインでも回復して障害に耐えられる可能性があります。 例えば、ノード障害ドメインを持つクラスタは、ディスク障害からの自己修復と回復ができる場合がありますが、ノード障害からの自己修復と回復はできません。
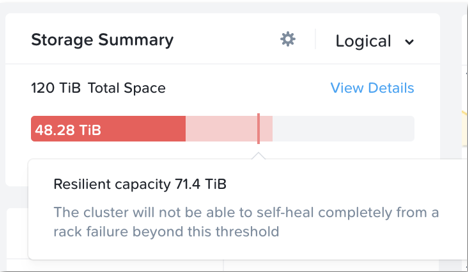
クラスタが適切に機能し、障害から自己修復で回復する能力を維持するために、どのような状況でもクラスタのレジリエントキャパシティを超えないようにすることを強くお勧めします。
キャパシティの最適化
Nutanixプラットフォームは、広範なストレージ最適化テクノロジーを組み合わせる形で採用し、全てのワークロードが使用可能なキャパシティを効率的に使用できるようにしています。このようなテクノロジーは、ワークロードの特性に合わせてインテリジェントに適応されるため、マニュアルによる設定やチューニングが不要となります。
使用されている最適化テクノロジーは以下の通りです:
- イレイジャーコーディング(Erasure Coding / 消失訂正符号 / EC-X)
- データ圧縮
- データ重複排除
それぞれの機能詳細については、次のセクションで説明します。
以下の表で、どのような最適化テクノロジーがどんなワークロードに適用可能かを説明します:
| データ変換 | 最も適したアプリケーション | 補足 |
|---|---|---|
| イレイジャーコーディング(EC-X) | Nutanix Files/Objectsに最適 | 従来のRFより少ないオーバーヘッドで高い可用性を提供。 通常のREAD/WRITE I/Oパフォーマンスに対し影響を与えない。 ディスク/ノード/ブロックに障害が発生しデータをデコードする必要がある場合には、READに若干のオーバーヘッドが発生。 VDIのような書き込みや上書きが集中するワークロードには適さない。 |
| インライン 圧縮 |
全て | ランダムI/Oに影響を与えずストレージ層の使用効率を向上。レプリケーションやディスクから読み込むデータ量を減らすことで、大規模なI/OやシーケンシャルI/Oのパフォーマンスを向上。 |
| オフライン 圧縮 |
なし | インライン圧縮は、大規模またはシーケンシャルなWRITEに限りインラインで圧縮。ランダムI/Oや小規模なI/Oに対しては、オフライン圧縮を使用すべき。 |
| 重複排除 | VDIでのフル クローン、パーシステント デスクトップ、P2V/V2V、Hyper-V (ODX) | クローンされなかったデータまたは効率的なAOSクローンを使用せずに作成されたデータに対して大幅な全体効率性を提供。 |
イレイジャーコーディング(消失訂正符号)
Nutanixプラットフォームでは、データ保護と可用性のためにレプリケーションファクター (RF) を利用しています。この方法では、1ヶ所を超えるストレージからデータ読み込んだり、障害時にデータの再計算を行なったりする必要がないため、極めて高い可用性を提供できます。 しかし、データの完全なコピーが必要となるため、ストレージリソースを消費することになります。
AOSでは、必要なストレージ容量を削減しつつ可用性とのバランスがとれるよう、イレイジャーコーディング(EC)を使用したデータのエンコードが可能になっています。
パリティを計算するRAID(レベル4、5、6など)の概念と同様、ECは、異なるノードに存在するデータブロックのストライプをエンコードしてパリティを計算します。 ホストまたはディスクに障害が発生すると、パリティを使用して消失したデータブロックの計算(デコーディング)を行います。 AOSの場合、データブロックはエクステントグループであり、また各データブロックはそれぞれ異なるノードに配置され、異なるvDiskに格納されている必要があります。
コールドで読み取られるデータの場合は、同じvDiskから、データブロックがノードを横断するよう分散してストライプ(同じvDiskのストライプ)を形成するようにします。 これにより、vDiskが削除された場合に完全なストライプを削除できるため、ガベージコレクション(GC)が簡素化されます。
ホットデータの読み取りでは、vDiskのデータブロックをノードに対してローカルに保ち、異なるvDiskのデータからストライプ(vDiskをまたぐストライプ)を形成します。 ローカルvDiskのデータブロックをローカルに配置できるため、別の仮想マシン/vDiskがストライプ内で別のデータ ブロックを構成でき、リモート読み取りが最小化します。 読み取るコールドストライプがホットになると、システムはストライプを再計算し、データブロックをローカル配置しようとします。
ストライプのデータやパリティのブロック数は、許容する障害耐性によって決定されます。 この構成は一般的に「<データブロック>/<パリティブロック数>」で指定されます。
例えば「RF2ライクな」可用性(N+1)を求める場合は、ストライプに3または4つのデータブロックと1つのパリティブロック(3/1または4/1)とします。 「RF3ライクな」可用性(N+2)を求める場合は、ストライプに3ないしは4つのデータブロックと2つのパリティブロック(3/2または4/2)とします。
ncli container [create/edit] ... erasure-code=<N>/<K>
ここでのNはデータ ブロックの数、Kはパリティ ブロックの数です。
EC + ブロック アウェアネス(ブロック認識)
AOS 5.8以降、ECはデータとパリティブロックをブロック認識する方法で配置できます(AOS 5.8より前はノードレベルで行われていました)。
既存のECコンテナは、AOS 5.8へのアップグレード後、すぐにはブロック認識の配置に変更されません。 クラスタ内で利用可能な十分なブロック(ストライプサイズ (k + n) + 1)がある場合、以前のノード認識ストライプはブロック認識になるよう移動します。 新しいECコンテナは、ブロック認識したECストライプを作成します。
想定されるオーバーヘッドは「<パリティブロック数> / <データブロック数>」で計算できます。 例えば、4/1ストライプの場合は25%のオーバーヘッドがあり、RF2の2倍と比較して1.25倍となります。 4/2ストライプの場合には50%のオーバーヘッドがあり、RF3の3倍と比較して1.5倍となります。
以下の表に、エンコードされたストライプのサイズとオーバーヘッドの例を示します:
|
|
|
|||
|---|---|---|---|---|
| クラスタサイズ (ノード数) |
ECストライプサイズ (データ/パリティブロック) |
ECオーバーヘッド (RF2の2Xに対して) |
ECストライプサイズ (データ/パリティ) |
ECオーバーヘッド (RF3の3Xに対して) |
| 4 | 2/1 | 1.5X | N/A | N/A |
| 5 | 3/1 | 1.33X | N/A | N/A |
| 6 | 4/1 | 1.25X | 2/2 | 2X |
| 7 | 4/1 | 1.25X | 3/2 | 1.6X |
| 8+ | 4/1 | 1.25X | 4/2 | 1.5X |
プロからのヒント
クラスタサイズは、常にストライプサイズ(データ+パリティ)より最低でも1ノード大きくなるように設定し、ノードに障害が発生した場合でも、ストライプの再構築が可能なようにしておくことが推奨されます。 こうすることで、(Curatorにより自動的に)ストライプが再構築される際のREADにかかるオーバーヘッドを避けることができます。 例えば4/1ストライプの場合は、クラスタに6ノードを確保すべきです。 前述の表は、このベストプラクティスを踏襲したものになっています。
エンコーディングは、ポストプロセスで実施され、Curator MapReduceフレームワークを使用してタスクの配布を行います。 ポストプロセスのフレームワークであるため、従来のWRITE I/Oパスが影響を受けることはありません。
RFを使用する通常の環境は以下に図示するような内容となります:
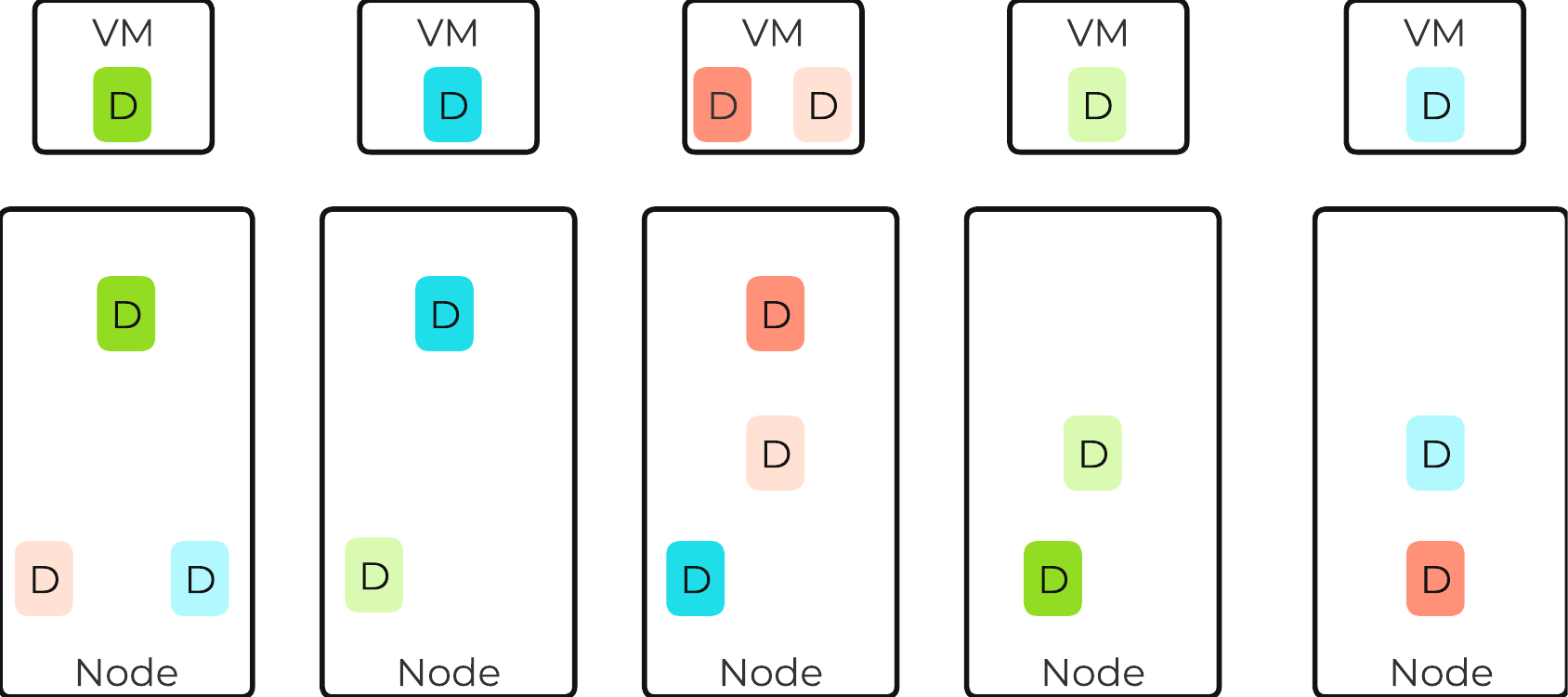
このシナリオの場合はRF2のデータが存在しており、元のデータはローカルに存在し、レプリカはクラスタ全体の他のノードに分散されています。
Curatorスキャンが実行され、エンコードが可能な適切なエクステントグループを検索します。 適切なエクステントグループとは、「write-cold」なもの、つまり一定の期間に書き込みが行われていないものを指します。 これはCurator Gflagであるcurator_erasure_code_threshold_secondsによって制御されます。 適切な候補が見つかると、Chronosによってエンコーディングタスクが配布され実行されます。
以下に3/1ストライプの例を図示します:
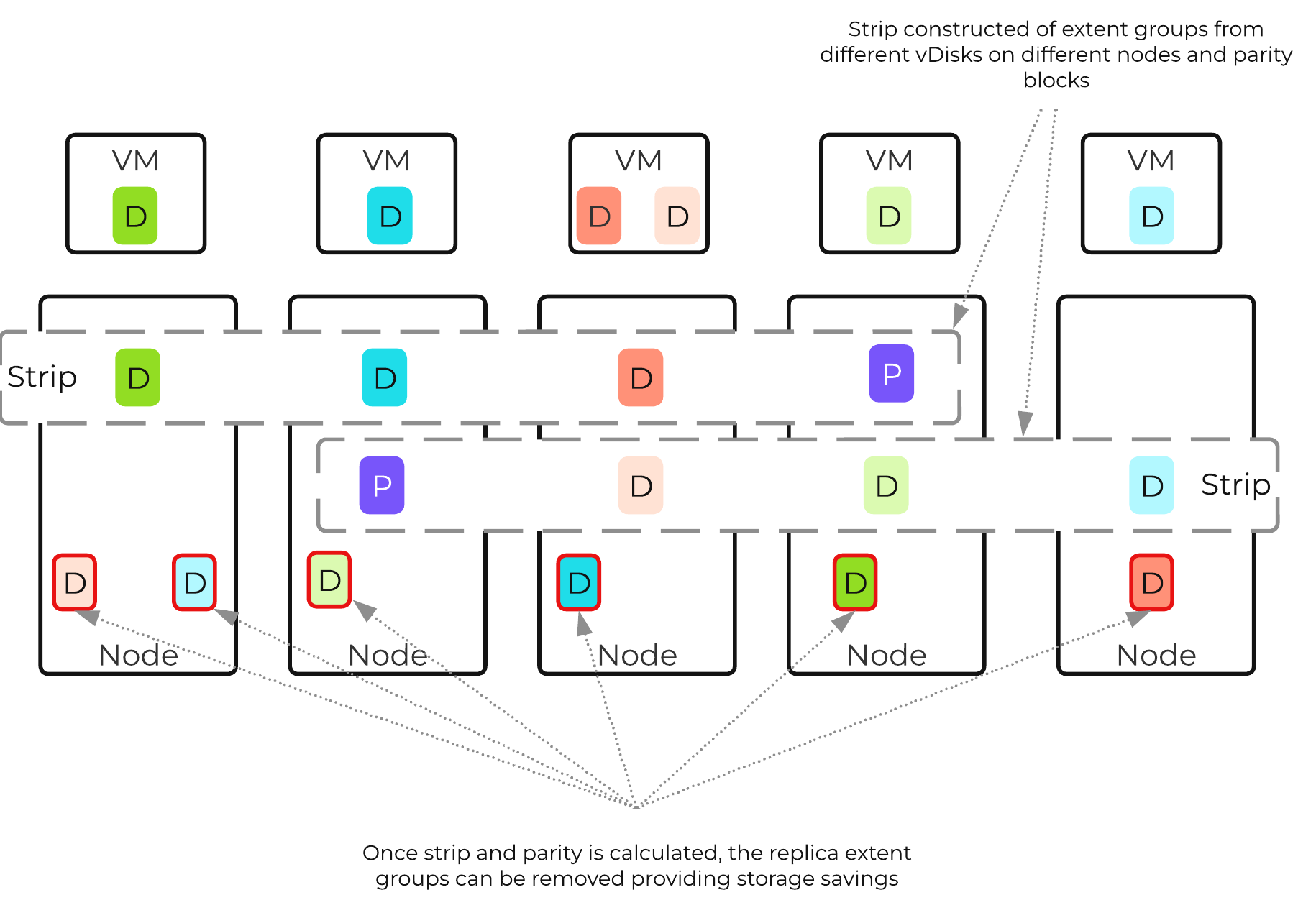
データのエンコード(ストライプおよびパリティ計算)が成功すると、レプリカエクステントグループは削除されます。
以下は、ストレージセービングのためにECが実行された後の環境を図示したものです:
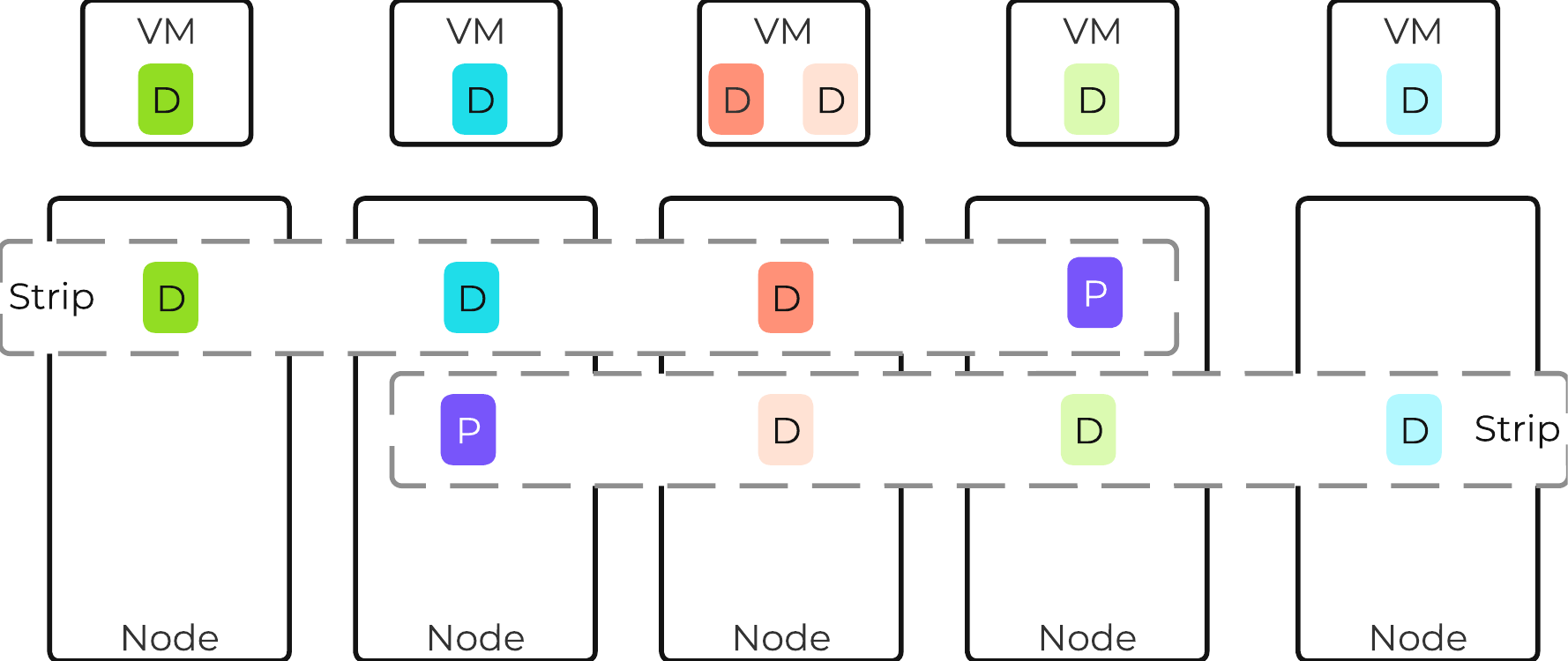
AOS 5.18以降では、nCLIを使用してコンテナ上でインライン イレイジャーコーディングを有効にすることができます。 これは、データがwrite-coldになるのを待たずに、インラインで消失訂正符号によってエンコードし、コーディング ストライプを作成します。 インライン イレイジャーコーディングでは、デフォルトでは消失訂正符号化されたストライプは同一のvDiskデータから作成されます。 AOS 6.6では、必要に応じてデータローカリティを維持しながらCross vDiskからストライプを作成するオプションもあります。 これにより、データローカリティや多数の上書き処理を必要としないワークロードにのみ推奨されます。 Objectsを展開すると、インライン イレイジャーコーディングがデフォルトで有効になります。
プロからのヒント
イレイジャーコーディングはインライン圧縮機能と相性がよく、さらにストレージの節約ができます。
圧縮
ビデオによる解説はこちらからご覧いただけます:LINK
Nutanix Capacity Optimization Engine(COE - キャパシティ最適化エンジン)は、ディスクのデータ効率を上げるために、データ変換を行います。 現在、圧縮機能は、データの最適化を行うための重要な機能の1つとなっています。 AOSは、お客様のニーズやデータタイプに応じた対応ができるよう、インライン圧縮とポストプロセス圧縮の両方を提供しています。 AOS 5.1では、オフライン圧縮がデフォルトで有効化されています。
インライン圧縮では、エクステントストア (SSD + HDD) の書き込み時に、シーケンシャルなデータや大きなサイズのI/O(>64K)を圧縮します。 これには、OpLogからのデータドレイニングやOplogをスキップするシーケンシャルデータなどが含まれます。
OpLogの圧縮
AOS 5.0では、OpLogが4Kを超える全てのインカミングの書き込みについて圧縮を行うことで(Gflag:vdisk_distributed_oplog_enable_compression)、優れた圧縮効果が得られるようになりました。 これによって、さらに効率的にOpLogのキャパシティを活用し、安定したパフォーマンスが得られるようになります。
OpLogからエクステントストアに溢れたデータについては、一度解凍し、アラインメントした後に、32Kのユニットサイズに合わせて再圧縮が行われます(AOS 5.1の場合)。
この機能はデフォルトで有効となっており、ユーザーが設定する必要はありません。
オフライン圧縮の場合、最初は通常の状態(非圧縮状態)で書き込みが行なわれ、Curatorフレームワークを使用してクラスタ全体のデータを圧縮します。 インライン圧縮が有効化された場合、I/Oがランダムな特性を持っていても、データは圧縮されない状態でOpLogに書き込まれて合成され、エクステントストアに書き込まれる前にインメモリで圧縮されます。
Nutanixは、AOS 5.0以降、データ圧縮にLZ4とLZ4HCを使用しています。 AOS 5.0より前は、Google Snappy圧縮ライブラリを使用することで、処理オーバーヘッドが少なく高速な圧縮/解凍速度で、非常に優れた圧縮率を得ていました。
通常のデータに対しては、圧縮率とパフォーマンスのバランスが取れたLZ4を使用しています。 コールドデータに対しては、より圧縮率に優れたLZ4HCを使用しています。
コールドデータは、次のような2つのカテゴリに分類されます:
- 一般のデータ: 3日間R/Wアクセスがない (Gflag: curator_medium_compress_mutable_data_delay_secs)
- 不変データ(スナップショット): 1日間R/Wアクセスがない (Gflag: curator_medium_compress_immutable_data_delay_secs)
以下に、インライン圧縮とAOS WRITE I/Oパスとの関連を図示します:
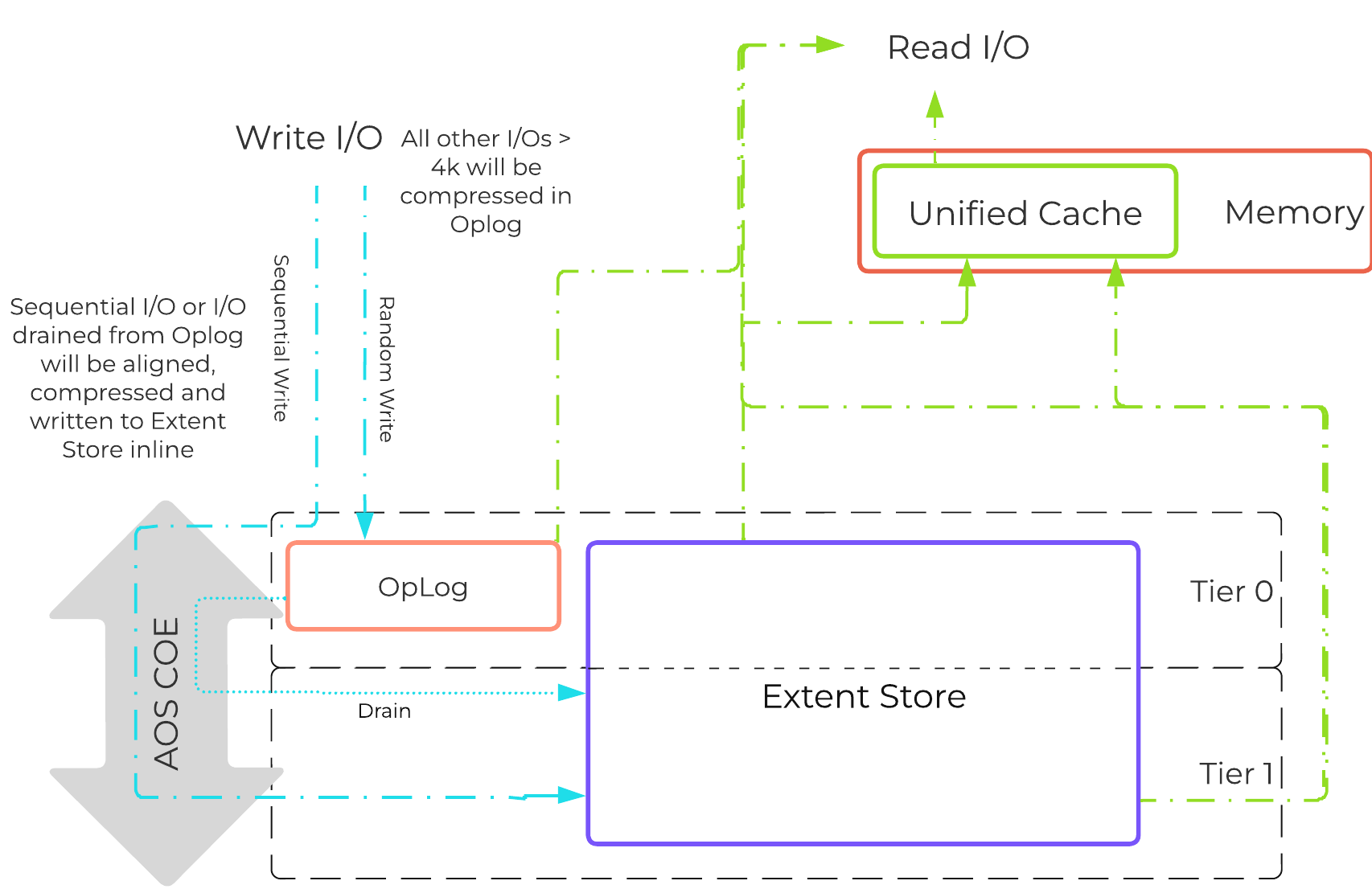
プロからのヒント
大規模またはシーケンシャルなWRITE処理のみが圧縮対象で、ランダムWRITEのパフォーマンスに影響を与えないため、ほとんどの場合インライン圧縮(圧縮遅延 = 0)が使用されます。
これによってSSD層の実効容量を増やし、パフォーマンスを効果的に向上させ、より多くのデータをSSD層に格納しておくことができます。 書き込みやインライン圧縮された、より大容量またはシーケンシャルデータに対しては、RFによるレプリケーションの際に圧縮データが送られることで回線を通過するデータ量が低減され、さらなるパフォーマンスの向上につながります。
またインライン圧縮は、消失訂正符号との相性という面でも優れています。
オフライン圧縮の場合、全ての新しいWRITE I/Oが非圧縮状態で行われ、通常のAOS I/Oパスが適用されます。 圧縮遅延時間(設定可能)に達するとデータの圧縮が可能となります。 オフライン圧縮は、Curator MapReduceフレームワークを使用し、全ノードで圧縮タスクを実行します。 圧縮タスクはChronosによって起動されます。
下記に、オフライン圧縮とAOS WRITE I/Oの関係を示します。
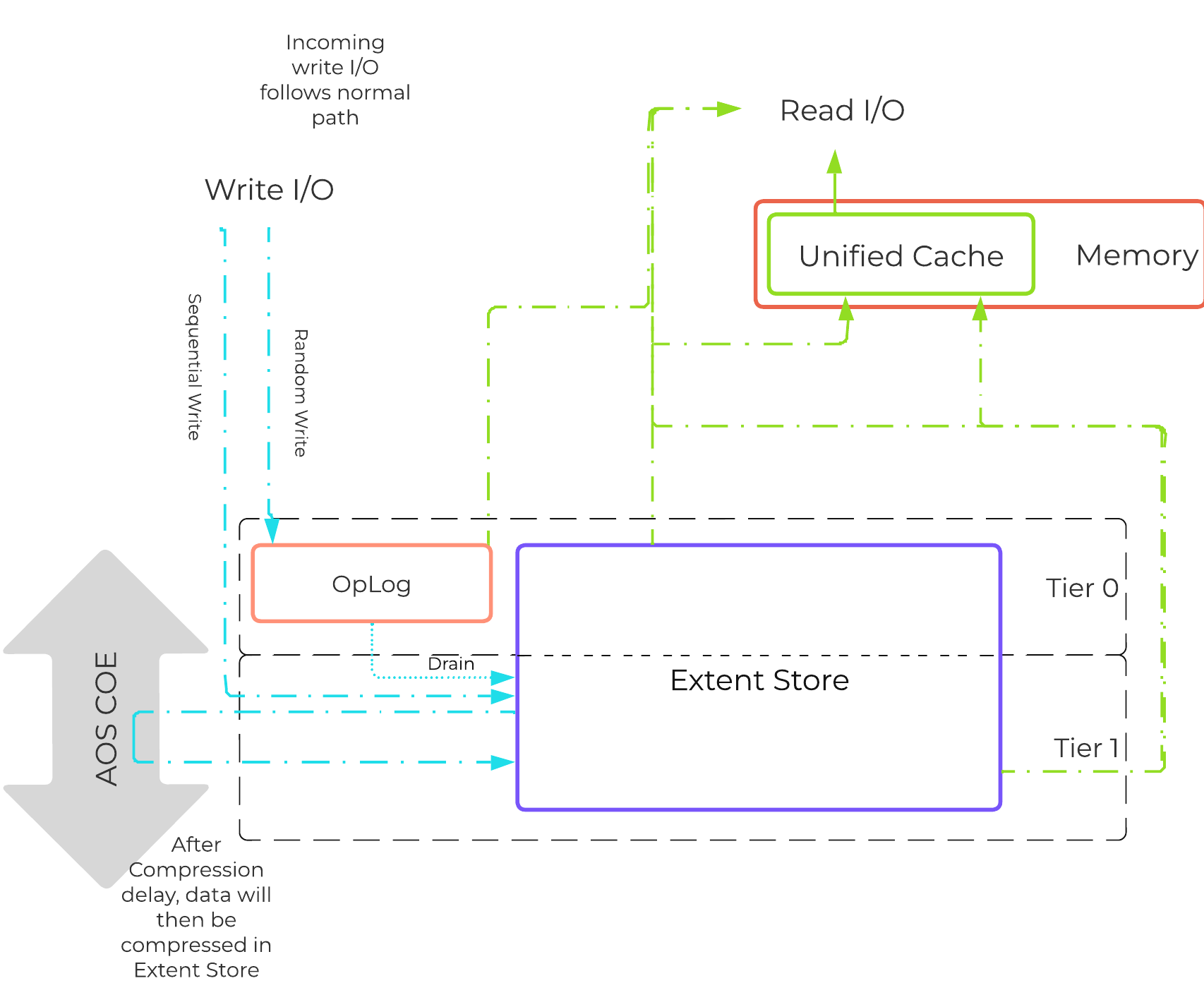
READ I/Oの場合、最初にメモリ内で解凍を行ってからI/Oが実施されます。
現在の圧縮率は、PrismのStorage > Dashboardページで確認できます。
Elastic Dedupe Engine
ビデオによる解説はこちらからご覧いただけます:LINK
Elastic Dedupe Engineは、AOSにおけるソフトウェアベースの機能で、キャパシティ層(エクステントストア)でデータの重複排除を行います。 データのストリームは、1MBのエクステントでフィンガープリント(stargate_dedup_fingerprintで制御)されます。 AOS 5.11より前は、AOSは重複排除の候補をフィンガープリントで識別するためにSHA-1ハッシュのみを使用していました。 AOS 5.11から、AOSは論理チェックサムを使用して重複排除の候補を選択するようになりました。 フィンガープリントは、データの取り込み時にのみ収集され、書き込みブロックのメタデータの一部として永続的にストアされます。
データの再読み込みが必要となるバックグラウンドのスキャンを使用する従来の手法とは異なり、Nutanixはデータ取り込み時にインラインでフィンガープリントを取得します。 キャパシティ層で重複排除が可能な重複データは、スキャンしたり再読み込みしたりする必要がないため、重複したデータは基本的に削除することが可能です。
メタデータのオーバーヘッドを効率化するため、フィンガープリントの参照カウントをモニターし、重複排除の可能性をトラッキングします。 メタデータのオーバーヘッドを最小限にするため、参照数の低いフィンガープリントは廃棄されます。 また、フラグメントを最小限にするためには、重複排除を最大限に使用することが望まれます。
プロからのヒント
ベースイメージ(vdisk_manipulatorを使用してマニュアルでフィンガープリント可能)に対しては、重複排除を使用しユニファイド キャッシュの優位性を活かすようにします。
I/Oサイズが64K以上(初期のI/OまたはOpLogからのドレイニングの際)のデータを取り込む間にフィンガープリントが収集されます。 AOSは次に、1MBエクステント内の各16KBチャンクのハッシュ/フィンガープリントを探し、チャンクの40%以上で重複が見つかった場合は、エクステント全体を重複排除します。 その結果、1MBエクステント内の残りの60%から参照カウント1(他とは重複なし)の重複排除エクステントが多数発生することになり、最終的にメタデータを使用することになりました。
AOS 6.6では、1MBエクステント内でのアルゴリズムがさらに強化され、エクステント全体ではなく、重複のあるチャンクのみが重複排除マークを付けられるため必要なメタデータが削減されます。
AOS 6.6では、重複排除メタデータの保存方法も変更されました。 AOS 6.6より前では、重複排除メタデータはトップレベルのvDiskブロック マップに保存されていたため、スナップショット取得時には重複排除メタデータがコピーされていました。 その結果、メタデータが肥大化しました。 AOS 6.6では、メタデータがvDisk ブロック マップよりもレベルが低い、エクステント グループIDマップに保存されるようになりました。 現在ではvDiskのスナップショットが取得されると、重複排除メタデータはコピーされなくなり、メタデータの肥大化が防止されるようになりました。
フィンガープリンティングが実施されると、同じフィンガープリントの複数のコピーに基づき、バックグラウンドプロセスがAOS MapReduceフレームワーク (Curator)を使用して重複データを削除します。 読み込みデータは、複数階層を持つプールキャッシュであるAOSユニファイド キャッシュに取り込まれます。 これ以降、同じフィンガープリントを持つデータリクエストは、キャッシュから直接データを取り込みます。 ユニファイド キャッシュとプールの階層構造の詳細については、I/Oパス概要セクション内の「ユニファイド キャッシュ」に関するサブセクションをご覧ください。
以下の図は、Elastic Dedupe EngineがAOSのI/Oパスをどのように扱うかを例示しています:
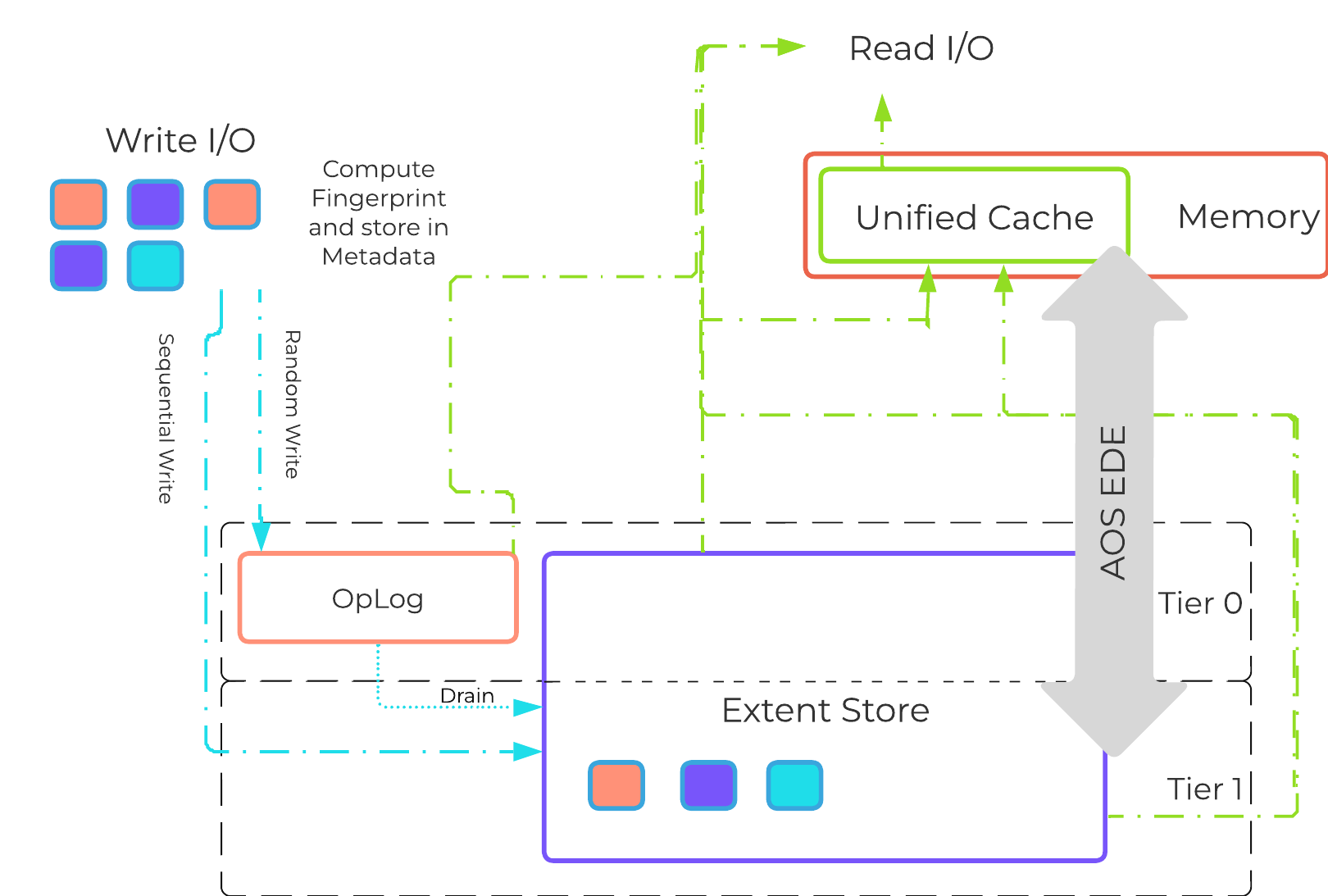
現在の重複排除率は、Prismの Storage > Dashboard ページ で確認することができます。
ストレージの階層化と優先順位付け
ディスクバランシングのセクションでは、どのようにしてNutanixクラスタの全てのノードにまたがるストレージ キャパシティをプールし、また、どのようにしてILMがホットデータをローカルに維持するかについて解説しました。 同様の概念が、クラスタ全体のSSDやHDD層といったディスクの階層化にも適用されており、AOS ILMは、階層間でデータを移動させる役目を担います。 ローカルノードのSSD層は、そのノードで稼動するVMが生成する全てのI/Oに対して常に最高優先度となる階層であり、また、クラスタの全てのSSDリソースは、クラスタ内の全てのノードに対して提供されることになります。 SSD層は、常に最高のパフォーマンスを提供すると同時に、その管理はハイブリットアレイにとって非常に重要なものとなります。
階層の優先度は次のような分類が可能です:
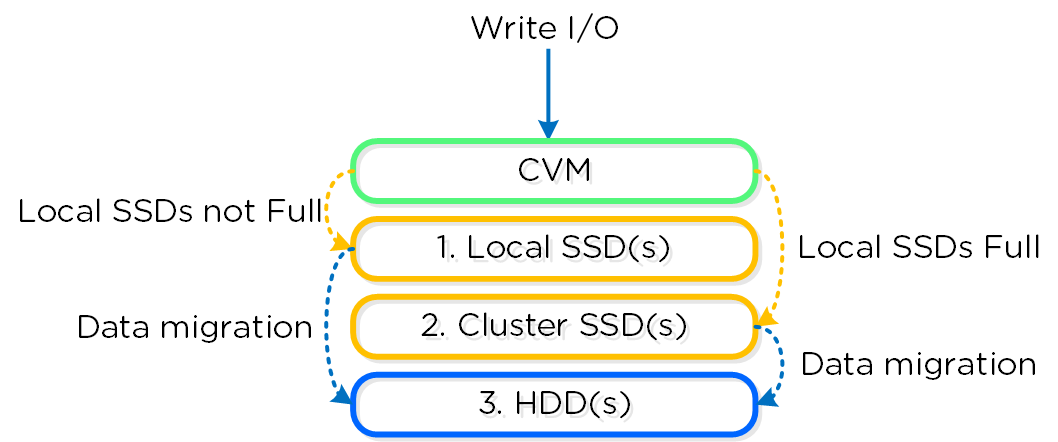
同じタイプのリソース(例えばSSD、HDDなど)が、クラスタ全体のストレージ層から集められてプールされます。 つまり、ローカルにあるかどうかを問わず、クラスタ内の全てのノードが、その層のキャパシティ構築に利用されるということです。
以下は、このプールされた階層がどのように見えるかを図示したものです:
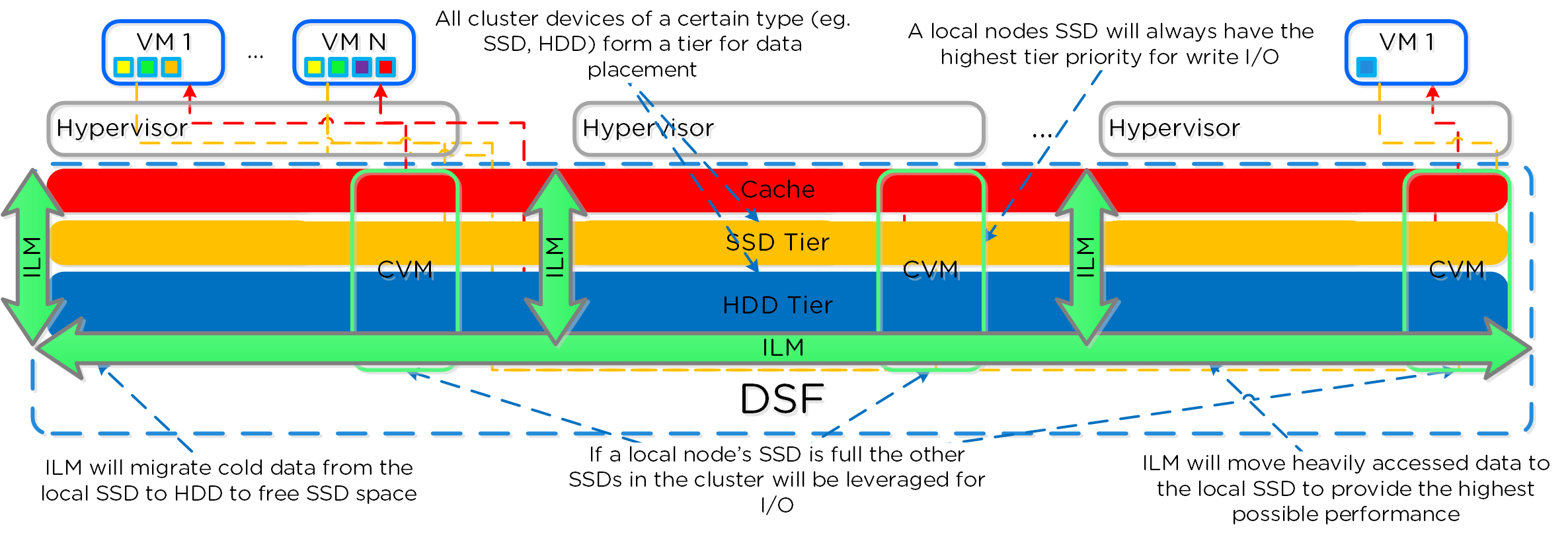
ローカルノードのSSDが一杯になるとどうなるのか?というのは一般によく聞かれる質問です。 ディスクバランシングのセクションで説明した通り、重要となるのは、ディスク層のデバイス間の使用率の平準化を図ることです。 ローカルノードのSSD使用率が高い場合、ディスクバランシングは、ローカルSSDに存在する最もコールドなデータをクラスタの他のSSDに移動するように機能します。 これにより、ローカルSSDに空きスペースを確保し、ローカルノードがネットワーク越しにではなく、ローカルのSSDに直接書き込めるようにします。 ここで重要な点は、全てのCVMとSSDがリモートI/Oに使用されることで、ボトルネックの発生を防ぎ、また、万が一発生した場合でも、ネットワーク経由でI/Oを実施してそれを修復できる点です。
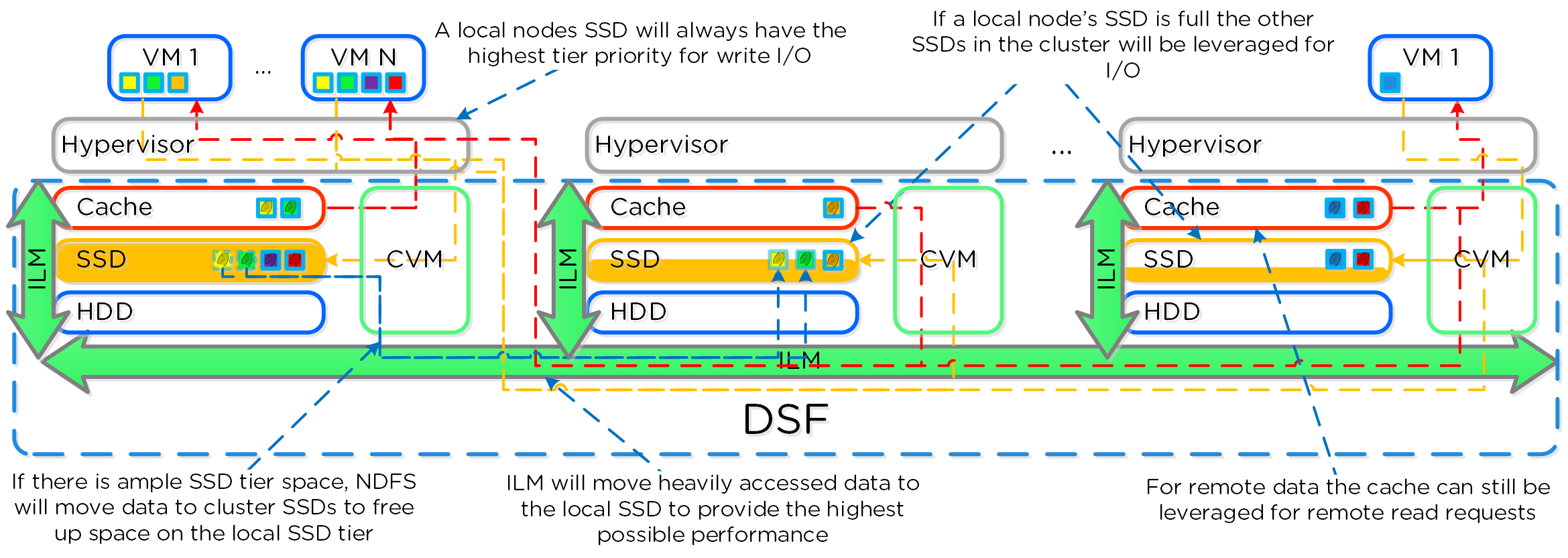
別のケースとして、階層全体の使用率が、一定のしきい値 [curator_tier_usage_ilm_threshold_percent (デフォルト=75)] を超えた場合、 Curatorジョブの一部としてAOS ILMが起動され、データをSSD層からHDD層に下層移動させます。 これにより、使用率が上記のしきい値内になるか、または最小解放値 [curator_tier_free_up_percent_by_ilm (デフォルト=15)] の2者から、大きい方の値でスペースが解放されます。 下層移動の対象となるデータは、最後にアクセスのあった時間によって決定されます。 SSD層の使用率が95%の場合、SSD層にある20%のデータをHDD層に移動(95% -> 75%)されます。
しかし、使用率が80%の場合は、階層の最小解放値に基づき、15%のデータのみがHDD層に移動することになります。
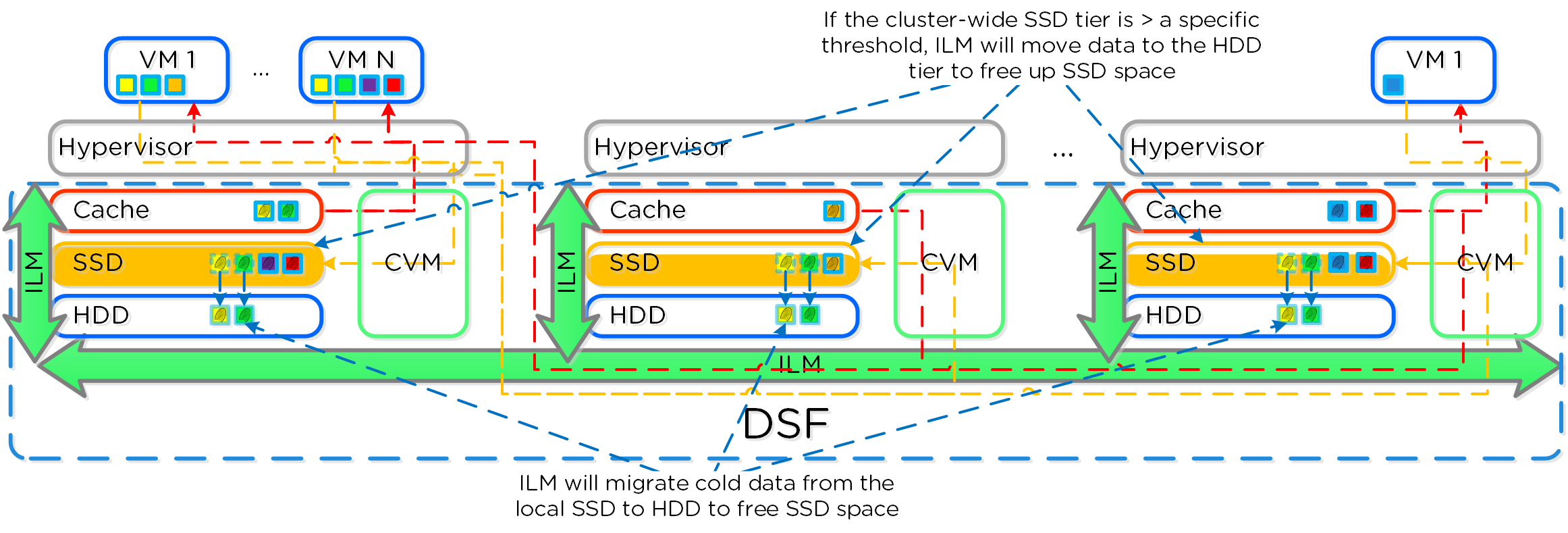
AOS ILMは、I/Oのパターンを定常的にモニターし、必要に応じてデータを上層または下層に移動すると共に、その階層に関係なく、ホットなデータをローカルに移動させます。 上層への移動(もしくは水平移動)のロジックは、egroupローカリティで定義されたものと同様です: 10分間に3回のランダムアクセス、または10回のシーケンシャルアクセスが発生した場合。ただし10秒間のサンプリング間隔内で発生した複数回のReadは1回としてカウントされます。
ディスクバランシング
ビデオによる解説はこちらからご覧いただけます:LINK
AOSは非常にダイナミックなプラットフォームとして、様々なワークロードに対応することが可能であると同時に、1つのクラスタをCPUに重点を置いた構成(3050など)や、ストレージに重点を置いた構成(60x0など)など、様々なノードタイプを組み合わせた構成が可能です。 大規模なストレージ容量を持ったノードを組み合わせた場合、データを均一に分散することが重要になります。 AOSには、クラスタ全体でデータを均一に分散するためのディスクバランシングと呼ばれるネイティブな機能が含まれています。 ディスクバランシングは、DSF ILMと連携しながらローカルにあるノードのストレージ キャパシティの使用率を調整します。 もし、使用率が一定のしきい値を超えた場合は、使用率の均一化を図ります。
注: ディスクバランシングのジョブは、プライマリI/O(UVMのI/O)とバックグラウンドI/O(例えばディスクバランシング)に異なる優先度キューを持つCuratorによって処理されます。 これは、ディスクバランシングやその他のバックグラウンド処理が、フロントエンドのレイテンシーやパフォーマンスに影響しないように行われます。 このときジョブのタスクは、タスク実行の抑制や制御をするChronosに渡されます。 また、ディスクバランシングのための移動は同じ層内で行われます。 例えば、HDD層に不均等なデータがある場合、ノード間の同じ層で移動します。
以下は、異なるタイプ(3050 + 6050)で構成された「バランスが悪い」状態にあるクラスを図示しています:
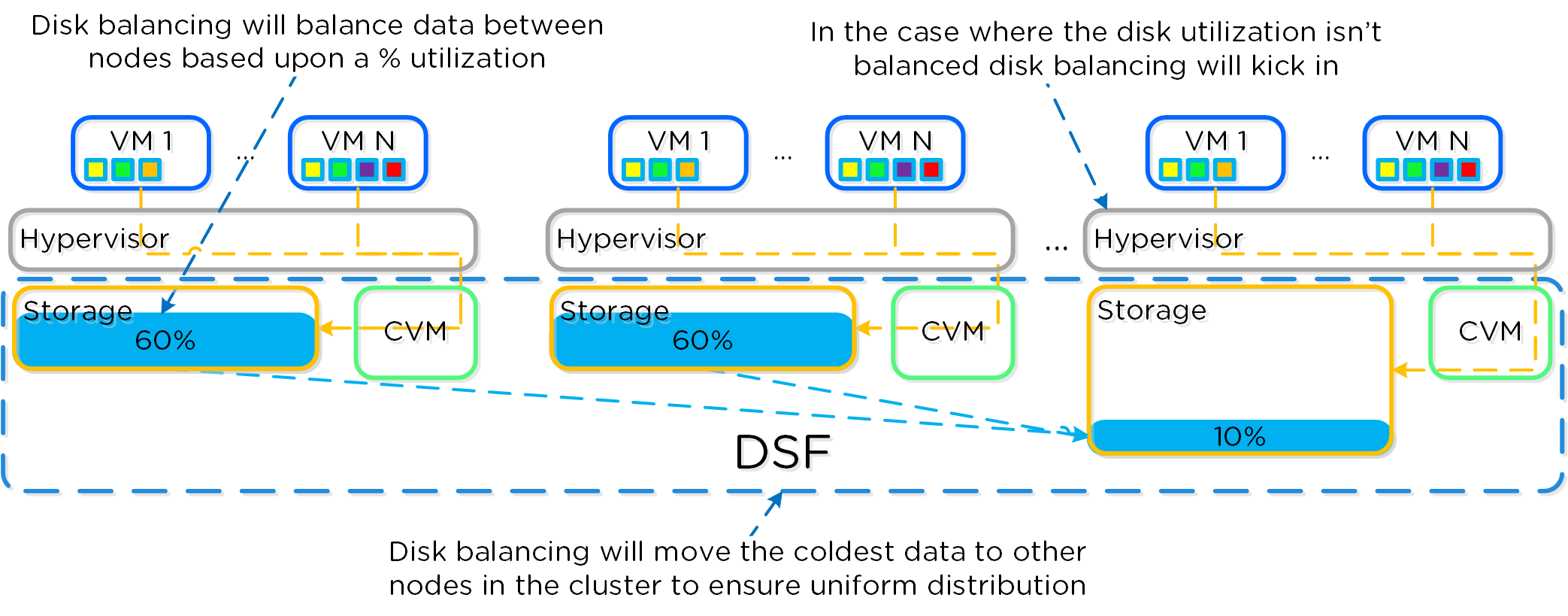
ディスクバランシングは、AOS Curatorフレームワークを使用し、スケジュールプロセスとして、 または、しきい値を超えた場合(例えば、ローカルノードのキャパシティの使用率 > n%)に機能します。 データのバランスが悪い場合、Curatorはどのデータを移動すべきかを判断し、クラスタのノードにタスクを配分します。 ノードタイプが均一(例えば、3050のみ)の場合、データの分散もほとんどが均一な状態になります。 しかし、ノード上に他に比べ大量のデータ書き込みを行うVMが存在した場合には、該当ノードのキャパシティ使用率のみが突出したものになります。 このような場合、ディスクバランシングが機能し、そのノードの最もコールドな状態にあるデータをクラスタ内の他のノードに移動させます。 さらに、ノードタイプが不均一(例えば、3050 + 6020/50/70など)な場合や、ストレージの利用のみに限定して使用されている(VMが動いていない状態)ノードが存在する場合にも、データを移動する必要があると考えられます。
以下に、ノードタイプが混在したクラスタで、ディスクバランシングが機能し、「バランスが取れた」状態を図示しました:
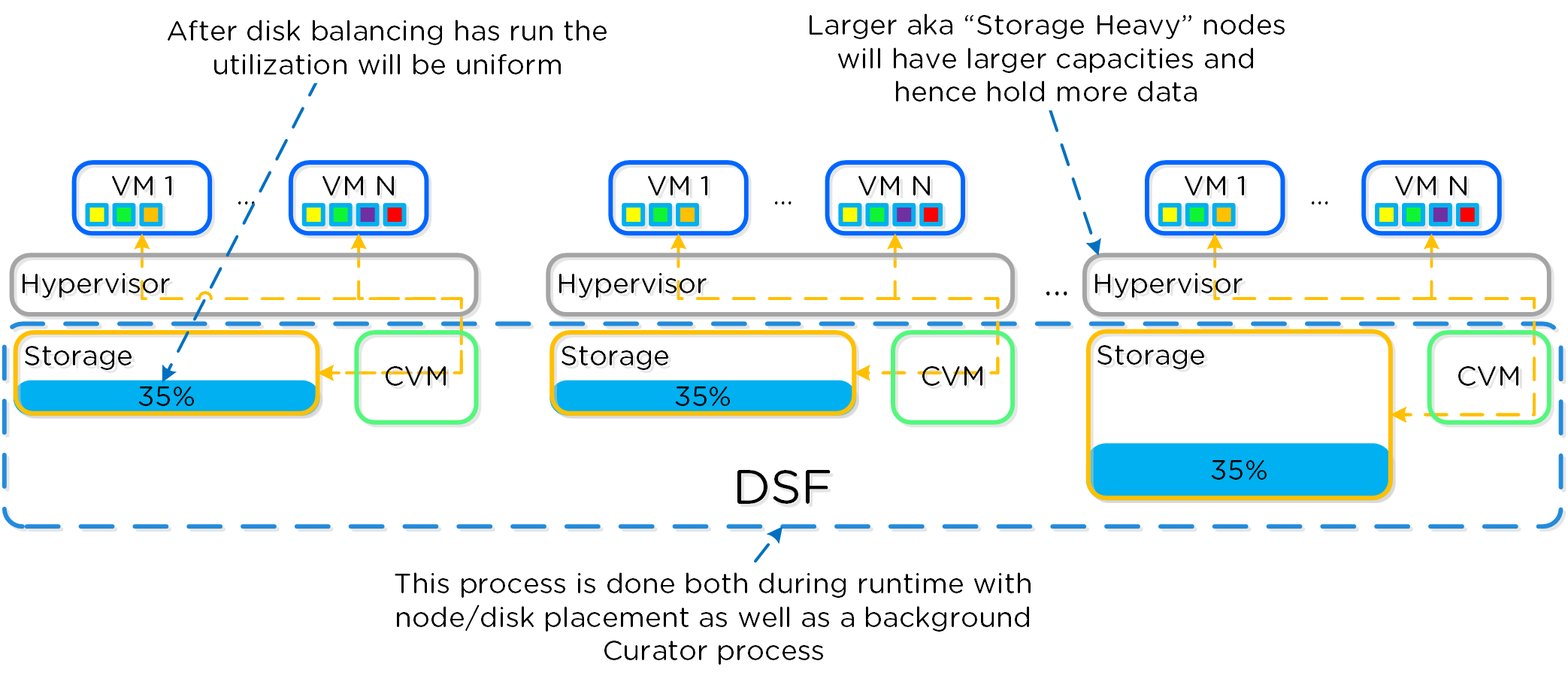
大量のストレージ キャパシティを確保するため、一部のノードを「Storage Only(ストレージとしてのみ利用する)」という状態で稼動させるお客様も存在します。 この場合、CVMのみがノード上で稼動することになります。 ノードの全てのメモリをCVMに割り当て、より大きなREADキャッシュを確保することができます。
以下は、ノードタイプ混在クラスタにStorage Onlyノードが存在する場合、ディスクバランシングがどのようにVMを稼動するノードからデータを移動させるかを図示したものです:
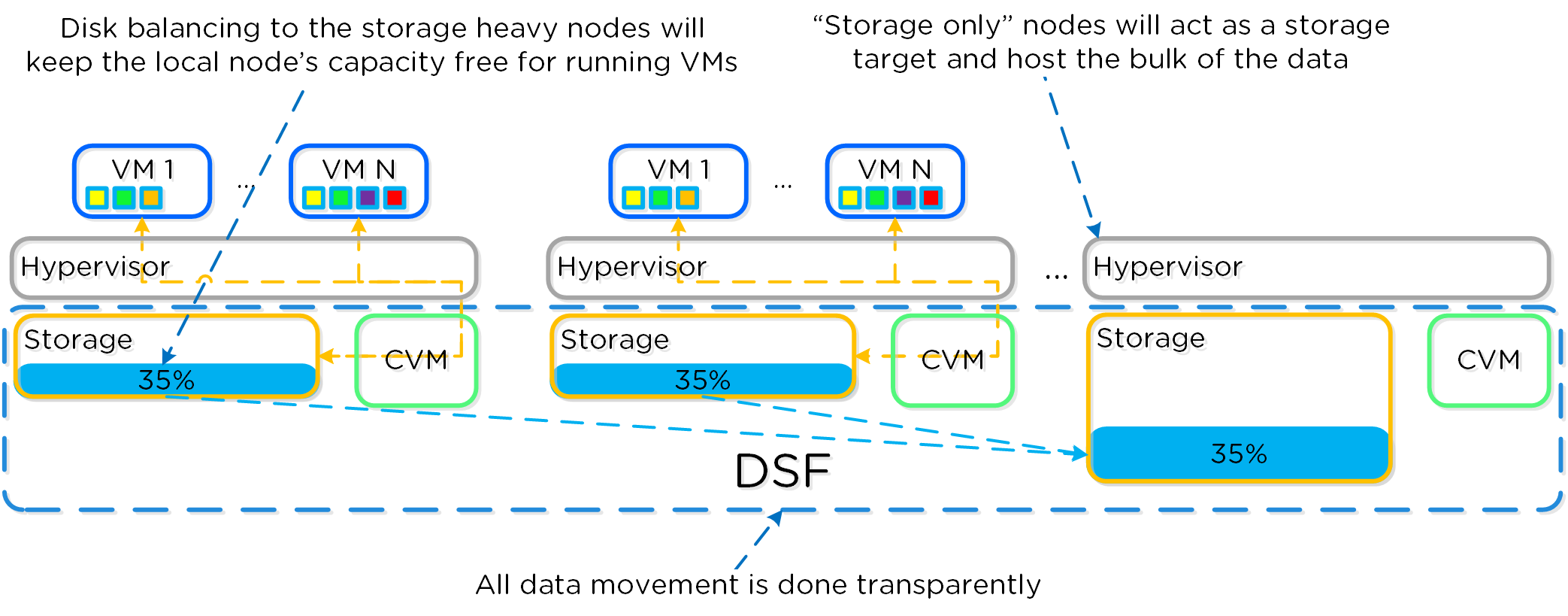
スナップショットとクローン
ビデオによる解説はこちらからご覧いただけます:LINK
AOSはオフロードされたスナップショットとクローンをネイティブにサポートし、VAAI、ODX、ncli、REST、Prismなどから使用することができます。 スナップショットもクローンも、最も効果的かつ効率的なリダイレクト オン ライト(redirect-on-write)アルゴリズムを採用しています。 データストラクチャのセクションで説明した通り、仮想マシンはNutanixプラットフォーム上のvDiskであるファイル(vmdk/vhdx)から構成されています。
vDiskは、論理的に連続したデータのかたまりであり、エクステントグループにストアされているエクステントで構成されています。エクステントグループは、ストレージデバイス上のファイルとしてストアされている物理的に連続したデータです。スナップショットやクローンが取得されると、元になるvDiskは変更不可とマークされ、一方のvDiskはREAD/WRITE可能な形で作成されます。この時点で、両方のvDiskは同じブロックマップ、すなわちvDiskに対応するエクステントをマップしたメタデータを持っています。スナップショットチェーンのトラバーサル(READに必要なレイテンシーの増加)が発生する従来のアプローチとは異なり、各vDiskがそれぞれのブロックマップを持っています。これによって、大きく深いスナップショットチェーンで一般的にみられるオーバーヘッドを排除し、パフォーマンスに影響を与えることなく、連続的にスナップショットを取得することができるようになります。
以下は、スナップショットを取得した際の動きを図示したものです(ソース: NTAP):
日本語版 補足: この図はNTAP(NetApp)の図をもとに作成されたものです。NTAPの説明が最も明解なものだったからです。
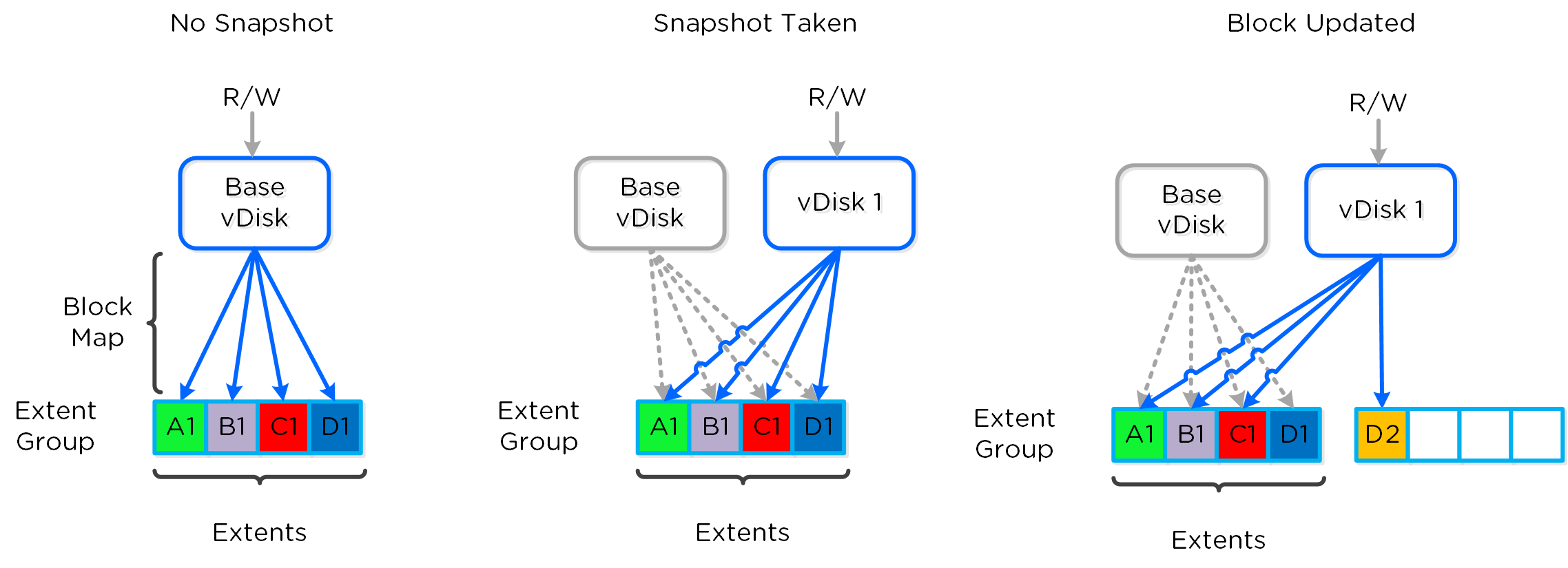
既にスナップショットあるいはクローンが取得されたvDiskでスナップショットまたはクローンを取得する場合も、同じ方法が適用されます:
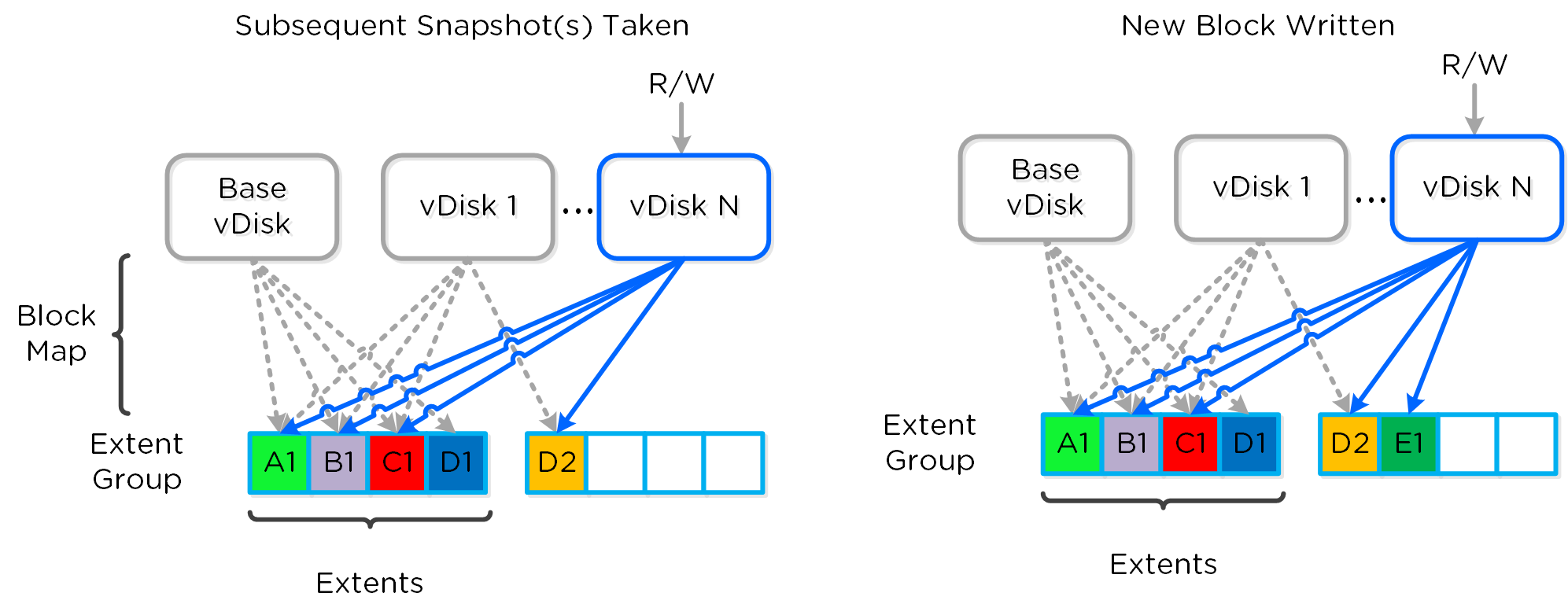
VMやvDiskに対するスナップショットやクローンも、同様の方法で取得します。 VMまたはvDiskがクローンされる場合、その時点のブロックマップをロックして、クローンが作成されます。 更新はメタデータのみに対して行われるため、実際にI/Oが発生することはありません。 さらにクローンのクローンについても同様です。 以前にクローン化されたVMは、「ベースvDisk(BasevDisk)」として機能し、クローニングが行われる場合ブロックマップがロックされ、2つの「クローン」が作成されます。 1つはクローン元のVMで、もう一方は新しいクローンです。 クローンの最大数に制限はありません。
いずれも以前のブロックマップを引き継ぎ、新規の書き込みや更新はそれぞれのブロックマップに対して行われます。
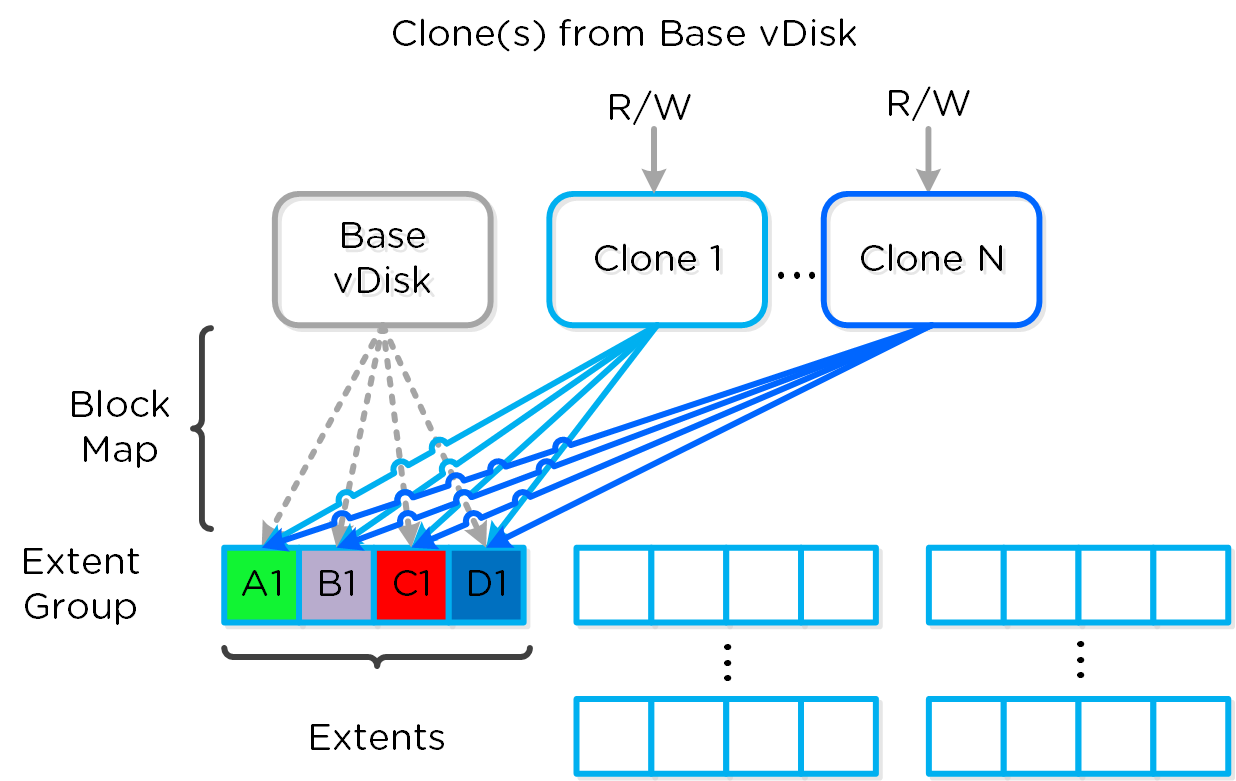
既にご説明した通り、各VM/vDiskはそれぞれブロックマップを持っています。上記の例では、ベースVMの全てのクローンがそれぞれのブロックマップを持つようになり、書き込みや更新はそこで発生します。
上書きが発生した場合、データを新しいエクステント/エクステントグループに移動します。 例えば、既存のデータが「エクステントe1のオフセットo1」にありそれが上書きされるとき、Stargateは新しいエクステントe2を作成し、新しいデータが「エクステントe2のオフセットo2」に書き込まれたことを追跡します。 vBlockマップは、これをバイトのレベルで追跡します。
以下にそのような状態を図示します:
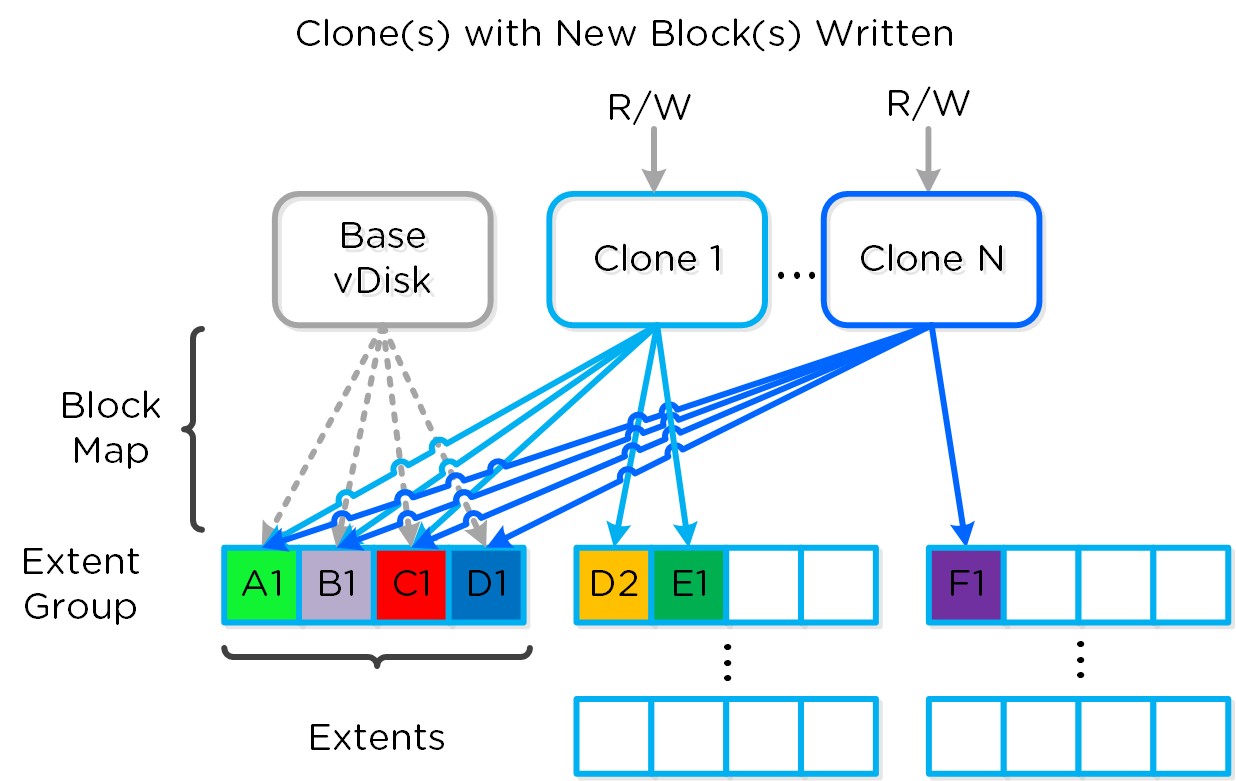
VM/vDiskに引き続き、クローンやスナップショットを取得しようとすると、元のブロックマップがロックされ、R/Wアクセスできる新しい対象が作成されます。
ネットワークとI/O
Nutanixプラットフォームでは、ノード間通信においてバックプレーンを一切使用せず、標準的な10GbEネットワークのみを使用しています。 Nutanixノード上で稼動するVMの全てのストレージI/Oは、ハイパーバイザーによって専用のプライベート ネットワーク上で処理されます。 I/Oリクエストは、ハイパーバイザーによって処理され、ローカルCVM上のプライベートIPに転送されます。 CVMは、外部IPを使いパブリック10GbEネットワーク経由で、他のNutanixノードに対してリモートレプリケーションを行います。 つまり、パブリック10GbEを利用するトラフィックは、AOSリモートレプリケーションとVMネットワークI/Oのみということです。 但し、CVMが停止していたり、データがリモートに存在したりする場合、CVMはリクエストをクラスタ内の他のCVMに転送します。 さらに、ディスクバランシングなどクラスタ横断的なタスクは、10GbEネットワーク上で一時的にI/Oを発生させます。
以下は、VMのI/Oパスとプライベートおよびパブリック10GbEネットワークの関係を図示したものです:
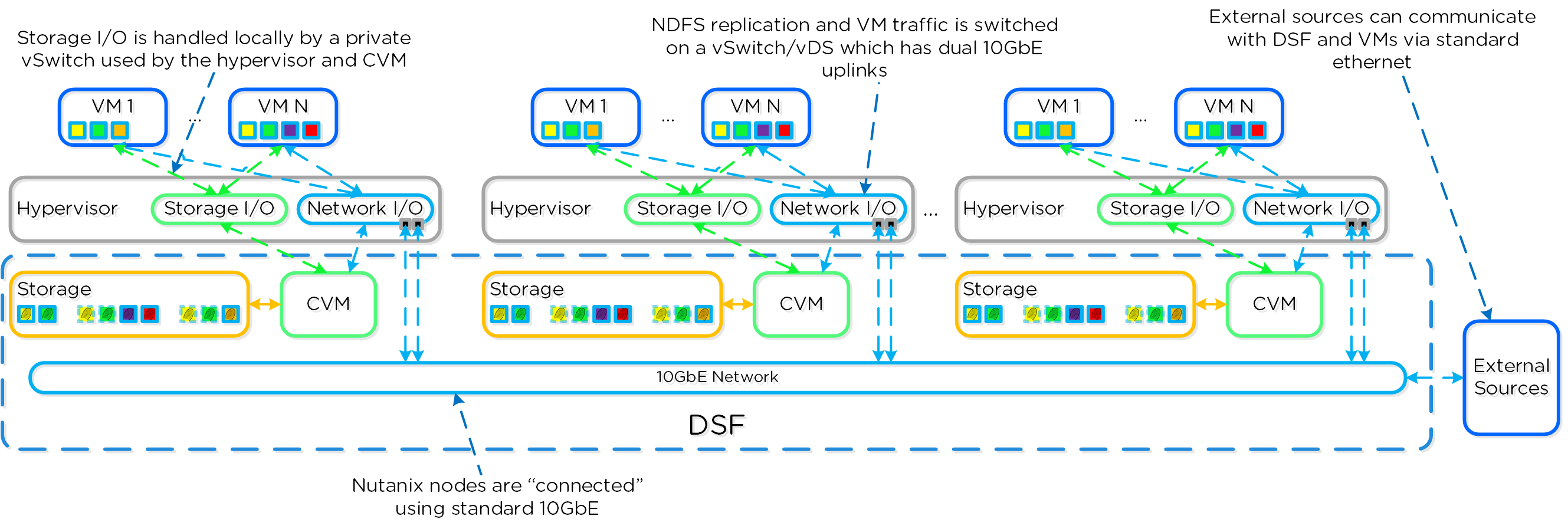
データ ローカリティ
コンバージド(サーバー+ストレージ)プラットフォームであるNutanixでは、I/Oとデータのローカリティが、クラスタおよびVMのパフォーマンスにおいて重要な要素となります。 前述のI/Oパスの通り、全てのRead/Write I/Oは、一般のVMに隣接した各ハイパーバイザー上に存在するローカルのコントローラーVM(CVM)によって処理されます。 VMのデータは、ローカルでCVMから提供され、CVMコントロール下のローカルディスクにストアされます。 VMが特定のハイパーバイザー ノードから他に移動する場合(あるいはHAイベント発生中)には、新たなローカルCVMによって移行されたVMのデータが処理されます。 古いデータ(リモート ノード/CVMに格納)を読み込む際、I/OはローカルCVMからリモートCVMに転送されます。 全てのWrite I/Oは、直ちにローカルで処理されます。 AOSは、異なるノードで発生したI/Oを検知し、バックグラウンドで該当データをローカルに移動し、全てのRead I/Oがローカルで処理されるようにします。 ネットワークに負荷を与えないようにするため、データの移動はRead処理が発生した場合にのみ実施されます。
データ ローカリティは、主に以下2つの状況で発生します:
-
キャッシュ ローカリティ
- リモートデータはローカルStargateのユニファイド キャッシュに取り込みます。 これは4Kの粒度で行われます。
- ローカルレプリカがないインスタンスの場合、リクエストはレプリカを持っていてデータを戻せるStargateに転送され、ローカルStargateはこれをローカルに格納してからI/Oを返します。 そのデータに対するその後の全てのリクエストは、キャッシュから返されます。
-
エクステントグループ(egroup)ローカリティ
- vDiskエクステントグループ(egroup)を、ローカルStargateのエクステントストアに保存されように移行しています。
- レプリカegroupが既にローカルにある場合、移動は必要ありません。
- このシナリオでは、実際のレプリカegroupは一定のI/Oしきい値に到達すると再ローカライズされます。 ネットワークを効率的に利用するために、egroupを自動的に再ローカライズや移行することはありません。
- AESが有効なegroupでも、レプリカがローカルではなくパターンが満たされている場合に、同様に水平移行が発生します。
以下は、VMがハイパーバイザー ノード間を移動した場合、データがどのようにVMを「追いかけるか」を図示したものです:
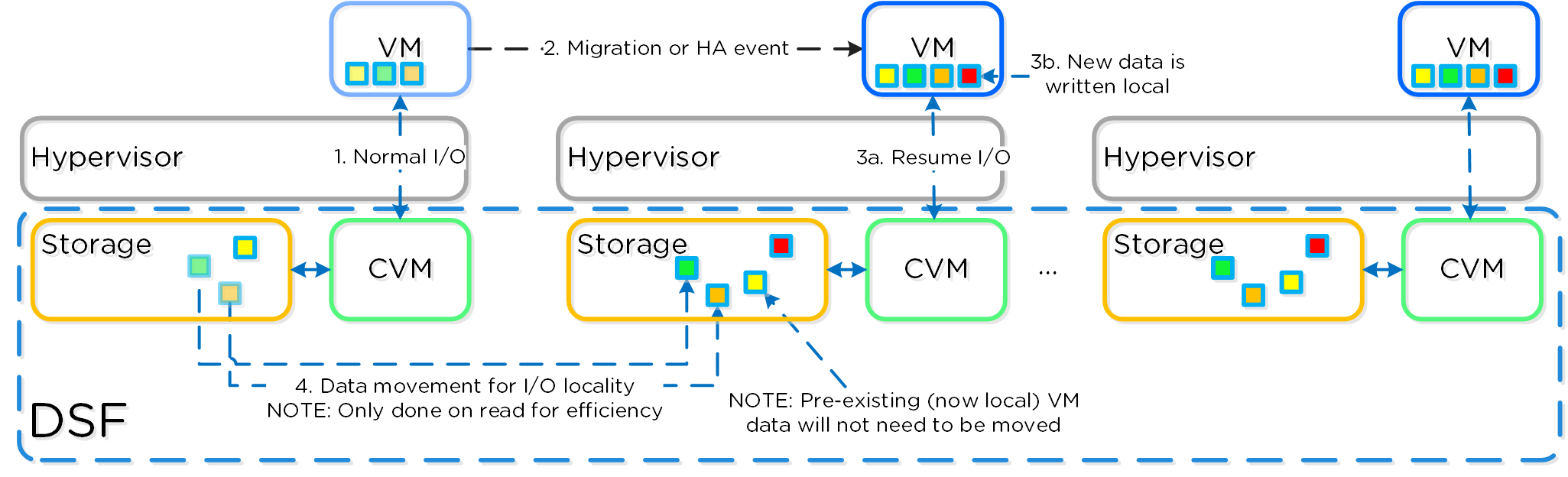
データ移行のしきい値
キャッシュローカリティはリアルタイムに発生し、vDiskの所有権に応じて決定されます。 vDiskやVMがあるノードから別のノードに移ると、vDiskの「所有権」もローカルCVMに移動します。 所有権が移動すると、データはユニファイド キャッシュ内でローカルにキャッシュされます。 その間、キャッシュは所有権がある場所(この場合はリモート ホスト)に格納されます。 それまでデータをホストしていたStargateは、リモートI/Oが300秒を超えた際にvDiskトークンを放棄し、それをローカルのStargateが引き継ぎます。 vDiskデータをキャッシュするには所有権が必要なため、キャッシュの統合処理が行われます。
egroupのローカリティは、サンプリングに基づく処理であり、エクステント グループの移行は以下の状況により発生します: 「10秒毎のサンプリング計測で、複数のRead処理が発生している10分間に、ランダム アクセスが3回、またはシーケンシャル アクセスが10回発生した場合」
シャドウ クローン
分散ストレージ ファブリックには「シャドウ クローン」と呼ばれる機能があり、「複数の読み手」のある特定のvDiskやVMデータの分散キャッシングを行うことができます。 VDI導入中に、多くの「リンク クローン」がReadリクエストをセントラルマスター、つまり「ベースVM」に対して送信する場合などがこの典型例と言えます。 VMware Viewの場合、この仕組みはレプリカ ディスクと呼ばれ、全てのリンク クローンから読み込まれます。 XenDesktopの場合には、MCSマスターVMと呼ばれています。 これは複数の読み手が存在する場合(例えば展開サーバーやリポジトリ)などあらゆるシナリオで機能します。 データやI/Oのローカリティは、VMが最大パフォーマンスを発揮するために不可欠であり、またAOSの重要な構成要素となります。
AOSは、シャドウ クローンを使って、データ ローカリティと同様にvDiskのアクセス傾向をモニターします。 しかし、2つ以上のリモートCVM(ローカルCVMも同様)からリクエストがあり、かつ全てがRead I/Oリクエストであった場合、vDiskは変更不可とマークされます。 一旦ディスクが変更不可とマークされると、vDiskはCVM毎にローカルにキャッシングされ、Readリクエストに対応できるようになります(ベースvDiskのシャドウクローンとも言います)。 これによって、各ノードのVMがベースVMのvDiskをローカルに読み込めるようになります。VDIの場合、レプリカディスクがノード毎にキャッシュされ、ベースに対する全てのReadリクエストがローカルで処理されるようになります。
注意: データの移動は、ネットワークに負荷を与えずに効率的なキャッシュ利用を可能にするため、Read処理が発生した場合にのみ実施されます。 ベースVMに変更があった場合、シャドウクローンは削除され、プロセスは最初からやり直しとなります。
シャドウ クローンは、デフォルトで有効化されており(4.0.2の場合)、以下のnCLIコマンドを使って有効化/無効化できます:
ncli cluster edit-params enable-shadow-clones=<true/false>
以下に、シャドウ クローンの動作と分散キャッシングの方法を図示します:
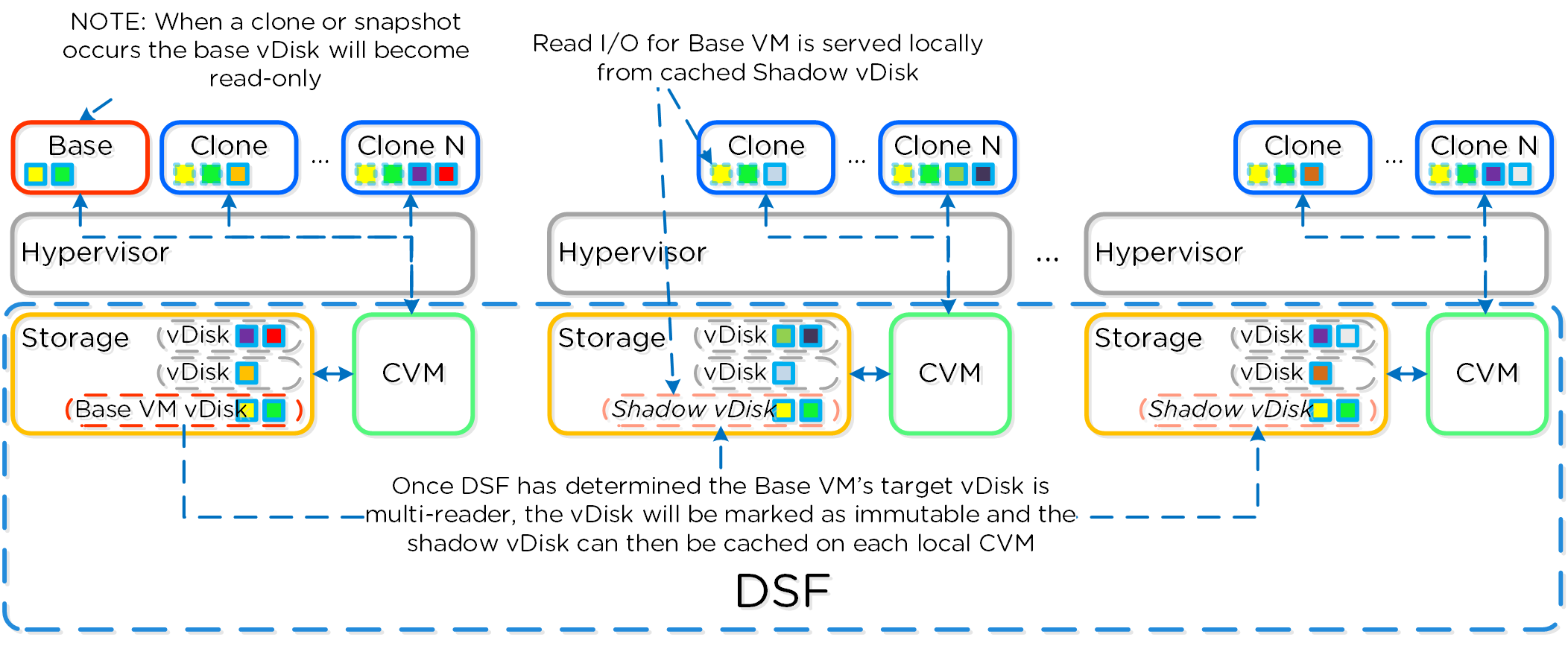
ストレージ層と監視
Nutanixプラットフォームは、VM/ゲストOSから物理ディスク デバイスに至るまで、スタック全体にわたる複数の層でストレージを監視しています。 様々な階層とそれらの関係を十分理解することが、ソリューションの監視においては非常に重要となり、処理との関連性をより可視化することができます。 以下は、処理を監視している各層とその粒度について図示したものです:

仮想マシン層
- 主要な役割: VM用にハイパーバイザーがレポートするメトリクス
- 説明: 仮想マシンまたはゲスト レベルのメトリクスをハイパーバイザーから直接取得し、VMから見たパフォーマンスおよびアプリケーションから見たI/Oパフォーマンスを提示
- 使用場面: トラブル シューティングやVMレベルの詳細を把握したい場合に使用されます。
ハイパーバイザー層
- 主要な役割: ハイパーバイザーがレポートするメトリクス
- 説明: ハイパーバイザー レベルのメトリクスを直接ハイパーバイザーから取得し、最も正確なハイパーバイザーから見たメトリクスを提示します。 該当データは複数のハイパーバイザーまたはクラスタ全体で見ることができます。 この層は、プラットフォームから見たパフォーマンスを確認するという意味では最も正確なデータを提供するため、多くのケースで活用されるべきです。 シナリオによっては、ハイパーバイザーがVMからの処理を組み合わせる、または分解することで、VMとハイパーバイザーによって異なるメトリクスが提示される場合があります。 これらの数値には、Nutanix CVMが提供するキャッシュ ヒットも含まれています。
- 使用場面: 最も詳細で価値あるメトリクスを提供するため、ほとんどのケースで使用されます。
コントローラー層
- 主要な役割: Nutanixコントローラーがレポートするメトリクス
- 説明: NutanixコントローラーVM(例えばStargate 2009ページ)からコントローラー レベルのメトリクスを直接取得し、NFS/SMB/iSCSIやバックエンド処理(例えばIML、ディスク バランシングなど)からNutanixフロントエンドが見ている内容を提示します。 このデータは、複数のコントローラーVMまたはクラスタ全体を通じて見ることができます。 通常、コントローラー層から見たメトリクスは、ハイパーバイザー層から見たメトリクスと一致しますが、これにバックエンド処理(例えばILMやディスク バランシングなど)が含まれています。 また、これらの数値には、メモリが提供するキャッシュ ヒットも含まれています。 NFS/SMB/iSCSIクライアントが大規模なI/Oを複数の小さなI/O単位に分解していることもあるため、IOPSのようなメトリクスについては一致しない場合があります。 しかし、帯域幅のようなメトリクスについては一致します。
- 使用場面: ハイパーバイザー層と同様に、バックエンド処理の負荷を提示するために使用することができます。
ディスク層
- 主要な役割: ディスク デバイスがレポートするメトリクス
- 説明: 物理ディスク デバイスから (CVM経由で) ディスク レベルのメトリクスを直接取得し、バックエンドから見た状態を提示します。 これには、ディスクI/Oが発生するOpLogやエクステント ストアにヒットするデータが含まれています。 このデータは、複数のディスク、特定のノードのディスクまたはクラスタのディスク全体で見ることができます。 通常、ディスク処理は、受信するWriteおよびメモリ キャッシュから提供されないReadの数と一致します。 メモリ キャッシュによって提供される全てのReadは、ディスク デバイスがヒットされないため、ここではカウントされません。
- 使用場面: キャッシュから提供した処理やディスクをヒットした処理の数を確認する場合に使用されます。
メトリクスと統計情報の保持
メトリクスと時系列データは、Prism Elementにローカルで90日間保存されます。Prism CentralやInsightsでは、データを (キャパシティが許す限り) 無期限に保存します。
AOSのサービス
Based on: PC 2023.3 | AOS 6.7
Nutanix Guest Tools (NGT)
Nutanix Guest Tools (NGT) は、ソフトウェア ベースのゲストにインストールするエージェント フレームワークであり、Nutanixプラットフォームを介して高度なVM管理機能を提供します。
本ソリューションは、VMにインストールされたNGTインストーラーおよび、エージェントとNutanixプラットフォーム間の調整に使用されるGuest Tools Frameworkで構成されています。
NGTインストーラーには以下のコンポーネントが含まれています:
- Guest Agent Service
- セルフ サービス リストア(SSR)、またはファイル レベル リストア(FLR)のCLI
- VM Mobility Drivers(AHV用のVirtIOドライバー)
- Windows VM用の、VSSエージェントおよびハードウェア プロバイダー
- Linux VM用の、アプリケーション整合性(App Consistent)スナップショットのサポート(スクリプトによる静止状態の取得)
このフレームワークは少数のハイレベル コンポーネントで構成されています:
-
Guest Tools Service
- AOS、Nutanixサービス、そしてGuest Agent間のゲートウェイです。 現在の(クラスタVIPをホストしている)Prismリーダー上で稼動する選定されたNGTリーダーで、クラスタ内のCVMへ分散されます。
-
Guest Agent
- NGTインストール プロセスの一部として、VMのOSに展開されるエージェントおよび関連サービスです。 ローカル機能(VSS、セルフ サービス リストア - SSR など)を処理し、Guest Tools Serviceとのやり取りを行います。
以下に各コンポーネントの関係概要を示します:
Guest Tools Service
Guest Tools Serviceは、以下2つの主要機能で構成されています:
-
NGTリーダー
- NGTプロキシからのリクエストを処理し、AOSコンポーネントとのやり取りを行います。 クラスタ毎に1つのNGTリーダーが動的に選定され、現状のリーダーに障害が発生すると、新しいものが選定されます。 本サービスは、ポート2073を使用して内部と接続します。
-
NGTプロキシ
- 全てのCVM上で稼動し、NGTリーダーが必要な処理を実行するためにリクエストを転送します。 (VIPをホストしている)Prismリーダーとして稼動するVMが、Guest Agentからの通信を処理するCVMとなります。 ポート2074を使って外部と接続します。
現在のNGTリーダー
NGTリーダーをホストしているCVMのIPは、以下のコマンドにより確認することができます(どのCVM上でも実行可能)。
nutanix_guest_tools_cli get_leader_location
以下に各ロールの概要を示します:
Guest Agent
前述の通り、Guest Agentは主に以下のようなコンポーネントで構成されています:
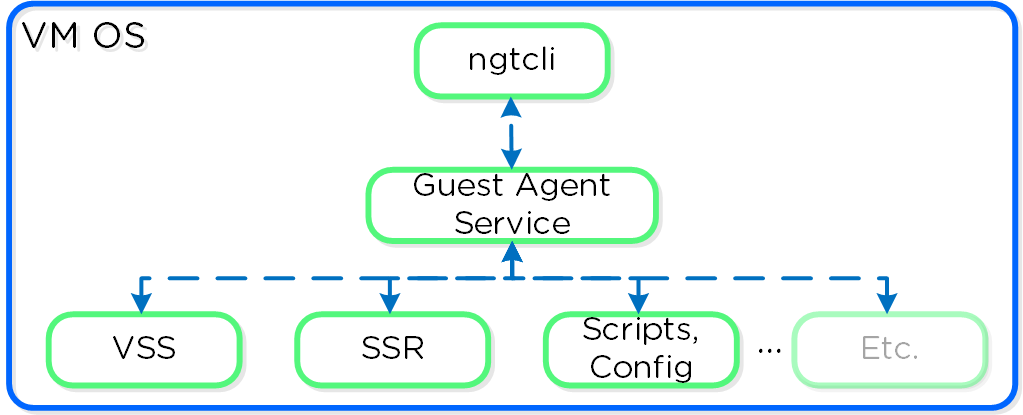
通信とセキュリティ
Guest Agent Serviceは、仮想マシンからCVMへのシリアル ポート接続を介して、Guest Tools Serviceと通信します。 サービスがシリアル ポート経由でCVMに到達できない場合は、SSLを使用するNutanixクラスタVIPへのネットワーク接続にフェイルバックします。 Nutanixクラスタ コンポーネントとUVMが別のネットワークに展開されている場合(可能であればすべて)、このフォールバック通信方法を許可するために次のことが可能であることを確認してください:
- UVMネットワークからクラスタVIPへのルーティング通信が可能なこと または
- UVMネットワークからポート2074 (推奨) 上のクラスタVIPに通信が可能となるように、ファイアウォール規則 (及び関連するNAT) が生成されていること
Guest Tools Serviceは、認証局(CA - Certificate Authority)として機能し、NGTが有効なUVMのための証明書ペアを生成します。 この証明書は、UVMのために構成されたISOに埋め込まれ、NGT導入プロセスの一部として使用されます。 これらの証明書はインストール プロセスの一部としてUVM内部にインストールされます。
NGTエージェントのインストール
NGT Agentのインストールは、Prism、インストール パッケージ、またはCLIおよびnCLI、REST API、PowerShellなどのスクリプトを介して実行できます。 インストール パッケージは、.exe(Windows)、.rpmおよび.deb(Linux)形式で用意されており、Nutanix Support & Insights Portalから入手できます。 これらのインストーラーは、手動、スクリプト経由、またはサードパーティのツールによってインストールできます。 サードパーティ ツールを使用する方式では、既存のツールを利用してNGTを大規模にインストールできます。
NGTの一括導入
それぞれの仮想マシンにNGTをインストールするのではなく、前述のインストール パッケージを使用するか、ベース イメージにNGTを埋め込んで展開できます。 パッケージ化での展開には、NGT Bulk Install instructions の手順を使用してください。
ベースイメージ内のNGTを使用できるようにするためには、次の手順に従います:
- NGTをテンプレートの仮想マシンにインストールし、CVMとの通信を可能にします
- テンプレートの仮想マシンから、仮想マシンをクローン作成します
-
NGT ISOを各クローン上でマウントします(新しい証明書ペアが必要)
- 例: ncli ngt mount vm-id=<CLONE_ID> またはPrismを使用
- クローンをパワーオン
クローンされた仮想マシンが起動されると、新しいNGT ISOを検知し、関連設定ファイルと新しい証明書をコピーして、Guest Tools Serviceとの通信を開始します。
OSのカスタマイズ
Nutanixでは、cloud-initおよびSysprepを使用してネイティブにOSをカスタマイズすることが可能です。 cloud-initは、Linuxクラウドサーバーのブートストラップを処理するパッケージです。 これにより短時間でLinuxインスタンスの初期化とカスタマイズを行うことができます。 Sysprepは、WindowsのOSカスタマイズ機能です。
例えば、次のようなケースで使用します:
- ホスト名の設定
- パッケージのインストール
- ユーザーの追加、キー管理
- カスタムスクリプト
サポート対象構成
本ソリューションは、以下のバージョンを含むAHV上で稼動するLinuxゲストで有効となります。 (以下のリストは一部です。全てを確認する際には、ドキュメントをご覧ください)
-
ハイパーバイザー:
- AHV
-
オペレーティングシステム:
- Linux - 最新のディストリビューション
- Windows - 最新のディストリビューション
前提
cloud-initを利用するためには以下が必要となります:
- cloud-initパッケージがLinuxイメージにインストールされていること
Sysprepはデフォルトで有効となっており、Windowsにインストールされています。
パッケージのインストレーション
cloud-initは(もし未済の場合には)以下のコマンドでインストールすることができます:
Red Hatベースのシステム (CentOS、RHEL)
yum -y install cloud-init
Debianベースのシステム (Ubuntu)
apt-get -y update; apt-get -y install cloud-init
Sysprepは、Windowsインストレーションの一部となっています。
イメージのカスタマイズ
カスタムスクリプトを使用してOSのカスタマイズを行うためには、PrismのチェックボックスまたはREST APIに内容を記述します。このオプションは、VMの作成またはクローニング処理の途中で指定します:
Nutanixには、カスタムスクリプトパスを指定するいくつかの方法があります:
-
ADSFパス
- 先にADSFにアップロードしたファイルを使用
-
ファイルをアップロード
- 使用するファイルをアップロード
-
スクリプトを手入力または貼り付ける
- cloud-initスクリプトまたはUnattend.xmlテキスト
Nutanixは、スクリプトを含むCD-ROM作成によって、初回ブート中にcloud-initまたはSysprepプロセスにユーザーデータスクリプトを引き渡します。 処理が完了した時点でCD-ROMを取り外します。
入力フォーマット
このプラットフォームは、様々なデータ入力フォーマットをサポートしています。以下に主なフォーマットの一部を示します:
ユーザーデータスクリプト (cloud-init - Linux)
ユーザーデータスクリプトは、簡単なシェルスクリプトでブートスクリプトの最後で処理されます(例えば「rc.local-like」)。
本スクリプトは、bashスクリプトのように「#!」で開始します。
以下にユーザーデータスクリプトの例を示します:
#!/bin/bash touch /tmp/fooTest mkdir /tmp/barFolder
インクルードファイル (cloud-init - Linux)
インクルードファイルには、URLのリスト(一行に1つ)が含まれています。各URLが読み込まれ、他のスクリプト同様に処理されます。
本スクリプトは「#include」で開始します。
以下はインクルードスクリプトの例です:
#include http://s3.amazonaws.com/path/to/script/1 http://s3.amazonaws.com/path/to/script/2
クラウド構成データ (cloud-init - Linux)
cloud-config入力タイプは、cloud-initで最もよく使用されています。
本スクリプトは「#cloud-config」で開始します。
以下にクラウド構成データスクリプトの例を示します:
#cloud-config # Set hostname hostname: foobar # Add user(s) users: - name: nutanix sudo: ['ALL=(ALL) NOPASSWD:ALL'] ssh-authorized-keys: - ssh-rsa: <PUB KEY> lock-passwd: false passwd: <PASSWORD> # Automatically update all of the packages package_upgrade: true package_reboot_if_required: true # Install the LAMP stack packages: - httpd - mariadb-server - php - php-pear - php-mysql # Run Commands after execution runcmd: - systemctl enable httpd
cloud-init実行結果の確認
cloud-initのログファイルは、/var/log/cloud-init.log および cloud-init-output.logにあります。
Unattend.xml (Sysprep - Windows)
unattend.xmlファイルは、ブート時のイメージカスタマイズに使用するSysprepの入力ファイルであり、詳細はこちらで確認できます: LINK
本スクリプトは、「<?xml version="1.0" ?>」で開始します。
以下はunattend.xmlファイルの例です:
<?xml version="1.0" ?> <unattend xmlns="urn:schemas-microsoft-com:unattend"> <settings pass="windowsPE"> <component name="Microsoft-Windows-Setup" publicKeyToken="31bf3856ad364e35" language="neutral" versionScope="nonSxS" processorArchitecture="x86"> <WindowsDeploymentServices> <Login> <WillShowUI>OnError</WillShowUI> <Credentials> <Username>username</Username> <Domain>Fabrikam.com</Domain> <Password>my_password</Password> </Credentials> </Login> <ImageSelection> <WillShowUI>OnError</WillShowUI> <InstallImage> <ImageName>Windows Vista with Office</ImageName> <ImageGroup>ImageGroup1</ImageGroup> <Filename>Install.wim</Filename> </InstallImage> <InstallTo> <DiskID>0</DiskID> <PartitionID>1</PartitionID> </InstallTo> </ImageSelection> </WindowsDeploymentServices> <DiskConfiguration> <WillShowUI>OnError</WillShowUI> <Disk> <DiskID>0</DiskID> <WillWipeDisk>false</WillWipeDisk> <ModifyPartitions> <ModifyPartition> <Order>1</Order> <PartitionID>1</PartitionID> <Letter>C</Letter> <Label>TestOS</Label> <Format>NTFS</Format> <Active>true</Active> <Extend>false</Extend> </ModifyPartition> </ModifyPartitions> </Disk> </DiskConfiguration> </component> <component name="Microsoft-Windows-International-Core-WinPE" publicKeyToken="31bf3856ad364e35" language="neutral" versionScope="nonSxS" processorArchitecture="x86"> <SetupUILanguage> <WillShowUI>OnError</WillShowUI> <UILanguage>en-US</UILanguage> </SetupUILanguage> <UILanguage>en-US</UILanguage> </component> </settings> </unattend>
Nutanix Kubernetes Engine(コンテナサービス)
Nutanixは、(現状では)Kubernetesを使用することで、永続的 (persistent) コンテナを利用することができます。以前もNutanixプラットフォームでDockerを動かすことは可能でしたが、短命なコンテナの特性によってデータの永続性確保が困難でした。
Dockerのようなコンテナテクノロジーは、ハードウェアの仮想化とは異なるアプローチと言えます。従来の仮想化では、それぞれのVM自体がオペレーティングシステム (OS) を持っていましたが、基盤となるハードウェアは共有されていました。アプリケーションやそれに必要な全てを含むコンテナは、オペレーティングシステム (OS) のカーネルを共有しながら、独立したプロセスとして実行されます。
以下の表では、VMとコンテナの簡単な比較を行っています:
| 比較基準 | 仮想マシン (VM) | コンテナ |
|---|---|---|
| 仮想化タイプ | ハードウェアレベルの仮想化 | OSカーネルの仮想化 |
| オーバーヘッド | 重い | 軽い |
| プロビジョニングの速さ | 遅い(数秒から数分) | リアルタイム / 高速 (usからms) |
| パフォーマンス オーバーヘッド |
限定的なパフォーマンス | ネイティブなパフォーマンス |
| セキュリティ | 完全に独立(相対的に高い) | プロセスレベルで独立 (相対的に低い) |
サポート対象構成
本ソリューションでは、以下の構成をサポートします。(一部のみを掲載しています。完全なリストについてはドキュメントをご覧ください)
-
ハイパーバイザー:
- AHV
-
コンテナシステム*:
- Docker 1.13
*AOS 4.7の時点で本ソリューションがサポートする対象は、Dockerベースのコンテナとの連携に限定されていますが、他のコンテナシステムについても、Nutanixプラットフォーム上のVMとして稼動させることが可能です。
コンテナサービスの構成要素
Karbonコンテナサービスは、以下の要素で構成されています:
- Nutanix Docker Machine Driver: Docker MachineおよびAOSイメージサービス経由でDockerコンテナホストのプロビジョニングを行います
- Nutanix Docker Volume Plugin: AOS Volumesとやり取りを行い、必要なコンテナに対してボリュームを作成、フォーマット、アタッチします
Dockerは以下の要素から構成されています(注意:全てが必要となる訳ではありません)
- Docker Image: コンテナのベースとイメージ
- Docker Registry: Dockerイメージの保持領域
- Docker Hub: オンラインコンテナのマーケットプレイス(パブリックDockerレジストリ)
- Docker File: Dockerイメージの構成方法に関する説明テキストファイル
- Docker Container: Dockerイメージのインスタンス化を実行
- Docker Engine: Dockerコンテナの作成、提供、実行
- Docker Swarm: Dockerホストクラスタ / スケジューリングプラットフォーム
- Docker Daemon: Docker Clientからのリクエストを処理し、コンテナを構成、実行、配布
- Docker Store: エンタープライズ向けの信頼性の高いコンテナのマーケットプレイス
サービスのアーキテクチャー
現在のところNutanixでは、Docker Machineを使用して生成されたVM内で稼動するDocker Engineを使用しています。これらのマシンは、通常のVMと一緒にプラットフォーム上で稼動させることができます。
Nutanixが開発したDocker Volume Pluginは、AOS Volumesの機能を利用して、コンテナ用にボリュームを作成、フォーマット、そしてアタッチします。 これによって、電源のオン・オフの繰り返しや移動において、データはコンテナとして永続性を保つことができます。
データの永続性は、AOS Volumesを活用してボリュームをホストやコンテナにアタッチするNutanix Volume Pluginを使用することで確保されます。
前提
コンテナサービスを使用するためには、以下の前提条件を満たす必要があります:
- NutanixクラスタがAOS 4.7以降であること
- CentOS 7.0またはRHEL 7.2以上のOSイメージを、iscsi-initiator-utilsパッケージと一緒にダウンロード済みであり、それがAOSイメージサービス内にイメージとして存在すること
- NutanixデータサービスIPが設定されていること
- Docker Toolboxがクライアントマシンにインストールされ設定可能なこと
- Nutanix Docker Machine DriverがクライアントのPATHに存在すること
Dockerホストの作成
上記前提条件が全て満たされた前提で、Docker Machine を使用してNutanix Dockerホストをプロビジョニングする最初の手順は:
docker-machine -D create -d nutanix \ --nutanix-username <PRISM_USER> --nutanix-password <PRISM_PASSWORD> \ --nutanix-endpoint <CLUSTER_IP>:9440 --nutanix-vm-image <DOCKER_IMAGE_NAME> \ --nutanix-vm-network <NETWORK_NAME> \ --nutanix-vm-cores <NUM_CPU> --nutanix-vm-mem <MEM_MB> \ <DOCKER_HOST_NAME>
下図にバックエンドのワークフロー概要を示します:
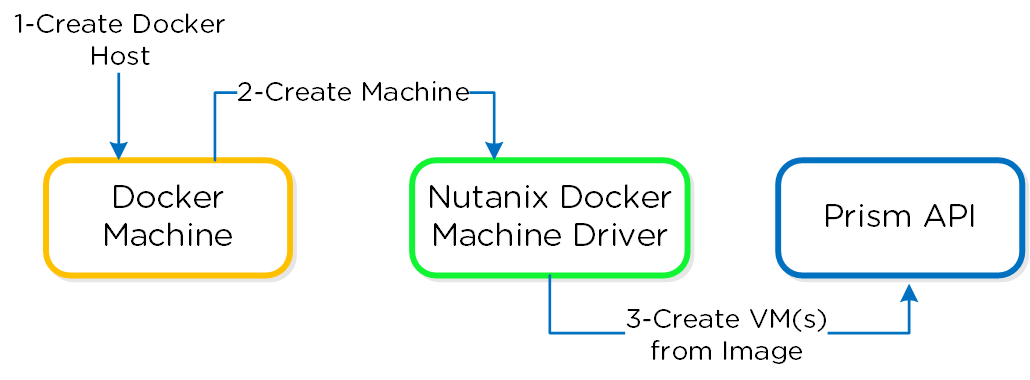
次に、docker-machine ssh経由で、新たに用意されたDockerホストに対してSSHを実行します:
docker-machine ssh <DOCKER_HOST_NAME>
以下を実行して、Nutanix Docker Volume Pluginをインストールします:
docker plugin install ntnx/nutanix_volume_plugin PRISM_IP=<PRISM-IP> DATASERVICES_IP=<DATASERVICES-IP> PRISM_PASSWORD=<PRISM-PASSWORD> PRISM_USERNAME=<PRISM-USERNAME> DEFAULT_CONTAINER=<Nutanix-STORAGE-CONTAINER> --alias nutanix
起動が完了したら、プラグインの有効化を確認します:
[root@DOCKER-NTNX-00 ~]# docker plugin ls ID Name Description Enabled 37fba568078d nutanix:latest Nutanix volume plugin for docker true
Dockerコンテナの作成
Nutanix Dockerホストが導入され、ボリュームプラグインが有効化されると、永続的ストレージにコンテナをプロビジョニングすることができます。
通常のdocker volumeコマンド構造を使ってNutanix Volume Driverを指定することで、AOS Volumesを使用するボリュームを作成することができます。 以下に例を示します:
docker volume create \ <VOLUME_NAME> --driver nutanix
例:
docker volume create PGDataVol --driver nutanix
以下のコマンド構造を使って、作成したボリュームを使用するコンテナを作成できます。
docker run -d --name <CONTAINER_NAME> \ -p <START_PORT:END_PORT> --volume-driver nutanix \ -v <VOL_NAME:VOL_MOUNT_POINT> <DOCKER_IMAGE_NAME>
例:
docker run -d --name postgresexample -p 5433:5433 --volume-driver nutanix -v PGDataVol:/var/lib/postgresql/data postgres:latest
下図にバックエンド処理のワークフローを示します:
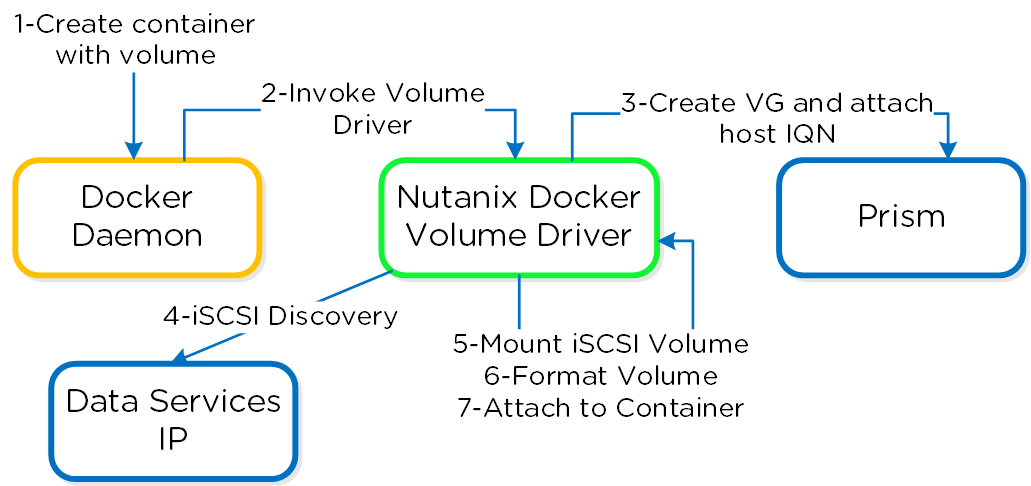
以上のように、永続的ストレージ上でコンテナを動かすことができました!
バックアップとディザスタリカバリ
Nutanixでは、ネイティブにバックアップとディザスタリカバリ (DR) 機能を提供しており、オンプレミスとクラウド環境(Xi)の両方で、ユーザーがDSF上で稼動する仮想マシンやオブジェクトをバックアップ、リストア、DRできるようにしています。 AOS 5.11 で、Nutanixはこれらの多くのコンセプトを抽象化するNutanix Disaster Recovery(旧称:Leap)とよばれる機能をリリースしました。 Nutanix Disaster Recoveryについての追加情報は、Backup / DR ServicesのNutanix Disaster Recoveryチャプターを参照してください。
次のセクションでは、以下の点について説明を行います:
- 導入構成
- 保護エンティティ
- バックアップとリストア
- レプリケーションとDR
注意: NutanixはネイティブにバックアップとDR機能を提供していますが、従来のソリューション(CommvaultやRubrikなど)についても、プラットフォームが提供するネイティブな機能(VSS、スナップショットなど)のいくつかを活用することで提供が可能です。
構成要素
NutanixバックアップとDRには、幾つかの主要な構成要素があります:
保護ドメイン (PD - Protection Domain)
- 主な役割: 保護対象となるVMまたはファイルのマクログループ
- 説明: 要求されたスケジュールに基づき、同時にレプリケートするVMまたはファイル(混在可)で構成された1つのグループ。 PDによってフルコンテナ、または選択した個別のVMまたはファイルを保護することができます。
プロからのヒント
希望するRPO/RTOに従って個々のサービス階層向けに複数のPDを作成します。 ファイル配布(ゴールデンイメージやISOなど)に対しては、レプリケーションするファイルを対象にPDを作成することができます。
整合性グループ(CG - Consistency Group)
- 主な役割: キャッシュの一貫性を維持すべきPD内のVMまたはファイルのサブセット
- 説明: クラッシュ整合性のある方法でスナップショットされる必要がある保護ドメイン(PD)のVMまたはファイル。 これによって、VMまたはファイルがリカバリされた場合、整合性のある状態で再生されます。 保護ドメインは、複数の整合性グループを持つことができます。
プロからのヒント
整合性グループ内で依存関係にあるアプリケーションやサービスVMをグループ化することで、これらを整合性のある状態で復旧することができます(例えばアプリとDBなど)
スナップショットスケジュール
- 主な役割: スナップショットとレプリケーションのスケジュール
- 説明: 特定のPDおよびCGにあるVMのスナップショットおよびレプリケーションのスケジュール
プロからのヒント
スナップショットのスケジュールは、希望するRPOと一致している必要があります
リテンションポリシー
- 主な役割: 保持するローカルおよびリモートスナップショットの数
- 説明: リテンションポリシーでは、保持するローカルおよびリモートスナップショットの数を定義します。
- 注意:リモートサイトについては、リモートリテンション/レプリケーションポリシーに対応するよう設定する必要があります
プロからのヒント
リテンションポリシーは、VMまたはファイル毎に必要となるリストアポイントの数と一致している必要があります
リモートサイト
- 主な役割: リモートNutanixクラスタ
- 説明: リモートNutanixクラスタは、バックアップまたはDRのターゲットとして使用することができます
プロからのヒント
ターゲットとなるサイトには、完全なサイト障害に備えた十分なキャパシティ(サーバー、ストレージ)が必要です。 このような場合には、単一サイト内のラック間でのレプリケーションも有効となります。
以下に、単一サイトのPD、CGおよびVMまたはファイルの関係を示します:
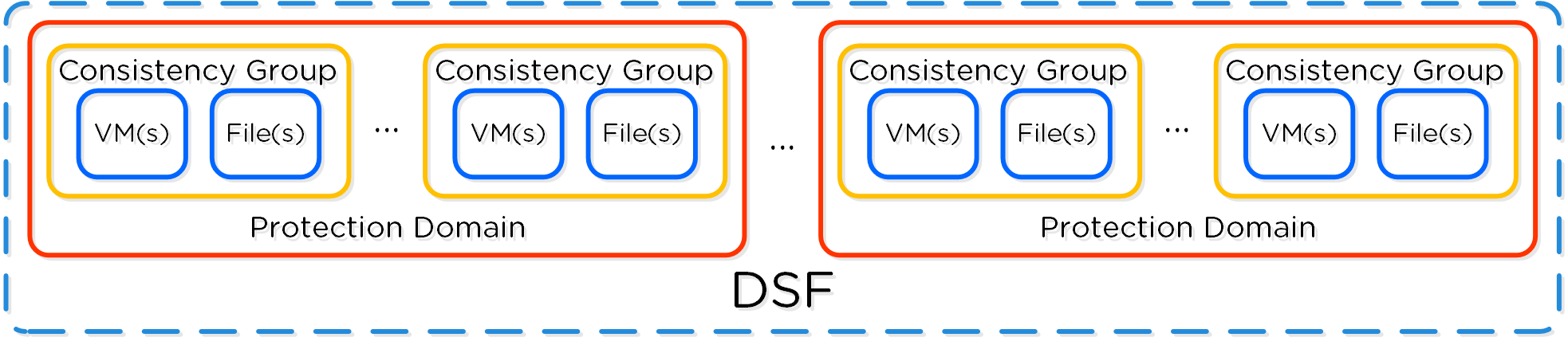
ポリシーベースのDRとランブック
ポリシーベースのDRとランブックは、VMベースのDRで定義されていた機能(PD、CGなど)を拡張し、ポリシー駆動モデルとして抽象化します。 重要な項目(例えばRPOや保持期限など)に焦点をあて、VMに直接ではなくカテゴリ割り当てにすることで、設定を簡素化します。 また、すべてのVMに適用できる「デフォルトポリシー」を設定することもできます。
注: これらのポリシーは、Prism Central(PC)で構成します。
エンティティの保護
以下の手順に従って、エンティティ(VM、VG、ファイル)を保護することができます:
Data Protection(データ保護)ページで、+ Protection Domain -> Async DR とします:

PD名を設定し、「Create(作成する)」をクリックします。
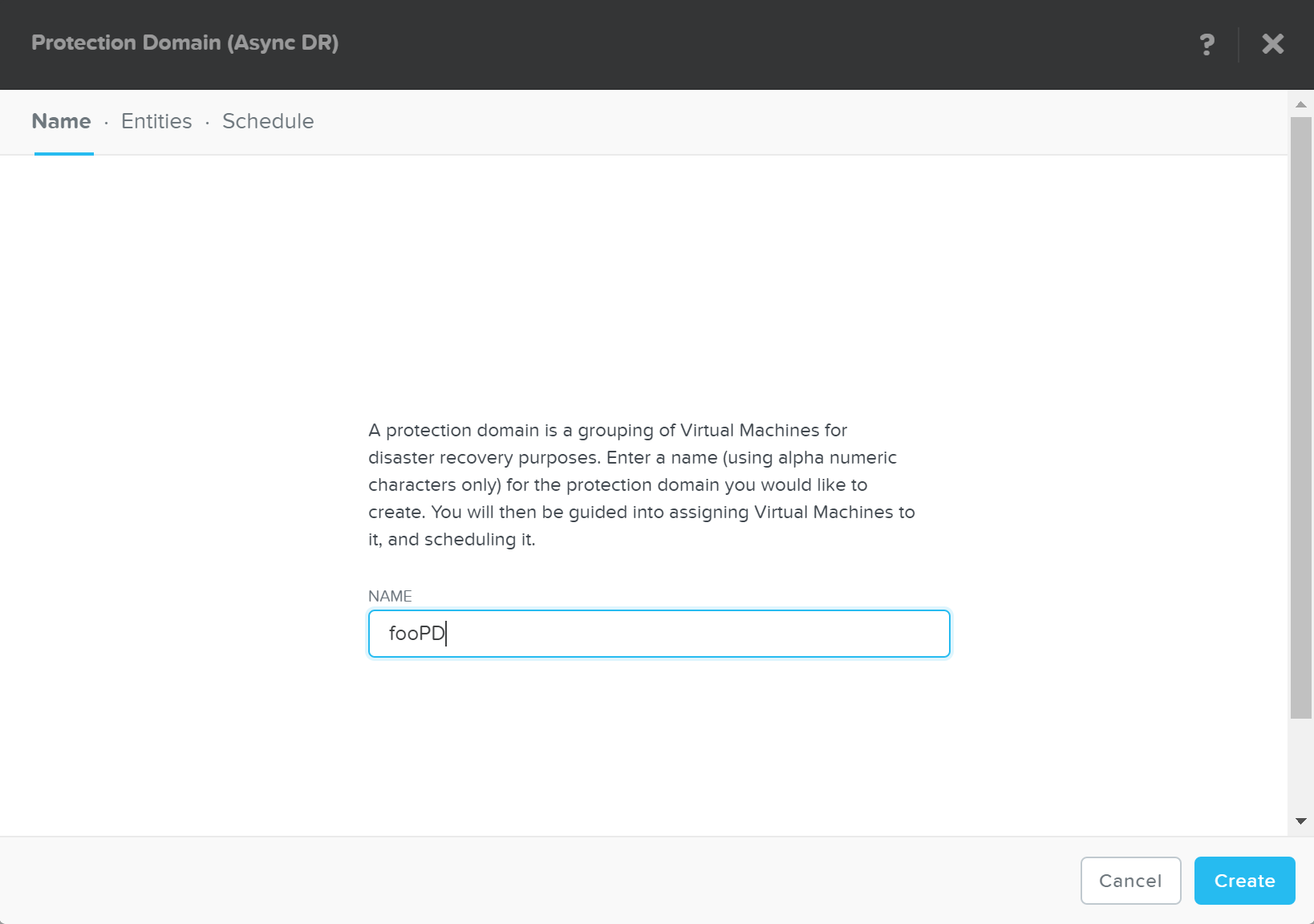
保護するエンティティの選択:
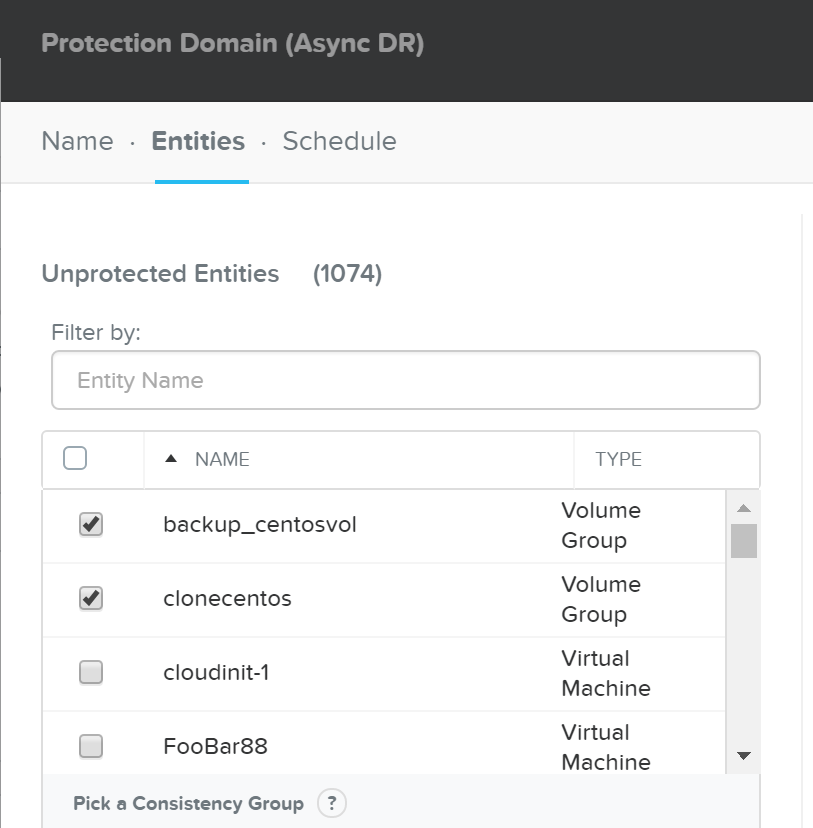
「Protect Selected Entities(選択済みエンティティを保護)」をクリックします。
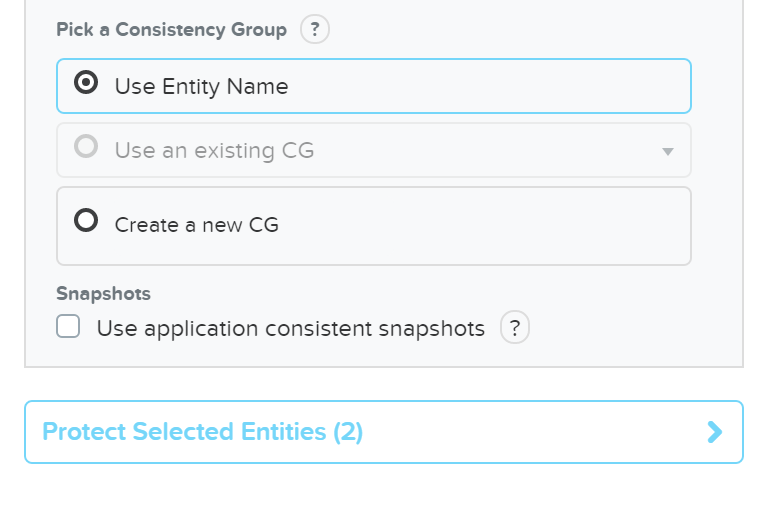
保護されたエンティティは、「Protected Entities(保護されているエンティティ)」に表示されます。
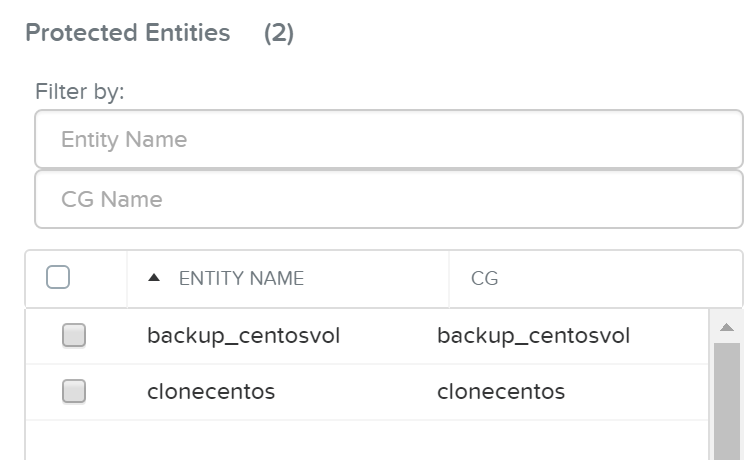
「Next(次へ)」をクリックし、次に「Next Schedule(次回のスケジュール)」をクリックしてスナップショットとレプリケーションをスケジュールします。
スナップショットの頻度、保存方針、レプリケーションするリモートサイトを設定します。
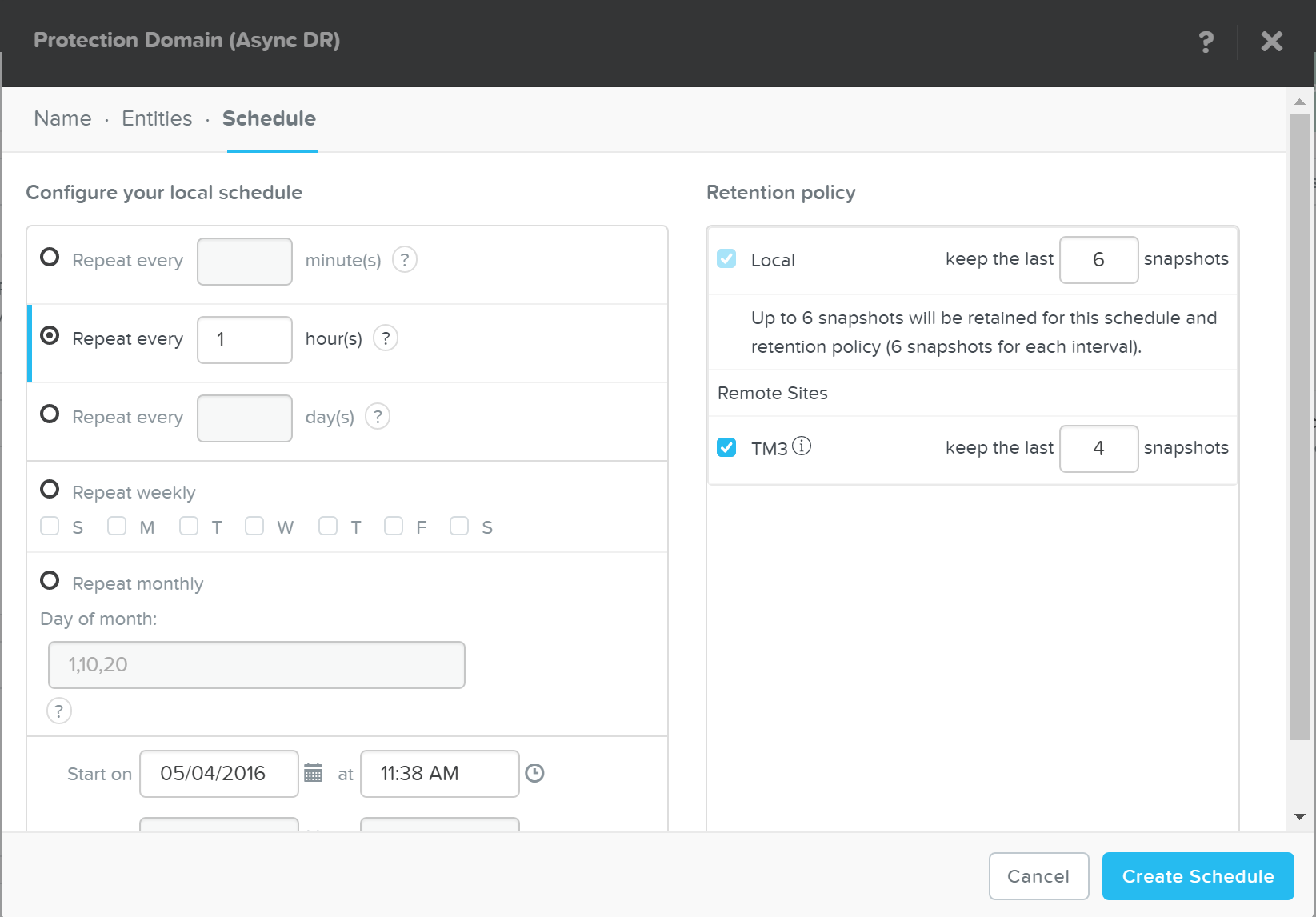
「Create Schedule(スケジュールを作成)」をクリックし、スケジュールを完成させます。
複数のスケジュール
スナップショットやレプリケーションスケジュールは、複数作成することができます。例えば、1時間おきにローカルバックアップを取得し、日次でリモートサイトに対してレプリケーションを行うといった対応が可能です。
単純化するために、コンテナ全体を保護対象にできる点に留意してください。ただし、プラットフォーム自体は、VMやファイルといった粒度での保護が可能です。
バックアップとリストア
Nutanixのバックアップ機能は、Cerebroによって起動されるネイティブなDSFスナップショット機能を使用してStargateが実行します。スナップショット機能は、ゼロコピー (zero copy) であり、ストレージを効率的に使用してオーバーヘッドを低減しています。スナップショットの詳細については、「スナップショットとクローン」のセクションをご覧ください。
通常のバックアップとリストア操作には、次のようなものがあります:
- スナップショット:ストアポイントとレプリケートを(必要に応じて)作成
- リストア: VMやファイルを以前のスナップショット状態に戻す(元のオブジェクトを置き換える)
- クローン: リストアに似ているが、元のオブジェクトは置き換えない(スナップショットから新しいオブジェクトを生成))
「エンティティの保護」セクションで作成した保護ドメイン (PD) は、Data Protection(データ保護)ページで確認することができます。

一旦、対象となるPDを選択すると、いくつかのオプションを選択することができます:

「Take Snapshot(スナップショットの取得)」をクリックすると、選択済みPDのスナップショットをアドホックに取得し、必要に応じてリモートサイトにレプリケートすることができます。
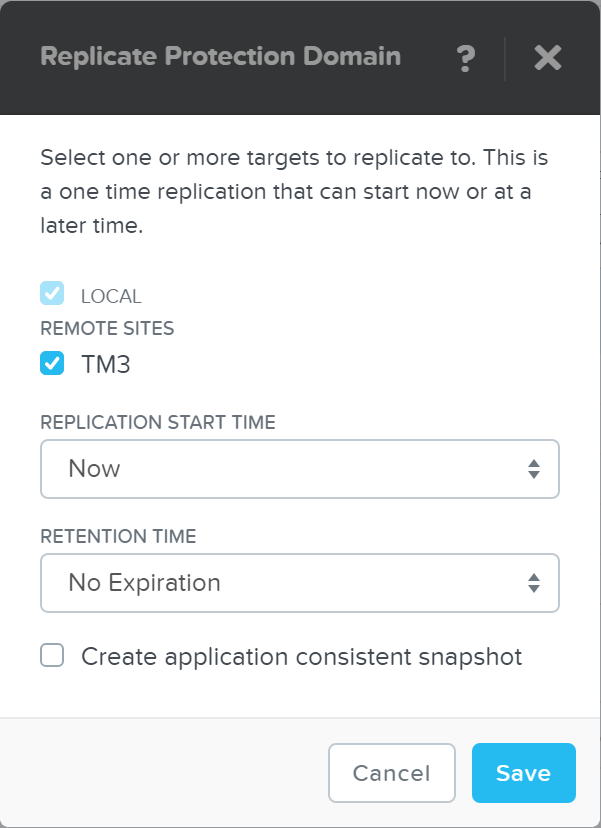
また、PDを「Migrate(移行)」して、リモートサイトにフェイルオーバーさせることも可能です:
移行(コントロール下にあるフェイルオーバー)が発生すると、システムは新しいスナップショットを作成してレプリケートし、新しいナップショットが作成されたことを他のサイトに通知します。
プロからのヒント
AOS 5.0以降は、単一ノードのレプリケーションターゲットを使用して、データを保護することができます。
PDのスナップショットについても以下の一覧で確認することができます:
ここからPDスナップショットをリストアまたはクローンすることもできます:
「Create new entities(新しくエンティティを作成)」を選択すると、指定したプリフィックスを持つ新しいエンティティにPDのスナップショットをクローンします。あるいは「Overwrite existing entities(既存エンティティに上書き)」を選択すると、現在のエンティティをスナップショット時にリプレースします。
ストレージ機能のみのバックアップターゲット
バックアップやアーカイブのみが目的であれば、バックアップ先として、ストレージ機能のみのNutanixクラスタをリモートサイトに構成することが可能です。 データは、ストレージ機能のみのクラスタへ(から)レプリケートすることができるようになります。
アプリケーション整合性スナップショット
NutanixのVmQuesced Snapshot Service (VSS) 機能によって、OSやアプリケーションの静止 (queiscing)操作を行い、アプリケーション整合性を保ったスナップショットを取得することができます。
VmQueisced Snapshot Service (VSS)
VSSと言えば、通常WindowsのVolume Shadow Copy Serviceを指します。 しかしこの機能は、WindowsとLinux双方に適用できるため、NutanixではVmQueisced Snapshot Serviceと呼んでいます。
サポート対象構成
本ソリューションは、WindowsとLinuxゲスト双方に対応します。 完全なサポート対象ゲストOSの一覧については、"Compatibility and Interoperability Matrix" にある "NGT Compatibility" をご覧ください: LINK
前提
Nutanix VSSスナップショットを使用するためには、以下が必要です:
-
Nutanixプラットフォーム
- クラスタ仮想IP (VIP) が設定されていること
-
ゲストOS / UVM
- NGTがインストールされていること
- CVM VIPにポート2074でアクセスできること
-
ディザスタリカバリ設定
- UVMが「Use application consistent snapshots(アプリケーション整合性スナップショットを使用)」が有効化された状態でPDにあること
バックアップのアーキテクチャー
AOS 4.6では、Nutanix Guest Toolsパッケージの一部としてインストールされる、ネイティブなNutanixハードウェアVSSプロバイダーを使用しています。
以下にVSSアーキテクチャー概要を示します:
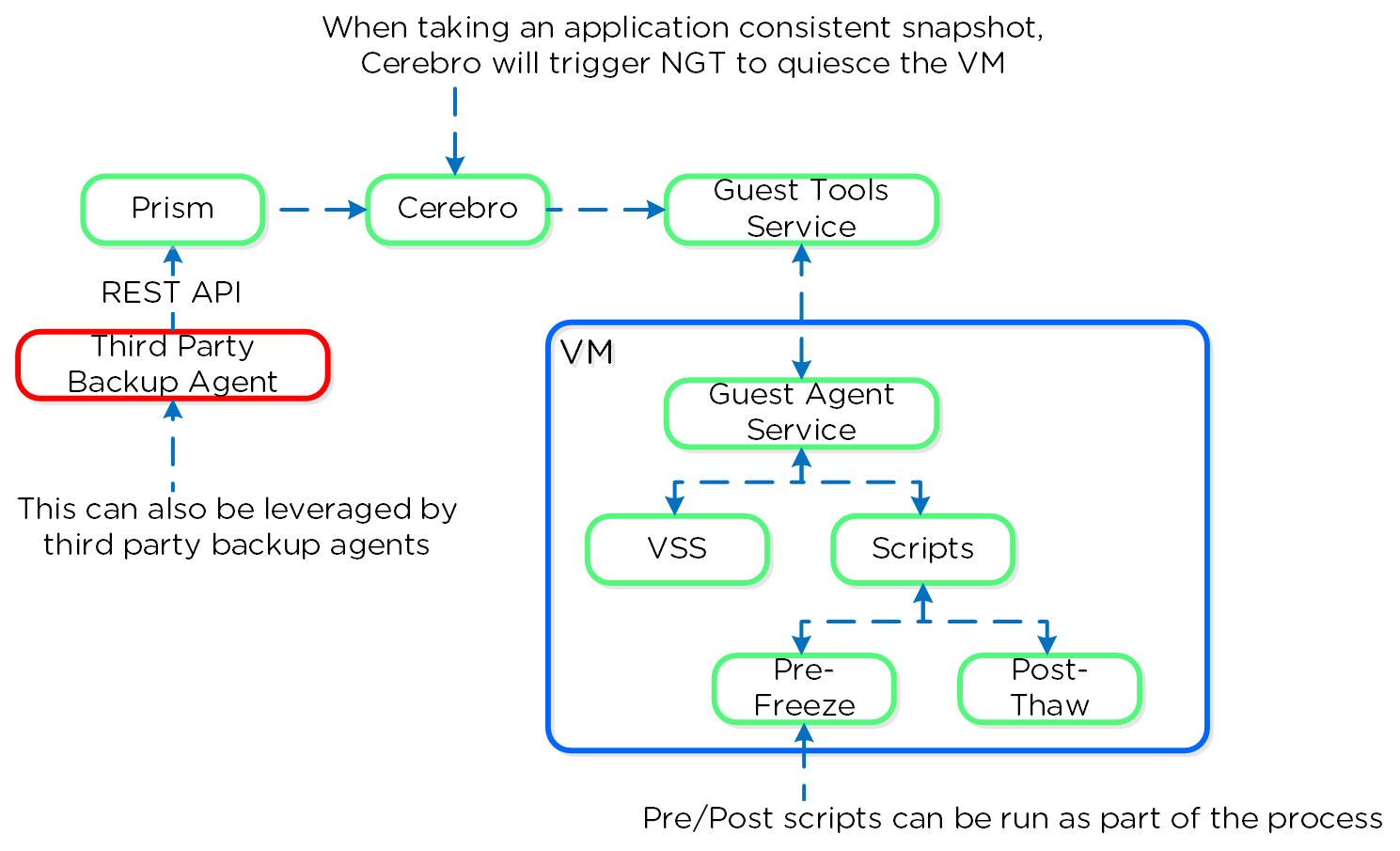
通常のデータ保護ワークフローを踏襲し、VMの保護において「Use application consistent snapshots(アプリケーション整合性スナップショットを使用)」を選択することで、 アプリケーション整合性のあるスナップショットを取得することができます。
Nutanix VSSの有効化、無効化
UVMのNGTが有効されていれば、Nutanix VSSスナップショット機能もデフォルトで有効化されています。しかし、本機能は、以下のコマンドで無効化することができます。
ncli ngt disable-applications application-names=vss_snapshot vm_id=<VM_ID>
Windows VSSアーキテクチャー
Nutanix VSSソリューションは、Windows VSSフレームワークと連携しています。下図にそのアーキテクチャー概要を示します:
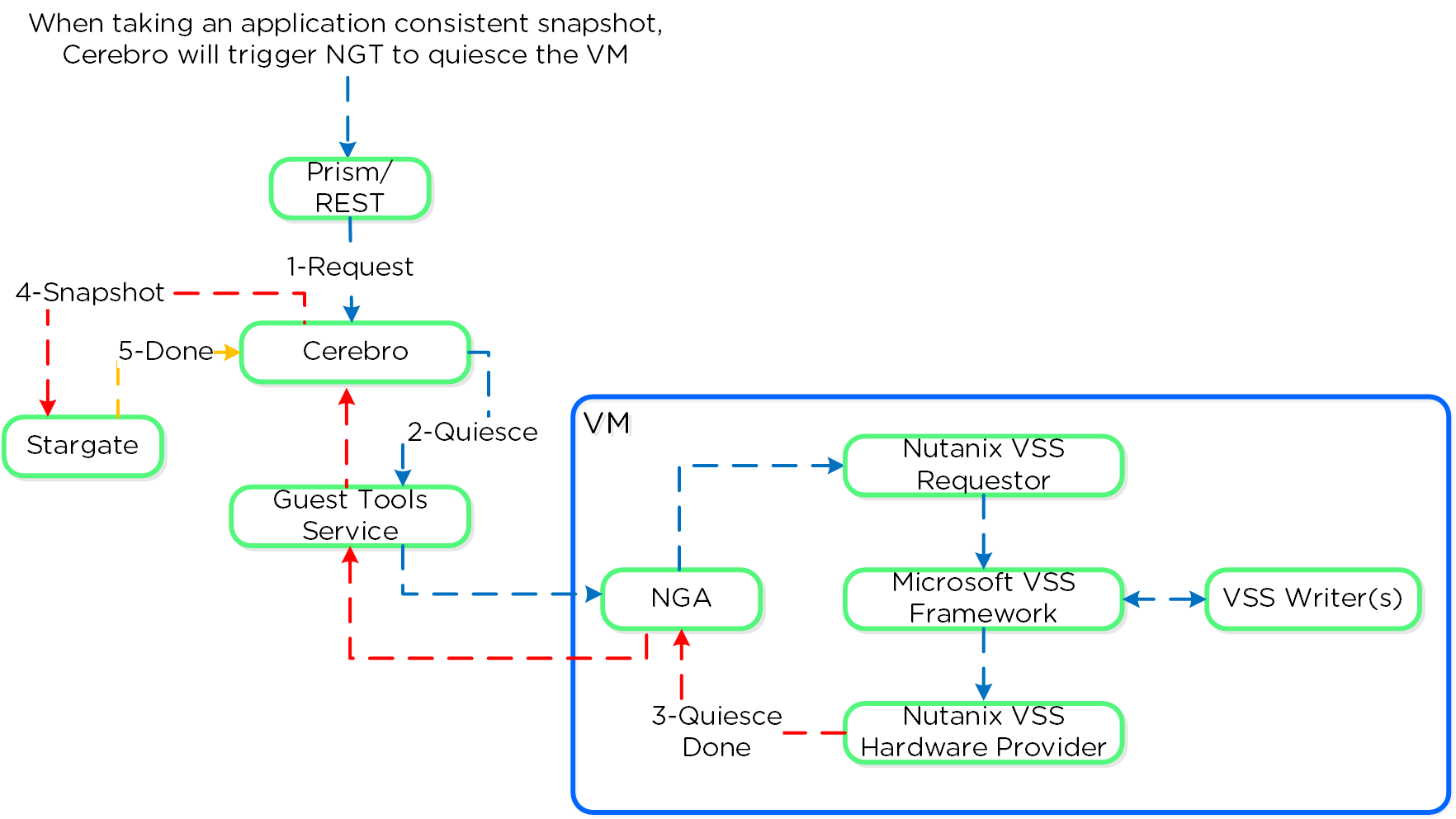
一旦、NGTがインストールされると、NGTエージェントとVSS Hardware Providerサービスを確認することができます:
Linux VSSアーキテクチャー
LinuxソリューションもWindowsソリューションに似ていますが、Linuxディストリビューションの場合には、Microsoft VSSフレームワークに該当するような機能が存在しないため、スクリプトを使用します。
以下にアーキテクチャー概要を示します:
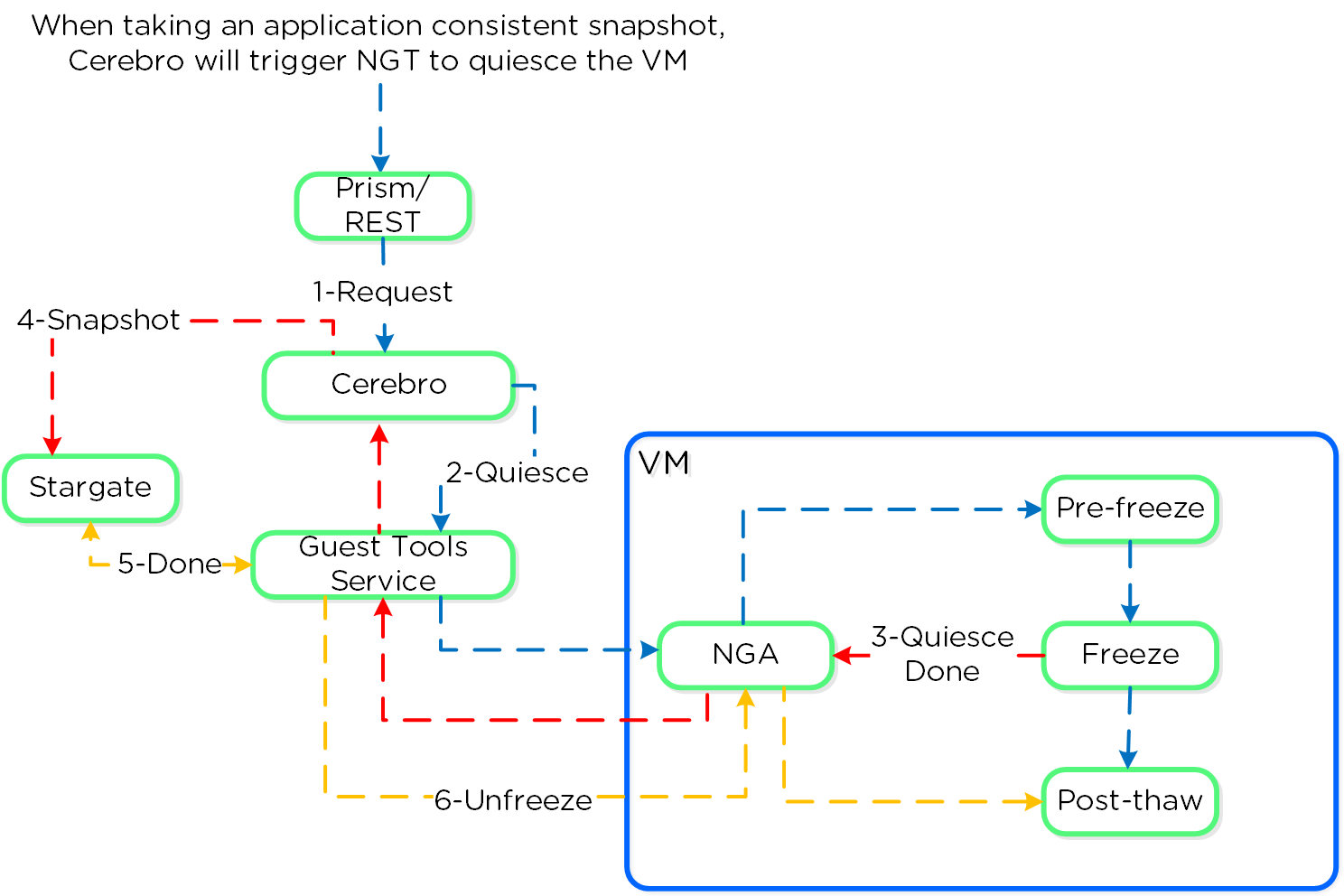
pre-freezeとpost-thawスクリプトは、以下のディレクトリにあります:
- Pre-freeze: /sbin/pre_freeze
- Post-thaw: /sbin/post-thaw
ESXiのスタンをなくす
ESXiでは、VMware Toolsを使用した、ネイティブなアプリケーション整合性スナップショットをサポートしています。 しかし、この処理の途中で差分ディスクが生成されるため、ESXiは、仮想ディスクを新規のWRITE I/Oを処理する新しい差分ファイルにマップするためにVMをスタン(stun:一時停止)させます。 このスタン状態は、VMwareスナップショットを削除した場合にも発生します。
VMがスタン状態の間、OSは一切の処理を行うことができず、基本的には「スタック」した状態(pingが通らない、I/O処理ができないなど)になります。 このスタンの長さは、vmdksの数とデータストア メタデータ処理(新規差分ディスクの作成など)の速さに依存します。
Nutanix VSSを使用することで、VMwareスナップショット / スタン処理を完全にバイパスし、VMやOSのパフォーマンスや可用性にほとんど影響を与えないようにすることができます。
レプリケーションとDR
ビデオによる解説はこちらからご覧いただけます:LINK
Nutanixでは、スナップショットおよびクローンのセクションで説明した機能をベースにしたネイティブなDRとレプリケーション機能を提供しています。 Cerebroは、DSFのDRとレプリケーション管理を担当するコンポーネントです。Cerebroは、全てのノードで稼動しますが、(NFSリーダー同様に)Cereboroリーダーが選択され、レプリケーション管理を担当します。 Cerebroリーダーに障害が発生し、CVMが代理で稼動している場合には、他のCerebroが選定され役割を引き継ぎます。 Cerebroのページは<CVM IP>:2020 にあります。 DRの機能は、以下に示すいくつかの主要な領域に分解することができます:
- レプリケーショントポロジー
- レプリケーションライフサイクル
- グローバル重複排除
レプリケーショントポロジー
以前から、サイト・ツー・サイト、ハブ・アンド・スポーク、フルまたは部分メッシュなど、レプリケーションのトポロジーはいくつか存在していました。 Nutanixでは、従来のサイト・ツー・サイトやハブ・アンド・スポークのみが可能なソリューションとは異なり、フルメッシュあるいは多対多モデルも提供しています。
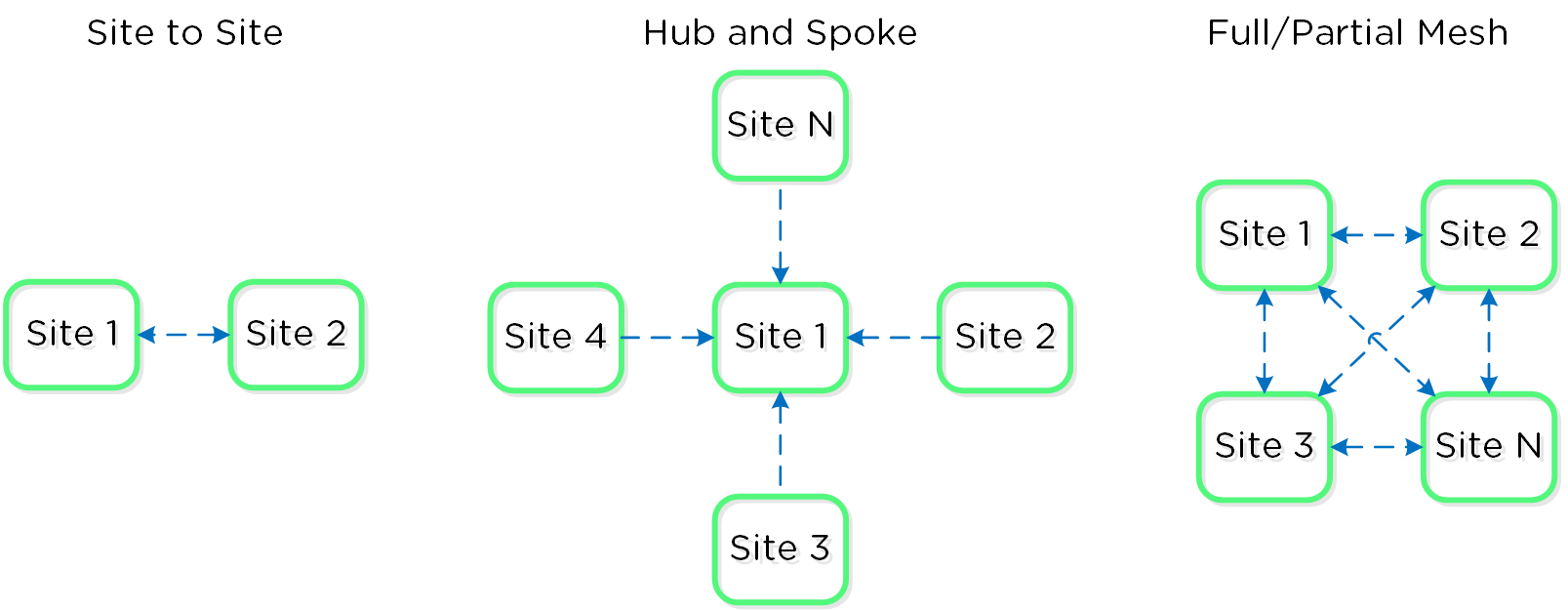
基本的に、企業のニーズに合わせたレプリケーション機能をシステム管理者が選択できるのです。
レプリケーションライフサイクル
前述の通り、Nutanixのレプリケーション機能はCerebroサービスを利用しています。Cerebroサービスは、動的に選定されるCVMである「Cerebroリーダー」と、各CVMで稼動するCerebroワーカーに分けられます。 「Celerbroリーダー」となったCVMに障害が発生した場合は、新しい「リーダー」が選定されます。
Cerebroリーダーは、ローカルにあるCerebroワーカーに対するタスク委譲管理を行い、リモートレプリケーションが発生した場合、リモートにある(複数の)Cerebroリーダーとのコーディネーションを行います。
レプリケーションが発生すると、Cerebroリーダーはレプリケーションの対象となるデータを特定し、レプリケーションタスクをCerebroワーカーに移譲し、Stargateにレプリケーションすべきデータとその場所を指示します。
レプリケーションされたデータは、プロセス全体の複数のレイヤー上で保護されます。 エクステントが読み込んだソースは、ソースデータの整合性を確保するよう(DSFの読み込み同様に)チェックサムが取られ、新しいエクステントについてもレプリケーション先で(DSFの書き込み同様)チェックサムが取られます。 ネットワークレイヤーの整合性はTCPで確認します。
以下に、このアーキテクチャーを図示します:
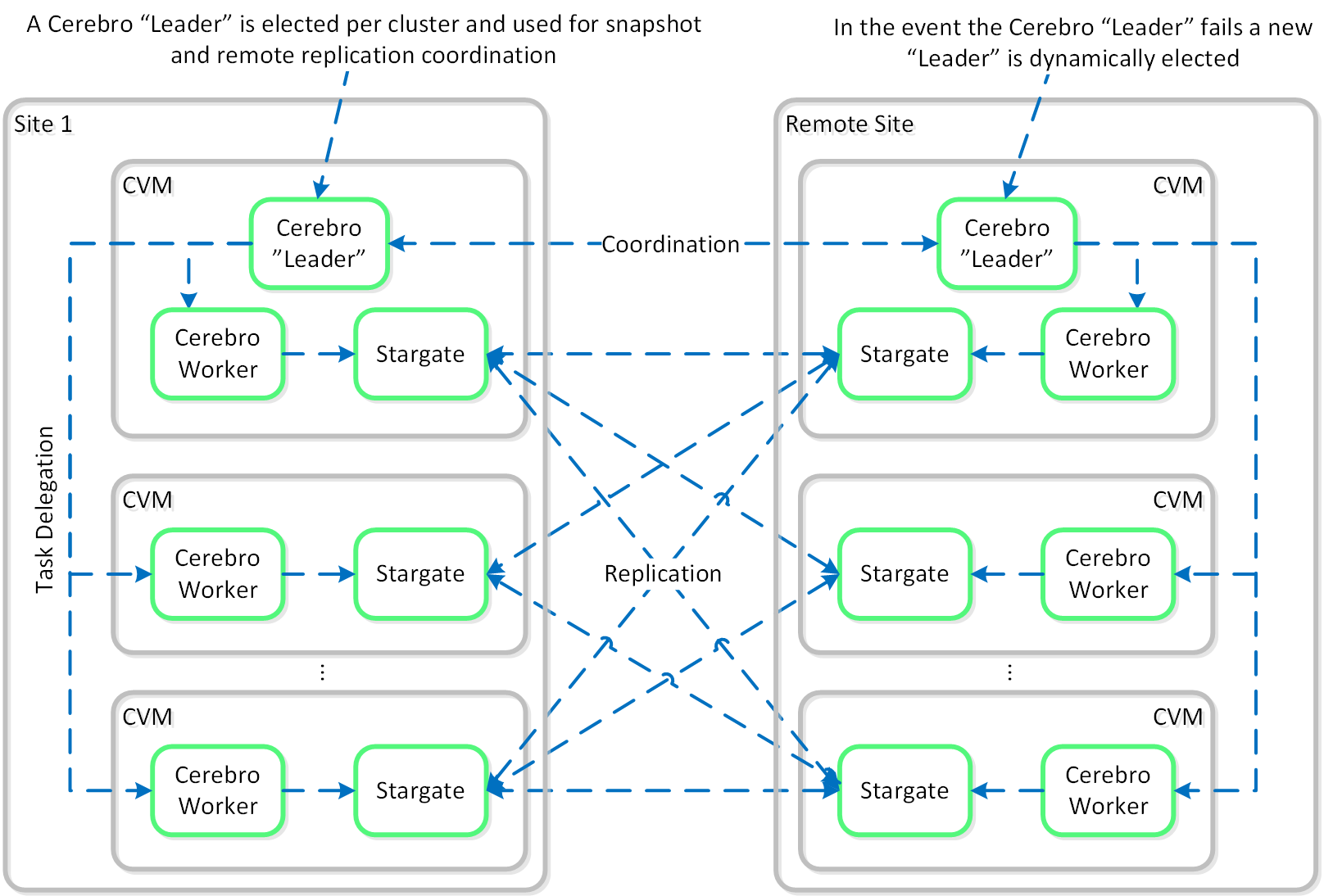
リモートサイトはプロキシを使って設定し、全てのコーディネーションやクラスタから到来するレプリケーショントラフィックの拠点として使用することもできます。
プロからのヒント
プロキシを利用してリモートサイトの設定を行う場合には、常にPrism Leaerにホストされ、CVMが停止した場合でも使用可能な状態にするため、必ずクラスタIPを使用するようにします。
以下に、プロキシを使用したレプリケーションアーキテクチャーを図示します:
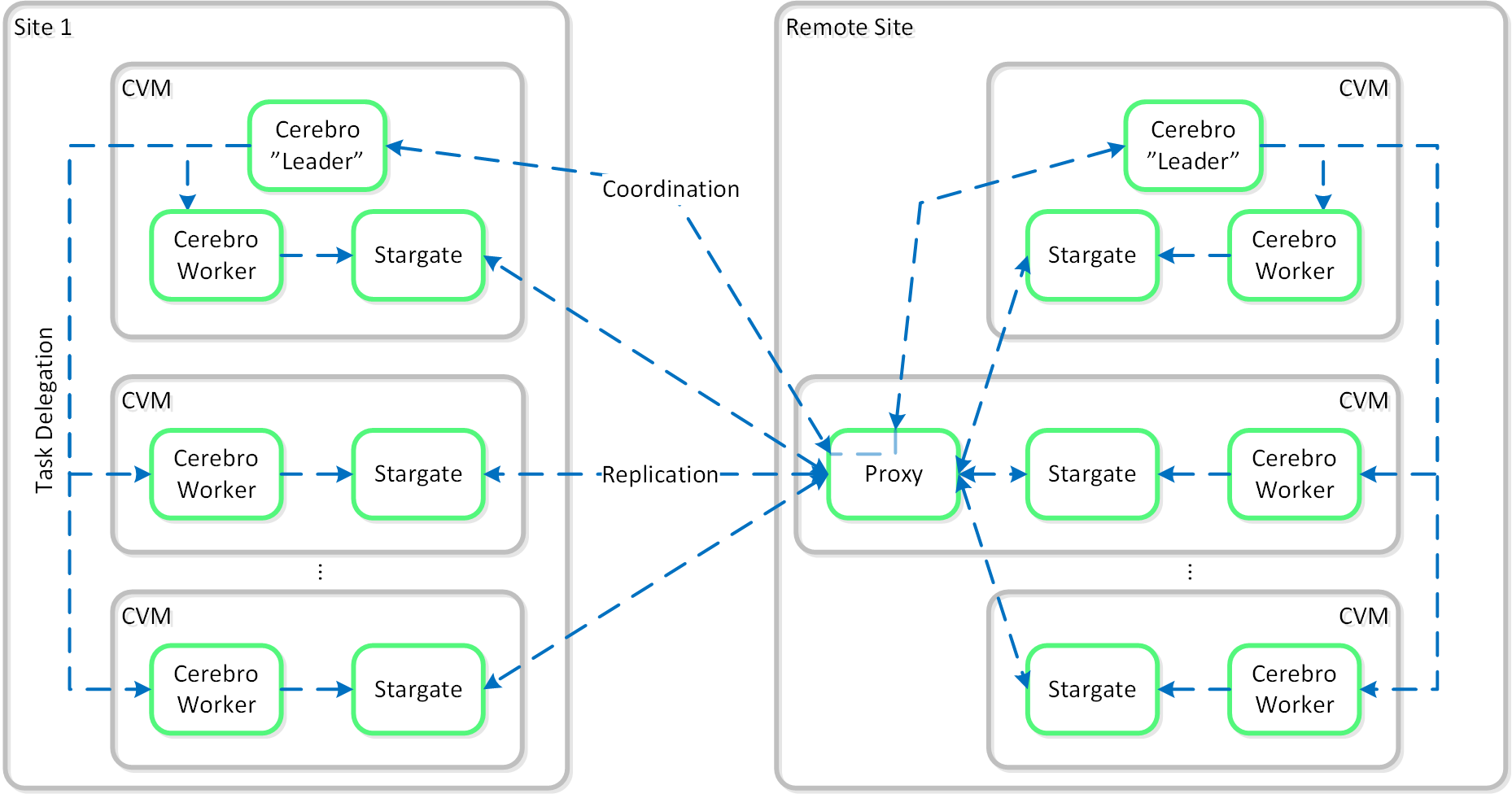
SSHトンネルを使用してリモートサイトを設定することも可能ですが、この場合トラフィックは、2つのCVM間を流れることになります。
注意
これは本番環境以外で使用するべきです。また、可用性を確保するためにクラスタIPを使用するようにします。以下に、SSHトンネルを使用したレプリケーションアーキテクチャーを図示します:
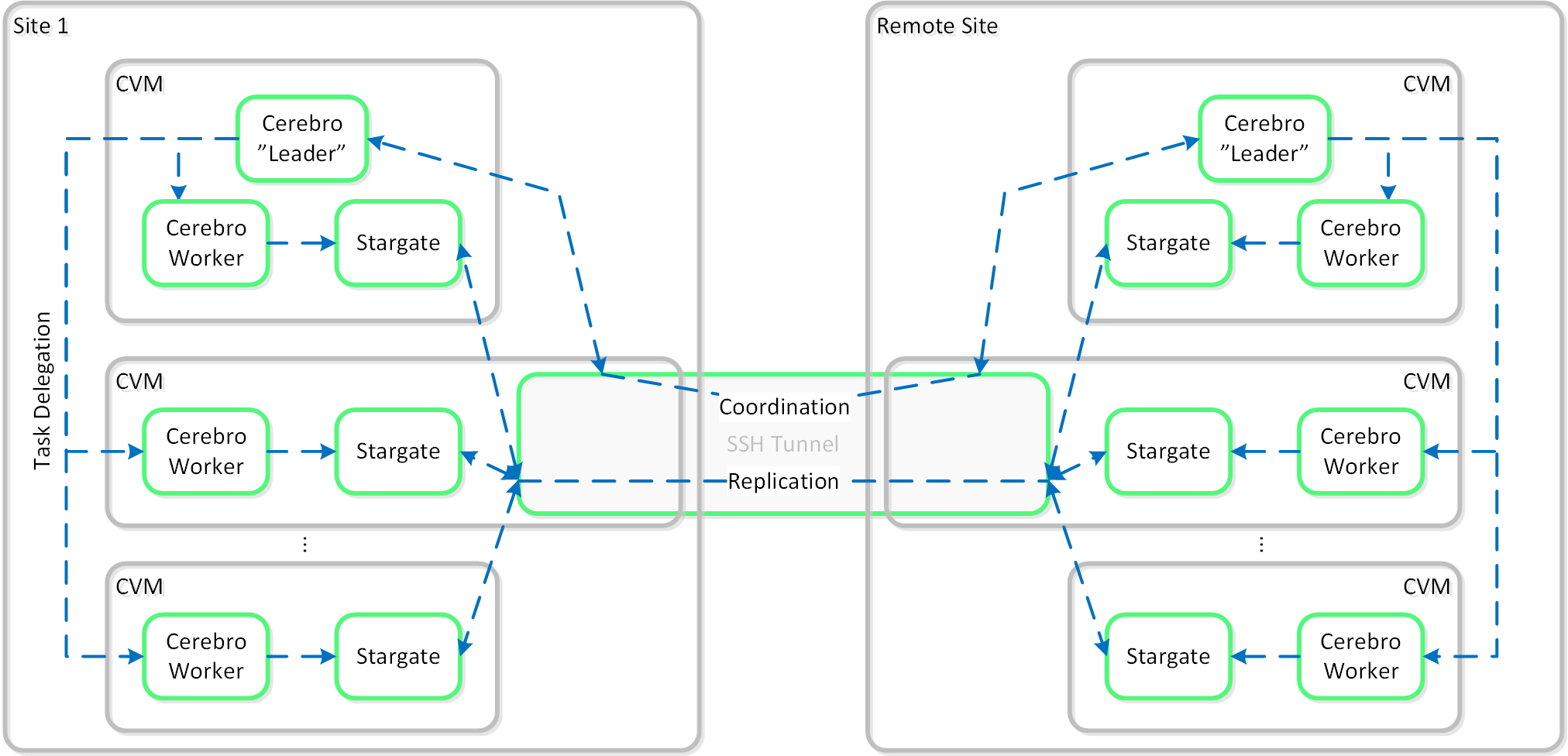
グローバル重複排除
Elastic Deduplication Engine(弾力的重複排除エンジン)のセクションで説明した通り、DSFではメタデータのポインタを更新するのみで重複排除ができるようになっています。 同じ考え方がDRとレプリケーション機能にも適用されます。DSFは回線越しにデータを送出する前にリモートサイトにクエリをかけ、ターゲットに既にフィンガープリントが存在しているかどうか(つまりデータが存在しているかどうか)を確認します。 存在している場合には、回線越しにデータを送出することなく、メタデータ更新のみが行われます。 ターゲットサイトにデータが存在しない場合には、該当データが圧縮されに送出されます。 この時点でデータは両方のサイトに存在することになり、重複排除の対象となり得ます。
以下は、1つ以上のプロテクションドメイン(PD)を有する3つのサイトからなる構成例を示しています:
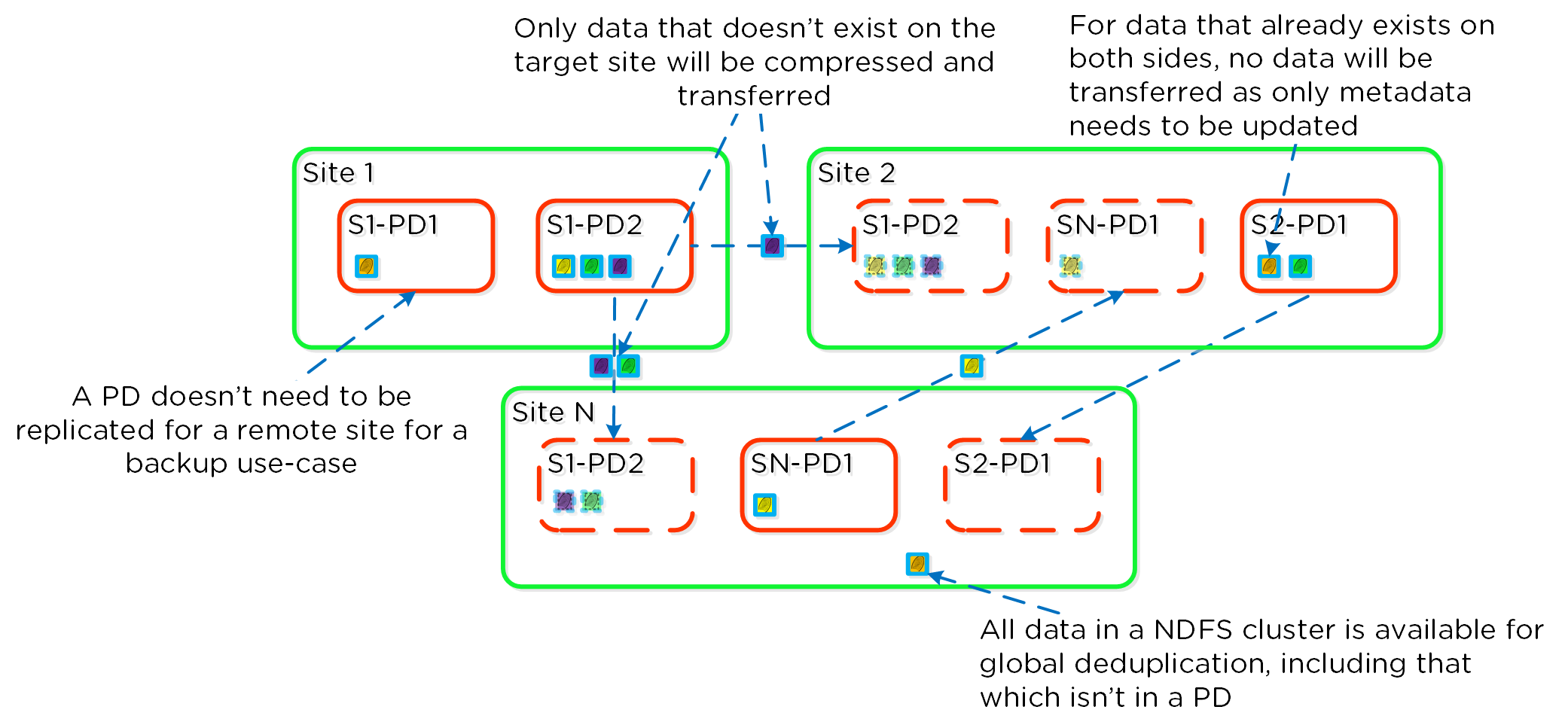
注意
レプリケーションの重複排除を可能にするためには、ソースおよびターゲットとなるコンテナおよびvstoreで、フィンガープリントが有効化されている必要があります。
NearSync
Nutanixでは、先に説明した従来の非同期(async)レプリケーション機能をベースにした、同期に近いレプリケーション(NearSync: Near Syncronous Replication)の提供をはじめました。
NearSyncは、プライマリI/Oのレイテンシーに(非同期レプリケーションのような)影響を与えないことに加え、(同期レプリケーション(Metro)のような)非常に短いRPOを実現することが可能です。 これによってユーザーは、通常、同期レプリケーションの書き込みに必要となるオーバーヘッドなしに、非常に短いRPOを実現することが可能になります。
この機能には、「ライトウェイトスナップショット (LWS: Light-Weight Snapshot)」と呼ばれるテクノロジーが使用されています。 非同期で使用する従来のvDiskベースのスナップショットとは異なり、NearSyncは、マーカーを使用した完全にOpLogベースの機能となっています(一方、vDiskのスナップショットはエクステントストアで行われます)。
Mesosは、スナップショット層の管理と、フル / 増分スナップショットにおける複雑性の排除を目的に追加された新しいサービスです。 ハイレベルな構造とポリシー(整合性グループなど)については引き続きCerebroが管理する一方で、MesosはStargateとのやり取りや、LWSのライフサイクルコントロール機能を受け持ちます。
NearSyncのコンポーネント間のやり取りの例を以下に示します:
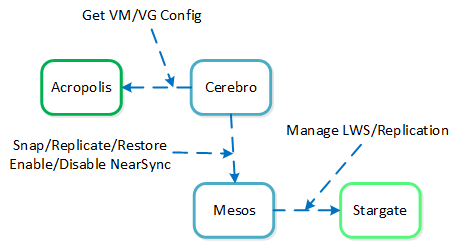
ユーザーがスナップショットの取得頻度を15分以下に設定すると、自動的にNearSyncが使用されます。この場合、初期のシードスナップショットが取得され、リモートサイトにレプリケーションされます。これが60分未満で完了すると、すぐに別のシードスナップショットが取得されてレプリケートされ、LWSスナップショットのレプリケーションが開始されます。2番目のシードスナップショットのレプリケーションが完了すると、既に存在する全てのLWSスナップショットが有効となり、システムは安定したNearSync状態となります。
以下に示す図は、NearSyncの有効化から実行までを時間の流れで追った例となります:
安定した状態にある間、vDiskのスナップショットは、1時間おきに取得されます。LSWとスナップショットを一緒にリモートサイトに送る代わりに、リモートサイトでは、以前のvDiskのスナップショットと、その時点以降のLWSを組み合わせてvDiskのスナップショットを生成します。
NearSyncの同期状態が崩れる(例えばネットワークの停止やWANの遅延など)と、LWSのレプリケーションに60分以上を要する状態となり、システムはvDiskベースのスナップショットに自動的に切り替えを行います。これらの内の1つが60分未満で完成すると、LWSのレプリケーションを開始する場合と同様に、システムは瞬時に他のスナップショットを取得します。一旦完全なスナップショットが完成すると、LWSスナップショットは有効となり、システムは安定したNearSyncの同期状態となります。このプロセスは、初期のNearSyncの有効化と同様の内容になります。
LWSベースのスナップショットがリストア(またはクローン)されると、システムは最新のvDiskのクローンを取得し、目的のスナップショットに達するまで、順次LWSを適用していきます。
以下の図は、LWSベースのスナップショットをリストアする方法を示しています:
Metro Availability
Nutanixは、ネイティブでサーバーやストレージクラスタを複数の物理サイトに拡張する「ストレッチクラスタ」機能を提供しています。これらの導入では、サーバークラスタは2つのロケーションにまたがる形でストレージの共有プールにアクセスします。
VM HAドメインは、単独のサイトから2つのサイトに拡張され、ニアゼロのRTOやゼロRPOを実現することができます。
この場合、各サイトにはそれぞれNutanixクラスタが存在することになりますが、コンテナはWRITE処理の完了確認前に同期される形でレプリケートされ、リモートサイトに「ストレッチ」されます。
以下に、本アーキテクチャーのデザイン概要を図示します:
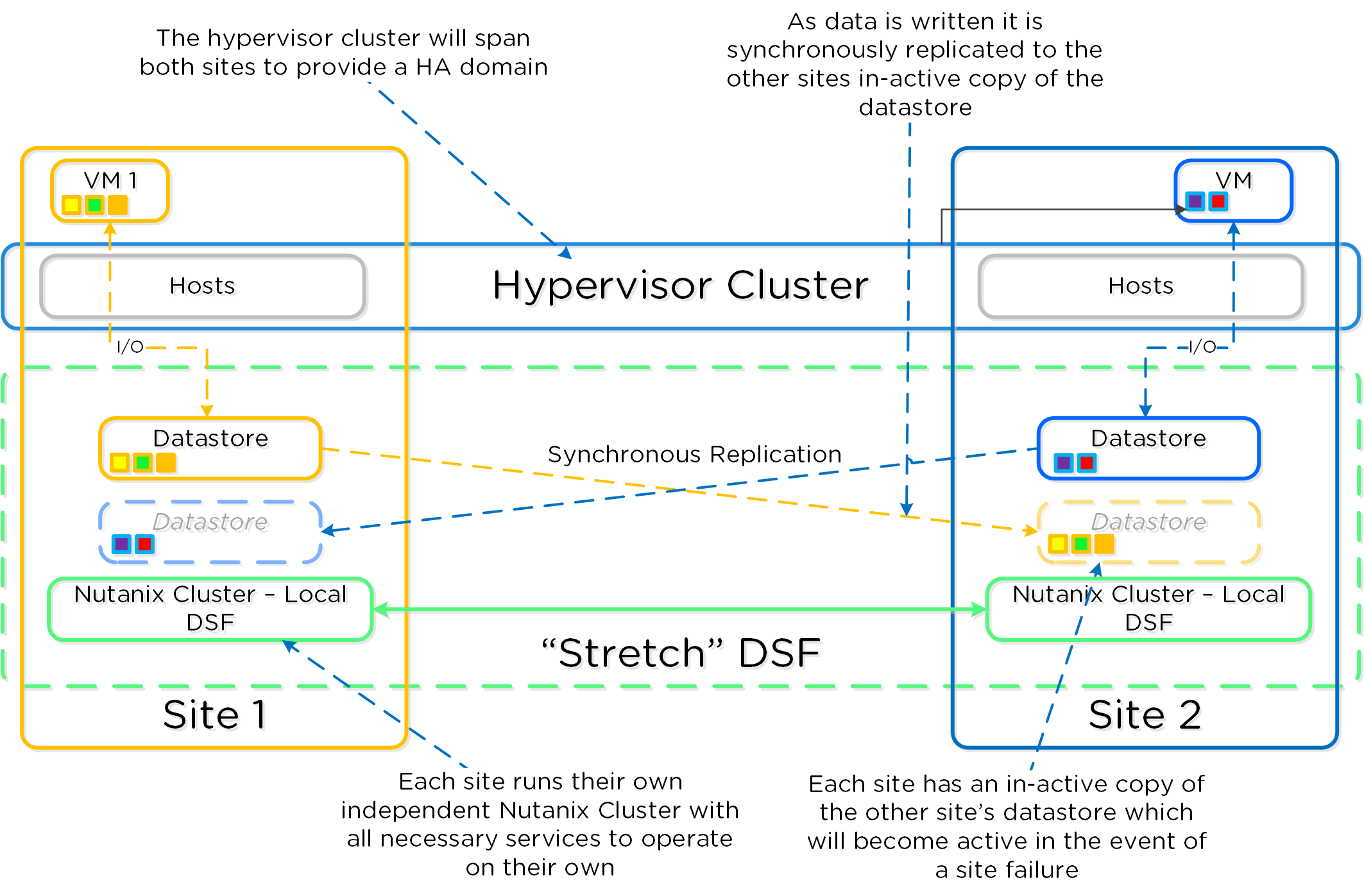
サイトに障害が発生した場合、HAイベントを発行し、別のサイトでVMを再起動することが可能です。 通常、フェイルオーバー処理は手動での対応となります。 しかしAOS 5.0でリリースされたMetro Witnessの場合には、フェイルオーバーの自動化設定が可能です。 WitnessはポータルからダウンロードしてPrismを使って設定することができます。
以下に、サイト障害発生時の例を図示します:
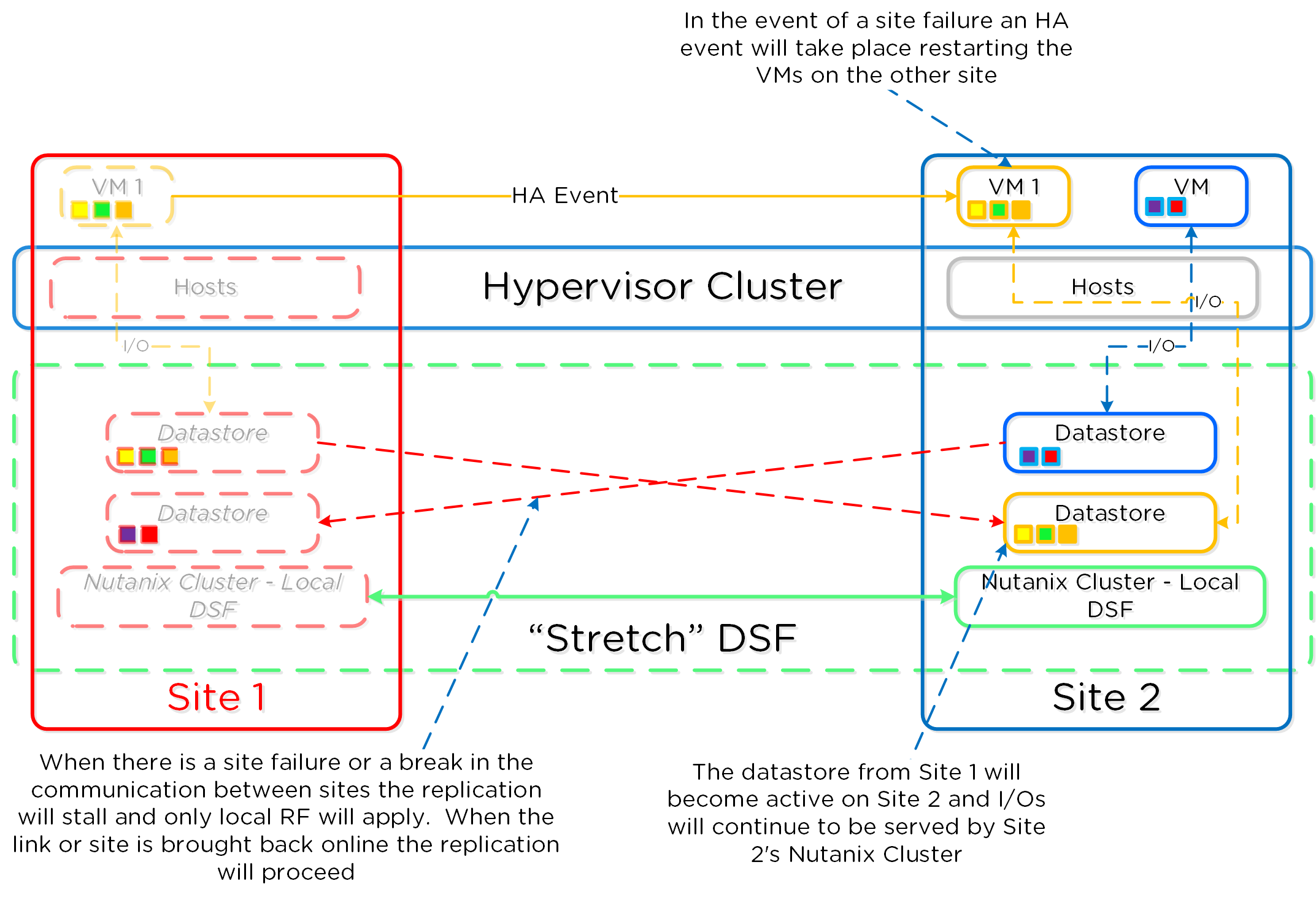
2つのサイト間のリンクに障害が発生した場合、各クラスタはそれぞれ独立して運用されます。リンクが回復した時点で、両サイトで再同期が図られ(差分のみ)、同期レプリケーションが再開されます。
以下に、リンク障害発生時の例を図示します:
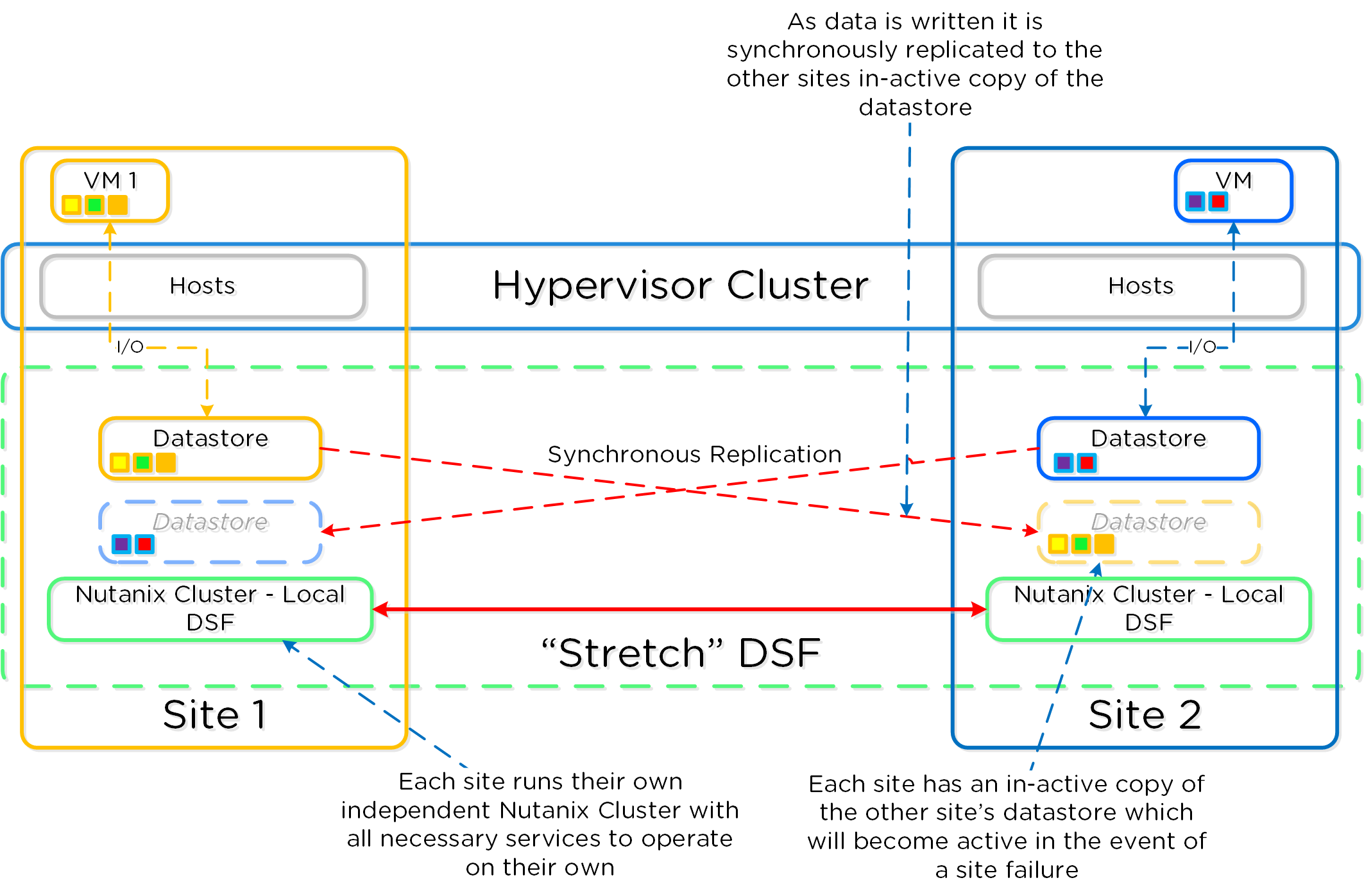
AOSのアドミニストレーション
AOSの重要なページ
一般的なユーザーインターフェイスに加え、高度なNutanixページを参照して、詳細なステータスや指標をモニターすることができます。 URLは、http://<Nutanix CVM IP/DNS>:<Port/path(以下に説明)> という形式になります。
例: http://MyCVM-A:2009
注意: 異なるサブネットを使用している場合、ページにアクセスするためにはiptablesをCVMで無効化する必要があります。
2009 ページ
バックエンド ストレージ システムをモニターするためのページであり、上級ユーザー向けとなります。 2009ページの説明や内容について別途投稿があります。
2009/latency ページ
バックエンドのレイテンシーをモニターするためのStargateのページです。
2009/vdisk_stats ページ
I/Oサイズやレイテンシー、WRITEヒット(OpLog、eStoreなど)、READヒット(キャッシュ、SSD、HDDなど)その他のヒストグラムを含む、様々なvDiskステータスを提示する、Stargateのページです。
2009/h/traces ページ
オペレーション状況をトレースしモニターするための、Stargateのページです。
2009/h/vars ページ
各種カウンターをモニターするためのStargateのページです。
2010 ページ
Curatorの稼動状況をモニターするためのCuratorのページです。
2010/master/control ページ
Curatorジョブをマニュアルで起動するための、Curatorコントロールのページです。
2011 ページ
Curatorによってスケジューリングされたジョブやタスクをモニターするための、Chronosのページです。
2020 ページ
プロテクションドメイン、レプリケーションのステータス、DRをモニターするための、Cerebroのページです。
2020/h/traces ページ
PD処理やレプリケーション状況をトレースしモニターするための、Cerebroのページです。
2030 ページ
Acropolisのメインとなるページで、環境内のホスト、稼動中のタスク、ネットワークなどの詳細を提示します。
2030/sched ページ
VMやリソース配分の計画に必要な情報を提示するAcropolisのページです。このページには、利用可能なホストのリソースと各ホストで稼動するVMが表示されます。
2030/tasks ページ
Acropolisのタスクとステータスに関する情報を提示するAcropolisのページです。タスクのUUIDをクリックすると、タスクに関するJSONの詳細情報が表示されます。
2030/vms ページ
AcropolisのVMとその詳細情報を提示するAcropolisのページです。VM名 (VM Name) をクリックすると、コンソールに接続されます。
クラスタコマンド
クラスタのステータスを確認
説明: CLIからクラスタのステータスを確認
cluster status
ローカルCVMサービスのステータスを確認
説明: CLIから特定のCVMサービスのステータスを確認
genesis status
アップグレードのステータスを確認
upgrade_status
手動のCLIアップグレードを実行
- <NUTANIX INSTALLER PACKAGE>.tar.gzを~/tmpにダウンロード
cd ~/tmp
tar xzf <NUTANIX INSTALLER PACKAGE>.tar.gz
./install/bin/cluster -i ./install upgrade
ノードアップグレード
ハイパーバイザーのアップグレードステータス
説明: CVMのCLIから、ハイパーバイザーのアップグレードステータスを確認
host_upgrade_status
詳細ログ(各CVM上)
~/data/logs/host_upgrade.out
CLIからクラスタサービスを再起動
説明: CLIから特定のクラスタサービスを再起動
サービスを停止
cluster stop <Service Name>
停止したサービスを起動
cluster start #NOTE: This will start all stopped services
CLIからクラスタサービスを起動
説明: CLIから停止したクラスタサービスを起動
停止したサービスを起動(注意: 全ての停止サービスが起動されます)
cluster start #NOTE: This will start all stopped services
または
特定のサービスを起動
cluster start <Service Name>
CLIからローカルサービスを再起動
説明: CLIから特定のクラスタサービスを再起動
サービスを停止
genesis stop <Service Name>
サービスを起動
cluster start
CLIからローカルサービスを起動
説明: CLIから停止したクラスタサービスを起動
cluster start #NOTE: This will start all stopped services
CLIでクラスタにノードを追加
説明: CLIからクラスタにノードを追加
ncli cluster discover-nodes | egrep "Uuid" | awk '{print $4}' | xargs -I UUID ncli cluster add-node node-uuid=UUID
クラスタIDを調査
説明: 現在のクラスタの、クラスタIDを調査
zeus_config_printer | grep cluster_id
ポートのオープン
説明: iptablesでポートを有効化
sudo vi /etc/sysconfig/iptables
-A INPUT -m state --state NEW -m tcp -p tcp --dport <PORT> -j ACCEPT
sudo service iptables restart
シャドウ クローンの確認
説明: シャドウ クローンを次の形式で表示: name#id@svm_id
vdisk_config_printer | grep '#'
レイテンシーページのステータスを初期化
説明: レイテンシーページ (
allssh "wget $i:2009/latency/reset"
vDisk情報を調査
説明: vDiskの情報や名前、ID、サイズ、IQNとして他を含む詳細を調査
vdisk_config_printer
vDiskの数を調査
説明: DSF上のvDisk(ファイル)の数を調査
vdisk_config_printer | grep vdisk_id | wc -l
vDiskの詳細情報の確認
説明: 指定したvDiskのegroup ID、サイズ、変換とセービング、ガベージ、レプリカ配置を表示
vdisk_usage_printer -vdisk_id=<VDISK_ID>
CLIからCuratorスキャンを起動
説明: CLIからCuratorフルスキャンを起動
フルスキャン
allssh "wget -O - "http://localhost:2010/master/api/client/StartCuratorTasks?task_type=2";"
部分的なスキャン
allssh "wget -O - "http://localhost:2010/master/api/client/StartCuratorTasks?task_type=3";"
使用量の更新
allssh "wget -O - "http://localhost:2010/master/api/client/RefreshStats";"
CLIからレプリケーション中のデータの確認
説明: curator_idでレプリケーション中のデータを確認
curator_cli get_under_replication_info summary=true
リングを圧縮
説明:メタデータリングを圧縮
allssh "nodetool -h localhost compact"
AOSのバージョンを調査
説明: AOSのバージョンを調査(注意: nCLIを使うことも可能)
allssh "cat /etc/nutanix/release_version"
CVMのバージョンを調査
説明: CVMのイメージのバージョンを調査
allssh "cat /etc/nutanix/svm-version"
vDiskをマニュアルでフィンガープリント
説明: (重複解除向けに) 特定のvDiskのフィンガープリントを作成。注意:コンテナの重複排除が有効になっている必要があります。
vdisk_manipulator -vdisk_id=<vDisk ID> --operation=add_fingerprints
全てのvDiskをマニュアルでフィンガープリント
説明:(重複排除向けに)全てのvDiskのフィンガープリントを作成。注意:コンテナの重複排除が有効になっている必要があります。
for vdisk in `vdisk_config_printer | grep vdisk_id | awk {'print $2'}`; do vdisk_manipulator -vdisk_id=$vdisk --operation=add_fingerprints; done
全てのクラスタノードに対しFactory_Config.json をエコー
説明: 全てのクラスタノードに対しFactory_Config.json をエコー
allssh "cat /etc/nutanix/factory_config.json"
特定のNutanixノードのAOSバージョンをアップグレード
説明: 特定のノードのAOSバージョンとクラスタに整合ようにアップグレード
~/cluster/bin/cluster -u <NEW_NODE_IP> upgrade_node
DSFのファイル(vDisk)一覧
説明: ファイルとDSFにストアされているvDiskに関する情報一覧を表示
nfs_ls
ヘルプテキストの出力
nfs_ls --help
Nutanix Cluster Check (NCC) のインストール
説明: 潜在的問題やクラスタのヘルスをテストするためのヘルススクリプト、Nutanix Cluster Check (NCC) をインストール
- NCCをNutanixサポートポータル(portal.nutanix.com)からダウンロード
- SCPで.tar.gzを/home/nutanixディレクトリに転送する
- NCC .tar.gz を展開(untar)する
tar xzmf <ncc .tar.gz file name> --recursive-unlink
インストールスクリプトの実行
./ncc/bin/install.sh -f <ncc .tar.gz file name>
リンクを作成
source ~/ncc/ncc_completion.bash
echo "source ~/ncc/ncc_completion.bash" >> ~/.bashrc
Nutanix Cluster Check(NCC)の実行
説明:潜在的問題やクラスタのヘルスをテストするためのヘルススクリプト、Nutanix Cluster Check (NCC) を実行。 クラスタに問題が発見された場合のトラブルシューティングとして、最初に実行すべきことです。
- NCCがインストールされていることを確認(前述の手順)
NCCヘルスチェックを実行
ncc health_checks run_all
「progress monitor cli」を使用したタスク一覧の作成
progress_monitor_cli -fetchall
「progress monitor cli」を使用したタスクの削除
progress_monitor_cli --entity_id=<ENTITY_ID> --operation=<OPERATION> --entity_type=<ENTITY_TYPE> --delete
注意: operationとentity_typeは、先頭にある小文字のkをすべて削除する必要があります。
AOSの指標値としきい値
以下のセクションでは、Nutanixバックエンドに対する特定の指標や、しきい値について説明します。この内容は今後も適時更新します!
Gflags
近日公開!
AOSのトラブルシューティングと高度な管理
Acropolisのログを調査
説明: クラスタのAcropolisのログを調査
allssh "cat ~/data/logs/Acropolis.log"
クラスタのエラーログを調査
説明: クラスタのERRORログを調査
allssh "cat ~/data/logs/<COMPONENT NAME or *>.ERROR"
Stargateの例
allssh "cat ~/data/logs/Stargate.ERROR"
クラスタのFATALログの調査
説明: クラスタのFATALログを調査
allssh "cat ~/data/logs/<COMPONENT NAME or *>.FATAL"
Stargateの例
allssh "cat ~/data/logs/Stargate.FATAL"
2009ページの利用 (Stargate)
ほとんどの場合、必要な情報やデータはPrismを使って得ることができます。 しかし、より詳細な情報を入手したいような場合は、Stargate(または2009ページと呼ばれる)を使用することができます。 2009ページは、<CVM IP>:2009 で見ることができます。
バックエンドページへのアクセス
異なるネットワークセグメント(L2サブネット)にいる場合、バックエンドページにアクセスするためには、IPテーブルにルールを追加する必要があります。
ページの最上部には、クラスタに関する様々な細部に関する概要が表示されます。

このセクションには、2つの重要な部分が含まれています。1つ目はI/Oキューで、これは処理待ちまたは未処理のI/O数を表します。
以下は、概要セクションのQueueに関する部分です:

2つめは、コンテンツキャッシュのキャッシュサイズとヒット率に関する情報を表示する部分です。
以下は、概要セクションのコンテンツキャッシュに関する部分です:

プロからのヒント
理想的には、ワークロードがREAD中心型で、最大のREADパフォーマンスを発揮した場合、ヒット率は80~90%を超えるものになります。
注意: 以上は、Stargate / CVM あたりの数値です。
次は「クラスタステータス」に関するセクションで、クラスタ内のStargateとそのディスク使用状況に関する詳細を表示しています。
以下は、Stargateとディスク使用状況(利用可能/合計)を図示したものです:
次のは「NFSワーカー」に関するセクションで、vDisk単位で様々な詳細やステータスを表示しています。
以下は、vDiskとI/Oの詳細を図示したものです:
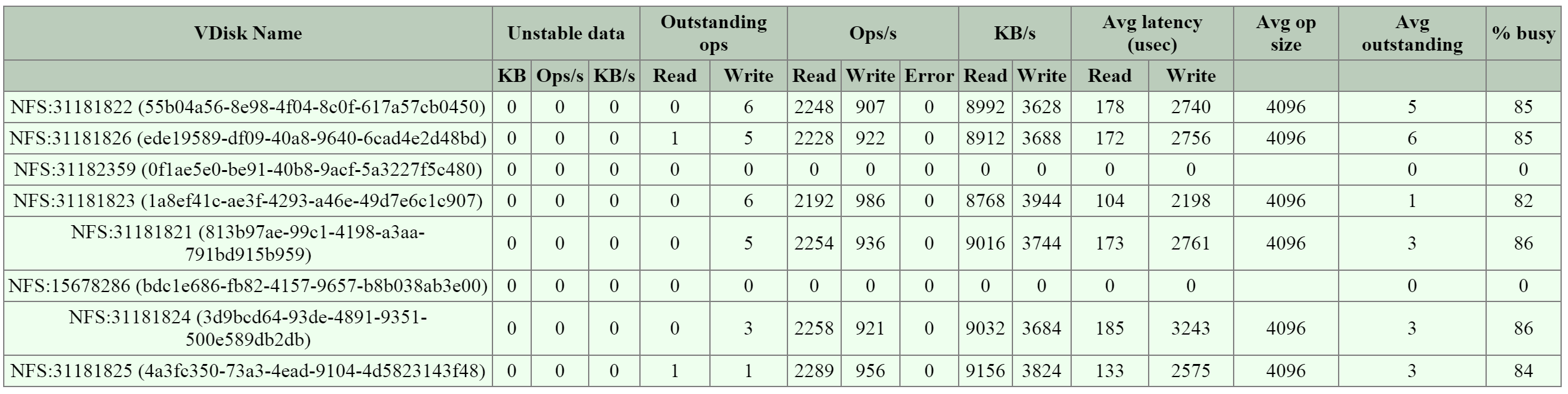
プロからのヒント
潜在的なパフォーマンスに関する問題を調査する場合、以下のメトリックを確認する必要があります:
- 平均レイテンシー(Avg. latency)
- 平均オペレーションサイズ(Avg. op size)
- 平均処理待ち数(Avg. outstanding)
より詳細な情報が、vdisk_stats ページに多数含まれています。
2009/vdisk_stats ページの利用
2009 vdisk_statsページは、vDiskに関するより詳細なデータを提供するためのページです。このページにはランダムネス、レイテンシーヒストグラム、I/Oサイズ、ワーキングセットの詳細などが含まれています。
左の列にある「vDisk Id」をクリックするとvDisk_statsページに移ります。
以下は、セクションとvDisk IDのハイパーリンクを示しています:
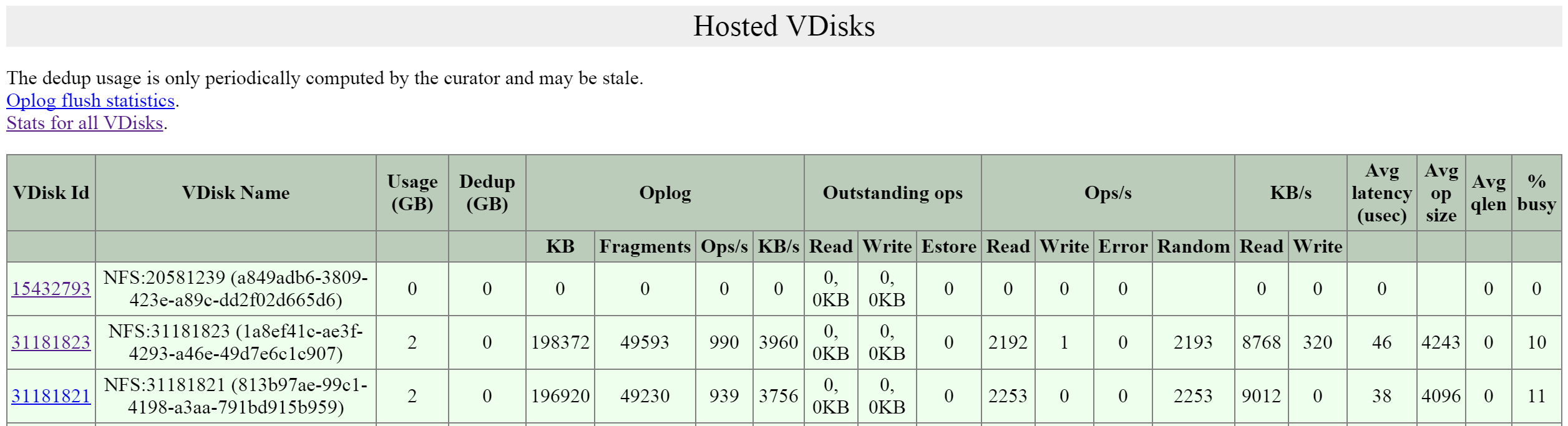
vdisk_statsページに移ると、vDiskのステータス詳細が表示されます。注意: 表示されている値はリアルタイムなもので、ページをリフレッシュすることで更新することができます。
まず重要なセクションは、「オペレーションとランダムネス (Ops and Randomness)」で、I/Oパターンをランダムなものとシーケンシャルなものに分解しています。
以下は、「オペレーションとランダムネス (Ops and Randomness)」セクションを図示したものです:
次の部分には、フロントエンドのREADおよびWRITE I/Oのレイテンシー(あるいはVM/OSから見たレイテンシー)のヒストグラムが表示されています。
以下が、「フロントエンドREADレイテンシー」のヒストグラムになります:

以下が、「フロントエンドWRITEレイテンシー」のヒストグラムになります:
次の重要な領域は、I/Oサイズの分散で、READとWRITEのI/Oサイズのヒストグラムを表示しています。
以下が、「READサイズの分散」のヒストグラムになります:
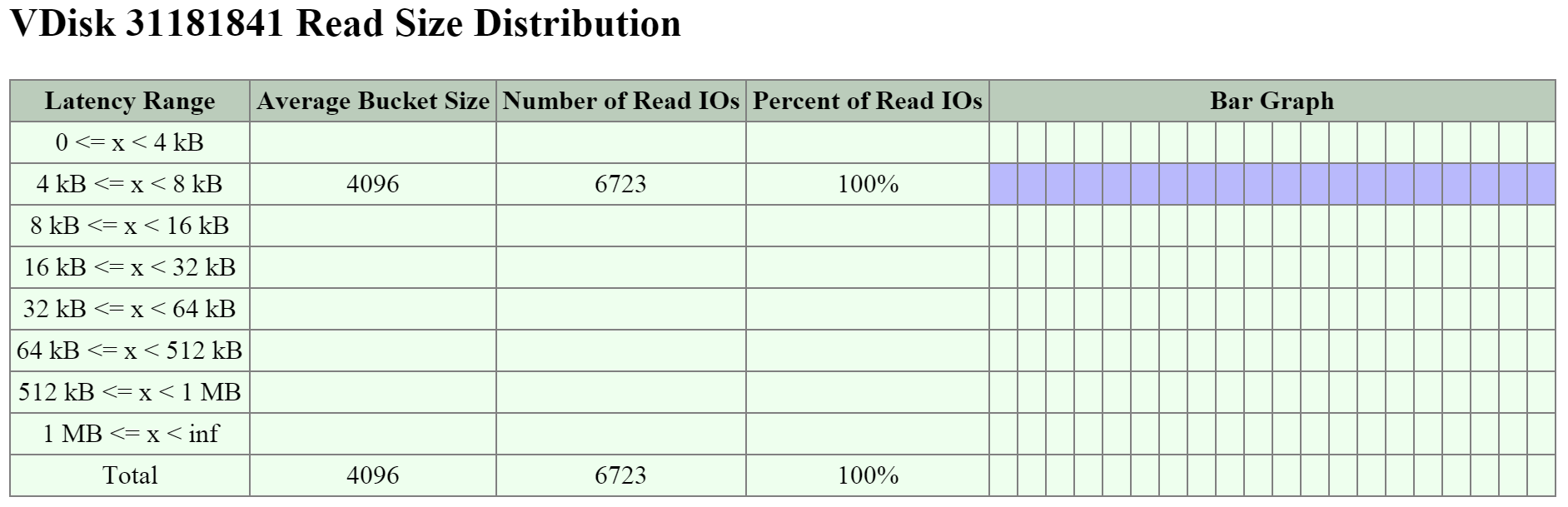
以下が、「WRITEサイズの分散」のヒストグラムになります:
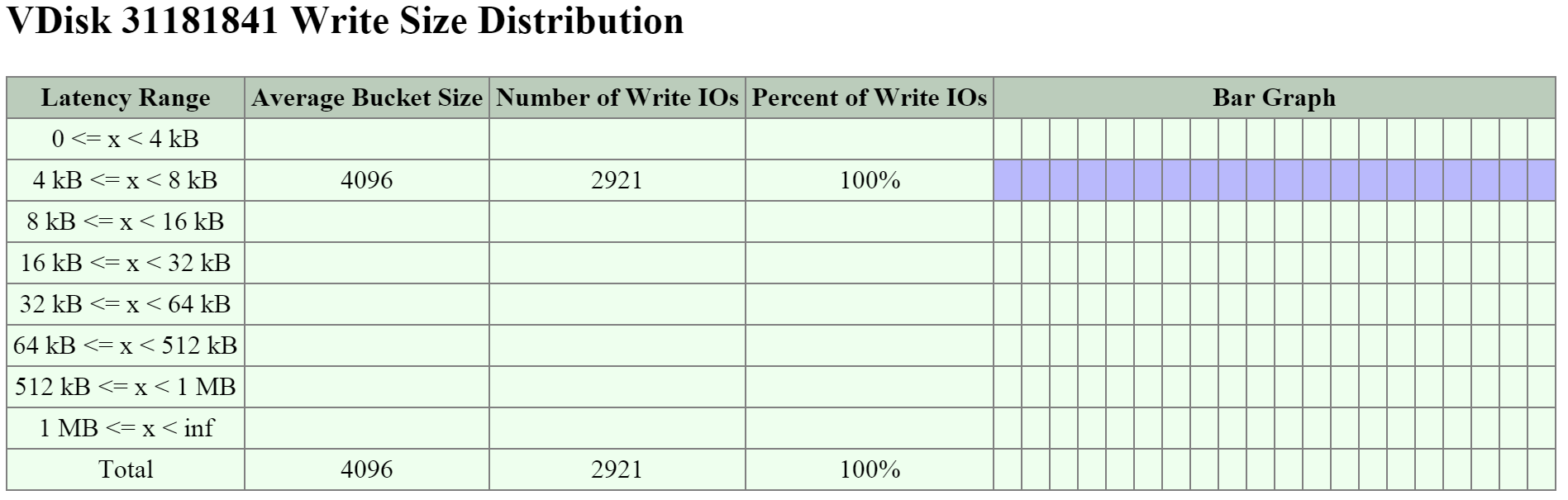
次の重要な領域は、「ワーキングセットサイズ」で、直近2分間と1時間におけるワーキングセットサイズに関する情報を提供しています。内容は、READとWRITE I/Oに分けられています。
以下が、「ワーキングセットサイズ」テーブルになります:

「READソース (Read Source)」は、READ I/Oに対する処理が行われた階層またはロケーションの詳細を示します。
以下が、「READソース (Read Source)」詳細になります:

プロからのヒント
READに高いレイテンシーが見られる場合、vDiskのREADソースを見て、I/O処理がどこで行われているかを確認します。 ほとんどの場合、READがHDD(Estore HDD)で処理されることでレイテンシーが高くなります。
「WRITE先 (Write Destination)」は、新規WRITE I/Oがどこに対して行われるかを示します。
以下が、「WRITE先 (Write Destination)」一覧になります:

プロからのヒント
ランダムまたは小規模なI/O (<64K) は、OpLogに書き込まれます。大規模あるいはシーケンシャルなI/OはOpLogをバイパスし、エクステントストア (Estore)に直接書き込まれます。
データの、HDDからSSDへの上層移動がILMによって行われます。 「エクステントグループ上層移動(Extent Group Up-Migration)」一覧は、直近300、3,600、86,400秒に上層移動したデータを示しています。
以下が、エクステントグループ上層移動(Extent Group Up-Migration)」一覧になります:
2010ページの利用 (Curator)
2010ページは、Curator MapReduceフレームワークの詳細をモニターするためのページです。このページは、ジョブ、スキャンおよび関連するタスクの詳細情報を提供します。
Curatorページには、http://<CVM IP>:2010 から入ることができます。 注意: Curatorリーダーにいない場合は、「Curator Leader:」の後のIPアドレスをクリックしてください。
ページの上部には、稼動時間、ビルドバージョンなど、Curatorリーダーに関する詳細な情報が表示されます。
次のセクションには、「Curatorノード」一覧があり、クラスタ内のノード、ロール、ヘルス状態といった詳細が表示されています。 これらは、Curatorが分散処理とタスクの移譲のために使用しているノードです。
以下が「Curatorノード」一覧になります:
次のセクションは「Curatorジョブ」一覧で、完了したジョブと現在実行中のジョブを表示しています。
ジョブには主に、60分に1回程度の実行が望ましいパーシャルスキャンと、6時間に1回程度の実行が望ましいフルスキャンという2つのタイプがあります。注意:実行タイミングは、使用率や他の処理状況により異なります。
スキャンはスケジュールに基づいて定期的に実行されますが、特定のクラスタイベントによっても起動されます。
ジョブが実行されるいくつかの理由を、以下に示します:
- 定期実行(通常の状態)
- ディスク、ノードまたはブロックの障害
- ILMの不均衡
- ディスクまたは階層の不均衡
以下が「Curatorジョブ」一覧になります:
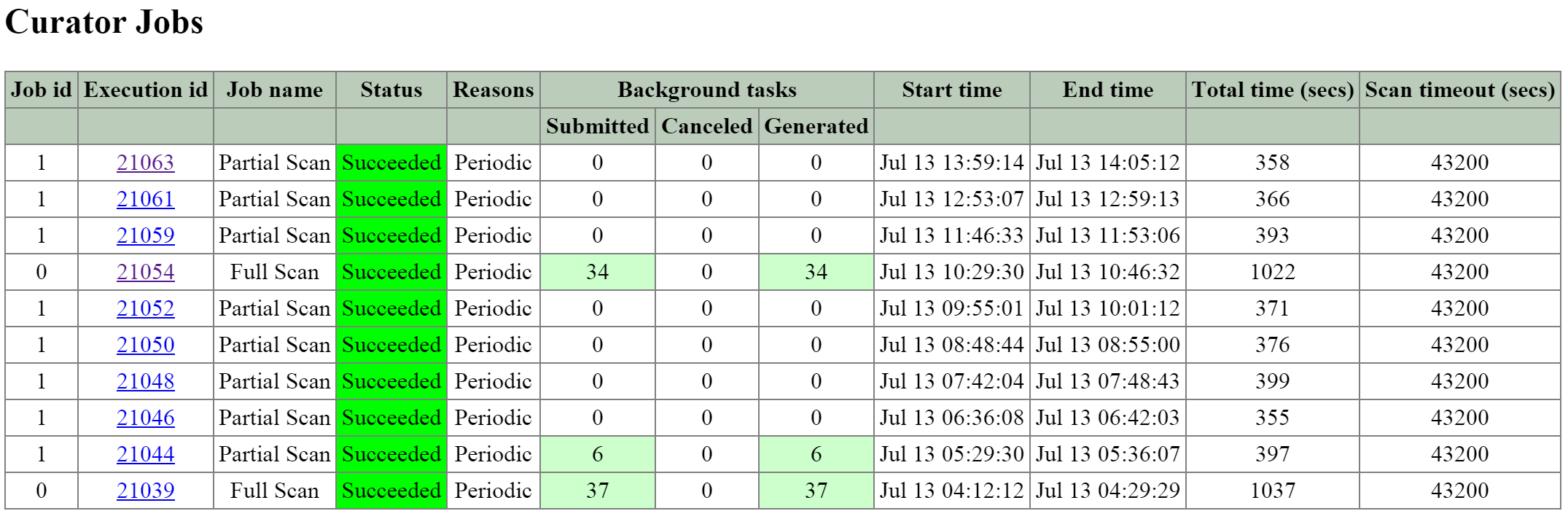
一覧には、各ジョブが実行したアクティビティの概要の一部が記載されています:
| 処理 | フルスキャン | パーシャルスキャン |
|---|---|---|
| ILM | X | X |
| ディスクバランシング | X | X |
| 圧縮 | X | X |
| 重複排除 | X | |
| 消失訂正符号 (EC) | X | |
| ガベージクリーンアップ | X |
「実行ID (Execution ID)」をクリックすると、ジョブの詳細ページに移り、生成されたタスクと同時にジョブの詳細情報が表示されます。
ページの上部に表示される一覧には、ジョブのタイプ、理由、タスク、デュレーションといった詳細が表示されます。
次のセクションには「バックグラウンドタスクステータス (Background Task Stats)」一覧があり、タスクのタイプ、生成された数量やプライオリティといった詳細が表示されます。
以下がジョブ詳細一覧になります:
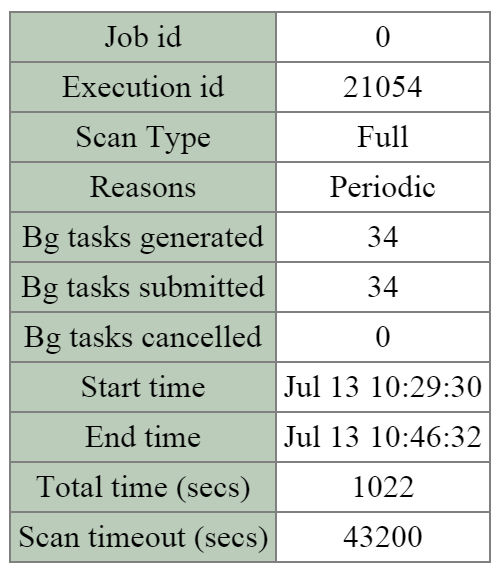
以下が「バックグラウンドタスクステータス」一覧になります:
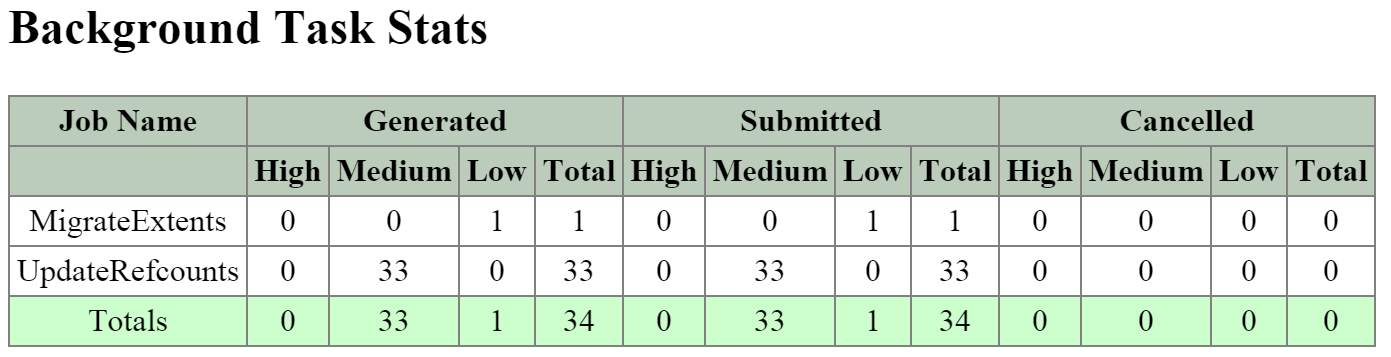
次のセクションには「MapReduceジョブ」一覧があり、各Curatorジョブにより起動された、実際のMapReduceジョブが表示されます。パーシャルスキャンには単独のMapReduceジョブとなり、フルスキャンは4つのMapReduceジョブとなります。
以下が「MapReduceジョブ」一覧になります:
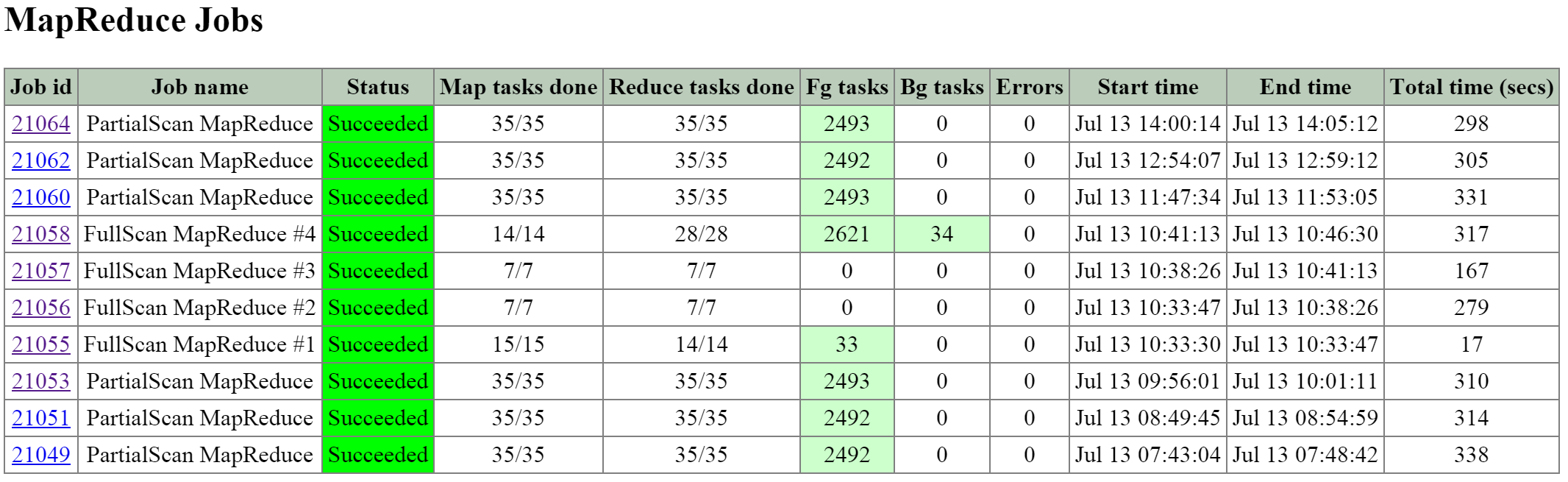
「ジョブID (Job ID)」をクリックすると、MapReduceジョブの詳細ページに移り、タスクステータス、各種カウンター、MapReduceジョブの詳細が表示されます。
以下に、ジョブのカウンターの例を図示します:
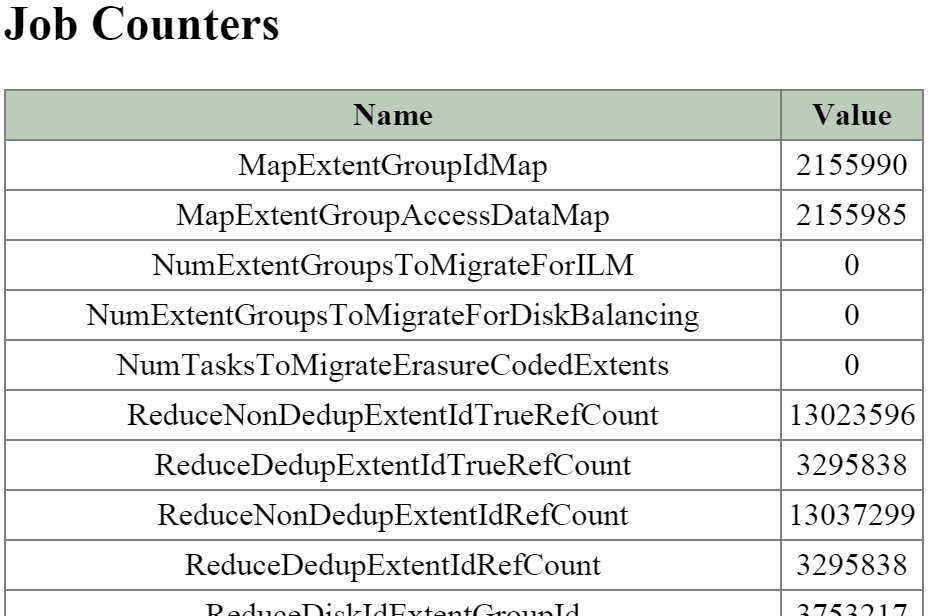
メインページの次のセクションには、「QueueされたCuratorジョブ」および「最後に完了したCuratorスキャン」一覧があります。これらの一覧には、定期的なスキャンを実施すべき適切な時間と、最後に実行されたたスキャン詳細が表示されています。
以下が「QueueされたCuratorジョブ」および「最後に完了したCuratorスキャン」セクションになります:
高度なCLIに関する情報
通常のトラブルシューティングやパフォーマンスの監視にあたっては、Prismがあれば全ての対応が可能です。しかし、これまで説明したバックエンドページやCLIで得た情報に関して、さらに詳細に把握したい場合もあるでしょう。
vdisk_config_printer
vdisk_config_printerは、クラスタの全てのvDiskに関する情報の一覧を表示するコマンドです。
以下に、主要なフィールドを列挙します:
- vdisk_id:vDisk ID
- vdisk_name:vDisk名
- parent_vdisk_id:親vDisk ID(クローンまたはスナップショットの場合)
- vdisk_size:vDiskサイズ(バイト)
- container_id:コンテナID
- to_remove bool:削除ブール値(Curatorスキャンで削除するか否か)
- mutability_state:可変ステータス(アクティブなr/w vDiskの場合は変更可、スナップショットは変更不可)
以下に、コマンドの出力例を示します:
nutanix@NTNX-13SM35210012-A-CVM:~$ vdisk_config_printer | more ... vdisk_id: 1014400 vdisk_name: "NFS:1314152" parent_vdisk_id: 16445 vdisk_size: 40000000000 container_id: 988 to_remove: true creation_time_usecs: 1414104961926709 mutability_state: kImmutableSnapshot closest_named_ancestor: "NFS:852488" vdisk_creator_loc: 7 vdisk_creator_loc: 67426 vdisk_creator_loc: 4420541 nfs_file_name: "d12f5058-f4ef-4471-a196-c1ce8b722877" may_be_parent: true parent_nfs_file_name_hint: "d12f5058-f4ef-4471-a196-c1ce8b722877" last_modification_time_usecs: 1414241875647629 ...
vdisk_usage_printer -vdisk_id=<VDISK ID>
vdisk_usage_printerは、vDiskの詳細、エクステント、egroupに関する情報の取得に使用します。
以下に、主要なフィールドを列挙します:
- Egid:egroup ID
- # eids:egroupエクステントカウント
- UT Size:未変換egroupサイズ(untransformed egroup size)
- T Size:変換済みegroupサイズ(transformed egroup size)
- Ratio:変換率(transform ratio)
- T Type:変換タイプ(transformation type)
- Replicas(disk/svm/rack):egroupのレプリカのロケーション(ディスク/CVM/ラック)
以下に、コマンドの出力例を示します:
nutanix@NTNX-13SM35210012-A-CVM:~$ vdisk_usage_printer -vdisk_id=99999 Egid # eids UT Size T Size ... T Type Replicas(disk/svm/rack) 1256878 64 1.03 MB 1.03 MB ... D,[73 /14/60][184108644 /184108632/60] 1256881 64 1.03 MB 1.03 MB ... D,[73 /14/60][152 /7/25] 1256883 64 1.00 MB 1.00 MB ... D,[73 /14/60][184108642 /184108632/60] 1055651 4 4.00 MB 4.00 MB ... none[76 /14/60][184108643 /184108632/60] 1056604 4 4.00 MB 4.00 MB ... none[74 /14/60][184108642 /184108632/60] 1056605 4 4.00 MB 4.00 MB ... none[73 /14/60][152 /7/25] ...
注意: 重複排除済みと非重複排除でのegroupのサイズの違い(1MB対4MB)にご注意下さい。 「データ構造」セクションで説明したように、重複排除の結果、重複排除後のデータにフラグメンテーションが発生しないようにするためには、egroupサイズが1MBの方を優先すべきです。
curator_cli display_data_reduction_report
curator_cli display_data_reduction_reportを使って、コンテナ別のストレージ削減量に関する詳細情報を、適用したトレージの変換テクニック(クローン、スナップショット、重複排除、圧縮、消失訂正符号など)別にレポートすることができます。
以下に、主要なフィールドを列挙します:
- Container Id:コンテナID
- Technique:テクニック(適用した変換)
- Pre Reduction:削減前のサイズ
- Post Reduction:削減後のサイズ
- Saved:削減容量
- Ratio:削減率
以下に、コマンドの出力例を示します:
CVM:~$ curator_cli display_data_reduction_report Using curator leader: 99.99.99.99:2010 Using execution id 68188 of the last successful full scan +---------------------------------------------------------------------------+ | Container| Technique | Pre | Post | Saved | Ratio | | Id | | Reduction | Reduction | | | +---------------------------------------------------------------------------+ | 988 | Clone | 4.88 TB | 2.86 TB | 2.02 TB | 1.70753 | | 988 | Snapshot | 2.86 TB | 2.22 TB | 656.92 GB | 1.28931 | | 988 | Dedup | 2.22 TB | 1.21 TB | 1.00 TB | 1.82518 | | 988 | Compression | 1.23 TB | 1.23 TB | 0.00 KB | 1 | | 988 | Erasure Coding | 1.23 TB | 1.23 TB | 0.00 KB | 1 | | 26768753 | Clone | 764.26 GB | 626.25 GB | 138.01 GB | 1.22038 | | 26768753 | Snapshot | 380.87 GB | 380.87 GB | 0.00 KB | 1 | | 84040 | Snappy | 810.35 GB | 102.38 GB | 707.97 GB | 7.91496 | | 6853230 | Snappy | 3.15 TB | 1.09 TB | 2.06 TB | 2.88713 | | 12199346 | Snappy | 872.42 GB | 109.89 GB | 762.53 GB | 7.93892 | | 12736558 | Snappy | 9.00 TB | 1.13 TB | 7.87 TB | 7.94087 | | 15430780 | Snappy | 1.23 TB | 89.37 GB | 1.14 TB | 14.1043 | | 26768751 | Snappy | 339.00 MB | 45.02 MB | 293.98 MB | 7.53072 | | 27352219 | Snappy | 1013.8 MB | 90.32 MB | 923.55 MB | 11.2253 | +---------------------------------------------------------------------------+
curator_cli get_vdisk_usage lookup_vdisk_ids=<COMMA SEPARATED VDISK ID(s)>
curator_cli get_vdisk_usage lookup_vdisk_idsコマンドは、指定された各vDiskで使用されているスペースについてのさまざまな統計を取得するために使用されます。
以下、主要なフィールドを列挙します:
- VDisk Id
- Exclusive usage(占有使用量):該当するvDiskのみがアクセスするデータ
- Logical Uninherited(論理未継承量):vDiskに書き込まれたデータで、クローン時に子に継承されるもの
- Logical Dedup(論理重複排除量):重複排除されたvDiskデータの総量
- Logical Snapshot(論理スナップショット):vDiskチェーンで共有されていないデータ
- Logical Clone(論理クローン):vDiskチェーンで共有されているデータ
以下に、コマンドの出力例を示します:
Using curator leader: 99.99.99.99:2010 VDisk usage stats: +------------------------------------------------------------------------+ | VDisk Id | Exclusive | Logical | Logical | Logical | Logical | | | usage | Uninherited | Dedup | Snapshot | Clone | +------------------------------------------------------------------------+ | 254244142 | 596.06 MB | 529.75 MB | 6.70 GB | 11.55 MB | 214 MB | | 15995052 | 599.05 MB | 90.70 MB | 7.14 GB | 0.00 KB | 4.81 MB | | 203739387 | 31.97 GB | 31.86 GB | 24.3 MB | 0.00 KB | 4.72 GB | | 22841153 | 147.51 GB | 147.18 GB | 0.00 KB | 0.00 KB | 0.00 KB | ...
curator_cli get_egroup_access_info
curator_cli get_egroup_access_infoを使って、最新のアクセス(読み込み、変更(書き込みまたは上書き))を基に、各バケットのegroupの数に関する詳細な情報をレポートすることができます。この情報を使えば、消失訂正符号に適したegroupの数を推定することができます。
以下に、主要なフィールドを列挙します:
- Container Id:コンテナID
- Access \ Modify (secs)
以下に、コマンドの出力例を示します:
Using curator leader: 99.99.99.99:2010 Container Id: 988 +----------------------------------------------------------------------------.. | Access \ Modify (secs) | [0,300) | [300,3600) | [3600,86400) | [86400,60480.. +----------------------------------------------------------------------------.. | [0,300) | 345 | 1 | 0 | 0 .. | [300,3600) | 164 | 817 | 0 | 0 .. | [3600,86400) | 4 | 7 | 3479 | 7 .. | [86400,604800) | 0 | 0 | 81 | 7063 .. | [604800,2592000) | 0 | 0 | 15 | 22 .. | [2592000,15552000) | 1 | 0 | 0 | 10 .. | [15552000,inf) | 0 | 0 | 0 | 1 .. +----------------------------------------------------------------------------.. ...
Networking
Network Services
本書では、Nutanix によって提供されるネットワークとネットワークセキュリティのサービスについて説明します
- Flow Network Security
- Security Central
- Flow Virtual Networking
これらの製品を別の名前で聞いたことがあるかたのために、ここで少し各製品の歴史と概要を示します。
我々は、カテゴリとポリシーベースマイクロセグメンテーションのソリューションとしてNutanix Flowをリリースしました。 以前はFlowとして知られていた、ステートフル、分散、そしてマイクロセグメンテーションのファイアウォールは、現在はFlow Network Securityと呼ばれています。
オンプレミスとクラウド環境の両方に対して、セキュリティプランニング、脅威検出、コンプライアンス監査を提供するために、NutanixはSaaSベースで提供されるBeamをリリースしました。 Beamのセキュリティコンポーネントは、現在はSecurity Centralとして知られています。
重複するIPアドレスに対応する本当のマルチテナントネットワーキングや、セルフサービスによるネットワークプロビジョニングのためにNutanix Flow Networkingをリリースしましたが、現在ではFlow Virtual Networkingと呼ばれています。
チャプター
- Flow Network Security
- Security Central
- Flow Virtual Networking
Flow Network Security
Flow Network Securityは、分散かつステートフルなファイアウォールとして、AHVプラットフォームで稼動する仮想マシン間や外部のエンティティとのきめ細かなネットワーク監視とエンフォースメントを可能にします。
サポートされている構成
このソリューションは以下の構成に適用できます:
-
主なユースケース:
- マイクロセグメンテーション
-
管理インターフェイス:
- Prism Central (PC)
-
サポートされる環境:
-
オンプレミス:
- AHV
- クラウド:
- Nutanix Cloud Clusters on AWS
-
アップグレード:
- Flow SecurityとしてLCMに組み込まれている
-
互換性のある機能:
- サービスチェイニング(Service Chaining)
- Security Central
- Calm
Flow Network Securityの設定については、Prism Centralでポリシーを定義し、仮想マシンにカテゴリを割り当てる形で行います。 Prism Centralは、接続されている多くのAHVクラスタのセキュリティポリシーとカテゴリをひとつの場所で定義できます。 それぞれのAHVホストについては、分散適用するための要件によりOVSとOpenFlowを使用してルールを実装します。
実装の構成
Flow Network Securityには、いくつかの重要な構成要素があります:
カテゴリ
カテゴリとは、ポリシーの適用対象となる仮想マシングループを定義するために使用される、シンプルなキー/バリューのペアです。 一般的なカテゴリは、環境、アプリケーションの種類、そしてアプリケーションの層です。 仮想マシンの識別に役立つように任意のキー/バリュータグをカテゴリとして使用できますが、アプリケーションセキュリティポリシーのためにはAppTypeやAppTierといったカテゴリが必要です。
- カテゴリ: 「キー: バリュー」形式のタグ
- キーの例: AppType、AppTier、Group、Location
例えば、商用環境のデータベースサービスを提供する仮想マシンには、以下のようにカテゴリが割り当てられる場合があります:
- AppTier: Database
- AppType: Billing
- Environment: Production
これらのカテゴリは、適用するルールやアクションを決定するためのセキュリティポリシーに利用できます。 カテゴリはFlow Network Securityだけでなく、保護ポリシー(Protection Policy)でも同じカテゴリが使用できます。
セキュリティポリシー
セキュリティポリシーは、定義済みのカテゴリ間で許可の内容を決定するためのルール定義です。
セキュリティポリシーには、以下に示すような幾つかのタイプが存在します:
- 検疫ポリシー (Quarantine Policy)
- 特定の仮想マシンまたはカテゴリへの全てのトラフィックを拒否します: Strict
- 調査のための特定のトラフィックを除く全てのトラフィックを拒否します: Forensics
- 例1: 仮想マシン A、B、Cがウィルスに感染した場合に、ウィルスのネットワーク感染を阻止するため、その仮想マシンを隔離します。
- 例2: 仮想マシン A、B、Cが感染しました。それらを隔離しますが、解析のためにセキュリティチームの仮想マシンへの接続は許可します。
- 分離ポリシー (Isolation Policy)
- カテゴリ間のトラフィックは拒否し、カテゴリ内のトラフィックについては許可します
- 例: テナントAをテナントBとクローン環境から分離し、通常のネットワーク通信に影響を与えずに並列実行を可能にします。
- アプリケーションポリシー (App Policy)
- これは一般的な5タプルのルールで、許可する通信を、トランスポート(TCP/UDP)、ポート、そしてソース/デスティネーションによって定義できます。
- Allow Transport: Port(s) To,From
- 例: Location:HQカテゴリを割り当てた仮想マシンから、AppTier:Webカテゴリを割り当てた仮想マシンへのTCP 443を許可します。
- VDI Policy
- ログインしたユーザのADグループに基づいてVDI仮想マシンにカテゴリを割り当てる、アイデンティティベースファイアウォールです。
- 割り当てられたADグループを基にポリシーを実装します。
以下は、Flow Network Securityを使った、サンプルアプリケーションにおけるトラフィックコントロールの例です:
ポリシーの状態
ポリシーの状態(Policy State)は、ルールが一致した場合にどんなアクションを取るかを決定します。Flow Network Securityには、2種類のステートがあります:
- Enforce
- 定義されたフローのみを許可し、それ以外の全てをドロップするポリシーを適用します。
- Monitor
- 全てのフローを許可しますが、ポリシーを可視化するページで、ポリシーに違反してたであろうパケットをハイライト表示します。
ルールの適用
Flow Network Securityのポリシーは、パケットがUVMを出て、他の仮想マシンに到達する前に適用されます。 これは、AHVホストのマイクロセグメンテーションブリッジ(br.microseg)で発生します。
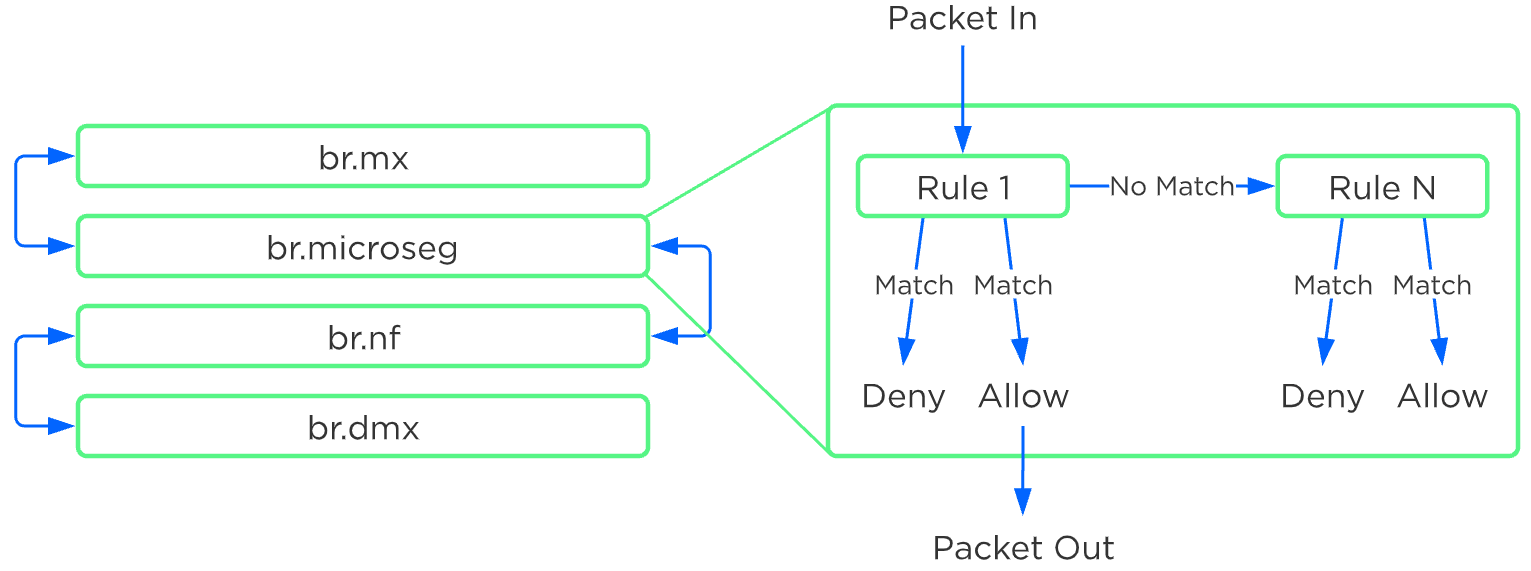
ポリシーはカテゴリを基に構築されますが、ルールの適用は検出された仮想マシンのIPアドレスをもとに行われます。 Flow Network Securityの役割は、全ての仮想マシンに割り当てられているカテゴリとポリシーを評価し、保護された仮想マシンの稼働しているホスト(またはホスト群)のbr.microsegブリッジに正しいルールをプログラムすることです。 Nutanix AHV IPAMを使用している仮想マシンは、仮想マシンがパワーオンされた際に、NICがプロビジョニングされるとすぐにIPアドレスが分かりルールがプログラムされます。 Nutanix Acropolisのプロセスは、スタティックIPまたは外部のDHCPを利用する仮想マシンのIPアドレスを検出するために、DHCPとARPのメッセージをインターセプトします。 それらの仮想マシンは、仮想マシンのIPアドレスが分かるとすぐにルールが適用されます。
検疫、アプリケーション、そしてVDIポリシーのルール評価は、検出したIPv4のアドレスをベースにしています。
隔離ポリシーのルール評価は、検出したIPv4のアドレスと、仮想マシンのMACアドレスの両方をベースにしています。
評価の順序は、次の順序での最初のマッチに基づきます。
- 検疫(Quarantine)
- 隔離(Isolation)
- アプリケーション(App)
- VDI
最初にマッチしたポリシでアクションが実行され、それ以降の処理はすべて停止します。 例えば、トラフィックがMonitorモードになっている隔離ポリシーに出会った場合は、転送するアクションが行われ、許可および監視されたことがログ出力されます。 たとえ、このトラフィックをブロックするアプリケーションやVDIのポリシーが以降にあったとしても、それ以上のルールは評価されません。
さらに、仮想マシンは1つのAppTypeカテゴリのみに所属することができ、 AppTypeカテゴリは、単一のAppTypeのみが設定できるポリシーのターゲットグループに入れることができます。 つまり、仮想マシンは1つのAppTypeポリシーのターゲットグループにのみに所属することができます。 仮想マシンで受信/送信する全てのトラフィックは、この単一のAppTypeポリシーで定義する必要があります。 現在、仮想マシンが複数のアプリケーションポリシーの中心にあるというコンセプトではなく、したがって、アプリケーションポリシー間で競合や評価順序が発生することはありません。
Security Central
Nutanix Security Centralは、マイクロセグメンテーションのセキュリティプランニング、脅威検出アラート、そして継続的なコンプライアンス監視を提供する、Software as a Service(SaaS)製品です。 複数の機械学習(ML)モデルと、Louvain法、ARIMA、ツリーベース、クラスタリングのようなアルゴリズムを使用し、Security Centralは500を超える監査チェックとセキュリティのベストプラクティスに基づいて、オンプレミスの展開へのセキュリティに関する洞察を提供します。
Security Central Portal(https://flow.nutanix.com/securitycentral)は、クラウドとオンプレミスインフラストラクチャーで一般的そしてリスクの高い構成間違いを調査するために、インベントリ(棚卸し)と構成アセスメントを提供します。 このインベントリとコンプライアンス追跡ツールを組み合わせることで、セキュリティポスチャ監視も提供されます。 Security Centralのユーザーは、システム定義されたSQLのようなカスタムクエリを使用することで、セキュリティの状態についてその瞬間の洞察を得ることもできます。
最後になりますが、オンプレミスのAHVクラスタから取り込んだネットワークフローの情報により、機械学習によるトラフィックパターン分析に基づくほぼリアルタイムでの脅威検出を提供します。
サポートされる環境
- オンプレミスのNutanix
- Flow Network Securityが有効化されたAHVを使用するプライベートクラウド
- パブリッククラウド: AWSとMicrosoft Azure
- パブリッククラウドインフラストラクチャー内のリソースとサービスを監視
管理インターフェイス
- Flow Security Central SaaS UI
- Flow Security Central VM(FSC VM)
- 初期構成と、必要に応じたアップグレード
実装の構成
Security Centralは、セキュリティ監視と管理フレームワークを提供するために、いくつかの新しい構成を導入しています。
導入された2つの要素は次のとおりです:
- Flow Security Central VM(FSC VM)[オンプレミスのNutanixのみで必要]
- 初期構成時のみ使用
- IPFIXログ収集
- インベントリ収集
- セキュリティポリシー構成のプッシュ
- Security Central SaaS
- セキュリティポスチャ監視
- ユーザーとネットワークの異常検知
- コンプライアンスのレポーティング
- マイクロセグメンテーションのセキュリティプランニング
- マルチクラウドのインベントリとクエリ
アップグレード
- Security CentralはSaaSプラットフォームであるため自動的
- 新機能がリリースされると、次回のログインから利用可能になります。
- 時折、機能強化のためにオンプレミスのFSC VMのアップグレードが必要になることがあります。
- アップグレードは、Flow Security Central VMのSettingsページから実行できます。
- 最新のFSC VMのイメージ("FSCVM Image with GUI"と"FSCVM Image Server only"の両方)は、Nutanix Portal にあります。
Security Centralアーキテクチャーの概観
Security Centralのハイレベルアーキテクチャーの詳細
Security CentralはFSC VMという新しいサービス仮想マシンを導入しており、これはNutanixクラスタのためのセキュリティ監視を有効化するために必要です。 FSC VMはプロキシとして動作し、Nutanixクラスタからの情報を集約します。 それから、その情報を安全なネットワーク接続を介してSecurity Centralに送信します。
FSC VMは、メタデータとよばれる環境と仮想マシンについてのインベントリ情報を収集します。 Security Centralは、インストールされているソフトウェアパッケージやバージョンといった、仮想マシンが所有するデータの収集はしませんが、Qualysのようなパートナーのエージェントとのインテグレーションによりメタデータを充実させられます。
インストールしたら、管理者はFSC VM UIに接続してネットワークログの収集を有効化します。 その後、FSC VMはPrism Centralに、そのPrism Centralインスタンスによって管理されるすべてのAHVクラスタでIPFIXエクスポーターを有効化するように指示します。
FSC VMはPrism Centralから、すべての登録されているクラスタと仮想マシンについてのクラスタインベントリ情報も収集します。 収集されるインベントリ情報には、仮想マシン名、接続されたネットワークの情報、構成情報、そして仮想マシンに割り当てられるカテゴリなどの項目が含まれます。 インベントリのポーリングは3時間ごとに繰り返され、SaaSポータルは変更の記録と分析を行えます。
インベントリとIPFIXログは、HTTPS/TLS接続を使用して安全にSecurity CentralのSaaS環境に送信されます。 IPFIXログを15分間隔で送信することで、FSC VMはバッチ単位の増分でデータを送信できるため、FSC VMに必要なストレージ容量が削減され、クラウドへのネットワークの制約が軽減されます。
管理者は必要に応じて、FSC VM UIを使用して、要求されたインベントリ更新を手動でクラウドにプッシュできます。
FSC VMは、Prism Central(PC)によって管理されるクラスタ数に関係なく、展開されたPCごとに必要です。 FSC VMは、Prism Centralへの内部通信と、SaaSポータルへのアウトバウンド通信を容易にします。 Security Centralは、コンポーネント間の通信で以下のTCPポートを使用します。
ファイアウォールで、次のポートが開放されていることを確認してください:
- FSC VMがPrism Central VMに接続するためのTCP 9440ポート
- FSC VMが*.nutanix.comと *.amazonaws.com に接続するためのTCP 443ポート
完全なポートの一覧については Flow Security CentralのPorts and Protocols ページを参照してください。
Flow Security Centralのプラットフォームは、厳格なセキュリティ管理を受けています。 Flow Security Centralのコンプライアンス認定を参照してより詳細を知るためにNutanix Trustを訪れてください。
Flow Security Central VMの構成要件を確実に満たすためには、Security Central Guideを調べてください。
主なユースケース
- 監視と可視化
- マルチクラウドダッシュボード、資産インベントリ、レポート、アラート
-
- 監査と修復
- リアルタイムの自動セキュリティ監査を使用した、Nutanix環境とパブリッククラウドに関する洞察
- コンプライアンス
- 継続的な環境監視、自動化されたコンプライアンスチェック、STIG/PCI/HIPAAのためのアセスメント
- セキュリティプランニング
- 仮想マシン同士のネットワークトラフィックの視覚化、ワークロードの分類、自動化されたセキュリティポリシーの推奨
- 違反の調査
- SQLのようなクエリ言語を使用した詳細調査の実施
- 脅威検出アラート
- ネットワークおよびユーザーベースの異常検出。 EUBA(End user behavior analysis)が内部および外部のセキュリティ脅威の検出に役立つ
Security Centralの主な機能
メインダッシュボード
Security Centralへの正常なログインの後に表示される最初の画面は、メインダッシュボードです。 そのダッシュボードは、Security Centralによって監視および警告された多くの領域の概観を提供します。 より詳細な表示は、個々のウィジェットから起動できます。
監査と修復
セキュリティ監査を利用することで、オンプレミス展開のセキュリティに関する深い洞察が提供されます。 Security Centralは、環境に500を超えるすぐに利用可能な(out-of-the-boxの)自動化されたセキュリティ監査を実行し、監査の失敗については修正手順とともに報告します。
Security Centralの監査チェックは、次のカテゴリとNutanixのセキュリティベストプラクティスに準拠しています:
- アクセスセキュリティ
- 非特権アクセスまたはアクセス監査欠如の可能性があるアイテムの構成とアラート
- データセキュリティ
- 保存データの暗号化(DARE:Data-at-Rest Encryption)が有効になっていないNutanixクラスタ。 DAREは、暗号化キーを所有していないシステムやユーザーによるデータへの許可されていないアクセスを防止するための、インフラストラクチャーを保護するために非常に重要なコンポーネントです。
- ホストセキュリティ
- バックアップ保護が有効になっていないNutanix仮想マシンは、仮想マシンがランサムウェアに感染した場合の回復を困難にします。
- ロギングと監視
- Prism Centralの重要なアラートで確認対応がされておらず、アラートが無視されているか見逃されていることを示している可能性があります。 これらのアラートは、インフラストラクチャーを危険にさらしうる潜在的なリスクを示している可能性があります。
- ネットワークセキュリティ
- 仮想マシンはすべての送信元からのすべてのトラフィックを許可しており、これにより悪意のある攻撃者が仮想マシンを危険にさらして環境に侵入するための非常に大きな攻撃対象領域が作られます。
常に更新される組み込みの監査に加えて、Security Centralは、Common Query Language(CQL)を使用して監査とレポートをカスタマイズする機能を提供しています。 これにより、さまざまな属性についてクラウドインベントリでCQLクエリを実行し、特定のユースケースのための監査チェックを作成できます。
コンプライアンス(Compliance)
Nutanixの多くのカスタマーにとって、コンプライアンスは非常に重要です。 コンプライアンスを維持することで、会社の運用環境が従うべき管理基準が満たされていることを検証できます。
コンプライアンスのために環境を監視することは、困難で時間がかかる場合があります。 絶えず変化する要件、規制、環境を常に把握するには、継続的なコンプライアンス監視機能が必要です。 カスタマーには、これらのチェックを自動化することで、コンプライアンス違反への対処において、簡潔なビューと解決時間の短縮という利益があります。
Security Centralは、PCI-DSS、HIPAA、NISTなどの一般的な規制フレームワークと、Nutanix STIGポリシーを使用したNutanixセキュリティベストプラクティスの監査チェックを提供します。
コンプライアンスダッシュボードは、監視されている各フレームワークのコンプライアンススコアを提供します。 スコアの要素をさらに調査して、監視および監査されているフレームワークの要素、合格したチェックの数、および失敗したチェックの数を表示できます。 コンプライアンスビューには、失敗したチェック、チェックが関連付けられているフレームワークのセクション、検出された問題などの、チェックの詳細が表示されます。 コンプライアンスレポートとその詳細は、オフラインでの使用および共有するためにエクスポートすることもできます。
Security Centralは、ビジネス要件に基づいたカスタム監査とカスタムコンプライアンスポリシーを作成する拡張機能も提供します。
調査とアラート(Findings and Alerts)
「問題をきちんと述べられれば、半分は解決したようなものだ」
- チャールズケタリング
脅威の状況は絶えず変化しているため、今日の環境ではセキュリティの監視とアラート発報が重要です。 ネットワーク、セキュリティコントロール、サーバー、エンドポイント、そしてユーザーアプリケーションで見つかった脅威と脆弱性を継続的に監視してアラート発報することで、全体的なセキュリティポスチャを強化し、問題が検出された際に解決時間を短縮するアラートへのプロアクティブなアプローチを可能にしています。
Security CentralにあるFindings and Alertsビューは、現在のセキュリティポスチャのビューを提供します。 このビューには、Security Centralによって監視されているNutanixクラスタで検出された構成の問題と観測された異常な動作が表示されます。 これらの調査結果は、選択した監査ポリシーに基づいています。 ユーザーにはこれらの問題の表示方法についてのカスタマイズ可能なオプションがあり、監査カテゴリ、リソース、役割、そしてビジネス要件ごとに調査結果を調整するための優れた柔軟性を提供します。
脅威検出のアラートは、Findings and Alertsビューに含まれています。 Security Centralは、NutanixのIPFIXネットワークログを分析して、監視対象のNutanixクラスタ内で発生する潜在的な脅威と異常な動作を検出してレポートします。 これらのアラートは、機械学習と観測されたデータポイントを使用してモデル化されます。
以下は、検出される潜在的な脅威と動作の一部と、異常の登録またはアラートをトリガーするために監視する必要のある最小日数またはデータポイントです:
- ブラックリストに登録されたIP(既知の疑わしいIP)と通信する仮想マシン
- 1 データポイント
- 辞書攻撃の可能性がある仮想マシン
- 1 データポイント
- サービス拒否(DDoS)攻撃の可能性がある仮想マシン
- 21 日
- 異常なネットワーク動作のVLAN
- 21 日
- 異常なネットワーク動作をする仮想マシン
- 21 日
- ポートスキャン攻撃の可能性がある仮想マシン
- 21 日
- データ漏えい攻撃の可能性がある仮想マシン
- 21 日
セキュリティプランニング(Security Planning)
アプリケーションのセキュリティ保護を計画する場合、効果的なセキュリティポリシーの作成に必要とされる、検出および情報収集する多くのコンポーネントがあります。 この情報を収集することは、非常に困難な場合があります。 多くの場合、アプリケーションの通信プロファイルを得るために、ファイアウォール、ネットワーク機器、アプリケーション、そしてオペレーティングシステムからログを収集する必要があります。 それらデータが収集および分析されたら、アプリケーションの所有者と相談して、観察された結果を、期待される動作と比較します。
Security CentralのMLベースのセキュリティプランニングは、アプリケーションのセキュリティポリシーの検出と計画に役立つ詳細な視覚化を提供します。 オンプレミスのNutanixクラスタ内のネットワークトラフィックフローを視覚化し、Security Centralがアプリケーションを分類して保護する方法についての推奨事項を作成します。
Security Planningセクションでは、アプリケーションと環境として、最大2レベルのグループ化を柔軟に利用できます。 この機能では、分析を特定のクラスタ、VLAN、仮想マシン、そしてカテゴリにドリルダウンできるため、アプリケーションの保護に集中することにおいて非常に役立ちます。 このグループ化により、観測またはフィルタリングされたすべてのネットワークトラフィックをダウンロードして、オフラインでの共有、検出、そして計画をさらに進めることができます。
備えられている機械学習機能を使用することで、Security Centralは観察されたネットワークフローに基づいて、カテゴリの推奨と仮想マシンへの割り当てを行うこともできます。 これは、新規のマイクロセグメンテーションまたはアプリケーションの展開で特に役立ちます。 アプリケーションの仮想マシンを分類することは、アプリケーションを保護するための重要なステップです。 さらに一歩進んで、Security Centralは、インバウンドおよびアウトバウンドのルール推奨を生成し、Nutanix AHVクラスタでのアプリケーションセキュリティポリシーをMonitorモードで作成することもできます。
Monitorモードのセキュリティポリシーを使用すると、ポリシーアクションを適用しなくても、セキュリティで保護されているアプリケーションの動作を監視できます。 Prism Centralを使用して、必要に応じてポリシーを適用する前にポリシーを編集できます。
調査(Investigate)
Investigateは、ハイブリッド クラウド インフラストラクチャーのセキュリティと運用に関する洞察を分析するために役立ちます。 これは、CQL(Common Query Language)を使用してネットワーク ログとセキュリティ構成を分析できます。 CQLのクエリは、SQLと同様のユーザー フレンドリーな操作感を提供します。 ほぼリアルタイムで望ましい結果を得るために、オンプレミスとパブリック クラウド インフラストラクチャーの両方でCQLクエリを簡単に実行できます。
Investigateは、次の種類のクエリをサポートしています:
-
インベントリと構成: オンプレミスおよびパブリック クラウド環境でのリソース インベントリと構成の検索
-
ネットワーク: オンプレミス環境でのネットワーク イベントの検索
クロススタックでの可視性を提供することは、ハイブリッド クラウド環境で調査するための主要な使用例の1つです。 例えば、ほとんどの場合にはセキュリティ ルールの複数のスタックがあります。 オンプレミス側にはFlow Network Securityのポリシーがあり、クラウドにはEC2インスタンスのセキュリティ グループがあるでしょう。 この場合はInvestigateのクエリにより、特定の仮想マシンに適用されるすべてのマイクロセグメンテーション ポリシーとAWSセキュリティ ポリシーのリストが提供されます。
Investigate機能では、最初によく使用されるクエリのライブラリも提供されており、ニーズに基づいてより複雑なクエリを作成するためのベースラインとなります。
クエリの例:
-
仮想マシンのステータス(保護または非保護)と、仮想マシンが保護されている場合のポリシーの名前の一覧
- SELECT NX.VM.name, NX.VM.NetworkPolicy.*, NX.VM.Category.* FROM NX.VM
-
AWS EC2インスタンスのすべてのタグの一覧
- SELECT AWS.EC2Instance.Tag.tagKey, AWS.EC2Instance.Tag.tagValue, AWS.EC2Instance.instanceId, AWS.EC2Instance.name FROM AWS.EC2Instance
統合(Integrations)
セキュリティアーキテクチャーは、多くの場合で、多層防御の姿勢を構築するために複数ベンダーのソリューションで構成されています。 エンドポイントの脅威と脆弱性、チケットシステム、ログ管理、脅威とイベントの分析を監視するソリューションは、すべてセキュリティアーキテクチャーの重要なコンポーネントになる可能性があります。 これらの製品は非常に重要ですが、多くの場合にスタンドアロンであり、セキュリティインフラストラクチャーの他のコンポーネントとの統合に制限があります。 統合は、セキュリティアーキテクチャーの構築でセキュリティソリューションをまとめるための鍵となります。 これは、脅威の認識、分析、脅威の修復についての効率化および時間短縮となります。
Security Centralは、Nutanix以外のアプリケーションをSecurity Centralと直接統合する機能を提供します。 これらの統合は、OSレベルの監視と保護から、エンタープライズのチケットシステムや分析エンジンまで、複数のソリューションをカバーしています。
いくつかのサポートされている統合を以下に示します:
- Splunk
- Webhook
- ServiceNow
- Qualys
Flow Virtual Networking
Flow Virtual Networkingを使用すると、物理ネットワークから切り離され、完全に隔離された仮想ネットワークを作成できます。 重複するIPアドレスを持つマルチテナントネットワークプロビジョニング、セルフサービスでのネットワークプロビジョニング、IPアドレスの保持といったことが実行できます。 特に、これらの分離された仮想ネットワークはデフォルトでセキュリティを提供します。
サポートされている構成
主なユースケース:
- マルチテナントネットワーキング
- セキュリティのためのネットワーク隔離
- IPアドレスの重複割り当て
- セルフサービスでのネットワーク作成
- 仮想マシンIPアドレスの移動
- ハイブリッドクラウドの接続
管理インターフェイス:
- Prism Central (PC)
サポートされる環境:
- オンプレミス:
- AHV
アップグレード:
- 主な機能のアップグレードが依存するもの
- Prism Central
- AHV
- 主な機能のアップグレードでLCMに含まれるもの
- Advanced Network Controller
- ネットワークゲートウェイ(VPN、サブネット延伸、BGP)
実装の構造
Flow Virtual Networkingは、完全なネットワーキングソリューションを提供するため、いくつかの新しい構造を導入しています。
- 仮想プライベートクラウド(VPC)
- オーバーレイサブネット(Overlay Subnets)
- ルート(Routes)
- ポリシー(Policies)
- 外部ネットワーク(External Networks)
- NAT
- Routed(NoNAT)
- 複数の外部ネットワーク
- ネットワークゲートウェイ
- レイヤー3 VPN
- VXLANによるレイヤー2延伸サブネット
- BGP
仮想プライベートクラウド(VPC)
VPC(Virtual Private Cloud)は、Flow Virtual Networkingの基本単位です。 それぞれのVPCは、VPC内の全サブネットと接続するための仮想ルータインスタンスを持つ、隔離されたネットワーク名前空間です。 これにより、ひとつのVPC内にあるIPアドレスを、他のVPCや物理ネットワークと重複させることができます。 VPCは同一のPrism Centralで管理されているクラスタに拡張することができます。 しかし、通常はVPCが単一のAHVクラスタ内、もしくは同一のアベイラビリティ ゾーン内のクラスタに存在するべきです。 詳細については、外部ネットワークにて説明します。
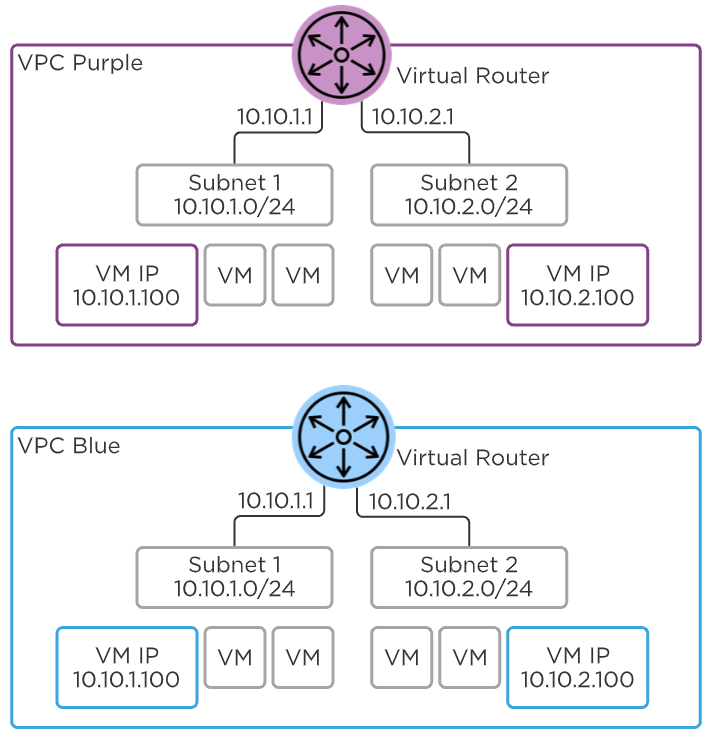
オーバーレイサブネット(Overlay Subnets)
それぞれのVPCは1つ以上のサブネットを持つことができ、それらは全て同じVPC仮想ルータに接続されます。 内部では、VPCは、必要に応じてAHVホスト間のトラフィックをトンネリングするためにGeneveによるカプセル化を利用しています。 つまり、異なるホスト上の仮想マシンが通信するために、VPC内のサブネットは、作成したりトップオブラックスイッチに存在させたりする必要はありません。 VPCにある2つの異なるホスト上の2つの仮想マシンで相互通信する場合、パケットは最初のホストでGeneveでカプセル化され、別のホストに送信されるとカプセル化が解除されて宛先の仮想マシンに送信されます。
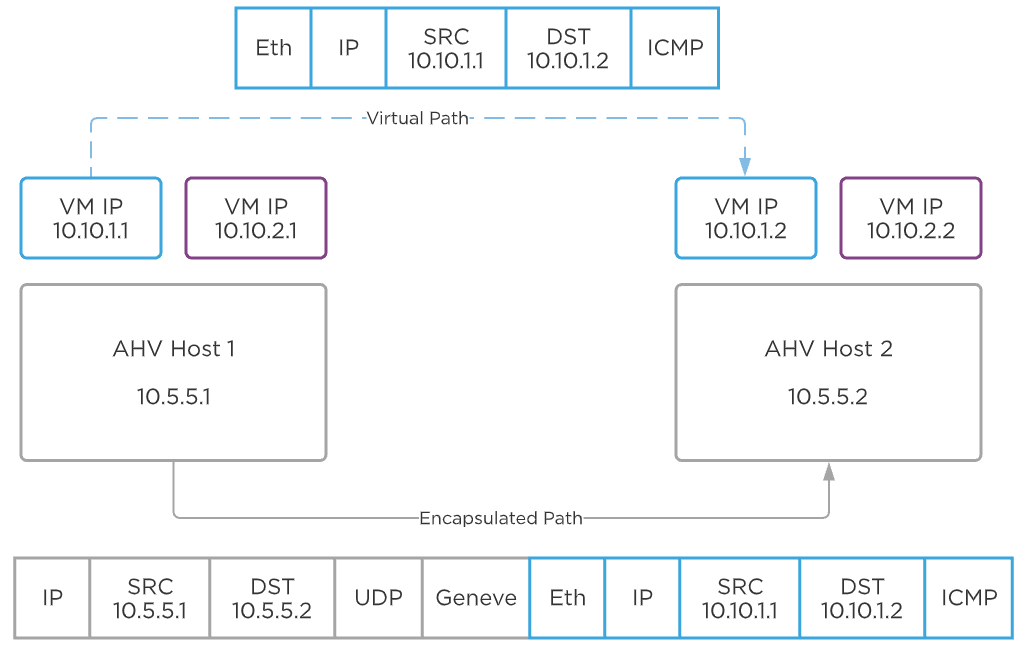
仮想マシンのNICを選択したときに、そのNICをオーバーレイサブネットまたは従来のVLANサブネットのどちらかに配置できます。 オーバーレイサブネットを選択した場合には、VPCも選択します。
プロからのヒント
それぞれの仮想マシンは、単一のVPCのみに配置できます。 仮想マシンは、VPCとVLANの両方に同時接続したり、異なる2つのVPCに同時接続したりすることはできません。
ルート(Routes)
全てのVPCには1つの仮想ルータが含まれており、いくつかの種類のルートが存在します:
- 外部ネットワーク(External Networks)
- 直接接続(Direct Connections)
- リモート接続(Remote Connections)
外部ネットワークは、VPC全体に対しての、0.0.0.0/0ネットワークプリフィックスのデフォルトの宛先である必要があります。 使用する外部ネットワークごとに、代替のネットワークプリフィックスルートを選択できます。 完全に隔離されたVPCにするために、デフォルトルートを選択しないことも選択できます。
直接接続されたルートは、VPC内のサブネットごとに作成されます。 Flow Virtual Networkingは、それぞれのサブネットの最初のIPアドレスを、そのサブネットのデフォルトゲートウェイとして割り当てます。 デフォルトゲートウェイとネットワークプリフィックスはサブネット構成によって決定され、直接変更することはできません。 同一VPCの同一ホスト上にあって、異なるサブネットにある2つの仮想マシン間のトラフィックは、ホスト内でローカルにルーティングされます。
VPN接続のようなリモート接続や外部ネットワークは、ネットワークプリフィックスのネクストホップの宛先として設定できます。
プロからのヒント
VPCルーティングテーブル内のそれぞれのネットワークプリフィックスは、一意である必要があります。 同じ宛先プリフィックスを持つ2つの異なるネクストホップ宛先は設定しないでください。
ポリシー(Policies)
仮想ルータは、VPC内のトラフィックの制御ポイントとして動作します。 ここでは、シンプルなステートレスポリシーを適用でき、ルータを通過する全てのトラフィックはそのポリシーで評価されます。 同じサブネット内では、ある仮想マシンから別の仮想マシンへのトラフィックは、ポリシーを通過しません。
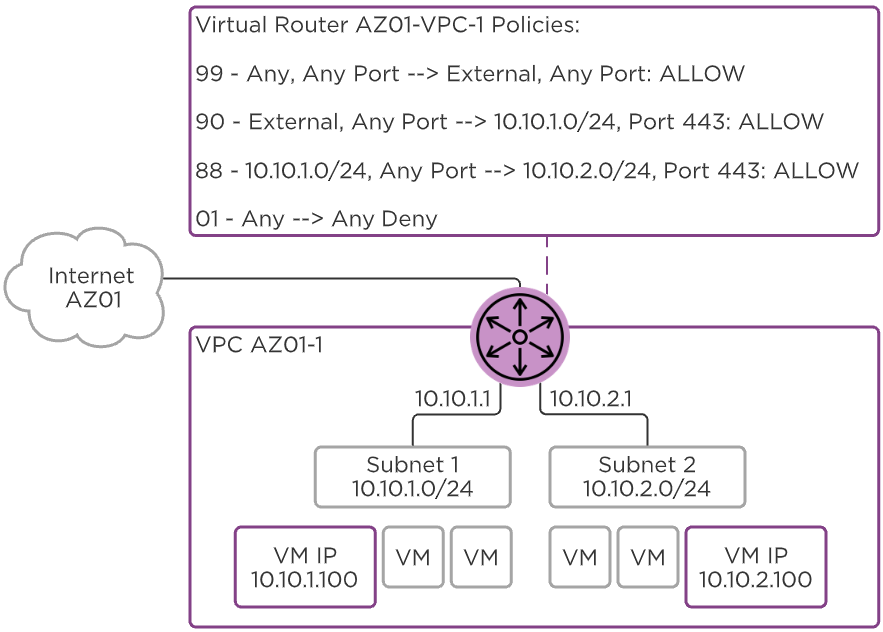
VPC内では、ポリシーは最高(1,000)から最低(10)の優先順位で評価されます。
次の値を基にトラフィックをマッチングします:
- 送信元または宛先のIPv4アドレス
- Any
- External(外部からVPCに流入する全てのトラフィック)
- Custom(IPプリフィックスを指定する)
- プロトコル
- Any
- Protocol Number
- TCP
- UDP
- ICMP
- 送信元または宛先のポート番号
トラフィックがマッチすると、ポリシーは次のアクションを実行できます:
- Permit
- Deny
- Reroute
- トラフィックを別のサブネットにある/32のIPv4アドレスにリダイレクトします。
reroute(Re-route)ポリシーは、全てのインバウンドトラフィックをロードバランサーや、VPCの別のサブネットで稼働しているファイアウォール仮想マシンを経由するルーティングを実行するようなことに非常に役立ちます。 これは、ネットワーク機能を提供する仮想マシン(NFVM: Network Function VM)がAHVホストごとに必要になる従来のサービスチェインと比較して、VPC内の全てのトラフィックに対してNFVMが1つのみ必要だという付加価値があります。
プロからのヒント
ステートレスポリシーでは、許可(Permit)ルールがドロップルールを上書きする場合、往復の両方向で個別のルールが必要です。 この場合、復路のトラフィックはドロップルールによって定義されます。 これらの対応する往路と復路のエントリーは、同じ優先度を使用してグループ化します。
外部ネットワーク(External Networks)
外部ネットワークは、VPCにトラフィックが出入りするための主な方法です。 外部ネットワークは、Prism Centralで作成され、そして単一のPrism Elementクラスタのみに存在します。 このネットワークはVLAN、デフォルトゲートウェイ、IPアドレスプール、そして全てのVPCが使用するNATの種類を定義します。 1つの外部ネットワークは、複数のVPCが利用できます。
外部ネットワークは2種類あります:
- NAT
- Routed(NoNAT)
PC.2022.1とAOS 6.1から、VPCでは最大2つの外部ネットワークが選択できるようになりました。 VPCは、最大で1つのNAT外部ネットワークと、最大で1つのRouted(NoNAT)外部ネットワークを持つことができます。 同一のVPCで2つのNAT、または2つのRouted外部ネットワークを構成することはできません。
NAT
NAT(Network Address Translation)外部ネットワークは、フローティングIPもしくはVPC SNAT(Source NAT)アドレスの背後にある、VPC内にある仮想マシンのIPアドレスを隠蔽します。 それぞれのVPCは外部ネットワークのIPプールからランダムに採番されたSNAT IPアドレスを持ち、VPCから出るトラフィックは、この送信元アドレスに書き換えられます。
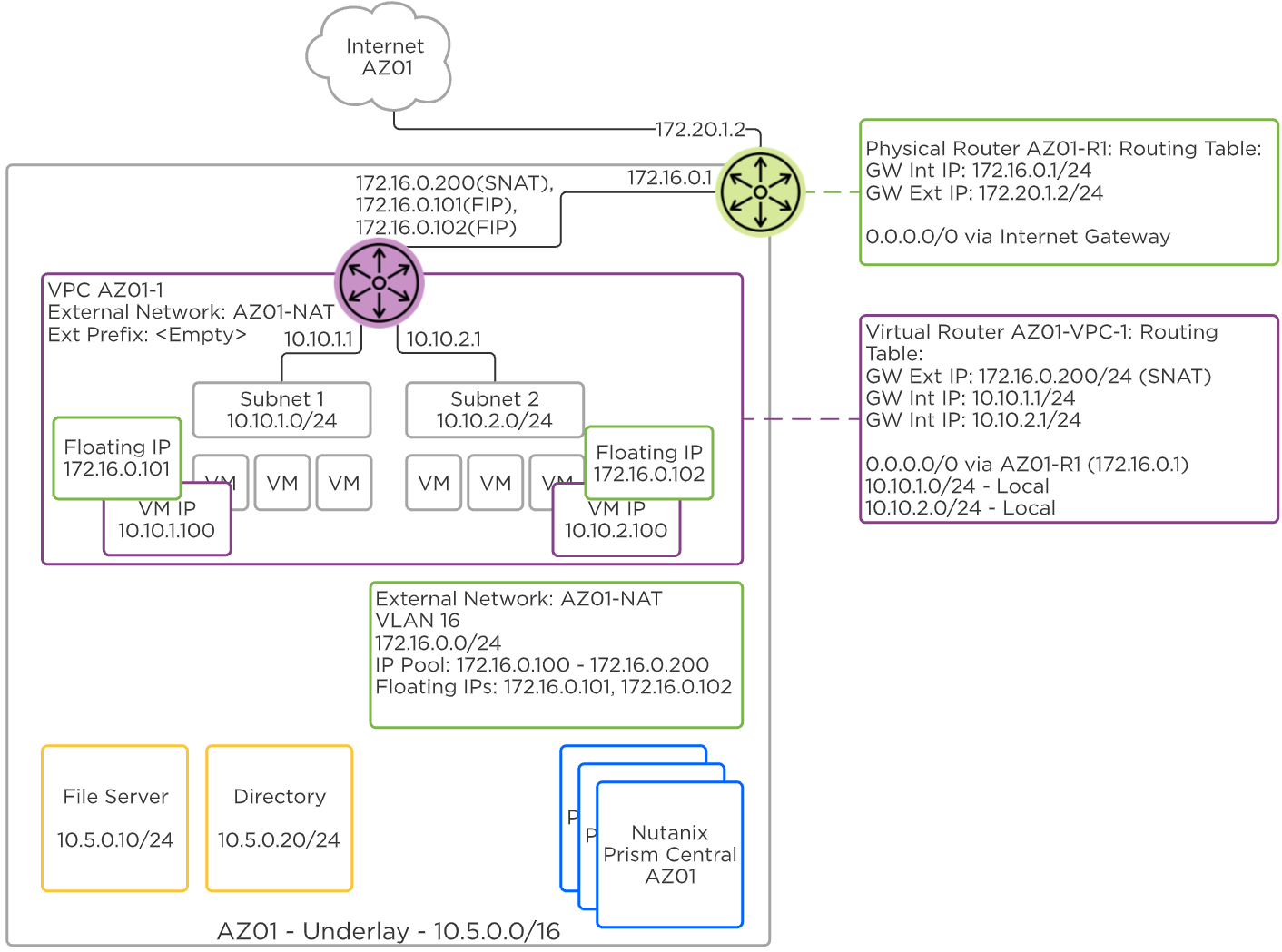
フローティングIPアドレスも、外部ネットワークのIPプールから採番され、入力トラフィックを許可するために、VPC内の仮想マシンに割り当てられます。 フローティングIPが割り当てられた仮想マシンは、出力トラフィックが、VPC SNAT IPの代わりにフローティングIPで書き換えられます。 これは、仮想マシンのプライベートIPアドレスを露出させることなく、VPCの外側にパブリックサービスを公開する際に役立ちます。
Routed
ルーティングされた(Routed)、もしくはNATなし(NoNAT)の外部ネットワークにより、ルーティングを介してVPC内で物理ネットワークのIPアドレス空間を共有できます。 VPC SNAT IPアドレスの代わりに、VPCルータIPが外部ネットワークのプールからランダムに採番されます。 このVPCルータIPを物理ネットワークのチームと共有することで、VPC内でプロビジョニングされた全てのサブネットに、仮想ルータIPをネクストホップとして設定できます。
例えば、外部ネットワークが10.5.0.0/24のVPCには、仮想ルータIPとして10.5.0.200を割り当てることができます。 VPC内のサブネットが10.10.0.0/16のネットワークで作成されている場合には、物理ネットワークチームは、10.5.0.200経由で10.10.0.0/16へのルートを作成します。 10.10.0.0/16のネットワークは、VPCの外部へルーティング可能なプリフィックスになります。
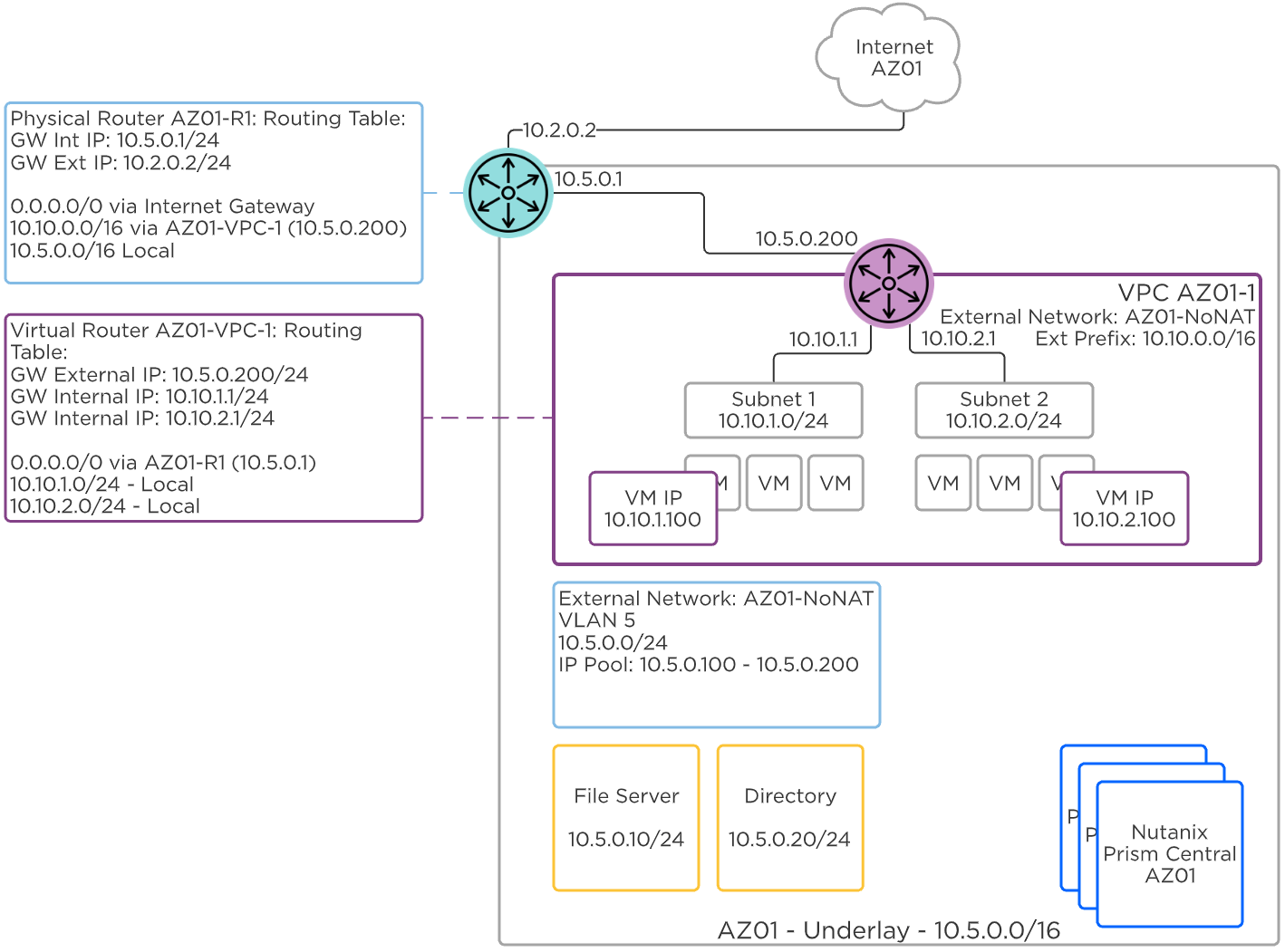
複数の外部ネットワーク
2つの外部ネットワークを持てることは、次のシナリオで役立ちます。
- 個別のルートを経由する内部および外部リソースへの接続。
- RoutedまたはNoNATを経由した内部または企業内リソース
- NATおよびフローティングIPを経由した外部サービスまたはインターネットサービス
-
VPC内のネットワークゲートウェイ仮想マシンにフローティングIPを提供します。
VPC内のネットワークゲートウェイには、フローティングIPが必要です。
- VPNネットワークゲートウェイ仮想マシン
- VXLAN VTEPネットワークゲートウェイ仮想マシン
- VPC内のBGPネットワークゲートウェイ仮想マシン
以下のVPCは、VPCルーティング テーブル「Virtual Router AZ01-VPC-1: Routing Table」が示すように、インターネットアクセス用のNATネットワークに接続されています。 すべてのインターネットに向かうトラフィック(0.0.0.0/0)は、AZ01-NAT外部ネットワークを経由してVPCから出ていきます。 このVPCはRoutedまたはNoNATの外部ネットワークにも接続されており、10.5.0.0/16宛のすべての内部トラフィックはAZ01-NoNAT外部ネットワーク経由で出ていきます。
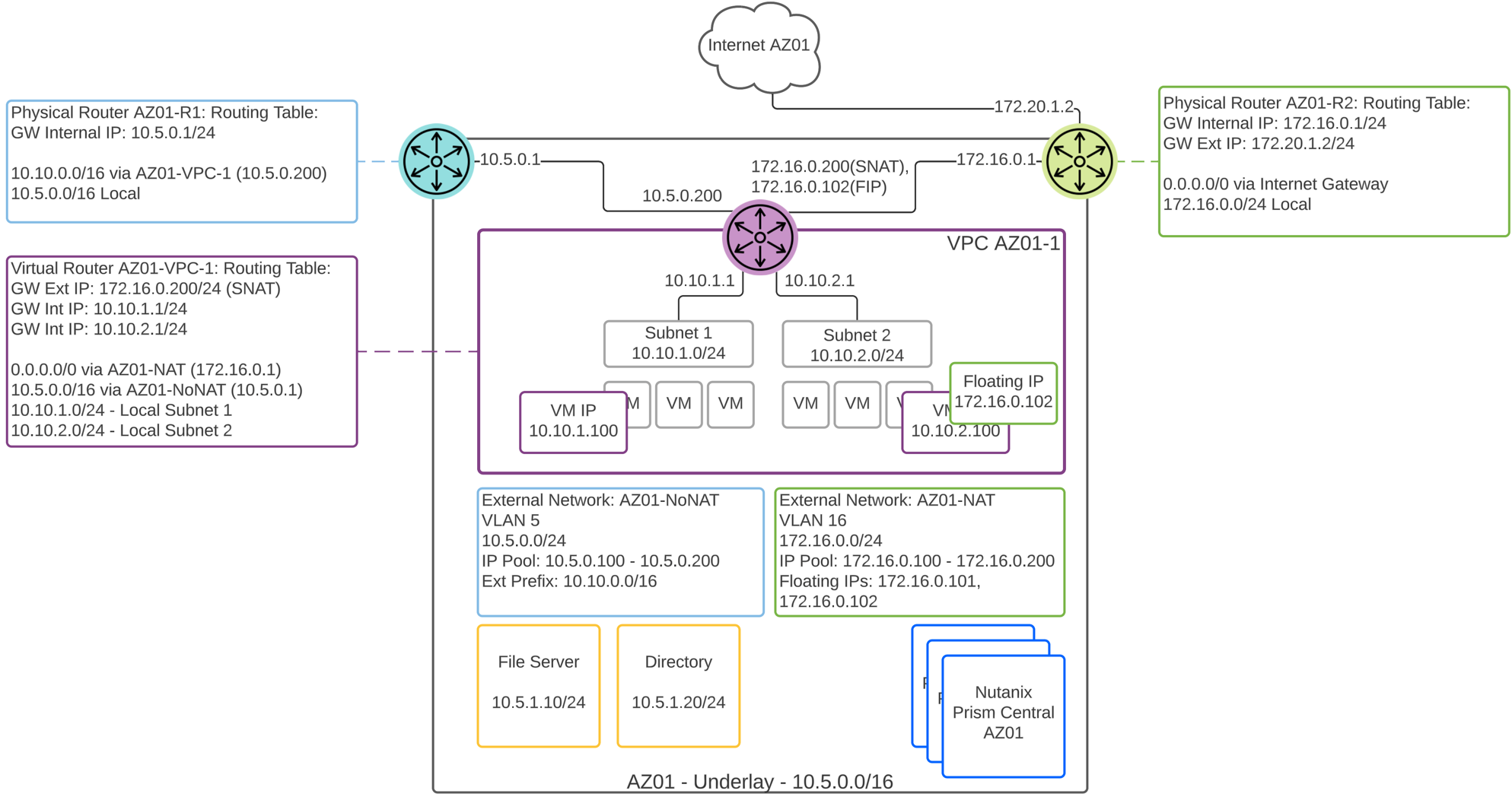
ネットワークゲートウェイ
ネットワークゲートウェイは、サブネット間のコネクタとして動作します。 これらのサブネットは、さまざまな種類と場所に配置できます。
- サブネットの種類
- ESXi VLAN
- AHV VLAN
- VPCオーバーレイ(VPC内のネットワークゲートウェイにはフローティングIPが必要です)
- 物理ネットワークのVLAN
- サブネットの場所
- オンプレミスのVLAN
- オンプレミスのVPC
- クラウドのVPC
ネットワークゲートウェイのサブネット接続には、いくつかの方法があります。
- レイヤー3 VPN
- ネットワークゲートウェイからネットワークゲートウェイ
- ネットワークゲートウェイから物理ファイアウォールまたはVPN
- レイヤー2 VXLAN VTEP
- ネットワークゲートウェイからネットワークゲートウェイ
- ネットワークゲートウェイから物理ルータまたはスイッチVTEP
- レイヤー2 VXLAN VTEP over VPN
- ネットワークゲートウェイからネットワークゲートウェイ
- BGP
- リモートBGPネイバーへの動的VPCサブネット アドバタイズメント
レイヤー3 VPN
レイヤー3 VPNによる接続タイプでは、別の2つのネットワークプリフィックスを持っている2つのサブネットが接続されます。 例えば、ローカルサブネットである10.10.1.0/24を、リモートサブネットである10.10.2.0/24に接続できます。 以下の図はNAT外部ネットワークを想定しており、VPN仮想マシンにはこのNATネットワークからフローティングIPが割り当てられています。
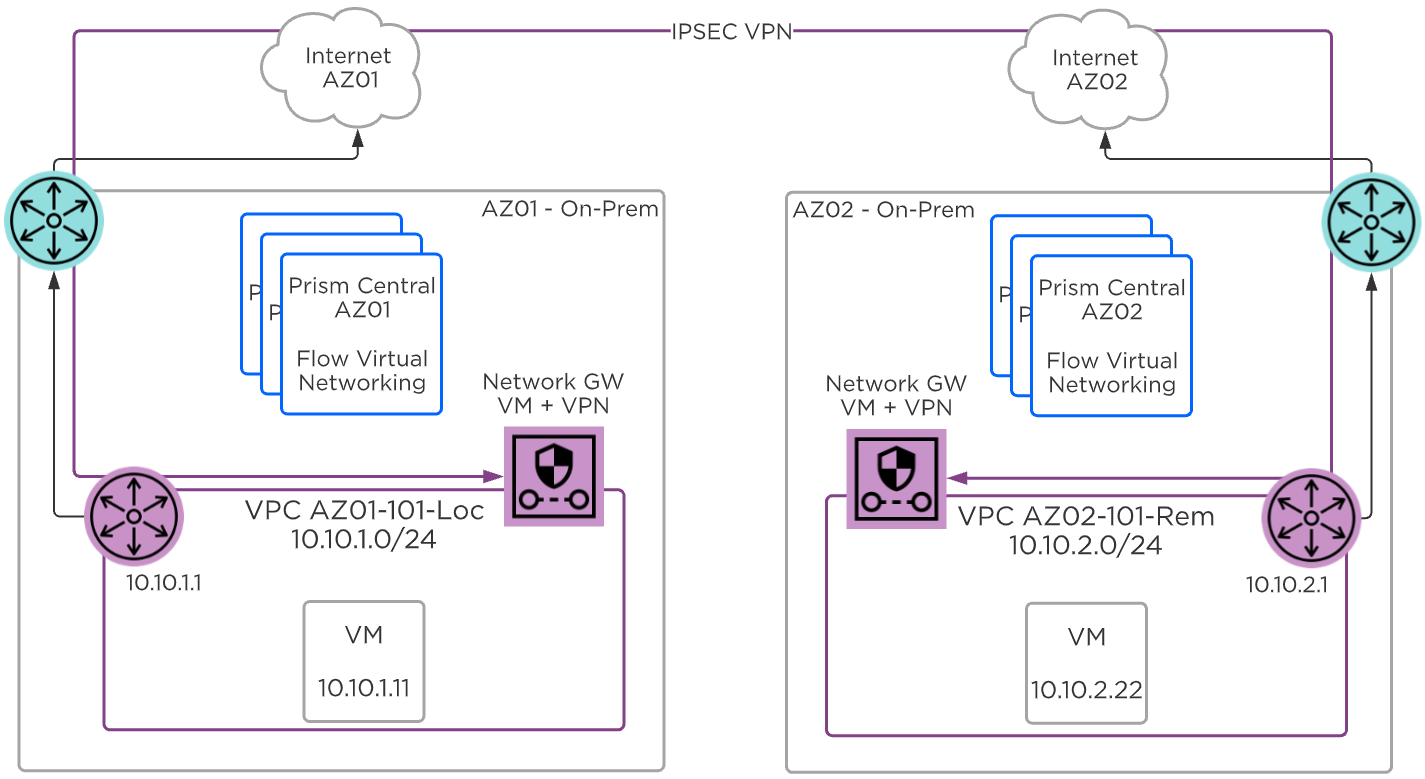
VPC内で2つのネットワークゲートウェイを使用する場合、それぞれのゲートウェイ仮想マシンにはNAT外部ネットワークDHCPプールから外部フローティングIPアドレスが割り当てられ、それらのアドレスを介して通信できる必要があります。 ネットワークゲートウェイがVLAN内にある場合、割り当てられたIPアドレスはリモートサイトから到達可能である必要があります。
ネットワークゲートウェイ仮想マシンを、リモートの物理ファイアウォール、またはVPNアプライアンスまたは仮想マシンに接続することもできます。 ローカルのネットワークゲートウェイは、リモートの物理アプライアンスまたは仮想アプライアンスと常に通信できる必要があります。
それぞれのサブネットからリモートサブネットへのトラフィックは、VPC内のIPルーティングを使用して作成されたVPN接続を介して転送されます。 ルートは静的に設定することも、BGPを使用してネットワークゲートウェイ間で共有することもできます。 このVPNトンネル内のトラフィックは、IPsecで暗号化されます。
プロからのヒント
サブネット間のトラフィックがインターネットのようなパブリックリンクを経由する場合は、IPsec暗号化でのVPNを使用します。
NATのレイヤー3 VPNについての詳細
以下の図は、NAT外部ネットワークで2つのVPC間を接続するVPNネットワークゲートウェイ仮想マシンに割り当てられた、インターフェイスとアドレスの詳細を示しています。
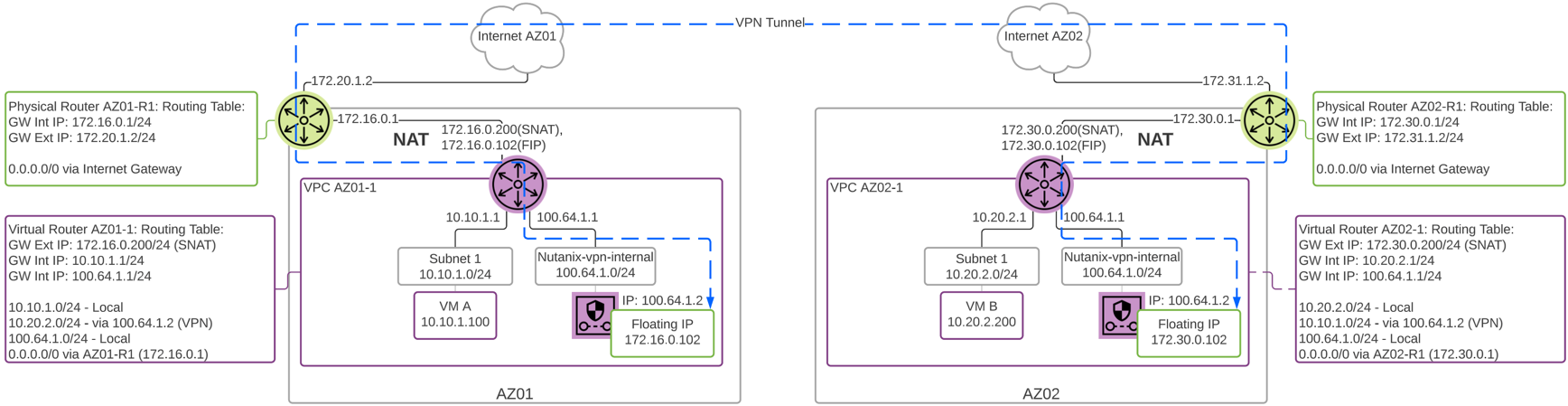
VPNゲートウェイ仮想マシンがデプロイされると、100.64.1.0/24オーバーレイ ネットワーク内の新しい内部サブネットが自動作成されることに注目してください。 この仮想マシンは、NAT外部ネットワークプールからフローティングIPを予約します。 VPC内のルーティングテーブルには特に注意してください。 リモートサブネットへのトラフィックは、VPN接続を経由してルーティングされます。
RoutedまたはNoNATのレイヤー3 VPNについての詳細
以下の図は、ルーティングされた外部ネットワークがVPCに接続されている場合の、インターフェイスの詳細について示しています。 この場合は、VPN仮想マシンのフローティングIPにNAT外部ネットワークを提供するには、複数の外部ネットワークが必須です。
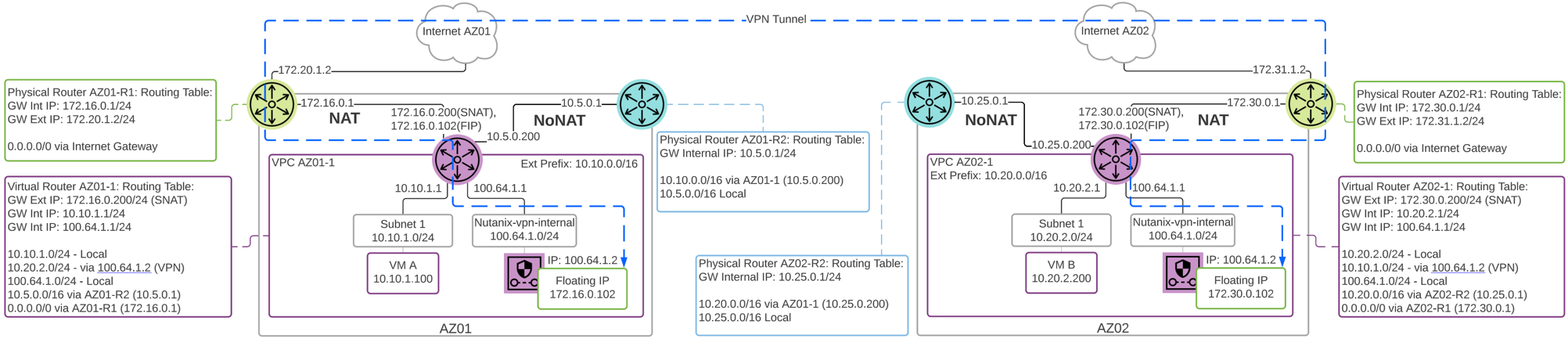
この場合のAZ01-1およびAZ01-2のVPCルーティングテーブルには、NATネットワークへのデフォルトルートと、プライベートな内部のRoutedまたはNoNATネットワークへのさらに個別のルートが含まれています。 VPNトンネルのトラフィックは、NAT外部ネットワークを通過してリモートサイトに到達します。
レイヤー2 VXLAN VTEPサブネット延伸
レイヤー2 VXLAN VTEPの場合はサブネット延伸と呼ばれ、同じネットワーク プリフィックスを共有する2つのサブネットが接続されます。 例えば、ローカル オーバーレイ サブネットの10.10.1.0/24が、同じく10.10.1.0/24を使用するリモート オーバーレイ サブネットに接続されます。
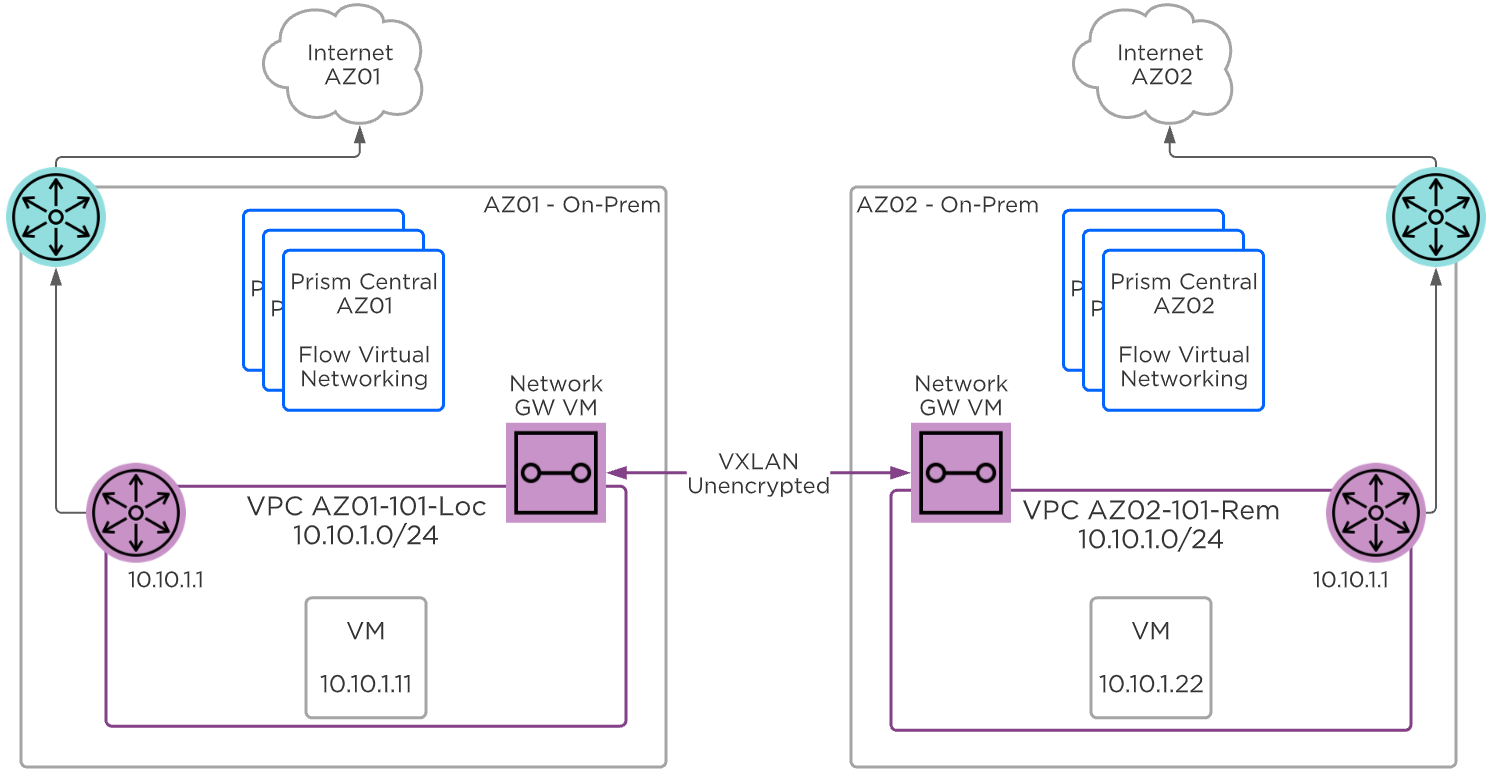
2つのネットワークゲートウェイ仮想マシンを使用して2つのVPCを接続する場合、各VPN仮想マシンには外部フローティングIPアドレスが割り当てられ、2つのVPN仮想マシンはこれらのアドレスを介して通信できる必要があります。 したがって、レイヤー2サブネット延伸を使用するVPCには、通信可能なフローティングIPを持つNAT外部サブネットが必要です。 RoutedまたはNoNATの外部サブネットのみを使用するVPCのサブネット延伸を実施している場合は、NAT外部サブネットをVPCに追加する必要があります。
レイヤー2サブネット延伸の詳細図(NAT)
次の図は、NAT外部サブネットを持つ2VPC間のサブネット延伸に使用される、ネットワーク ゲートウェイ仮想マシンのインターフェイスの詳細を示しています。 サブネット延伸のためのネットワーク ゲートウェイ仮想マシンは2つのインターフェイスを持ち、1つのインターフェイスは内部100.64.1.0/24オーバーレイ サブネット、もう1つのインターフェイスは拡張されるオーバーレイ サブネットのものです。 ネットワーク ゲートウェイ仮想マシンのフローティングIPアドレスは、100.64.1.0/24内部インターフェイスに割り当てられます。 サブネット延伸は、2つのネットワーク間に仮想ケーブルを差し込むようなものと考えられます。 ネットワーク ゲートウェイ仮想マシンは、ターゲット サブネット内のインターフェイスとのレイヤー2ブリッジとして機能します。
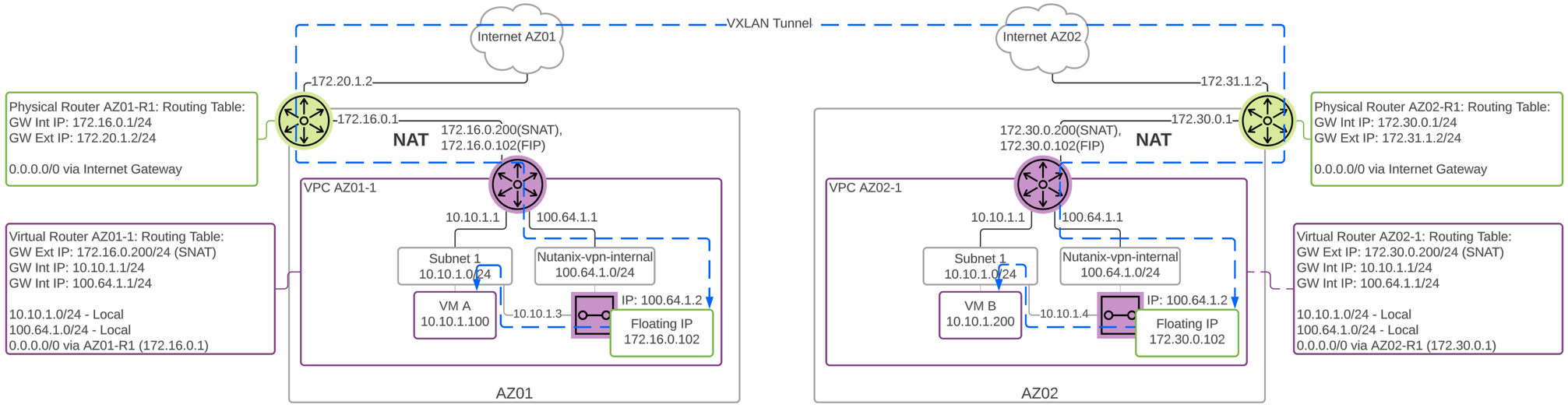
レイヤー2サブネット延伸の詳細図(RoutedまたはNoNAT)
次の詳細な図は、Routed VPCでのサブネット延伸に必要なRoutedサブネットとNATサブネットの両方を示しています。 トラフィックが適切なエンドポイントに確実に送信されるように、Routedネットワークとサブネット延伸については慎重な計画が必要です。 この例では、AZ1の10.10.1.0/24オーバーレイ サブネットから10.20.2.0/24宛てのトラフィックは、サブネット延伸ではなく物理的なNoNATネットワークを経由してルーティングされます。 AZ2の10.10.1.0/24から10.20.2.0/24宛てのトラフィックは、代わりにNutanixの仮想ルーターを経由してルーティングされます。 サブネット延伸を使用する場合は、これらのルーティング経路を考慮してください。
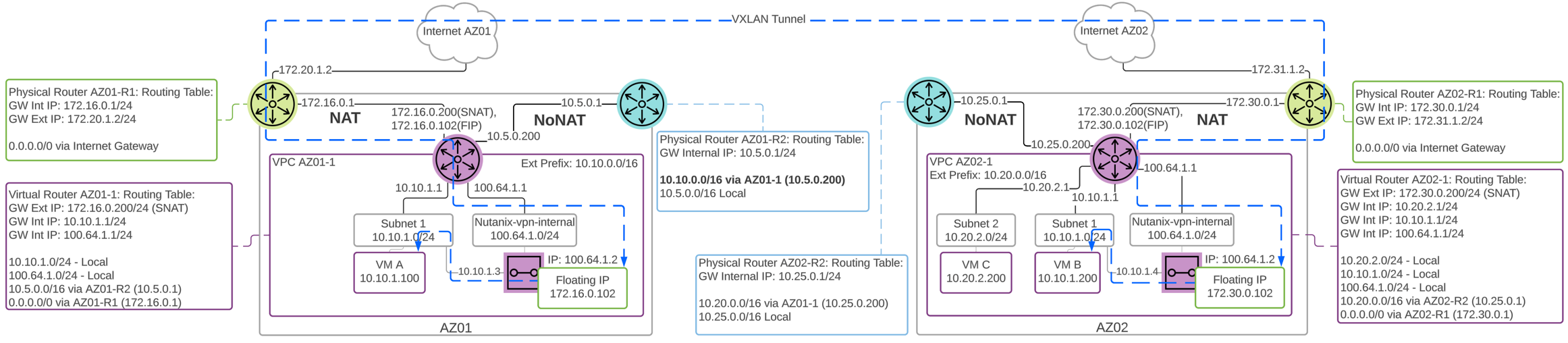
レイヤー2 サブネット延伸 物理デバイス
ローカルのネットワークゲートウェイは、物理スイッチなどのリモートにある物理VXLAN VTEP終端デバイスに接続することもできます。 物理デバイスは、Cisco、Arista、Juniperなどの一般的なベンダーの標準的なVXLANデバイスが利用できますが、これらに限定されません。 VXLAN VTEP接続には、リモート物理デバイスのIPアドレスを入力するだけです。
ローカルサブネットからリモートサブネットへのトラフィックは、レイヤー2スイッチ経由で交換され、暗号化されていないVXLANにカプセル化されます。 それぞれのネットワークゲートウェイはソースMACアドレステーブルを維持し、ユニキャストまたはフラッディングされたパケットをリモートサブネットに転送します。
プロからのヒント
トラフィックが暗号化されないため、VXLAN TEPはトラフィックがプライベートもしくはセキュアなリンクを通過する場合のみ使用します。
レイヤー2 VXLAN VTEP over VPN
セキュリティを強化するために、VXLAN接続は、既存のVPN接続でトンネリングすることで暗号化できます。 このケースでは、ネットワークゲートウェイ仮想マシンがVXLANとVPN接続を提供するので、ネットワークゲートウェイ仮想マシンがローカルとリモートの両方のサブネットに必要です。
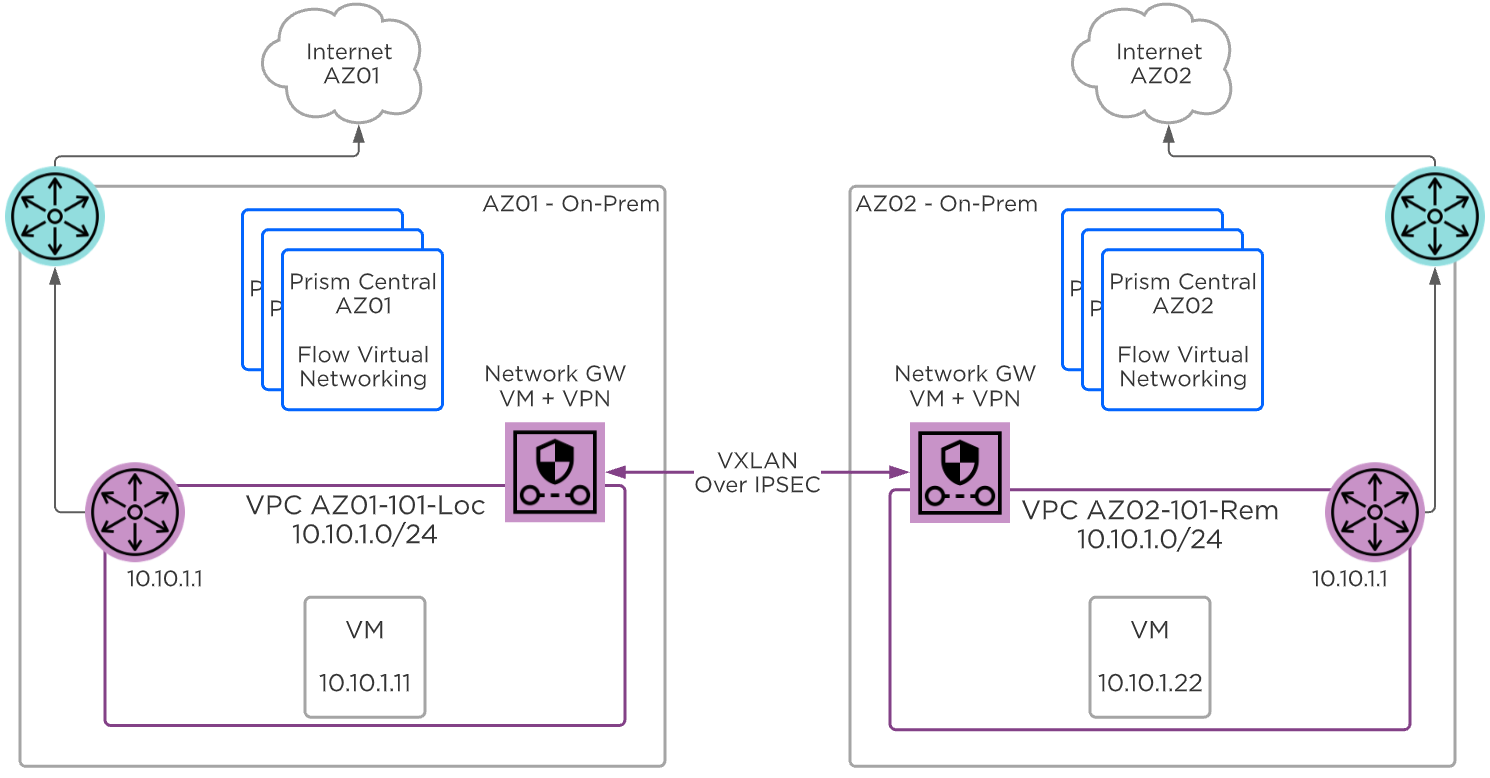
BGPゲートウェイ
BGPゲートウェイは、VPCと外部BGPピア間のルーティング情報の交換を自動化します。 VPCに、RoutedまたはNoNATの外部ネットワークと、NATを使用せずに外部ネットワークとの通信が必要なIPアドレス空間のオーバーレイ サブネットがある場合は、BGP ゲートウェイを使用し、この通信には動的なアドレス アドバタイズメントが必要になります。 Flow Virtual Networking の他のネットワーク ゲートウェイ オプションとは異なり、BGP ゲートウェイはデータ パス内にありません。 このゲートウェイはコントロール プレーンの一部です。
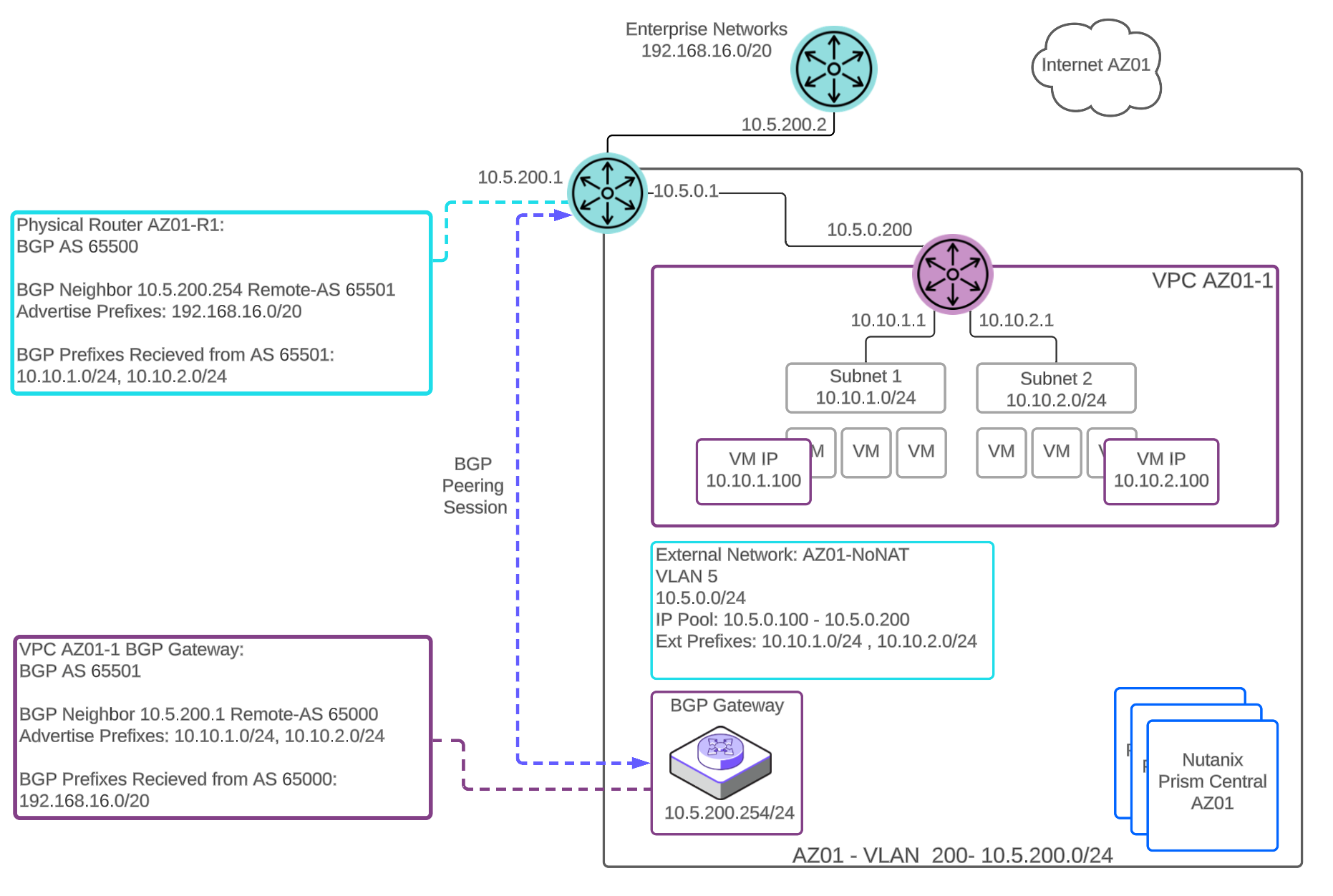
BGPゲートウェイの展開
BGPゲートウェイは、アンダーレイのVLANベースのネットワーク上か、オーバーレイ サブネットのVPC内にデプロイできます。
BGPゲートウェイは、アップストリームのインフラストラクチャー ルーターとのピアリング セッションを確立します。 ピアリング セッションは、設定されたルーティング可能なVPCサブネットの到達可能性をBGPネイバーにアドバタイズするために使用されます。 ゲートウェイは、最大20個のルーティング可能なプリフィックスをアドバタイズできます。 VPCのBGPゲートウェイからアドバタイズされるネクスト ホップは、RoutedまたはNoNAT、外部サブネットに接続されているVPCルーターのインターフェイスです。 ゲートウェイは、BGPピアごとに1つのセッションと、最大10個の一意のBGPピアをサポートします。
リモートBGPネイバーは、この到達可能性を残りのネットワークにアドバタイズします。 リモートBGPネイバーは、VPCのBGPゲートウェイへの外部ルートもアドバタイズします。 ゲートウェイは、BGPピアリング セッションごとに最大250のルートを学習してVPCルート テーブルにインストールできます。 ゲートウェイは、設定された外部ルーティング可能なIPアドレスをアドバタイズします。 これらのIPアドレスはCIDR形式で定義され、x.x.x.x/16からx.x.x.x/28のネットワークをサポートします。 これにより、サブネット全体またはネットワーク アドレスのより小さなサブセットをアドバタイズする柔軟性が提供されます。 ゲートウェイは設定された外部ピアからルートを学習し、それらのルートをVPCのルーティング テーブルにインストールします。
VLAN内のBGPゲートウェイ
BGPゲートウェイがVLANによるサブネットに展開されている場合、BGPピアにアクセスするためのIP到達可能性が必要です。 VPCはRoutedまたはNoNATの外部サブネットで構成され、BGPゲートウェイはVPCの仮想ルーターのネクストホップで、VPCの外部ルーティング可能なIPアドレスをアドバタイズします。
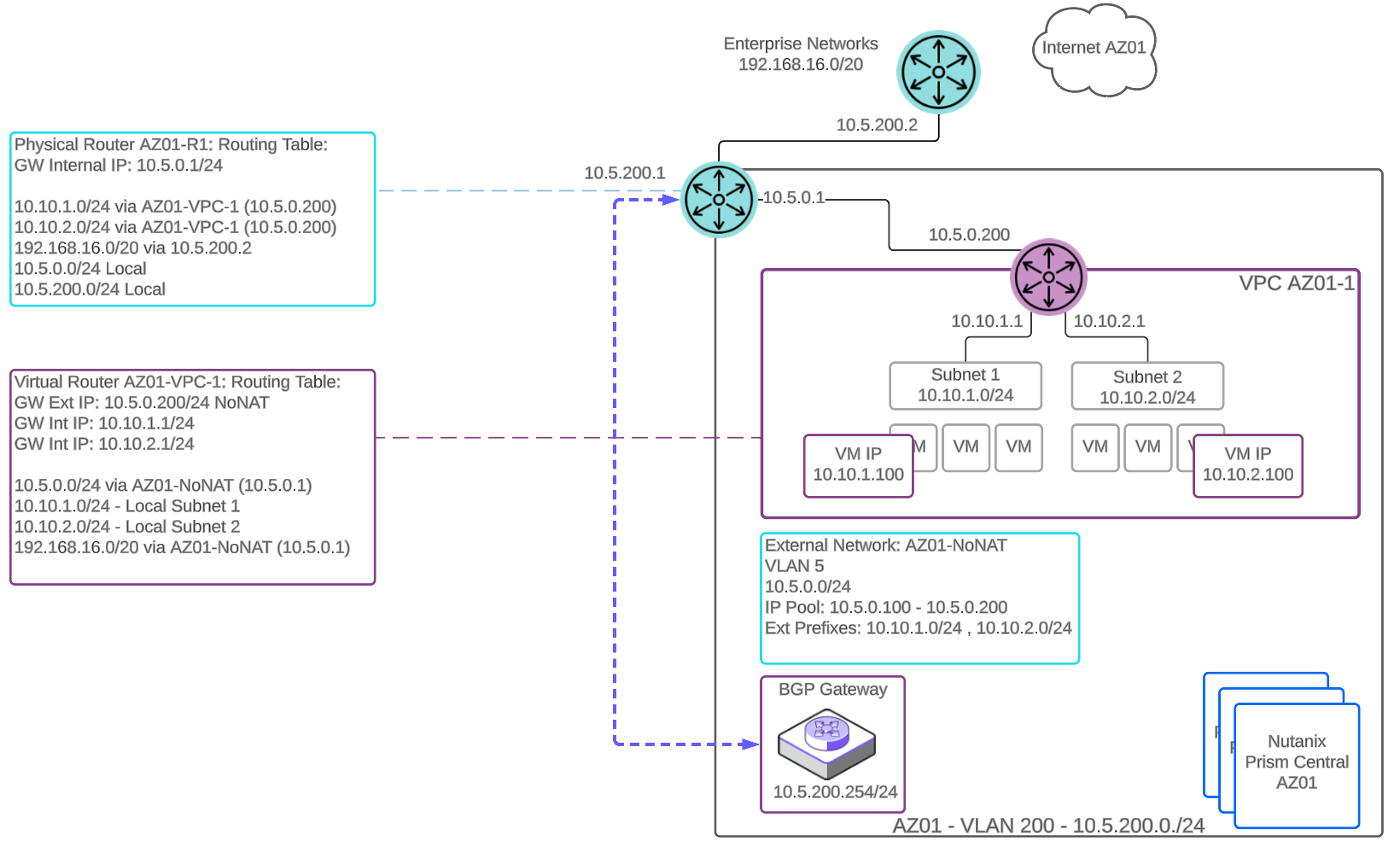
プロからのヒント
VLANによるアンダーレイ ネットワークにBGPゲートウェイを展開すると、NAT外部ネットワークやフローティングIP割り当ての要件がなくなるため、構成が容易になります。
オーバーレイ サブネットに展開されたBGPゲートウェイ
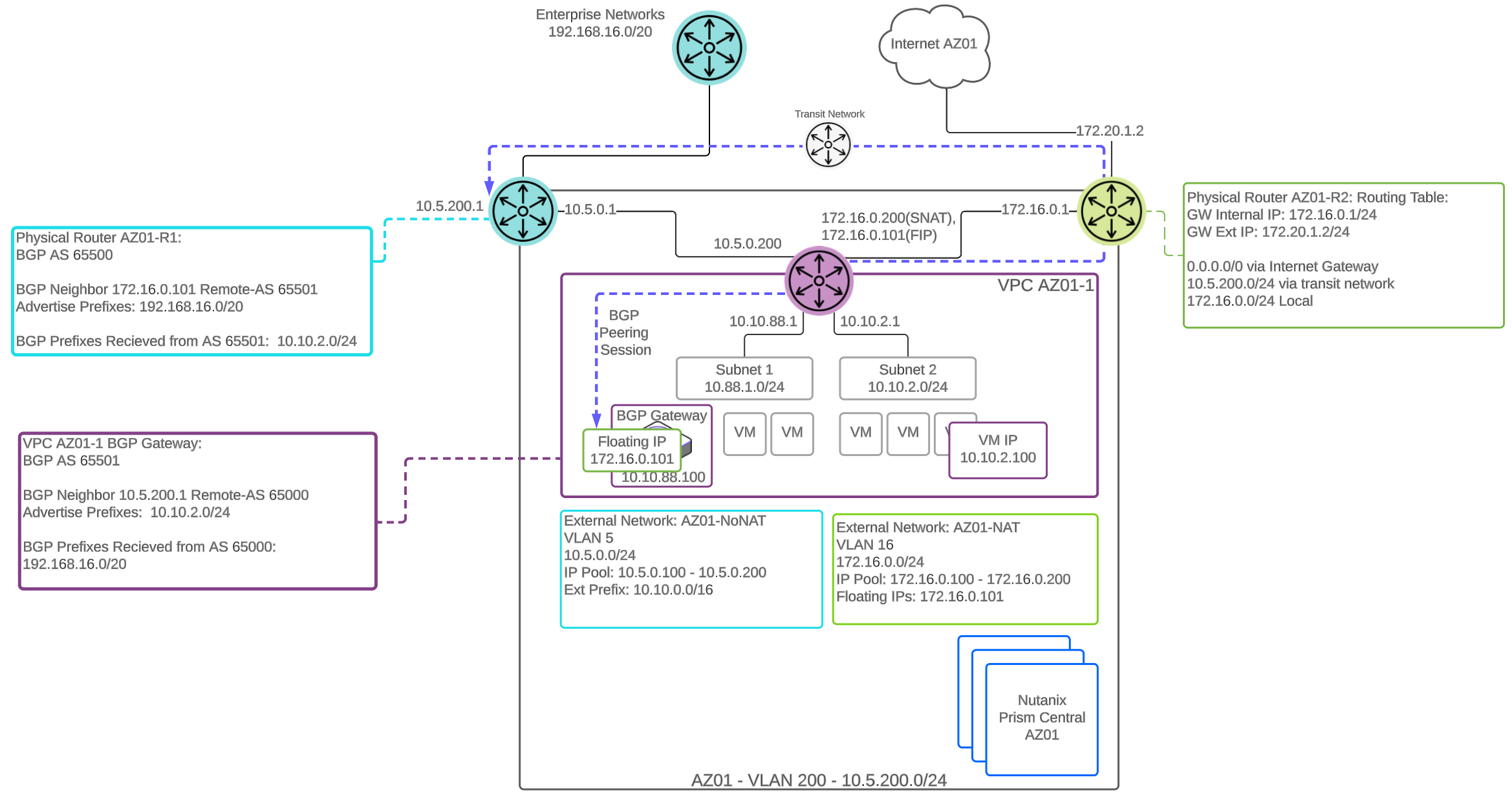
VPC内のオーバーレイ サブネットにBGPゲートウェイを展開するオプションもあります。 BGPゲートウェイをオーバーレイ サブネットに配置するには2種類の外部サブネットが必要であり、それはNoNatとNATのものです。 BGPゲートウェイには、NAT外部サブネット プールから割り当てられたフローティングIPアドレスが必要です。 ゲートウェイは、このフローティングIPアドレスを使用してリモート ネイバーとのBGPセッションを確立します。 これらのピアリング セッションは、NAT外部ネットワーク パスを経由してルーティングされます。
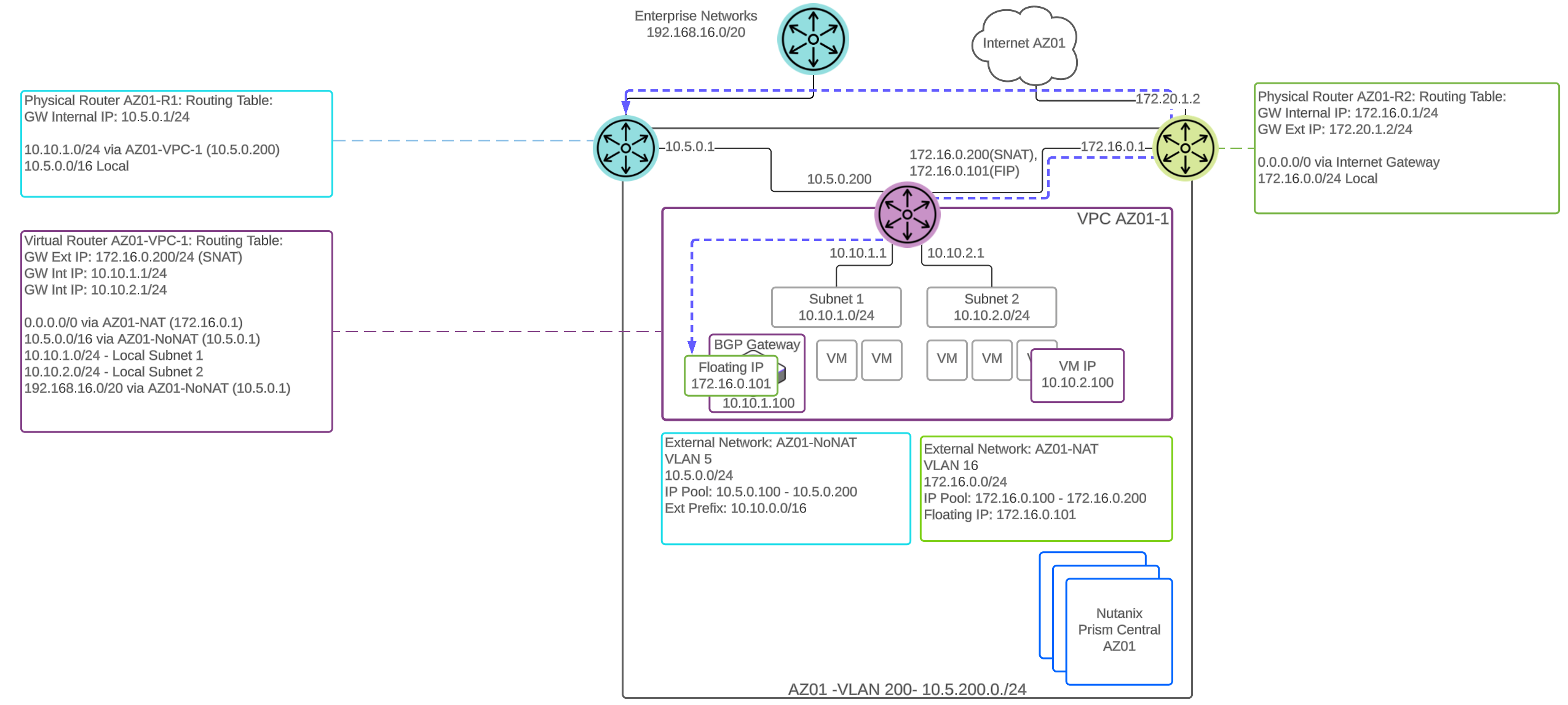
VPCのBGPゲートウェイからアドバタイズされるネクスト ホップは、NoNAT(Routed)外部サブネットに接続されているVPCルーターのインターフェイスです。 BGPネイバーから学習した宛先へのすべてのトラフィックは、NoNAT外部サブネット経由でVPCから出ます。
Hybrid Multicloud
Nutanix Cloud Clusters(NC2)
パブリッククラウドを活用するということは、アプリケーションとデータをオンデマンドで数分以内に拡張できるということを意味します。 Nutanix Cloud Clusters(NC2)では、単一の管理プレーンを使用してNutanixによるプライベートクラウドとパブリッククラウドのリソースの両方が同じPrismインターフェイスで管理できるようになり、シームレスな体験になります。
本書では、アーキテクチャー、ネットワーキング、ストレージ、そしてNC2の稼働についてのその他の側面について、技術的な詳細について解説します。
NC2は、現在はAWSとAzure、そしてGoogle Cloud上でサポートされています。
チャプター
- Nutanix Cloud Clusters on AWS
- Nutanix Cloud Clusters on Azure
Nutanix Cloud Clusters on AWS
Based on: PC 2024.2 | AOS 6.10 LTS
Nutanix Cloud Clusters (NC2) on AWSは、ターゲットクラウド環境のベアメタル リソースで実行される、オンデマンドのクラスタを提供します。 これにより、ご存知のNutanixプラットフォームのシンプルさで、真のオンデマンドな収容能力を実現できます。 プロビジョニングされたクラスタは従来のAHVクラスタのように見えますが、クラウド プロバイダーのデータセンターで実行されています。
サポートされる構成
このソリューションは以下の構成に適用できます(このリストはおそらく不完全であり、完全なサポートされている構成のリストについては、ドキュメントを参照してください):
-
主なユースケース:
- オンデマンド / バースト容量
- バックアップ / DR
- クラウド ネイティブ
- 地理的拡張 / DC統合
- アプリケーションのマイグレーション
- その他
-
管理インターフェイス:
- Nutanix Cloud Clusters Portal - プロビジョニング
- Prism Central(PC) - Nutanixの管理
- AWS Console - AWSの管理
- EC2ベアメタル インスタンスの種類:
- m5d.metal
- z1d.metal
- i3en.metal
- g4dn.metal
- i4i.metal
- m6d.metal
- i7i.metal-48xl
- i7ie.metal-48xl
-
アップグレード:
- AOSの一部
-
互換性のある機能:
- AOSの機能
- AWSのサービス
主な用語/構造
このセクションでの用語は、以下のように定義されています。
- Nutanix Cloud Clusters Portal
- Nutanix Cloud Clusters Portalは、クラスタのプロビジョニング リクエストの処理を受け持ち、AWSやプロビジョニングされたホストとのやりとりを行います。 クラスタ個別の詳細設定を作成し、動的なCloudFormationスタックの作成を処理します。
- リージョン
- 複数のアベイラビリティ ゾーン(サイト)が配置されている地理的な土地または地域です。 リージョンには2つ以上のAZを含めることができます。 これらには、US-East-1やUS-West-1などのリージョンを含めることができます。
- アベイラビリティ ゾーン(AZ)
- AZは、低遅延リンクで相互接続された、1つ以上の個別のデータセンターで構成されます。 各サイトは、独自の冗長電源、冷却システム、ネットワークを持ちます。 AZは複数の独立したデータセンターで構成できるため、これらを従来のコロケーションやデータセンターと比較すると、より回復力があると見なされます。 これらには、US-East-1aやUS-West-1aなどのサイトを含めることができます。
- VPC
- テナント向けの、AWSクラウドの論理的に隔離されたセグメントです。 環境を他からセキュアに隔離するための仕組みを提供します。 インターネットや、他のプライベート ネットワーク セグメント(他のVPCやVPN)に公開できます。
- S3
- S3 APIを介してアクセスされる永続オブジェクト ストレージを提供するAmazonのオブジェクトサービスです。 これはアーカイブやリストアに使用されます。
- EBS
- AMIに接続できる永続的なボリュームを提供するAmazonのボリューム/ブロック サービスです。
- CloudFormation Template (CFT)
- Cloud Formation Templateはプロビジョニングを簡素化しますが、リソースと依存関係の「スタック」を定義できます。 このスタックは、個々のリソースごとではなく、全体としてプロビジョニングできます。
クラスタのアーキテクチャー
Nutanix Cloud Clusters Portalは、概観的にいうとNC2 on AWSをプロビジョニングし、AWSと対話するためのメイン インターフェイスです。
プロビジョニング手順は、おおまかに下記のステップとして要約できます。
- NC2 Portalでクラスタを作成する
- 個別入力の展開(例えば、リージョン、AZ、インスタンスの種類、VPC/サブネットなど)
- NC2 Portalが、関連するリソースを作成する
- Nutanix AMIのHost agentが、Nutanix Cloud Clusters on AWSにチェックインする
- すべてのホストが起動すると、クラスタが作成される
以下は、NC2 on AWSの相互作用における概要を示します:
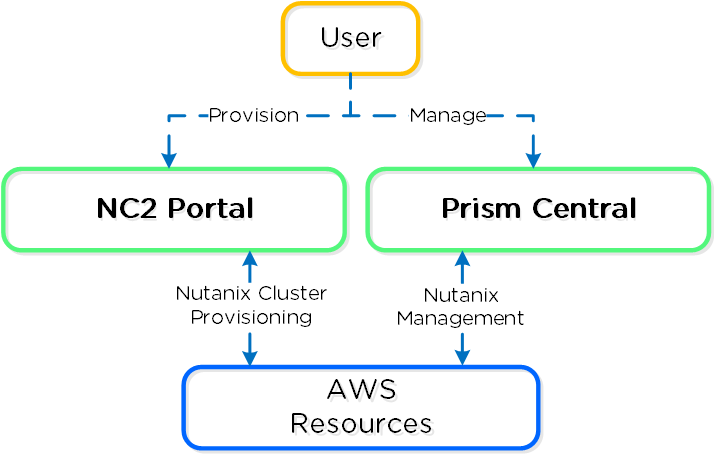
以下は、NC2 Portalによる入力と、作成されるリソースの概要を示します:
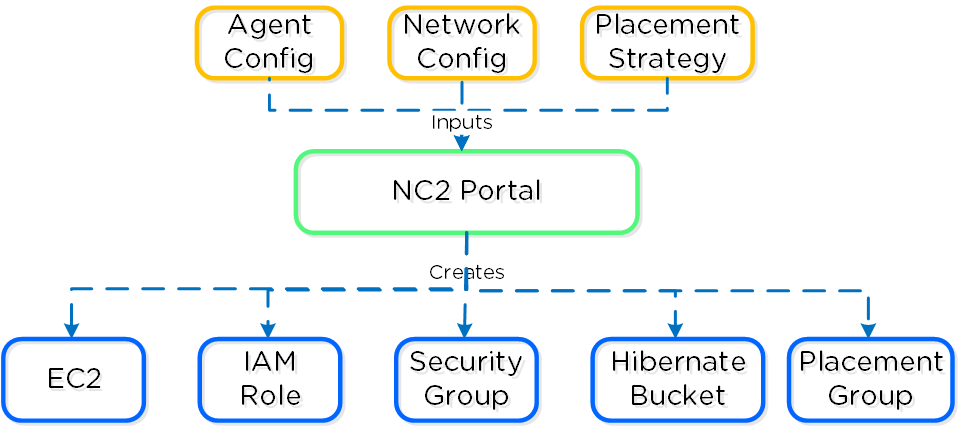
以下は、AWSでのノードの概要を示します:
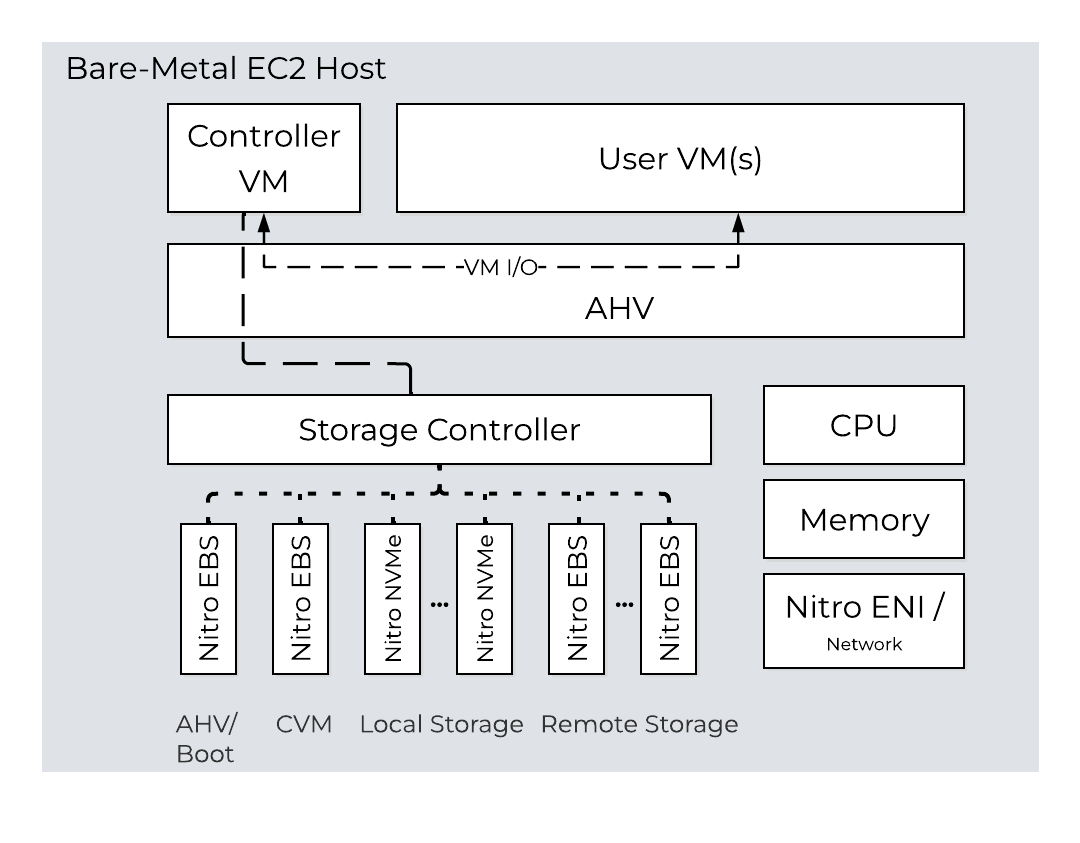
Nutanix Cloud Clusters on Amazon Web Servicesのストレージ
NC2のプライマリ ストレージは、ローカル接続されたNVMeディスクから提供されます。 ローカル接続されたディスクは、CVMがデータを永続化するために使用する最初の層です。 各AWSノードは、ベアメタル ノードに接続された2つのAWS Nitro EBSボリュームも消費します。 これらのEBSボリュームの1つはAHVに使用され、もう1つはCVMに使用されます。
NC2 PortalでNC2インスタンスをプロビジョニングする際、クラスタ内の各ベアメタル ノードにリモート ストレージとして、さらにNitro EBSボリュームを追加することができ、ビジネスニーズに合わせてベアメタル ノードを追加せずにストレージを拡張できます。 クラスタを最初にNitro EBSボリュームで作成した場合も、後からNitro EBSボリュームを追加できます。
ホストがベアメタルであるため、通常のオンプレミス展開と同様に、ストレージとネットワークのリソースを完全に制御できます。 CVMおよびAHVホストのブート領域では、EBSボリュームが使用されます。
注: EBSなどの特定のリソースとのやりとりは、AHVホストでNVMeコントローラーとして認識されるAWS Nitroカードを介して実行されます。
クラスタにEBSボリュームを追加すると、それらはクラスタ全体に均等に追加されます。 総ストレージ容量は、追加できる最大ストレージ容量に関するAOSの制限(確認にはNutanix Portalの認証が必要)に従いますが、追加の制約として、最大ストレージ量がベアメタル ノードのローカル ストレージの20%を超えることはできません。 I4i.metalインスタンスを使用すると、30TBのローカルAWS Nitro NVMeベースのストレージを持つため、スナップショットを使用して他の80%を利用することで、現在のAOSノードの制限に達することができます。
NC2 Portalでは、初期展開時には小容量のEBSストレージを追加し、後からさらに追加できます。 災害復旧のユースケースでNC2を使用する場合、迅速な復旧が必要なTier-1ワークロードのストレージ使用量をカバーするために、小容量のEBSストレージを持つ3ノード クラスタを展開できます。 ニーズが変わった場合は、後からストレージをスケールアップすることができます。 フェイルオーバー時には、Prism CentralのプレイブックやNC2 Portalを使用して、3台のベアメタル ノードによって供給されなくなったRAM使用量をカバーするために、NC2ノードを追加できます。
Nutanixは、最小でもクラスタのリダンダンシー ファクター以上の数の追加ノードを保持することを推奨しています。 追加ノードについては、リダンダンシー ファクターの倍数でクラスタの拡張を実施してください。
Note:ストレージにEBSボリュームを使用する場合は、単一インスタンス タイプのクラスタのみを使用してください (すべてのノードが同じインスタンス タイプである必要があります)。
NC2 on AWSのデータ階層化プロセスは、オンプレミスのハイブリッド構成のプロセスと同じです。
配置ポリシー
Nutanixは、AWSのアベイラビリティ ゾーン内にノードをデプロイする際に、パーティション配置戦略をとります。 1つのNutanixクラスタが同じリージョン内の異なるアベイラビリティ ゾーンにまたがることはできませんが、異なるゾーンまたはリージョン内にある複数のNutanixクラスタで相互にレプリケーションを行うことはできます。 Nutanixは、最大で7つのパーティションを使用して、AWSベアメタル ノードを異なるAWSラックに配置し、新規ホストをパーティション全体にストライプ化します。
NC2 on AWSは、クラスタ内での異種ノード タイプの組み合わせをサポートしています。 1つのノード タイプのクラスタを展開し、そこに異種ノードを追加してクラスタの容量を拡張できます。 この機能は、元のノードタイプがリージョンで不足した場合に、オンデマンドでクラスタを拡張する柔軟性を提供できるようにします。 ストレージ ソリューションの適切なサイズを検討している場合にも、異種ノードのサポートにより、より多くのインスタンス オプションから選択できます。
NC2 on AWSでは、新規クラスタを作成する際や、稼働中の既存クラスタの容量を拡張する際に、i3.metal、i3en.metal、i4i.metalインスタンス タイプや、z1d.metal、m5d.metal、m6id.metalインスタンス タイプを組み合わせて使用できます。
NC2 on AWSでは、以下の条件に従って混在クラスタを作成することができます:
NC2 on AWSは、i3.metal、i3en.metal、i4i.metalインスタンスタイプや、z1d.metal、m5d.metal、m6id.metalインスタンス タイプの組み合わせをサポートしています。 AWSリージョンには、NC2 on AWSによってサポートされている、これらのインスタンス タイプが含まれている必要があります。 詳細については、Supported Regions and Bare-metal Instances を参照してください。
Note: g4dn.metalでは同種クラスタのみ作成可能であり、混在クラスタの作成には使用できません。
Nutanixは、追加ノードの最小数はクラスタのリダンダンシー ファクター(RF)以上を必要とし、クラスタの拡張についてはRFの倍数の追加ノードで実施することを推奨しています。 ノード数がRFの数で割り切れない場合は、警告が表示されます。
特定のノード、または以下に記載された互換性のあるノードの組み合わせで動作している元のクラスタで作成され、パワー オン状態のユーザー仮想マシン(UVM)は、クラスタに他のノードが追加された際に、異なるノード タイプ間でライブ マイグレーションを行うことはできません。 クラスタの拡張が成功した後、すべてのUVMを一度パワー オフし、その後パワー オンすることでライブ マイグレーションが可能になります。
z1d.metalが、クラスタの初期ノード タイプとして、または既存クラスタに追加された新規ノード タイプとして、混在クラスタ内に存在する場合。 i4i.metalがクラスタの初期ノード タイプであり、他の互換性のあるノードが追加された場合。 m6id.metalがクラスタの初期ノード タイプであり、他の互換性のあるノードが追加された場合。 i3en.metalがクラスタの初期ノード タイプであり、i3.metalノードが追加された場合。
クラスタ サイズが最大28ノードの上限内であれば、i3.metal、i3en.metal、i4i.metalインスタンス タイプや、z1d.metal、m5d.metal、m6id.metalインスタンス タイプの任意の数でクラスタを拡張または縮小できます。
Nutanixクラスタを構成すると、パーティション グループはNutanixのラック アウェアネス機能にマップされます。 AOSストレージは、クラスタ内の異なるラックにデータ レプリカを書き込み、ラックの障害または計画的なダウンタイムの際に、レプリケーション ファクタ2とレプリケーション ファクタ3の両方のシナリオにおいてデータが利用可能のままであることを保障します。
ストレージ
Nutanix Cloud Clusters on AWSのストレージは、次の2つの領域に分類できます:
- コア / アクティブ
- ハイバネーション(Hibernation)
コア ストレージは、Nutanixクラスタで期待するものとまったく同じであり、「ローカル」ストレージデバイスをCVMに接続して、Stargateで活用します。
インスタンスのストレージ
「ローカル」ストレージではAWSインスタンス ストアが使われており、 停電やノード障害が発生した場合の完全な復元力がなく、追加の考慮が必要になります。
例えば、停電またはノード障害が発生した場合、ローカルのNutanixクラスタでは、ストレージはローカル デバイスに永続化されており、ノードや電源がオンラインに戻ると復旧します。 AWSインスタンス ストアの場合、このケースには当てはまりません。
ほとんどの場合、AZ全体が電源を失うまたはダウンするという可能性は低いですが、 センシティブなワークロードの場合は、次のことをお勧めします:
- バックアップソリューションを活用してS3または永続性のあるストレージに保存する
- 異なるAZ / リージョン / クラウド(オンプレミスまたはリモート)にある、別のNutanixクラスタにデータを複製する
NC2 on AWSのユニークな機能の1つは、クラスタを「ハイバネート」状態にして、EC2コンピューティング インスタンスを停止している間もデータを永続化できることです。 これは、コンピューティング リソースが不要で、支払いを継続したくないが、データを永続化して後で復元できるようにしたいという場合に役立ちます。
クラスタがハイバネート状態になると、データはクラスタからS3にバックアップされます。 データがバックアップされると、EC2インスタンスが終了されます。 再開または復元の際には、新しいEC2インスタンスがプロビジョニングされ、データがS3からクラスタに読み込まれます。
ネットワーク
ネットワークは、いくつかの中核的な領域に分類できます:
- ホスト / クラスタのネットワーク
- ゲスト / UVMのネットワーク
- WAN / L3ネットワーク
ネイティブ対オーバーレイ
独自のオーバーレイ ネットワークを運用する代わりに、AWSサブネットでネイティブに運用することを決定しました。 これにより、プラットフォームで起動されているVMがパフォーマンス低下なくAWSサービスとネイティブに通信できるようになります。
NC2 on AWSは、AWS VPCにプロビジョニングされます。以下に、AWS VPCの概要を示します:
新規VPC対デフォルトVPC
AWSはデフォルトのVPCやサブネットなどを作成します。各リージョンには172.31.0.0/16のIPスキームを使用します。
企業のIPスキームに適合するサブネット、NATやインターネット ゲートウェイなどが関連付けられた、新規VPCを作成することを推奨します。 このことは、VPC(VPCピアリング)や既存のWANにネットワークを拡張する計画がある場合に重要です。 これはWAN上の他のサイトと同じように扱う必要があります。
Nutanix Cloud のネットワーク
Nutanixは、スタンドアロンで動作するネイティブ クラウド ネットワーキングまたはFlow Virtual Networkingを使用できるため、真のハイブリッド マルチクラウド体験を提供しており、これによりハイブリッド マルチクラウド全体と同じ運用モデルを維持しつつ、ネイティブ ネットワーキングの低オーバーヘッドを利用する選択肢が得られます。
ネイティブ ネットワーキング
NutanixがAWSネットワーキング スタックと統合されているため、NC2 on AWS上で展開された仮想マシンは、ネイティブネットワーキングを使用すると、すべてネイティブのAWS IPアドレスを受け取ります。 その結果、アプリケーションは、NC2 on AWS上に移行または作成された時点で、すぐにすべてのAWSリソースにフル アクセスできるようになります。 Nutanixのネットワーク機能がAWSのオーバーレイ上に直接配置されているため、追加のネットワーク コンポーネントが不要で、ネットワーク性能は高く保たれ、リソース消費も少なくなります。
ネイティブなネットワーク統合により、既存のAWS Virtual Private Cloud(VPC)にNC2を展開できます。 既存のAWS環境はすでに変更管理やセキュリティ プロセスを経ているため、NC2 on AWSがNC2 Portalと通信できるように許可するだけで済みます。 この統合により、クラウド環境のセキュリティを強化できます。
Nutanixは、ネイティブのAWS APIコールを使用して、ベアメタルのAmazon Elastic Compute Cloud(EC2)インスタンスにAOSをデプロイし、ネットワーク リソースを消費します。 各ベアメタルEC2インスタンスは、ENIを通じてその帯域幅で完全にアクセスでき、Nutanixをi3.metalインスタンスにデプロイする場合、各ノードは25Gbpsでアクセス可能です。 ENIは、VPC内の論理ネットワーキング コンポーネントであり、仮想ネットワークカードを表します。
ENIは、1つのプライマリIPアドレスと最大49のセカンダリIPアドレスを持つことができます。 AWSホストは、最大15個のENIがサポートされます。 新しいサブネットで仮想マシンを起動するたびにENIが消費されます。 あるサブネット内の特定のホストに49以上の仮想マシンが存在する場合には、NC2ホスト上で動作するネットワーク サービスが自動的にENIを追加して、そのワークロードをサポートします。
NC2インスタンスは、すべてのホストで設定されたAWSサブネットにアクセスできますが、起動されていない仮想マシンはENIを消費しません。 デプロイされたすべてのゲスト仮想マシンは、セカンダリIPアドレスを使用して直接AWSネットワークにアクセスします。
AWSにデプロイされたAHVホストは、管理トラフィック(AHVおよびCVM)とゲスト仮想マシン用にそれぞれ別のENIを持ち、これにより管理用とゲスト仮想マシン用に異なるAWSセキュリティ グループを設定できます。 AHVでは、ENIを使用することで、トップ オブ ラック スイッチへのネットワーク パス冗長化のために、追加のネットワーク高可用性を設定する必要がなくなります。
AHVでは、すべての仮想マシン ネットワークにOpen vSwitch(OVS)を使用しています。 仮想マシンのネットワークは、PrismまたはaCLIで構成でき、各vNICはtapインターフェイスに接続されます。 ネイティブ ネットワーキングでは、オンプレミスと同じネットワーキング スタックを使用します。 Flow Virtual Networkingでは、別のENIを使用してトラフィックをクラスタから外部に出すことができます。
以下の図は、OVSアーキテクチャーの概念図です。
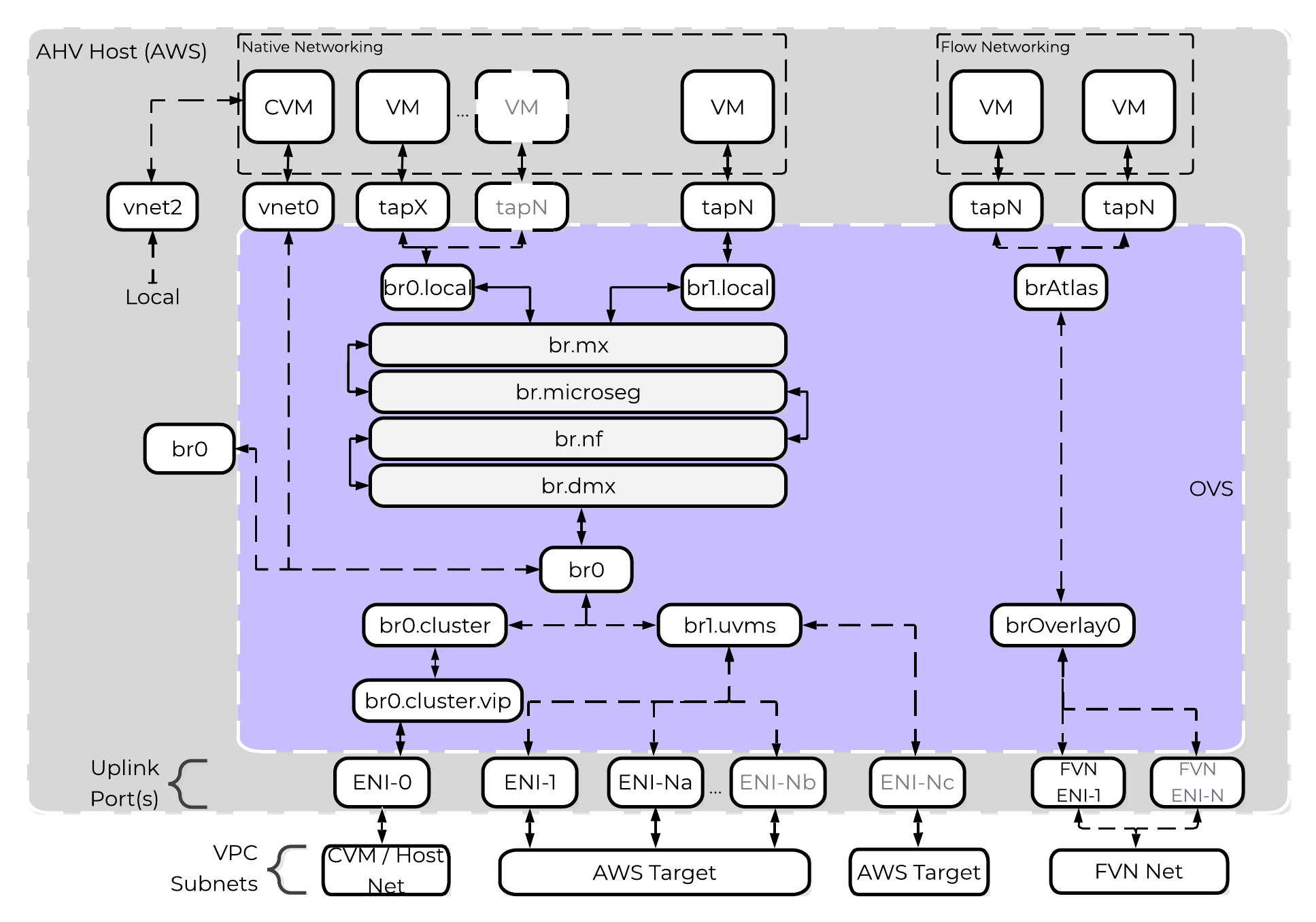
AHVホスト、仮想マシン、そして物理インターフェイスは、ポートを使用してブリッジに接続し、両方のブリッジはAWSオーバーレイ ネットワークと通信します。 各ホストには、AWSオーバーレイ ネットワークを使用するために必要なドライバが含まれています。
ネイティブなネットワーク統合により、既存のAWS VPCにNC2をデプロイできます。 既存のAWS環境では変更管理とセキュリティ プロセスが適用されるため、NC2 on AWSがNC2コンソールと通信できるようにすることのみが必要です。 この統合により、クラウド環境のセキュリティを強化できます。
NutanixはネイティブなAWS APIコールを使用して、ベアメタルEC2インスタンス上にAOSをデプロイし、ネットワーク リソースを利用します。 各ベアメタルEC2インスタンスはENIを介して帯域幅にフルアクセスできるため、Nutanixをi3.metalインスタンスにデプロイすることで、各ノードは最大25Gbpsまでアクセスできます。 ENIはVPC内の論理的なネットワーキング コンポーネントであり仮想ネットワーク カードを表し、各ENIは1つのプライマリIPアドレスと最大49のセカンダリIPアドレスを持つことができます。 AWSホストは最大15個のENIをサポートできます。
AWS上のNC2でデプロイされた場合、AHVは各ノードでリーダーレス サービスとしてCloud Network Controller(CNC)サービスを実行し、OpenFlowコントローラを実行します。 CNCはCloud Port Managerという内部サービスを使用して、ENIの作成と削除を行い、ENI IPアドレスをゲスト仮想マシンに割り当てます。
Cloud Port ManagerはAWSから大きなCIDR範囲をマッピングでき、AHVがその範囲全体または一部を利用できるようにします。 AWSサブネットとして10.0.0.0/24を使用し、その後AHVサブネットとして10.0.0.0/24を作成すると、Cloud Port ManagerはすべてのセカンダリIPアドレスがアクティブな仮想マシンによって消費されるまで、1つのENI(クラウド ポート)を使用します。 49個のセカンダリIPアドレスが使用されると、Cloud Port Managerは追加のENIをホストにアタッチし、このプロセスを繰り返します。 それぞれの新しいサブネットはホスト上の異なるENIを使用するため、多数のAWSサブネットをデプロイに使用すると、このプロセスによってENI枯渇が発生する可能性があります。
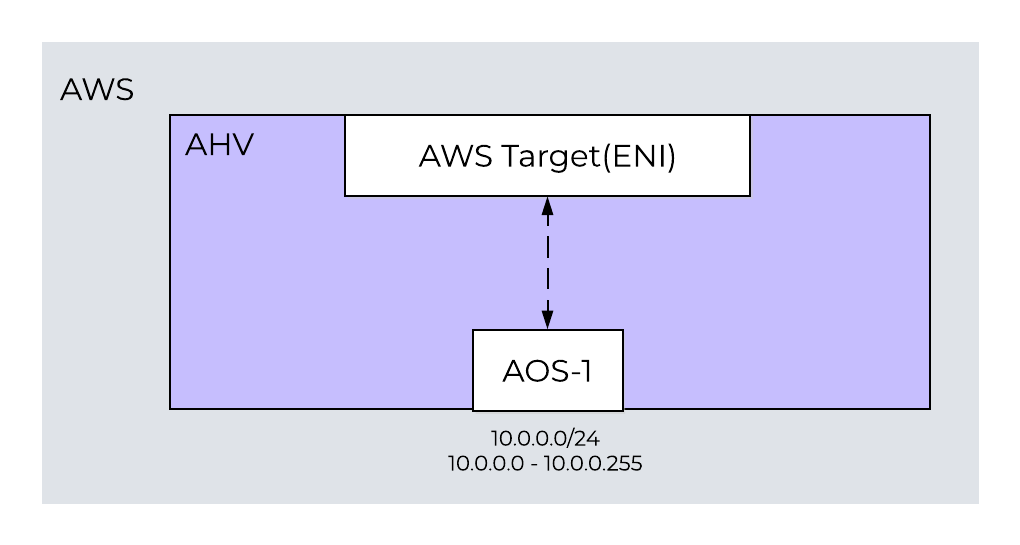
ENIの枯渇を防ぐためには、AWSのターゲットとして10.0.2.0/23のAWSサブネットを使用してください。 AHV側では、2つのサブネットとして10.0.2.0/24と10.0.3.0/24を作成します。 この構成により、Cloud Port ManagerはAHVのサブネット群を1つのENIにマッピングし、多数のサブネットを使用してもベアメタル ノード上のENIを枯渇させずに利用できます。 NC2クラスタは十分なENIが利用可能であれば複数のAWSサブネットを持つことができるため、スループット向上のために、任意のサブネットに専用のENIを割り当てられます。
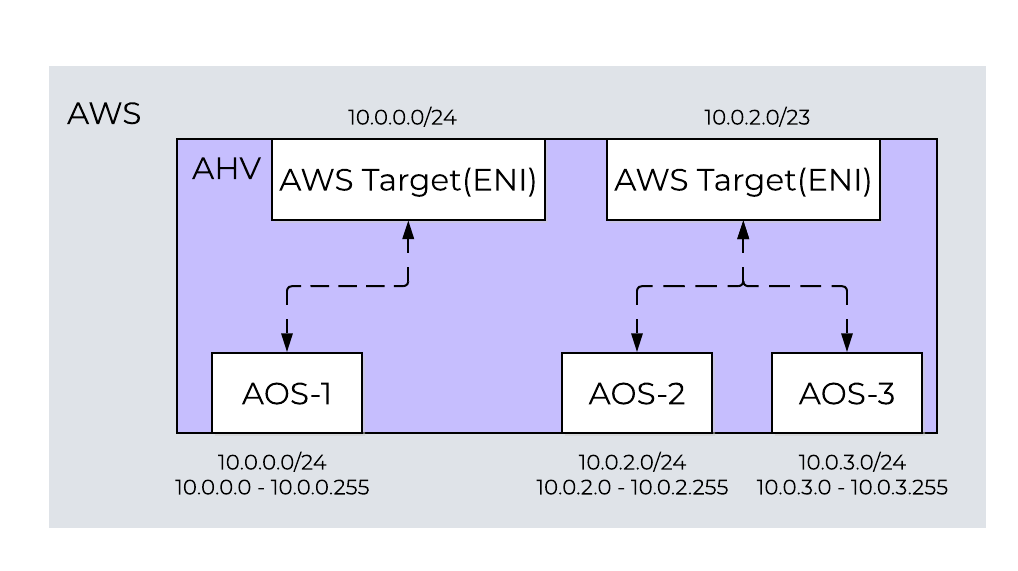
大きなAWS CIDR範囲で複数のAHVサブネットを使用すると、Network ControllerはソースとしてENIアドレスを使用し、AWSデフォルト ゲートウェイに対してAddress Resolution Protocol(ARP)リクエストを生成します。 AWSデフォルト ゲートウェイが応答すると、Network Controllerは、ENI(クラウド ポート)上でアクティブな仮想マシンを持つすべてのAHVサブネットに対して、ARPプロキシ フローをインストールします。 ネットワークのデフォルト ゲートウェイへのARPリクエストは、プロキシ フローに到達し、AWSゲートウェイのMACアドレスを応答として受け取ります。 この構成により、トラフィックがクラスタに入出できるようになり、適切なENIでのトラフィック入出を保証するOVSフロー ルールが構成されます。
NutanixにおけるOVSの実装の詳細については、AHV Administration Guideを参照してください。
NC2 on AWSは、Nutanixクラスタ内で稼働するゲスト仮想マシンのために、ひとつのデフォルト セキュリティ グループを作成します。 ゲスト仮想マシンをサポートするために作成されたすべてのENIは、このデフォルト セキュリティ グループのメンバーとなり、これによりクラスタ内にあるすべてのゲスト仮想マシン同士の通信が許可されます。 セキュリティ グループに加えて、Nutanix Flow Network Securityを使用することで、East-Westトラフィックに対するより高いセキュリティ制御を提供できます。
AWSのVPCダッシュボードで、「Subnets」をクリックし、「Create Subnet」をクリックして、ネットワークの詳細を入力します:
サブネットの作成
AWSのリージョンは、独立した地理的エリアです。 各リージョンには、アベイラビリティ ゾーン(AZ)として知られる複数の独立したロケーションがあり、これらはそのリージョン内のAWS顧客が使用できる論理的なデータセンターです。 リージョン内の各AZには、冗長化された独立した電力、ネットワーク、接続性が備わっており、2つのAZが同時に障害を起こす可能性を低減しています。
AWSでVPCにサブネットを作成し、それをPrism ElementのAOSに接続します。 CVM内の新しいサービスであるCloud Networkは、AOSの設定と連携し、AWSサブネットにVLAN ID(またはVLANタグ)を割り当て、AWSからサブネットの関連情報を取得します。 ネットワーク サービスは、AHVまたはCVMサブネットをゲスト仮想マシンで使用することを防止するため、同じサブネットでネットワークを作成することを許可しません。
各ENIを使用して、49個のセカンダリIPアドレスを管理できます。 また、使用する各サブネットに対して新しいENIが作成されます。 AHVホスト、仮想マシン、および物理インターフェイスは、ブリッジに接続するためにポートを使用し、それらのブリッジはAWSオーバーレイ ネットワークと通信します。 展開が成功した各ホストには、すでに必要なドライバがインストールされているため、AWSオーバーレイ ネットワークを使用するための追加作業は必要ありません。
以下のベストプラクティスを常に念頭に置いてください:
- AWSのゲスト仮想マシン サブネットをクラスタ間で共有しないでください。
- 管理用(AHVおよびCVM)とゲスト仮想マシン用に、別のサブネットを用意してください。
- VPCピアリングを使用する予定がある場合、AWSリージョン全体で一意性を確保するために、デフォルトでないサブネットを使用してください。
- リージョン内のすべての利用可能なAZに対して、VPCネットワーク範囲を均等に分割してください。
- 各AZにおいて、固有のルーティング要件があるホスト グループごとにサブネットを作成してください。(例:パブリック ルーティングとプライベート ルーティング)
- VPC CIDRとサブネットを、大幅な成長に対応できるようにサイジングしてください。
AHVのゲスト仮想マシンIPアドレス管理
AHVは、IPアドレス管理(IPAM)を使用してネイティブなAWSネットワークと統合しています。 NC2 on AWSは、ネイティブなAHV IPAMを使用して、すべてのIPアドレスの割り当てを、APIコールを通じてAWSのDHCPサーバーに通知します。 NC2は、ENIのセカンダリーIPアドレスに追加があった際に、AWSがGratuitous Address Resolution Protocol(ARP)パケットを送信することに依存しています。 これらのパケットを利用して、各ハイパーバイザー ホストがIPアドレスの移動や新しいIPアドレスが到達可能になったことが通知されることを確実にします。 ゲスト仮想マシンの場合、特定のAWSサブネットを2つのNC2 on AWSデプロイメント間で共有することはできません。 しかし、複数のクラスタで同じ管理サブネット (AHVとCVM) を使用することは可能です。
Cloud Network Controllerは、AHVホスト内のサービスであり、ENIの作成を支援します。 Cloud Network Controllerは、OpenFlowコントローラーを実行しており、AHVホスト内のOVSを管理し、ゲスト仮想マシンのセカンダリIPアドレスをENIやホスト間でマッピング、アンマッピング、移行します。 Cloud Network Controllerのサブ コンポーネントであるCloud Port Managerは、インターフェイスを提供し、AWS ENIを管理します。
IPAMは、AWSにAPIコールを送信して、使用されているアドレスを通知することでアドレスの重複を回避します。
AOSのリーダーは、管理対象のvNICを作成するときにアドレス プールからIPアドレスを割り当て、vNICや仮想マシンが削除されるとそのアドレスをプールに戻します。
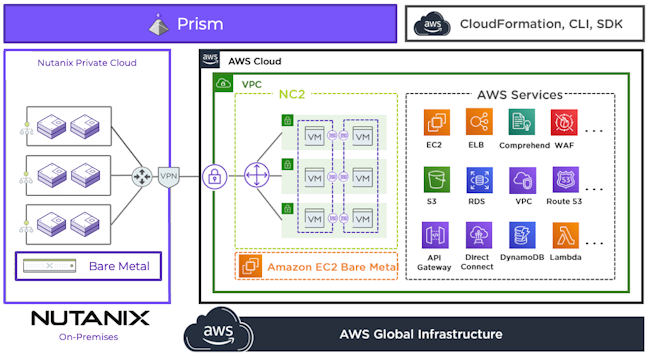
ネイティブなAWSネットワークを使用することで、クラウド管理者が追加のネットワーク技術を管理するのではなく自身のタスクに集中し、迅速に接続を確立できます。 NC2インスタンスは、同じAmazon Virtual Private Cloud内で動作するS3や他のEC2インスタンスなど、すべてのAWSサービスにフル アクセスできます。 典型的なデプロイ手順については、Nutanix Cloud Clusters on AWS Deployment and User Guideの Creating a Cluster セクションを参照してください。
Flow Virtual Networking
Flow Virtual Networkingは、AWSのネイティブなネットワーク スタックを基盤として、他のNC2対応クラウドで提供されるものと同じネットワーク仮想化と制御を提供します。
Flow Virtual Networkingは、Nutanix VPC、サブネット、およびその他の仮想コンポーネントを使用して、AHVクラスタを物理ネットワーク(AWSオーバーレイ)から切り離すことで、マルチテナントの分離、セルフサービスのプロビジョニング、IPアドレスの保持を提供するソフトウェア定義ネットワーキング ソリューションです。 これは、仮想LAN(VLAN)、VPC、仮想プライベート ネットワーク(VPN)、VPNまたは仮想トンネル エンド ポイント(VTEP)を使用したレイヤー2仮想ネットワーク延伸、Border Gateway Protocol(BGP)セッションなどのネットワーキング機能をデプロイするためのツールを統合し、仮想マシンとアプリケーションに焦点を当てた柔軟なネットワーキングをサポートします。
AWS上のFlow Virtual Networking
Flow Virtual Networkingを実行するには、Prism CentralをAWS上のNC2クラスタのいずれかで実行する必要があります。 複数のNC2クラスタでFlow Virtual Networkingを利用できます。 NC2を展開するプロセスでは、Prism Centralが高可用性構成でデプロイされ、Prism CentralがFlow Virtual Networkingのコントロールプレーンをホストします。
Flow Virtual Networkingをデプロイする際には、Prism Central用とFlow Virtual Networkingの外部サブネット用の2つの新しいサブネットが必要です。 Prism Centralのサブネットは、ネイティブAWSサブネットを使用してデプロイされるPrism Elementインスタンスに自動的に追加されます。 Flow Virtual Networkingのサブネットは、すべてのベアメタル ノードにも追加されます。
Flow Virtual Networkingのサブネットは、Nutanix VPCからのトラフィックの外部ネットワークとして機能します。 VPCは、論理ルーターまたは仮想ルーターを介して接続された1つ以上のサブネットで構成され、論理的に分離された仮想ネットワークとして機能する、独立かつ分離されたIPアドレス空間です。 VPC内のIPアドレスは一意である必要がありますが、IPアドレスはVPC間で重複できます。
AWSでは、Nutanixは2層トポロジを使用して、Nutanix VPCへの外部アクセスを提供します。
Flow Virtual Networkingを使用してAWSに最初のクラスタをデプロイすると、overlay-external-subnet-nat と呼ばれる外部サブネットを含むトランジットVPCが自動的に作成されます。 トランジットVPCでは、Nutanix VPCと外部とのNorth-Southトラフィックに対して、AWS ENIを使用し、Nutanix Flow VPCゲートウェイとして機能するためにこの外部サブネットを必要とします。 ルーティング トラフィック向けのトランジットVPCに追加の外部ネットワーク(NoNATネットワークとも呼ばれます)を作成できます。 NATとNo-NATの両方のネットワークで、プライベート アドレス空間を使用して、NutanixのユーザーVPCおよびトランジットVPCから、Nutanix VPCゲートウェイをホストするAWS ENIへのトラフィックをルーティングします。
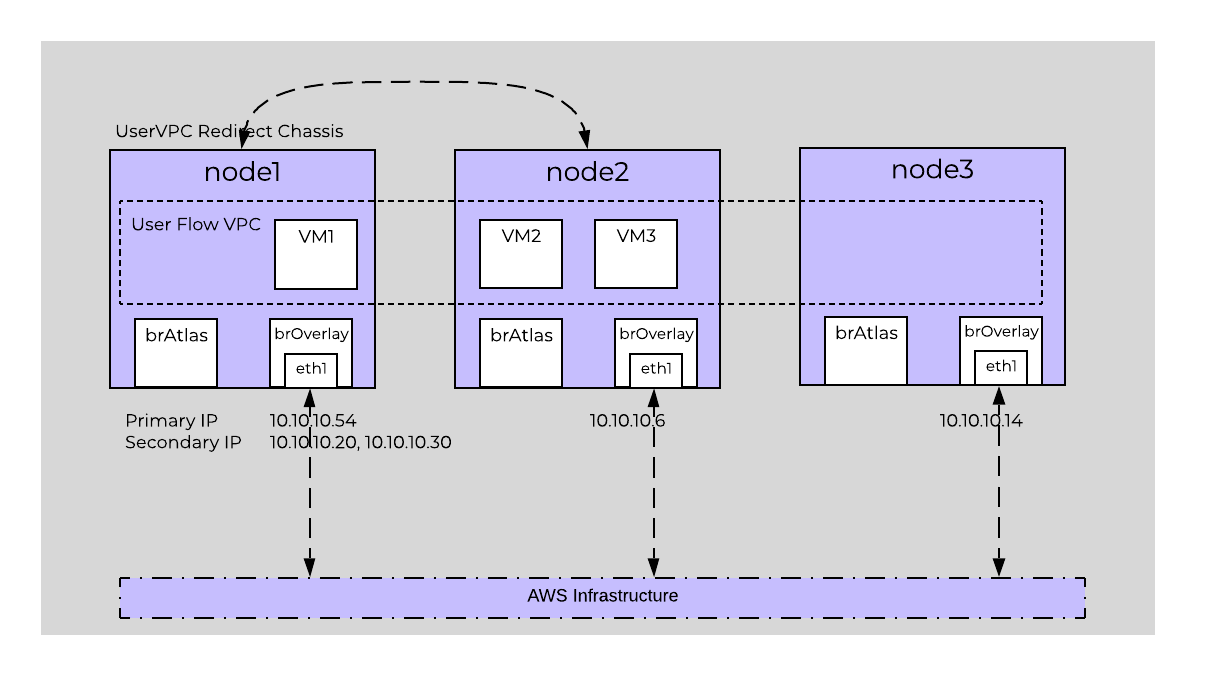
前の図では、ユーザーVPCのNutanix Flowゲートウェイで使用されるAWS ENIは、node1のものです。 Flow Virtual Networkingでは、VPCゲートウェイのホストをAHVのリダイレクト シャーシとして使用します。 リダイレクト シャーシは、VPCからアンダーレイ ネットワークへのすべてのトラフィックの出口ポイントです。 VM1のトラフィックは、リダイレクト シャーシからトランジットVPCに出て、node1上のeth1であるENIから出ます。
node2上にあるVM2とVM3のトラフィック パスは、node1のリダイレクト シャーシを使用します。 トラフィックはAHVネットワーク上のホスト間でGeneric Network Virtualization Encapsulation(GENEVE)トンネルを使用します。 トラフィックはカプセル化が解除され、AWSネットワークの残り部分へルーティングするためにENIへ送信されます。
Flow Virtual NetworkingネイティブAWSサブネットは、ソース ネットワーク アドレス変換(SNAT:Source Network Address Translation)IPアドレスと、ユーザーVPCに入るためにインバウンド トラフィックを必要とするユーザーVMに付与されるフローティングIPアドレスを使用します。 各NC2ベアメタル ノードはプライマリENI IPアドレスを消費し、ネイティブのFlow Virtual Networkingサブネット範囲の60%は、(AWSコンソールでENIのセカンダリIPとして表示される)フローティングIPアドレスに使用できます。
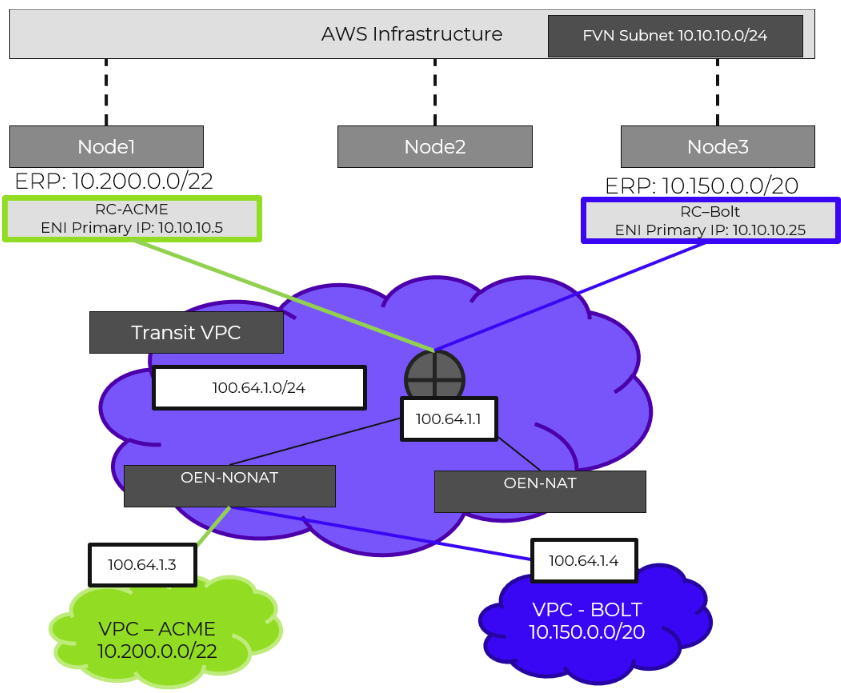
トラフィックは、選択したNC2ノードの1つでホストされているAWS ENIリンクを介してトランジットVPCから出ます。 すべてのNC2ノードがFlow Virtual Networkingサブネットに接続されていたとしても、各VPCは1つのNutanix Flowゲートウェイのみを持ちます。 同じENI上には、複数のNutanix Flow VPCゲートウェイをホストできます。 トランジット ゲートウェイは、そのプライベート ネットワークから各NutanixユーザーVPCにIPアドレスを自動的に割り当てます。 前の図では、ACMEという名前のVPCには100.64.1.3が割り当てられ、BOLTという名前のVPCには100.64.1.4が割り当てられています。
Prism CentralでユーザーVPCサブネットにExternally Routable Prefix(ERP)を設定すると、ERP CIDR範囲をENIに向けるルートが、AWSのデフォルト ルート テーブルに追加されます。 前の図では、ACME用のNutanix Flow VPCゲートウェイはnode1上にあり、ERPは10.200.0.0/22です。 AWSトラフィックは、10.200.0.0/22宛てのすべてのトラフィックのルートを確認し、ENIに送信します。 トラフィックがENIに到達すると、トランジット ゲートウェイはそのトラフィックを100.64.1.3にルーティングします。 この設計により、クラスタ内の各ノードは複数のNutanix Flow VPCゲートウェイをホストできます。
Prism CentralのトランジットVPCページでは、Summary(概要)タブの「Associated External Subnets(関連付けられた外部サブネット)」をクリックすると、ピアツーピア リンクをホストしているNC2ベアメタル ノードを確認できます。
WAN / L3ネットワーク
ほとんどの場合の展開では、AWS内部のみでなく、外部の世界(他のVPC、インターネットまたはWAN)と通信する必要があります。
VPCを接続する場合(同じ、または異なるリージョン)、VPC間でトンネリングできるVPCピアリングを使用できます。 注:WAN IPスキームのベスト プラクティスに従っており、VPCとサブネットのCIDR範囲重複がないことを確認する必要があります。
以下は、eu-west-1およびeu-west-2リージョンの、VPC間のVPCピアリング接続を示します:
各VPCのルートテーブルは、ピアリング接続を経由して他のVPCに向かうトラフィックをルーティングします(通信が双方向の場合、これは両側に存在する必要があります)。
オンプレミスまたはWANへのネットワーク拡張では、VPNゲートウェイ(トンネル)またはAWS Direct Connectが利用できます。
セキュリティ
リソースがフル コントロール セキュリティ外であるクラウドで実行されている場合、データ暗号化とコンプライアンスは非常に重要な考慮事項です。
推奨事項は以下のように特徴付けられます:
- データ暗号化を有効にする
- プライベート サブネットのみを使用する(パブリックIP割り当てなし)
- セキュリティ グループと許可ポートとIP CIDRブロックをロックダウンする
- より詳細なセキュリティを実現するためには、Flowを活用する
AWSセキュリティ グループ
クラスタを他のAWSまたはオンプレミスのリソースから保護するために、AWSセキュリティ グループおよびネットワーク アクセス制御リストを使用できます。 Flow Virtual Networkingをデプロイする際、Prism Central用に、Flow Virtual Networkingコントロール プレーンに必要なすべてのルールを含む、4番目のセキュリティグループがデプロイされます。 AWSを保護するためにNutanix Disaster Recoveryを使用する予定がある場合は、オンプレミスのPrism Centralインスタンスからのトラフィックを許可するように、このセキュリティグループを編集します。 また、環境内にある既存のグループも使用できます。
AWSセキュリティ グループを使用すると、AWS CVM、AHVホスト、ゲスト仮想マシンへのアクセスを、オンプレミスの管理ネットワークとCVMからトラフィックのみを許可できます。 オンプレミスからAWSへのレプリケーションをポート レベルまで制御でき、レプリケーション ソフトウェアが両端のCVMに組み込まれているため、ワークロードを簡単に移行できます。
AOS 6.7以降のバージョンでは、カスタムAWSセキュリティ グループのサポートが追加されており、AWSセキュリティ グループをVPCドメイン、クラスタ、サブネットのレベルで適用できるようになりました。
ENIをベアメタル ホストに接続すると、カスタムAWSセキュリティ グループが適用されます。 以前からあるカスタム セキュリティ グループを維持およびサポートするための追加スクリプトなしで、既存のセキュリティ グループをさまざまなクラスタ間で使用/再利用できます。
クラウド ネットワーク サービス(CVM上で動作し、サブネット管理、IPアドレスのイベント処理、セキュリティ グループ管理に対するクラウド特有のバックエンド サポートを提供する分散サービス)は、どのセキュリティ グループをネットワーク インターフェイスにアタッチするかを評価するために、タグを使用します。 これらのタグは、カスタム セキュリティ グループを含む、任意のAWSセキュリティ グループで使用できます。
次のリストは依存関係の順に並べられています。
- Scope: VPC
- Key: tag:nutanix:clusters:external
- Value: <なし> (このタグは空欄のままにしておく)
上記のタグを使用すると、同一VPC内の複数のクラスタを保護できます。
- Scope: VPCまたはクラスタ
- Key: tag:nutanix:clusters:external:cluster-uuid
- Value: <cluster-uuid>
上記のタグは、CVMとAHVが使用する、すべてのUVMとインターフェイスを保護します。
- Scope: VPC、クラスタ、ネットワーク、サブネット
- Key: tag:nutanix:clusters:external:networks
- Value: <CIDR1、CIDR2、CIDR3>
上記のタグは、指定したサブネットのみを保護します。
サブネットやCIDRに基づいてタグを適用したい場合、ネットワークやサブネットに適用するタグとしてexternal-uuidとcluster-uuidの両方を設定する必要があります。 次のサブセクションでは、構成例を示します。
デフォルトのセキュリティ グループ
上図の赤い線は、クラスタとともにデプロイされる標準のAWSセキュリティ グループを表しています。
- Internal managementセキュリティ グループ: すべてのCVMとAHVホスト(EC2ベアメタル ホスト)間の、すべての内部トラフィックを許可します。 Nutanixサポートからの承認なしで、このグループを編集しないでください。
- User managementセキュリティ グループ: ユーザーの、CVM上で実行されているPrism Elementおよびその他のサービスへのアクセスを許可します。
- UVMセキュリティ グループ: UVMが相互に通信できるようにします。 デフォルトでは、すべてのサブネット上の、すべてのUVM が相互に通信できます。 このセキュリティグループはサブネットの粒度では提供されていません。
VPCレベル
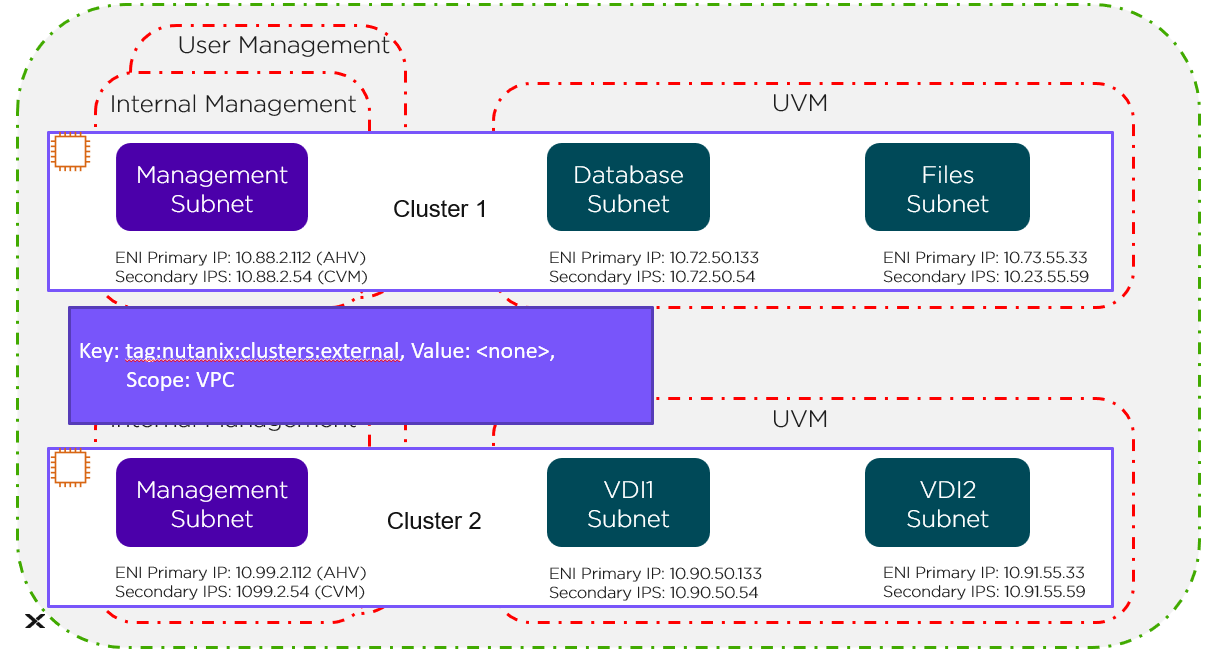
上図の緑線は、クラスタ1とクラスタ2を保護するVPCレベルのタグを表しています。
クラスタ レベル
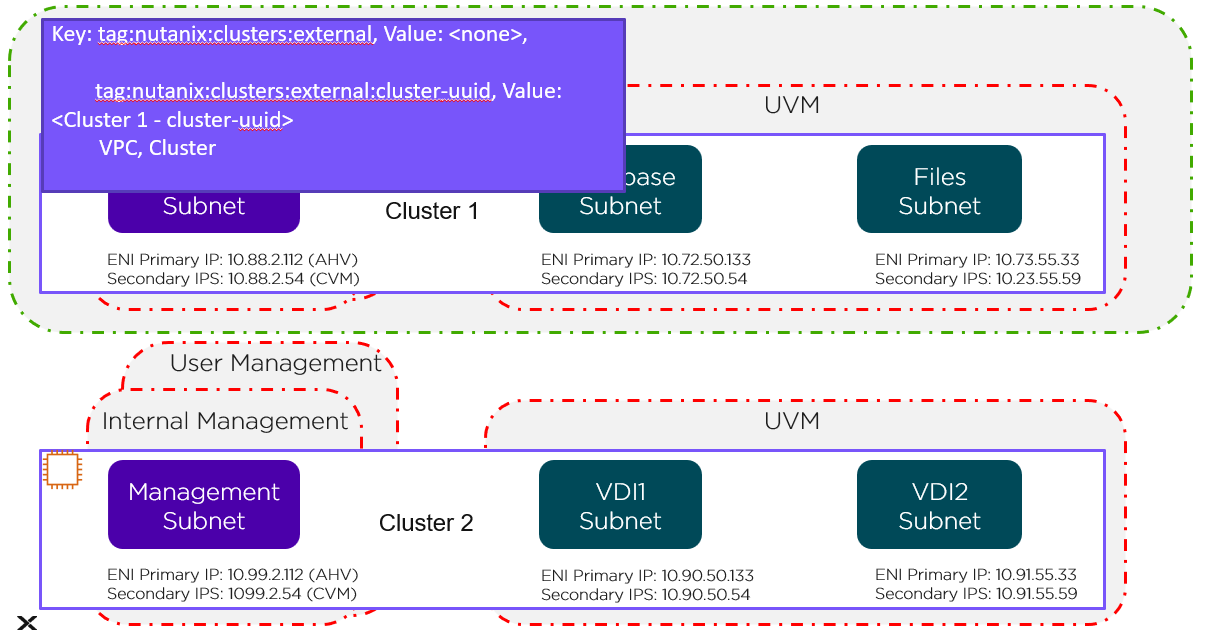
上図の緑線はクラスタ レベルのタグを表します。 これらのセキュリティ グループへの変更は、管理サブネットとクラスタ1で実行されているすべてのUVMに影響します。
ネットワーク レベル
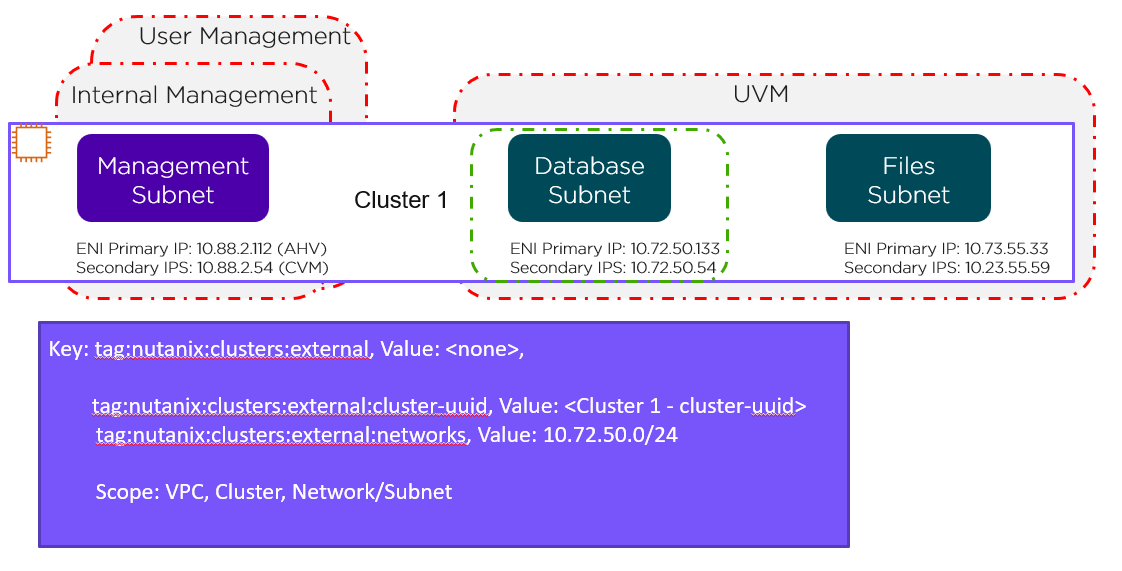
上図の緑線で示されているように、このネットワーク レベルのカスタム セキュリティ グループはDatabaseサブネットのみをカバーします。 このセキュリティ グループでFilesサブネットをカバーするには、次のようにタグを変更するだけです。
- Key: tag:nutanix:clusters:external:networks
- Value: 10.72.50.0/24, 10.73.55.0/24
使用法と構成
このセクションでは、NC2 on AWSを構成して活用する方法について説明します。
おおまかなプロセスは、以下の手順となります:
- AWSアカウントの作成
- AWSネットワークリソースを構成する(必要な場合)
- Nutanix Cloud Clusters Portalを介してクラスタをプロビジョニングする
- プロビジョニングが完了したら、クラスタリソースを利用する
- クラスタを保護する
Nutanix Cluster Protectでのネイティブ バックアップ
アプリケーションをクラウドに移行した場合でも、アプリケーションがオンプレミスにある場合と同様に、すべての運用(Day2)オペレーションを提供する必要があります。 Nutanix Cluster Protectでは、AWS上で実行されているNutanix Cloud Clusters(NC2)をS3バケットにバックアップするためのネイティブ オプションを提供し、これにはユーザー データやPrism Centralとその設定データが含まれます。 Cluster Protectは、クラスタ上にあるすべてのユーザー作成のVMとボリューム グループをバックアップします。
オンプレミスからクラウドに移行すると、AWSアベイラビリティ ゾーン(AZ)に障害が発生した場合でも、アプリケーションとデータの別のコピーが確実に保持できます。 Nutanixはノードおよびラック レベルでローカルな障害に対するネイティブな保護をすでに提供しており、Cluster Protectはその保護をクラスタのAZに拡張します。 このサービスは統合されており、バックアップ プロセスではネイティブAOSスナップショットを使用してバックアップをS3に直接送信するため、ハイ パフォーマンス アプリケーションへの影響は最小限に抑えられます。
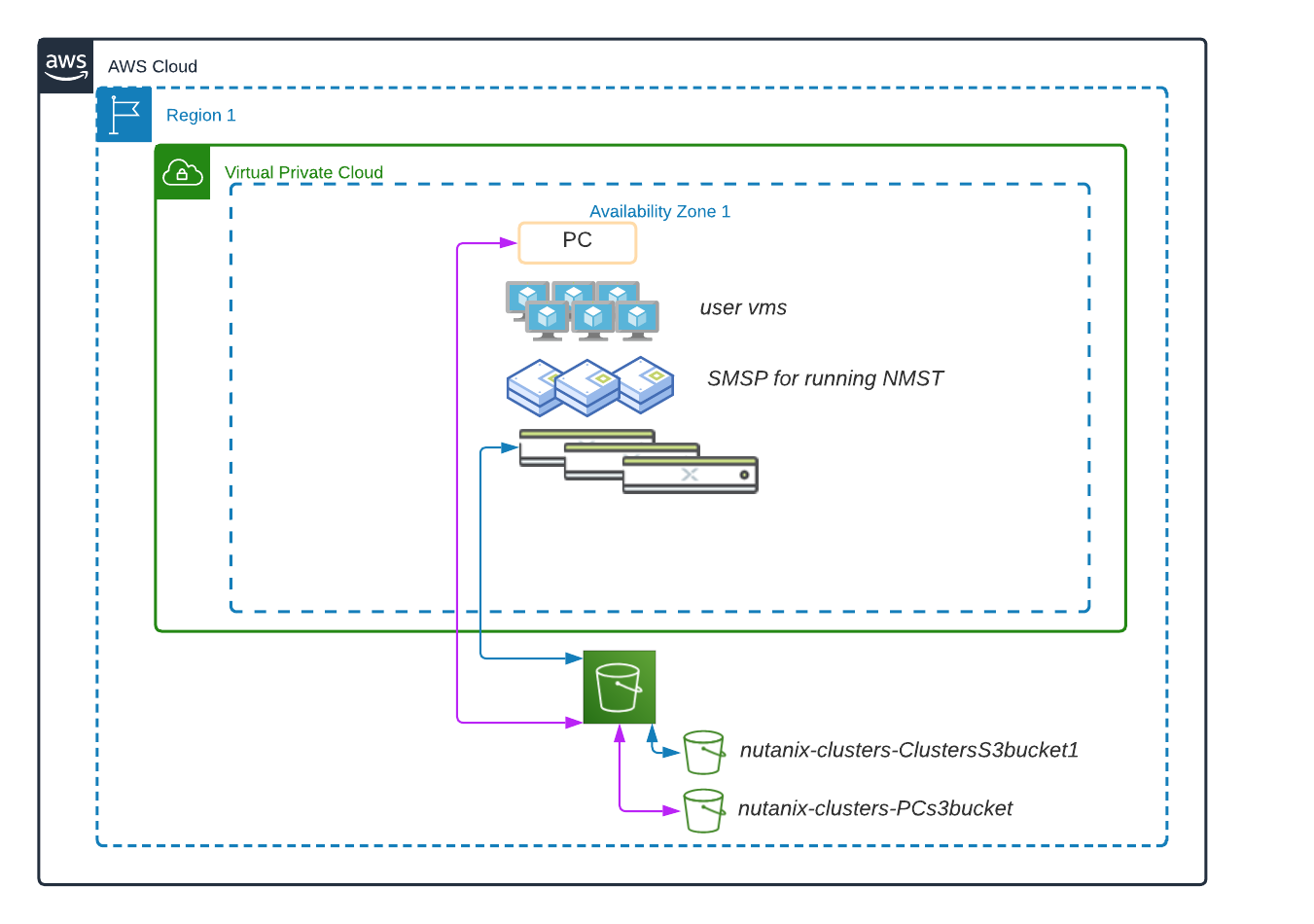
2つのNutanixサービスがCluster Protectの実現を補助します:
- Prism Central Disaster Recoveryは、Prism Centralデータのバックアップを担当します。 AOSストレージ コンテナにバックアップする代わりに、新しいS3バケットをバックアップ先として指定できるようになりました。
- Nutanix Multicloud Snapshot Technology(NMST)は、ネイティブNutanix AOSスナップショットをオブジェクト ストレージに複製します。 Cluster Protectの設計では、AWSの2番目の新しいS3バケットを指定して、保護されたすべてのクラスタのスナップショットを同じS3バケットに送信します。 Cloud Snapshot Engineは、AWSのPrism Centralインスタンス上で実行されます。
次の手順概要では、AWSでクラスタとPrism Centralを保護する方法について説明します。
- AWSに1ノードまたは3ノードのPrism Centralインスタンスをデプロイする。
- 2つのS3バケットを作成する。(1つはPrism Central用で、もう1つはNC2クラスタ用)
- Prism Centralの保護を有効化する。
- NMSTを展開する。
- AWSのNC2クラスタを保護する。
システムは、Prism CentralとAOSの両方のスナップショットを1時間ごとに取得し、最大2つのスナップショットをS3に保持します。 Nutanix Disaster Recoveryはカテゴリで、クラスタ上にユーザーが作成したすべてのVMとボリューム グループを保護します。 サービスが作成イベントまたは削除イベントを監視しており、それらにCluster Protectのカテゴリを割り当てます。
次の手順概要では、AWS上でPrism CentralインスタンスとClustersを復旧する方法について説明します。
- NC2コンソールが、リカバリ プロセス中に新しいNC2クラスタを自動的にデプロイする。
- Prism Centralサブネットとユーザー仮想マシン(UVM)ネットワークを、再作成したNC2クラスタに追加する。
- S3バケットからPrism Centralの設定を復旧する。
- 復旧したクラスタに Prism Centralインスタンスを登録します。
- NMSTを復旧する。
- Recovery Planを作成する。
- Prism CentralからRecovery Planを実行する。
NMSTが回復したら、Prism CentralのRecovery Planを使用して復旧できます。 Recovery Planには、復旧する必要があるすべての仮想マシンが含まれています。 この新しいサービスでNutanix Disaster Recoveryを使用することで、災害発生時に管理者が簡単に復旧できます。
S3へのNutanix Disaster Recovery
NMSTを使用することで、任意のNutanixベースのクラスタからS3にAOSスナップショットを送信できます。 この機能により、定期的にアクセスしないスナップショットや、リカバリ時間目標(RTO)が高いアプリケーションをオフロードし、プライマリ ストレージ インフラストラクチャーのパフォーマンスと容量を最適化できます。
3ノード以上のNC2クラスタ(これをパイロット クラスタと呼びます)でNMSTを使用すると、NMSTはAOSスナップショットをS3にリダイレクトします。 健全なNutanixクラスタが利用可能であれば、スナップショットをNC2クラスタに復元したり、プライマリサイトに戻したりできます。 S3ベースのスナップショットをNC2クラスタに復元するために追加のスペースが必要な場合は、NC2 PortalまたはNC2 Portal APIを使用してクラスタにノードを追加できます。
次の図は、拡張可能な3ノードのNC2クラスタがNMSTを使用して、オンプレミスのプライマリ クラスタからAmazon S3にAOSスナップショットを送信する様子を示しています。
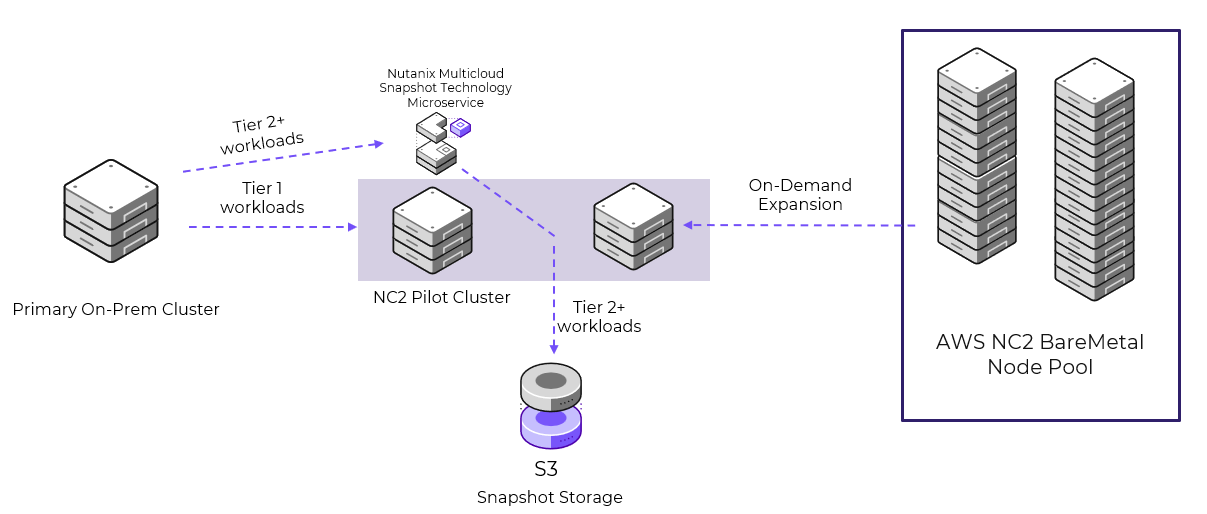
このモデルは、Tier-1アプリケーションの高速なRTOをサポートするために、スナップショットをパイロット クラスタに直接送信して迅速な復元を行い、S3を使用してTier-2アプリケーションのスナップショットを保存します。 Tier-1アプリケーションの追加ストレージとしてEBSを利用することで、このモデルは要件を満たしながらビジネスコストを大幅に削減できます。
Nutanix Cloud Clusters on Azure
Based on: PC 2023.3 | AOS 6.7
Nutanix Cloud Clusters (NC2) on Azureは、ターゲットクラウド環境のベアメタル リソースで実行される、オンデマンドのクラスタを提供します。 これにより、ご存知のNutanixプラットフォームのシンプルさで、真のオンデマンドな収容能力を実現できます。 プロビジョニングされたクラスタは従来のAHVクラスタのように見えますが、クラウドプロバイダーのデータセンターで実行されています。
サポートされる構成
このソリューションは以下の構成に適用できます(このリストはおそらく不完全であり、完全なサポートされている構成のリストについては、ドキュメントを参照してください):
-
主なユースケース:
- オンデマンド / バースト容量
- バックアップ / DR
- クラウド ネイティブ
- 地理的拡張 / DC統合
- アプリケーションのマイグレーション
- その他
-
管理インターフェイス:
- Nutanix Cloud Clusters Portal - プロビジョニング
- Prism Central(PC) - Nutanixの管理
- Azure Portal - Azureの管理
-
サポートされる環境:
- クラウド:
- Azure
- ベアメタル インスタンスの種類:
- AN36
- AN36P
- AN64
-
アップグレード:
- AOSの一部
-
互換性のある機能:
- AOSの機能
- Azureのサービス
主な用語/構造
このセクションでの用語は、以下のように定義されています:
- Nutanix Cloud Clusters Portal
- Nutanix Cloud Clusters Portalは、クラスタのプロビジョニング リクエストの処理を受け持ち、Azureやプロビジョニングされたホストとのやりとりを行います。 クラスタ個別の詳細設定を作成し、クラスタ作成処理をして、ハードウェアの問題を修正するのに役立ちます。
- リージョン
- 複数のアベイラビリティ ゾーン(サイト)が配置されている地理的な土地または地域です。 リージョンには2つ以上のAZを含めることができます。 これらには、East US(バージニア)やWest US 2(ワシントン)などのリージョンを含めることができます。
- アベイラビリティ ゾーン(AZ)
- AZは、低遅延リンクで相互接続された、1つ以上の個別のデータセンターで構成されます。 各サイトは、独自の冗長電源、冷却システム、ネットワークを持ちます。 AZは複数の独立したデータセンターで構成できるため、これらを従来のコロケーションやデータセンターと比較すると、より回復力があると見なされます。
- VNet
- テナント向けの、Azureクラウドの論理的に隔離されたセグメントです。 環境を他からセキュアに隔離するための仕組みを提供します。 インターネットや、他のプライベート ネットワーク セグメント(他のVNetやVPN)に公開できます。
クラスタのアーキテクチャー
Nutanix Cloud Clusters(NC2)Portalは、概観的にいうとNC2 on Azureをプロビジョニングし、Azureと対話するためのメイン インターフェイスです。
プロビジョニング手順は、おおまかに下記のステップとして要約できます:
- NC2 Portalでクラスタを作成する
- 個別入力の展開(例えば、リージョン、AZ、インスタンスの種類、VNet/サブネットなど)
- NC2 Portalが、関連するリソースを作成する
- Nutanix AHVのHost agentが、NC2 on Azureにチェックインする
- すべてのホストが起動すると、クラスタが作成される
以下に、NC2 on Azureの相互作用の概要を示します:
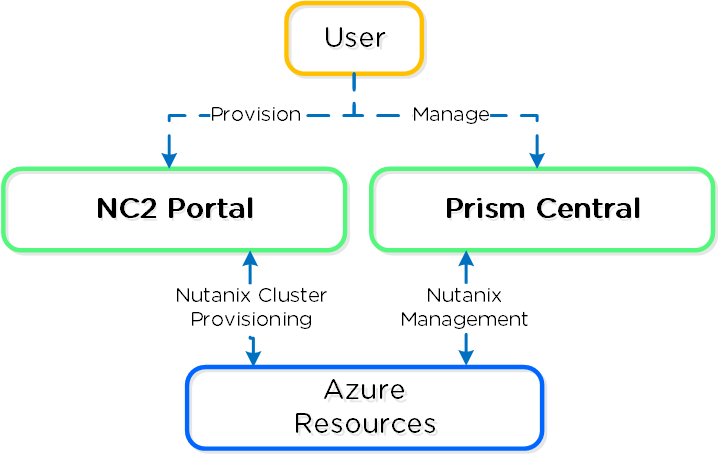
以下は、NC2 Portalによる入力と作成されるリソースの概要を示します:
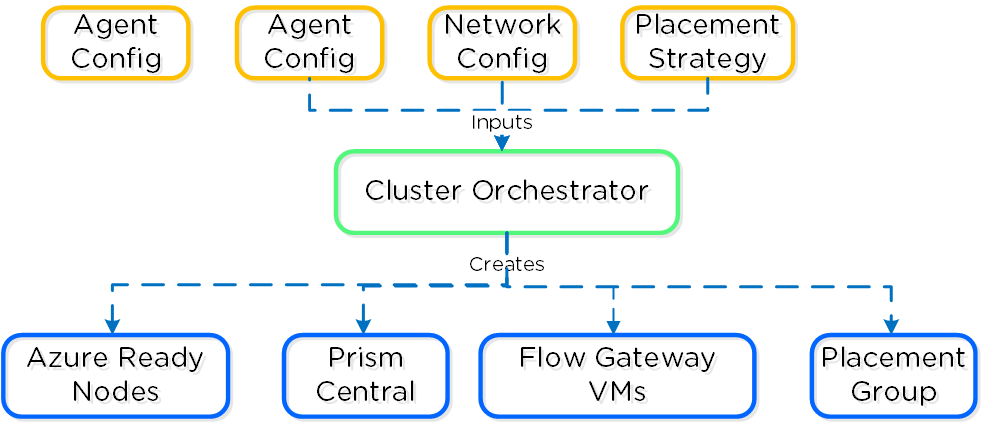
ノードのアーキテクチャー
ホストがベアメタルであるため、通常のオンプレミス展開と同様に、ストレージとネットワークのリソースを完全に制御できます。 ビルディング ブロックとして、Azure Nutanix Ready Nodeを使用しています。 AWSとは異なり、Azureベースのノードは、CVMまたはAHVのための追加サービスを消費しません。
配置ポリシー
Nutanix Cloud Clusters on Azureは、デフォルトで7つのパーティションを持つ、パーティション配置ポリシーを使用します。 ホストは、Nutanixのラックに対応するパーティションに、ストライプ状に配置されています。 これにより、1~2箇所の「ラック」全体障害が発生しても、可用性を維持できます。
以下に、パーティションによる配置戦略および、ホストのストライピングの概要を示します:
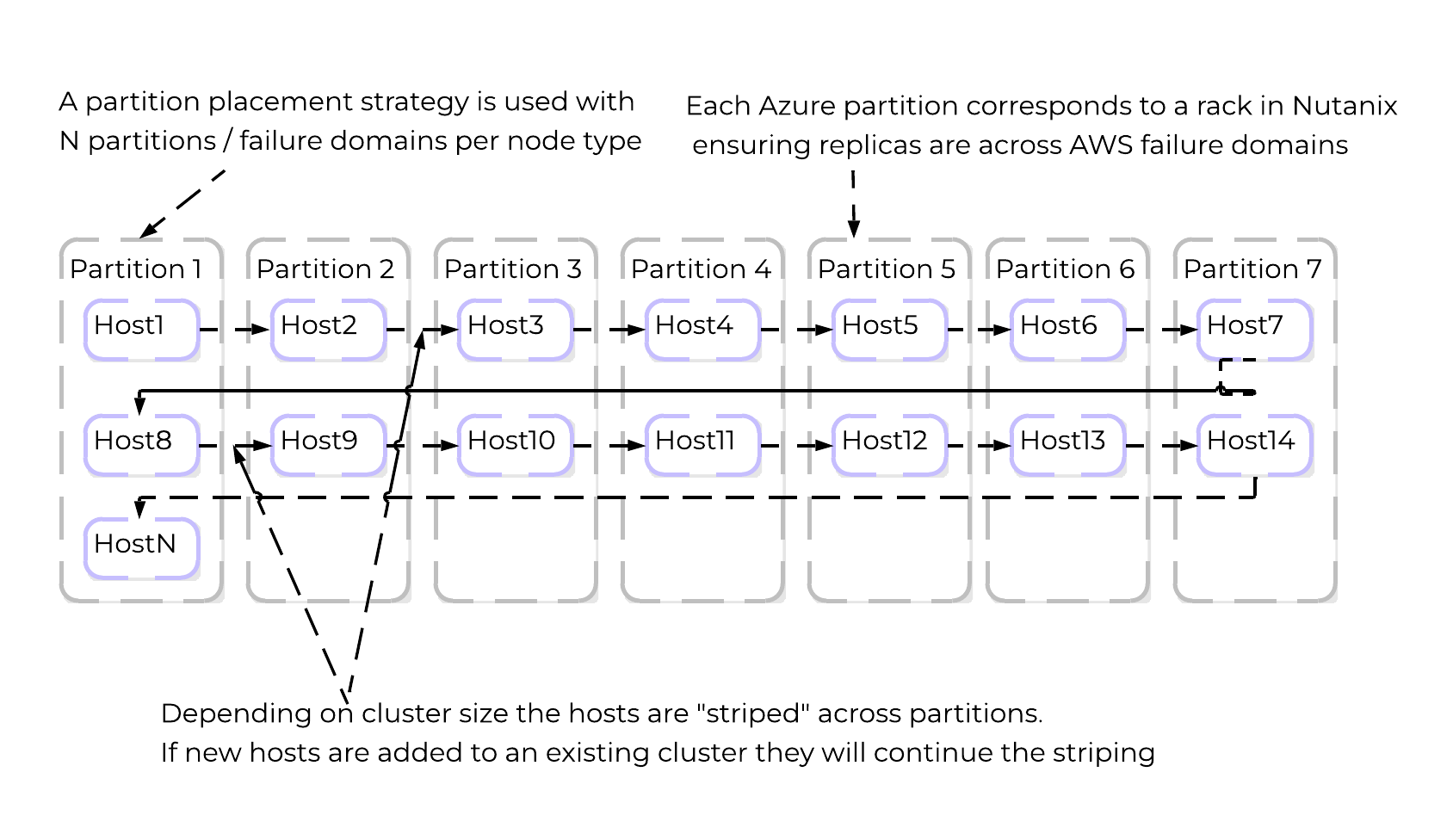
ストレージ
コア ストレージは、Nutanixクラスタで期待するものとまったく同じであり、「ローカル」ストレージデバイスをCVMに接続して、Stargateで活用します。
インスタンスのストレージ
「ローカル」ストレージとしてローカルフラッシュデバイスがバッキングされているため、停電が発生した場合でも完全に回復力があります。
ネットワーク
NC2は、AzureのFlow Virtual Networkingを利用してオーバーレイネットワークを作成することで、Nutanix管理者による管理作業を容易にし、クラウドベンダー間のネットワークの制約を軽減します。 Flow Virtual Networkingは、オーバーレイ仮想ネットワークを作成することにより、Azureのネイティブネットワークを抽象化するために使用されます。 これによりAzureの基盤となるネットワークが抽象化され、それと同時に、ネットワークの下地(およびそれに関連する機能や操作性)をカスタマーの持つオンプレミスのNutanix展開と整合させることができます。 使い慣れたPrism Centralのインターフェイスで、Nutanix内に新しい仮想ネットワーク(仮想プライベートクラウドまたはVPCと呼ばれる)を作成し、RFC 1918の(プライベート)アドレス空間に含まれる任意のアドレス範囲からのサブネットによってDHCPを定義し、NAT、ルーティング、およびセキュリティポリシーを設定します。
Flow Virtual Networkingは、抽象化レイヤーを提供することによりクラウドの制約をマスキングまたは軽減できます。 例として、AzureではVNetごとに1つの委任されたサブネットのみが許可されます。 サブネットの委任により、仮想ネットワークに導入する必要があるAzure PaaSサービスに、特定のサブネットを指定できます。 NC2には、Microsoft.BareMetal/AzureHostedServiceに委任された管理サブネットが必要です。 サブネットがBareMetalサービスに委任されると、NC2 Portalではそのサブネットを使用してNutanixクラスタをデプロイできるようになります。 AzureHostedServiceは、NC2 Portalがベアメタルノードにデプロイとネットワーク構成をするために使用するものです。
ネイティブのユーザー仮想マシンのネットワーキングに使用される各サブネットも、同じサービスに委任する必要があります。 VNetが持てるのは1つの委任されたサブネットのみなので、通信を可能にするためにはVNetを相互にピアリングする必要があり、ネットワーク構成は手に負えなくなります。 Flow Virtual Networkingを使用することで、NC2とAzureで実行されているワークロードが通信できるようにするために必要なVNetの量を大幅に減らすことができます。 Flow Virtual Networkingでは、Azure VNetを1つ消費するだけで500を超えるサブネットを作成できます。
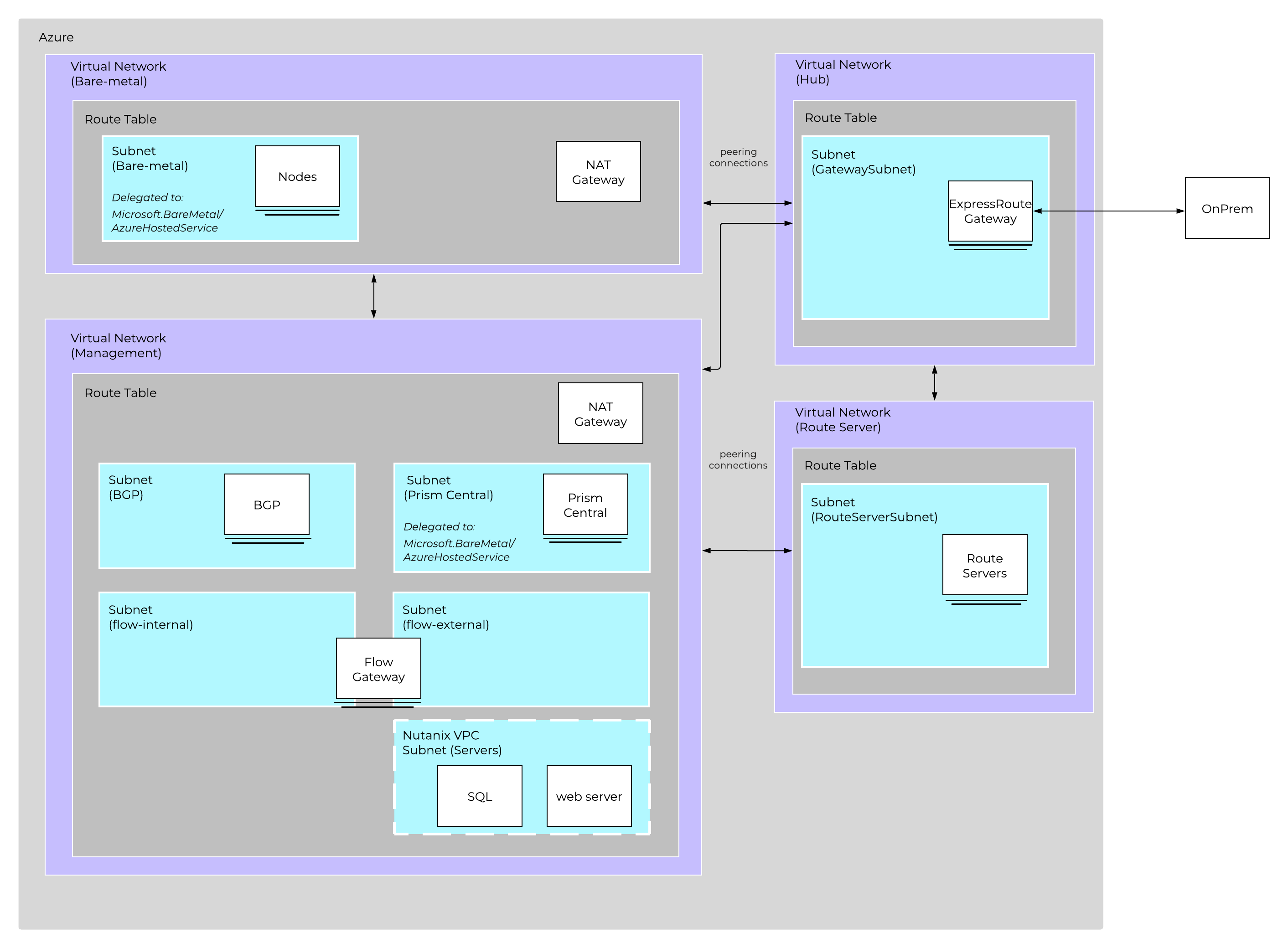
企業のIPスキームに適合するサブネット、NATやインターネット ゲートウェイなどが関連付けられた、新規VPCを作成することを推奨します。 このことは、VPC間(VPCピアリング)や既存のWANにネットワークを拡張する計画がある場合に重要です。 これはWAN上の他のサイトと同じように扱います。
Prism Central(PC)は、展開後のNutanixクラスタにデプロイされます。 Prism Centralには、Flow Virtual Networkingのコントロールプレーンが含まれています。 PCのサブネットはMicrosoft.BareMetal/AzureHostedServiceに委任されるため、ネイティブのAzureネットワークを使用してPCのIPを配布できます。 PCがデプロイされると、Flow GatewayがPCと同じサブネットにデプロイされます。 Flow Gatewayを使用すると、Flow VPCを使用するユーザー仮想マシンがネイティブAzureサービスと通信できるようになり、仮想マシンが次のようにネイティブAzure仮想マシンと同等になります:
- ユーザー定義のルート: Azureで、カスタムまたはユーザー定義(静的)のルートを作成して、Azureのデフォルトのシステムルートをオーバーライドしたり、サブネットのルートテーブルにルートを追加したりできます。 Azureでは、ルートテーブルを作成してから、ルートテーブルを0個以上の仮想ネットワークサブネットに関連付けます。
- ロードバランサーのデプロイ: Azureネイティブのロードバランサーを使用して、ユーザー仮想マシンによってフロントエンドサービスを提供する機能。
- ネットワークセキュリティグループ: ステートフルファイアウォールポリシーを作成する機能。
Flow Gateway VMは、クラスタからNorth-Southに向かう、すべての仮想マシンのトラフィックを担当します。 展開中に、必要な帯域幅に基づいてFlow Gateway VMのサイズを選択できます。 他のCVMやオンプレミスとの間でのCVMレプリケーションはFlow Gateway VMを介して流れないため、それらのトラフィックはサイジングする必要がないと理解することが重要です。
Flow Virtual Networking Gateway VM High Availability
最初のクラスタの初期デプロイ時に、作成するFGW VMの数(2~4)を選択できます。 AOS 6.7より前では、ゲートウェイVMを1台だけデプロイする場合、NC2 Portalは、元の仮想マシンがダウンしていることを検出すると、同じ構成の新しいFGW VMを再デプロイします。 このプロセスはさまざまなAzure APIを呼び出すため、新しいFGW VMがトラフィックを転送できるようになるまでに約5分かかる場合があり、これがNorth-Southのトラフィック フローに影響を与える可能性があります。
このダウンタイムを短縮するために、NC2 on Azureはアクティブ/アクティブ構成に移行しました。 この設定では、より多くのトラフィック スループットが必要な場合に、柔軟なスケールアウト構成が提供されます。
次のワークフローでは、アップデートなどの計画されたイベントのためにFGW VMを、正常な(gracefully)停止を実施した場合に何が起こるかを説明します。
- NC2 Portalで、FGW VMを無効にする。
- Prism Centralが、トラフィック パスから仮想マシンを削除する。
- NC2 Portalが、元の仮想マシンを削除し、同一の構成で新しいFGW VMを作成する。
- NC2 Portalが、新しいインスタンスをPrism Centralに登録する。
- Prism Centralが、新しいインスタンスをトラフィック パスに追加しなおす。
不適切な停止または計画外の障害については、NC2 PortalとPrism Centralの両方にキープアライブに基づく独自の検出メカニズムがあります。 それらについても、正常なケースまたは計画されたケースと同様のアクションを実行します。
ネットワークアドレス変換(NAT): AHV/CVM/PC/Azureリソースと通信するユーザー仮想マシンは、Flow Gateway VMの外部ネットワークカードを経由します。 提供されるNATは、ネイティブのAzureアドレスを使用して、すべてのリソースへのルーティングを保証します。 NATの使用が望ましくない場合は、Azureのユーザー定義のルートを使用してAzureリソースと直接通信できます。 これにより、新規インストールでAzureとすぐに通信できるようになりますが、カスタマーにはより高度な構成のオプションも提供されます。
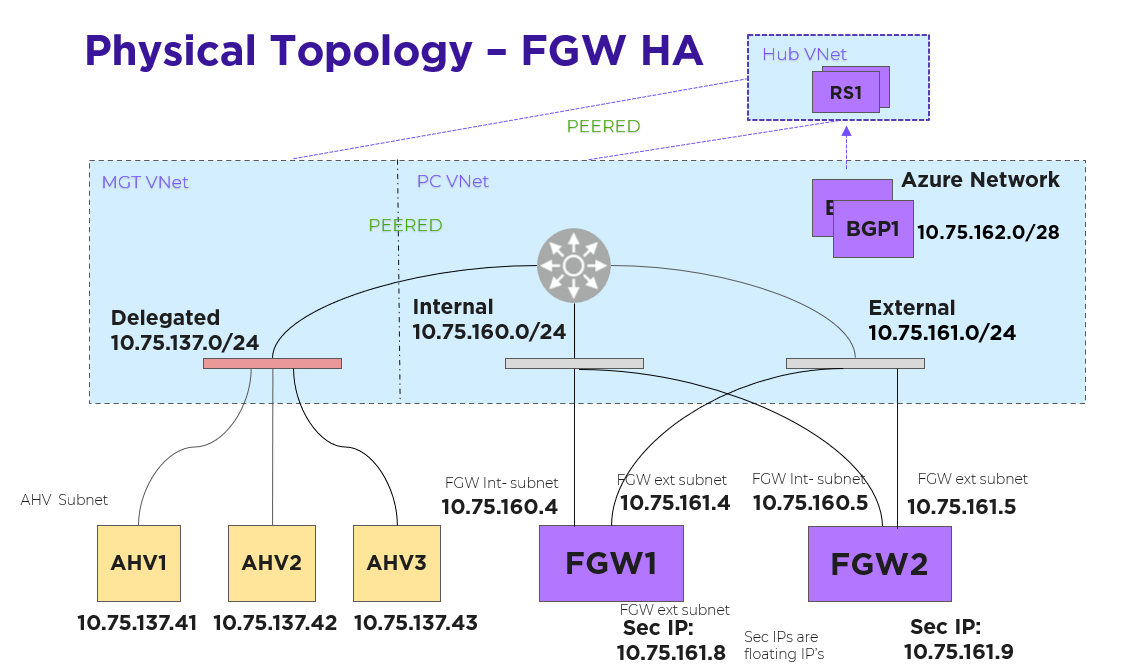
各FGWインスタンスには2つの NIC があります。 1つはAHVとトラフィックを交換する内部サブネット上にあり、もう1つはAzureネットワークとトラフィックを交換する外部サブネット上にあります。
各FGWインスタンスはPrism Centralに登録され、トラフィック パスに追加されます。 ポイント ツー ポイント接続の外部サブネットが各FGWに対して作成され、トランジットVPCがそれに接続され、FGWインスタンスは対応する論理ルーター ゲートウェイのポートをホストします。 次の図では、EN-NONAT1とEN-NONAT2がポイントツーポイント接続されている外部サブネットです。
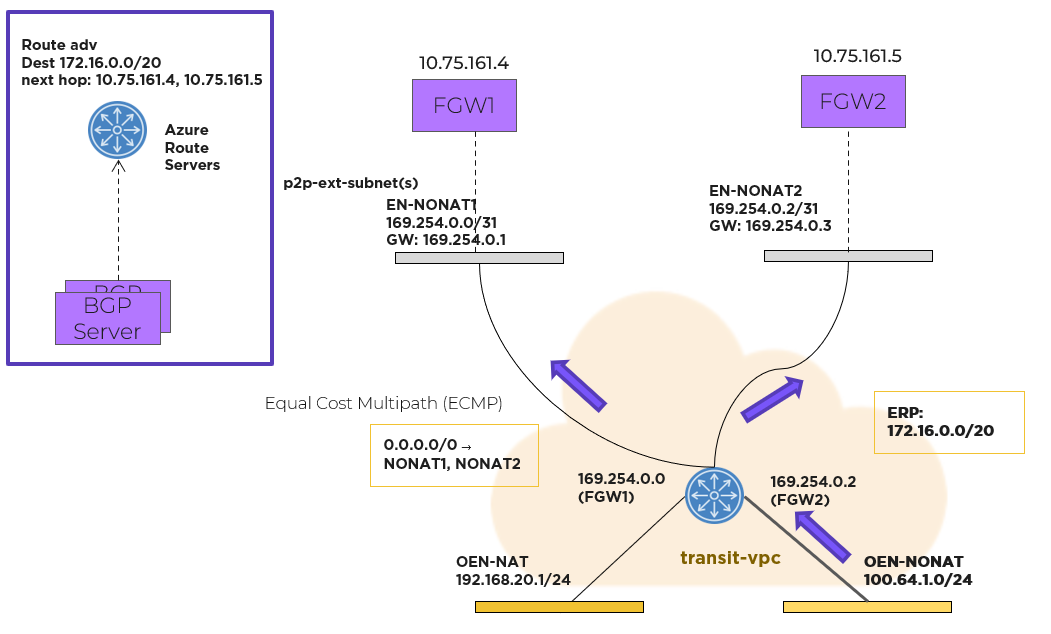
NoNATを利用するFlow Virtual Networking Gateway
ノースバウンド トラフィックでは、トランジットVPCには等コスト マルチパス(ECMP)のデフォルト ルートがあり、すべてのポイントツーポイント外部サブネットが到達可能なネクスト ホップとして含まれます。 この場合、トランジットVPCは、異なるFGWでホストされている複数の外部サブネットにトラフィックを分散します。
1つより多いFGWを使用するサウスバウンド トラフィックの場合、Border Gateway Protocol(BGP)ゲートウェイが、Prism Central Virtual Network(VNet)にAzureネイティブ仮想マシンのインスタンスとしてデプロイされます。 Azure Route Serverが、同じPrism Central VNetにデプロイされます。 Azure Route Serverを使用すると、ルート テーブルを手動で構成または管理する必要がなく、BGPをサポートするネットワーク仮想アプライアンスとAzure VNetの間で、BGPを介してルーティング情報を直接交換できます。
BGPゲートウェイは、Azure Route Serverとピアリングします。 BGPゲートウェイは、それぞれのアクティブなFGW外部IPアドレスをネクスト ホップとして、外部ルーティング可能なIPアドレスをAzure Route Serverにアドバタイズします。 外部ルーティング可能なIPアドレスは、作成したアドレス範囲を構成し、Flow Virtual NetworkingのユーザーVPC内の、残りのネットワークにアドバタイズします。 外部ルーティング可能なIPアドレスがユーザーVPCのPrism Centralに設定されると、Azureネットワークはサウスバウンド パケットを、すべてのFGWインスタンスに分散します。
Prism Centralは、どのFGWインスタンスが特定のNAT IPアドレスをホストするかを決定し、各NAT IPアドレスを各FGWのセカンダリIPアドレスとして設定します。 これらのIPアドレスから送信されたパケットは、対応するFGW経由のみで転送できます。 NATトラフィックが、すべてのFGWに分散されることはありません。
Azureネットワークから発信され、フローティングIPアドレスを宛先とするNATトラフィックは、そのIPアドレスを所有するFGW VMに送信されますが、これはAzureが現在そのIPアドレスを所有しているNICを認識しているためです。
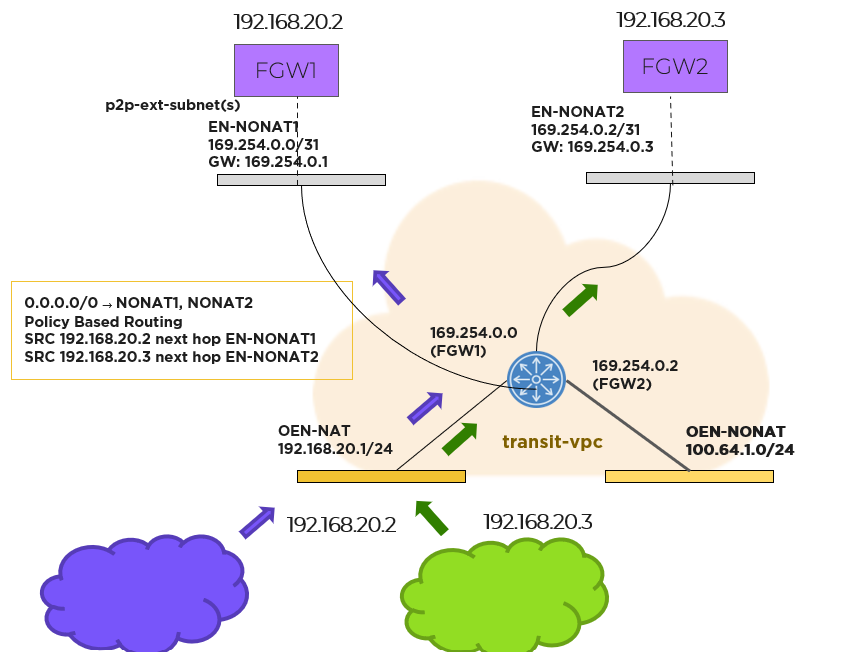
Prism Centralは、ポリシー ベース ルーティングを使用して、フローティングIPアドレスと一致する送信元IPアドレスに基づく転送をサポートします。 Flow Virtual Networkingに組み込まれたカスタム フォワーディング ポリシー ベースのルーティング ルールは、トランジットVPCにルートを自動インストールするために使用されます。
ホストのネットワーク
Azureのベアメタルで実行されているホストは従来どおりのAHVホストであるため、同様にOVSベースのネットワーク スタックを利用します。
以下は、AzureでのAHVホストにおけるOVSスタックの概要を示しています:
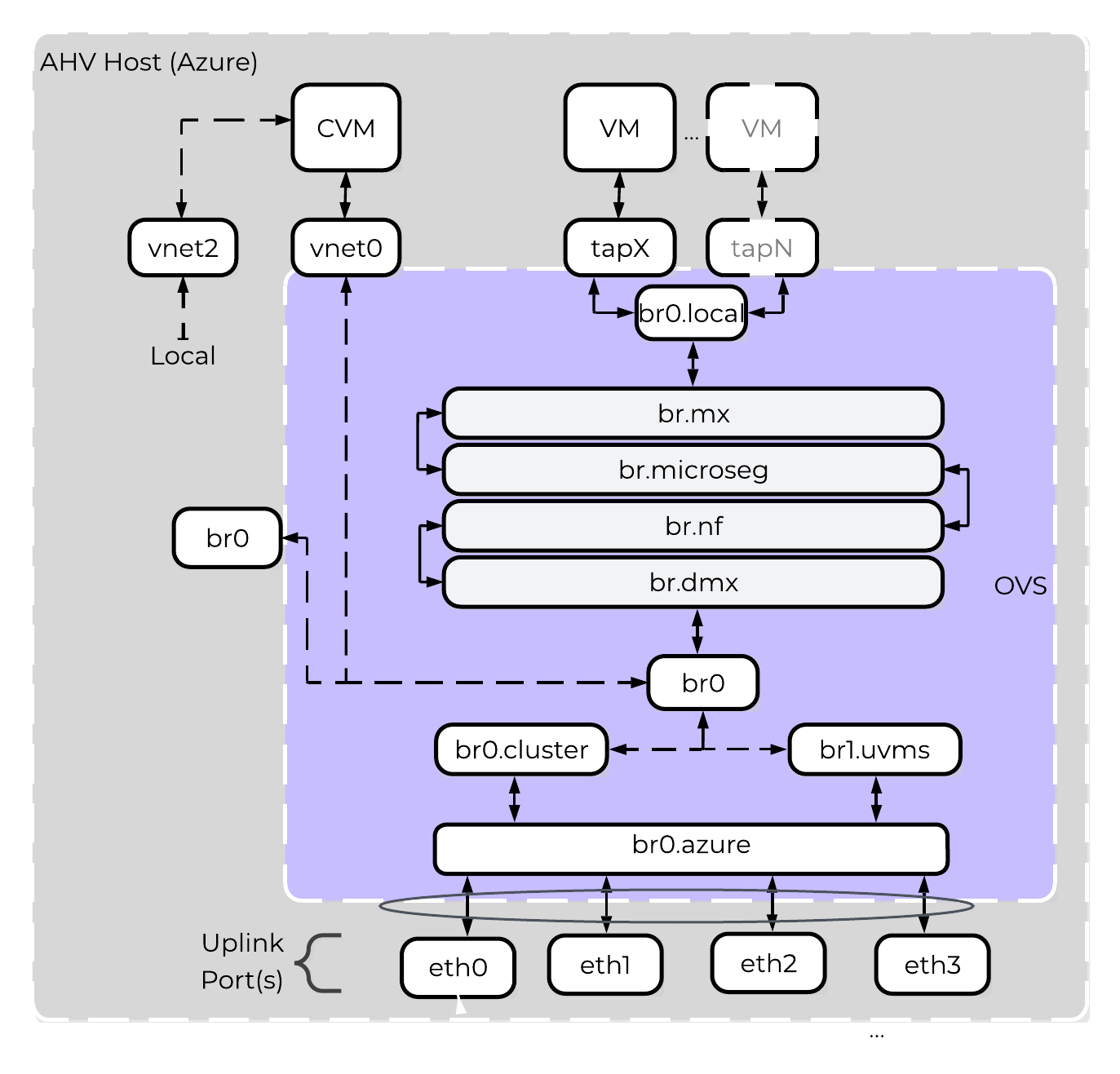
NutanixのOpenv Switchの実装は、オンプレミスでの実装と非常によく似ています。 上の図は、ベアメタルに展開されるAHVの内部アーキテクチャーを示しています。 br0ブリッジは、トラフィックをbr0.cluster(AHV/CVMのIP)とbr0.uvms(ユーザー仮想マシンのIP)の間で分割します。
br0.clusterを介したAHV/CVMトラフィックの場合、データパケットを変更せずに、br0.azureブリッジへの単純なパススルーになります。 トップオブラックのスイッチングは、br0.clusterトラフィックへのセキュリティを提供します。 ユーザー仮想マシンのIPトラフィックがbr0.uvmsを介して流れる場合、VLAN-ID変換およびbr0.azureへのパススルートラフィック用にOVSルールがインストールされます。
br0.azureは、OVSボンド(bond)のbr0.azure-upを持ち、ベアメタルに接続された物理NICとのボンドインターフェイスを形成します。 したがってbr0.azureは、ボンドインターフェイスをbr0.uvmsおよびbr0.clusterから隠します。
サブネットの作成
作成するサブネットはビルトインのIPAMを持ち、ネットワークをオンプレミスからAzureに拡張するオプションがあります。 外部アプリケーションがサブネット内のユーザー仮想マシンと直接通信する必要がある場合には、AzureのIPプールからフローティングIPを割り当てるオプションもあり、Flow Gatewayの外部ネットワークからのものです。
展開を成功させるには、NC2は、NATゲートウェイまたはアウトバウンドアクセスのオンプレミスVPNを使用して、NC2 Portalへのアウトバウンドアクセスを必要とします。 Nutanixクラスタは、VPNからのみアクセスできるプライベートサブネットに配置できるため、環境への露出は制限されます。
Nutanix Multicloud Snapshot Technologyによるワークロードの保護
Nutanix Multicloud Snapshot Technology(NMST)は、ネイティブなNutanix AOSスナップショットをオブジェクト ストレージ、AWS S3、そしてAzure Blob Storageにレプリケートします。 NMSTエンジンは、Prism Centralと並行してPrism上で動作します。 この機能により、定常的にアクセスしないスナップショットや、より長い復旧時間目標(RTO)を持つアプリケーションをオフロードし、プライマリ ストレージ インフラストラクチャにおけるパフォーマンスとキャパシティを最適化できます。 その後、必要に応じて、ゼロコンピュート(オンプレミスまたはAzure上でのNutanixクラスタのオンデマンド展開)またはパイロットライト(NC2展開のオンデマンド拡張)モデルを使用してワークロードを復旧できます。
ゼロコンピュート展開
ゼロコンピュート展開は、NMSTサービスが保護対象のワークロードと並行して実行される、オンデマンドのNutanixクラスタ展開モデルです。 このモデルをAzureで使用すると、スナップショットを直接Azure Blob Storageにレプリケートして、RTOが長くても対応可能な重要度の低いワークロードを保存および復旧できます。 フェイルオーバー時には、レプリケートされたスナップショットをすぐに使用し、オンプレミスまたはAzureでオンデマンドのNutanixクラスタを展開してリストアできます。
パイロットライト展開
パイロットライト展開では、NMSTサービスが最小3ノードのNC2展開上で動作します。 NMSTはAOSスナップショットをAzure Blob Storageにリダイレクトします。 正常なNutanixクラスタが利用可能であれば、スナップショットをNC2展開またはプライマリ サイトにリストアできます。 NC2デプロイメントにAzure Blob Storageベースのスナップショットをリストアするために追加の領域が必要な場合は、NC2 ConsoleまたはNC2 Console APIを使用してクラスタにノードを追加できます。
このモデルは、Tier-1アプリケーション向けの迅速なRTOをサポートします。 スナップショットをパイロット クラスタに直接送信して迅速なリストアを行い、Tier-2アプリケーション向けにはAzure Blob Storageを使用してスナップショットを保存します。
WAN / L3ネットワーク
ほとんどの場合の展開では、Azure内部のみでなく、外部の世界(他のVNet、インターネットまたはWAN)と通信する必要があります。
VNetを接続する場合(同じ、または異なるリージョン)、VNet間でトンネリングできるVNetピアリングを使用できます。 注:WAN IPスキームのベスト プラクティスに従っており、VNetとサブネットのCIDR範囲重複がないことを確認する必要があります。
オンプレミスまたはWANへのネットワーク拡張では、VNetゲートウェイ(トンネル)またはExpress Routeが利用できます。
使用法と構成
このセクションでは、NC2 on Azureを構成して活用する方法について説明します。
おおまかなプロセスは、以下の手順となります:
- アクティブなサブスクリプションをセットアップする。
- My Nutanix アカウントの作成し、NC2をサブスクライブする。
- Azureリソースプロバイダーを登録する。
- 新しいサブスクリプションへの「Contributor(共同作成者)」アクセスがある、Azure ADでの「アプリの登録」を作成する。
- DNSを構成する。
- リソースグループを作成する、または既存リソースグループを再利用する。
- 必要なVNetとサブネットを作成する。
- 2つのNATゲートウェイを構成する。
- Nutanixクラスタに必要なVNetピアリングを確立する。
- AzureアカウントをNC2 Consoleに追加する。
- NC2 Consoleを使用してAzureにNutanixクラスタを作成する。
More to come!
Nutanix Cloud Clusters on Google Cloud
Based on: PC 7.3.1.1 | AOS 7.3.1.1
NC2 now extends NCP into the Google Cloud ecosystem, providing a true hybrid multicloud infrastructure stack. NC2 on Google Cloud allows organizations to run directly on Google Compute Engine (GCE) bare-metal instances in their own Google Cloud Virtual Private Cloud (VPC).
Supported Configurations
The solution is applicable to the configurations below (list may be incomplete, refer to documentation for a fully supported list):
Core Use Case(s):
- On-Demand / burst capacity
- Backup / DR
- Cloud Native
- Geo Expansion / DC consolidation
- App migration
Management interfaces(s):
- Nutanix Clusters Portal - Provisioning
- Prism Central (PC) - Nutanix Management
- Google Cloud Console - Google Cloud Management
Supported Environment(s):
- Cloud:
- AWS
- Azure
- Google Cloud
- Bare Metal Instance Types:
- Z3 High Memory
- C4 High Memory
- C4 Standard
Upgrades:
- Part of AOS
Compatible Features:
- AOS Features
- Google Cloud Services
Key terms / Constructs
Nutanix Cloud Clusters (NC2) on Google Cloud integrates Nutanix Cloud Platform (NCP) with the underlying Google Cloud infrastructure. The solution uses the following components:
- NC2 Portal
- The NC2 Portal is a multicloud control plane used to deploy, manage, expand, and shrink NC2 clusters in supported public clouds, including Google Cloud. The NC2 Portal is responsible for handling cluster provisioning requests and interacting with Google Cloud and the provisioned hosts. It creates cluster specific details and handles the cluster creation and helps to remediate hardware problems.
- Region
- A geographic landmass or area where multiple Availability Zones (sites) are located. A region can have two or more AZs. These can include regions like “us-central1” (Iowa) or us-east1 (South Carolina).
- Availability Zone (AZ)
- An AZ consists of one or more discrete datacenters interconnected by low latency links. Each site has its own redundant power, cooling, network, etc. Comparing these to a traditional colo or datacenter, these would be considered more resilient as a AZ can consist of multiple independent datacenters.
- Google Compute Engine bare-metal instances
- Google Compute Engine (GCE) provides the bare-metal instances on which the NCP solution runs. These bare-metal instances appear in the Google Cloud Console like any other GCE instances and are distinct from the Google Bare Metal Solution that is not supported with NC2. Nutanix AHV runs directly on the GCE bare-metal instances, providing the foundation for running VMs.
- Google Cloud Project
- A Google Cloud project is the fundamental organizing entity for all your resources, APIs, billing, and permissions on Google Cloud.
- Virtual Private Cloud (VPC)
- A logically isolated segment of the Google Cloud Cloud within a project. Provides a mechanism to secure and isolate environment from others. Can be exposed to the internet or other private network segments (other VPCs, or VPNs).
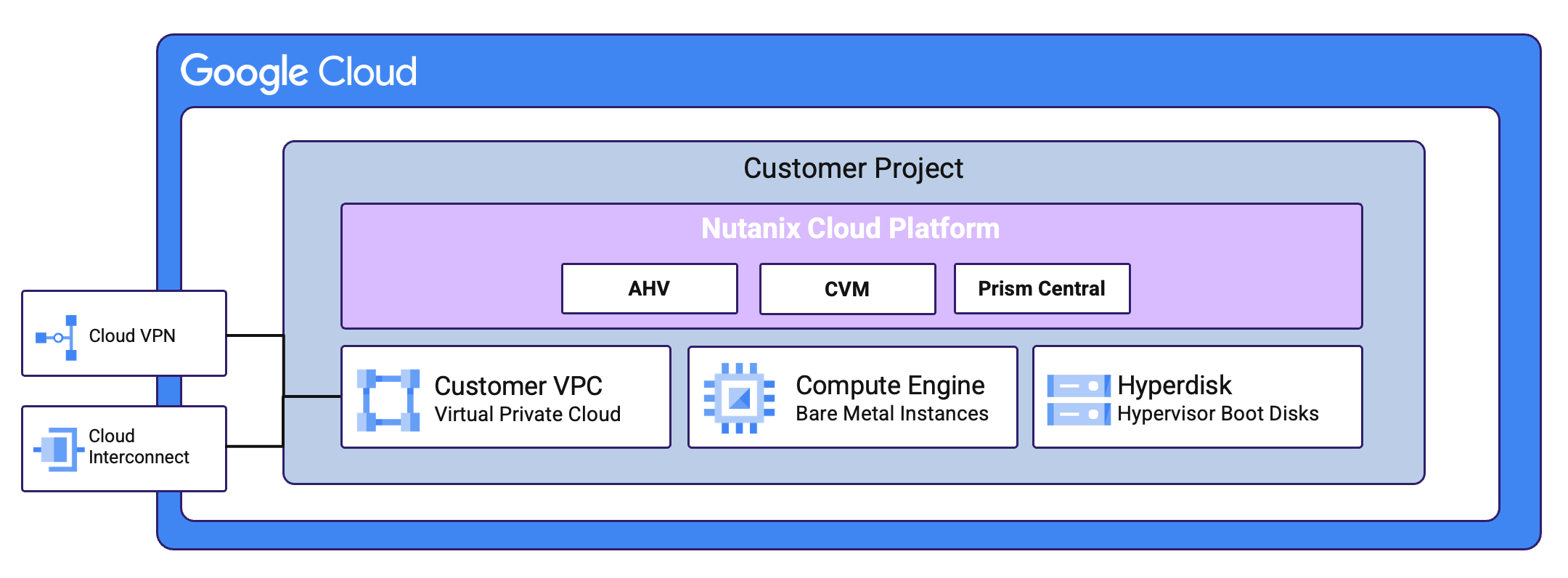
Solution Architecture
From a high-level the NC2 Portal is the main interface for provisioning Nutanix Clusters on Google Cloud and interacting with Google Cloud.
The provisioning process can be summarized with the following high-level steps:
- Create a cluster in NC2 Portal
- Deployment specific inputs (e.g. Region, AZ, Instance type, VPCs/Subnets, etc.)
- The NC2 Portal creates associated resources
- Host agent running on AHV checks-in with Nutanix Clusters on Google Cloud
- Once all hosts as up, cluster is created
The following shows a high-level overview of the NC2 on Google Cloud interaction:
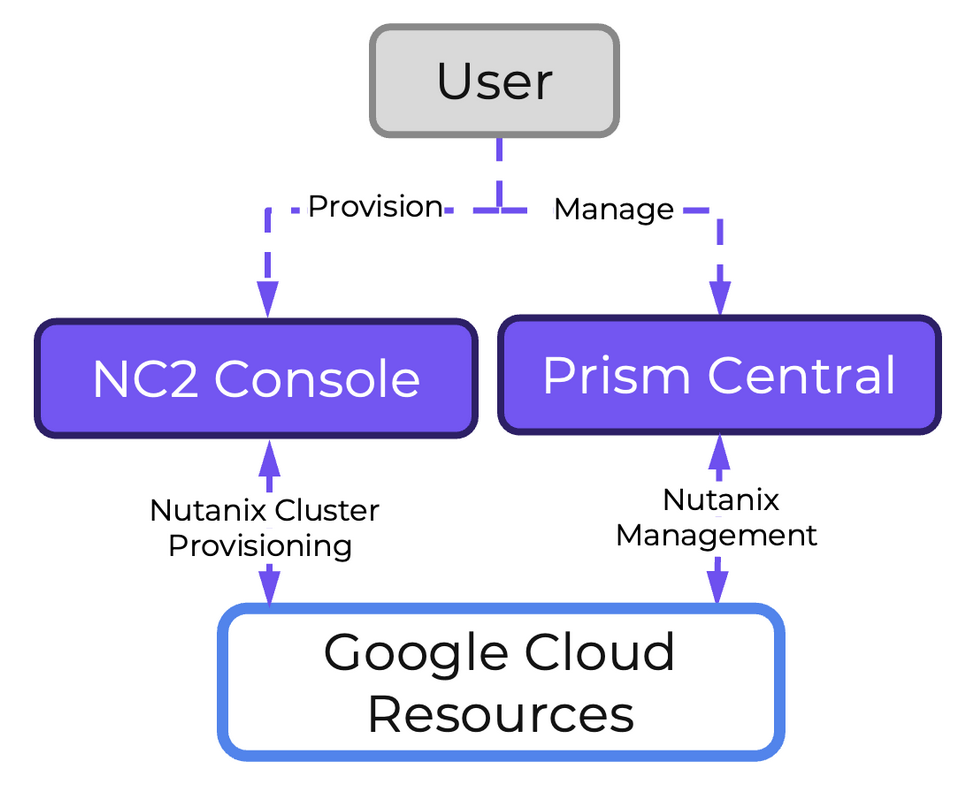
Node Architecture
Given that the hosts are bare metal, the solution has full control over storage and network resources similar to a typical on-premises Nutanix deployment, witht he exception that Google Cloud’s Hyperdisk service is used to provide the AHV Hypervisor boot volumes.
Placement policy
Nutanix Clusters on Google Cloud uses a partition placement policy with 7 partitions. Hosts are striped across these partitions which correspond with racks in an on premises Nutanix deployment. This ensures you can have 1 or 2 (with a 2N/2D configuration) full “rack” failures and still maintain availability.
Storage
Core storage is the exact same as you’d expect on any Nutanix cluster, passing the “local” storage devices to the CVM to be leveraged by Stargate.
Networking
NC2 utilizes Flow Virtual Networking in Google Cloud to create an overlay network to ease administration for Nutanix administrators and reduce networking constraints across Cloud vendors. Flow Virtual Networking is used to abstract the Google Cloud native network by creating overlay virtual networks. On the one hand this abstracts the underlying network in Google Cloud, while at the same time, it allows the network substrate (and its associated features and functionalities) to be consistent with the customer’s on-premises Nutanix deployments. You will be able to create new virtual networks (called Virtual Private Clouds or VPCs) within Nutanix, subnets in any address range, including those from the RFC1918 (private) address space and define DHCP, NAT, routing, and security policy right from the familiar Prism Central interface.
You can deploy Nutanix Cloud Clusters (NC2) on Google Cloud into an existing Google Cloud Virtual Private Cloud (VPC) and its subnets, or you can create a VPC and subnets specifically for NC2 in a project at deployment. VMs and containers running on the cluster can connect to the internet, native Google Cloud services, and on-premises datacenters using WAN networking (virtual private network, Google Cloud Router, Multiprotocol Label Switching).
Flow Virtual Networking for NC2 on Google Cloud has the following capabilities:
- Flow Virtual Networking creates an overlay network for user VMs, allowing you to create virtual networks (VPCs) and subnets in Prism Central independent of the underlying Google Cloud network topology.
- Flow Virtual Networking provides a unified networking experience across on-premises and Google Cloud environments, simplifying hybrid connectivity and policy management.
- For communication between user VMs on different physical hosts, the overlay network uses Geneve encapsulation.
- User VMs can connect to external Google Cloud networks, the internet, and native Google Cloud services, such as Google Kubernetes Engine (GKE) and BigQuery.
- You can provision user VMs to a network regardless of network address translation (NAT). > If you provision a user VM to a NAT network, assign a floating IP address to the user VM to facilitate connectivity from outside the Flow Virtual Networking overlay networks.
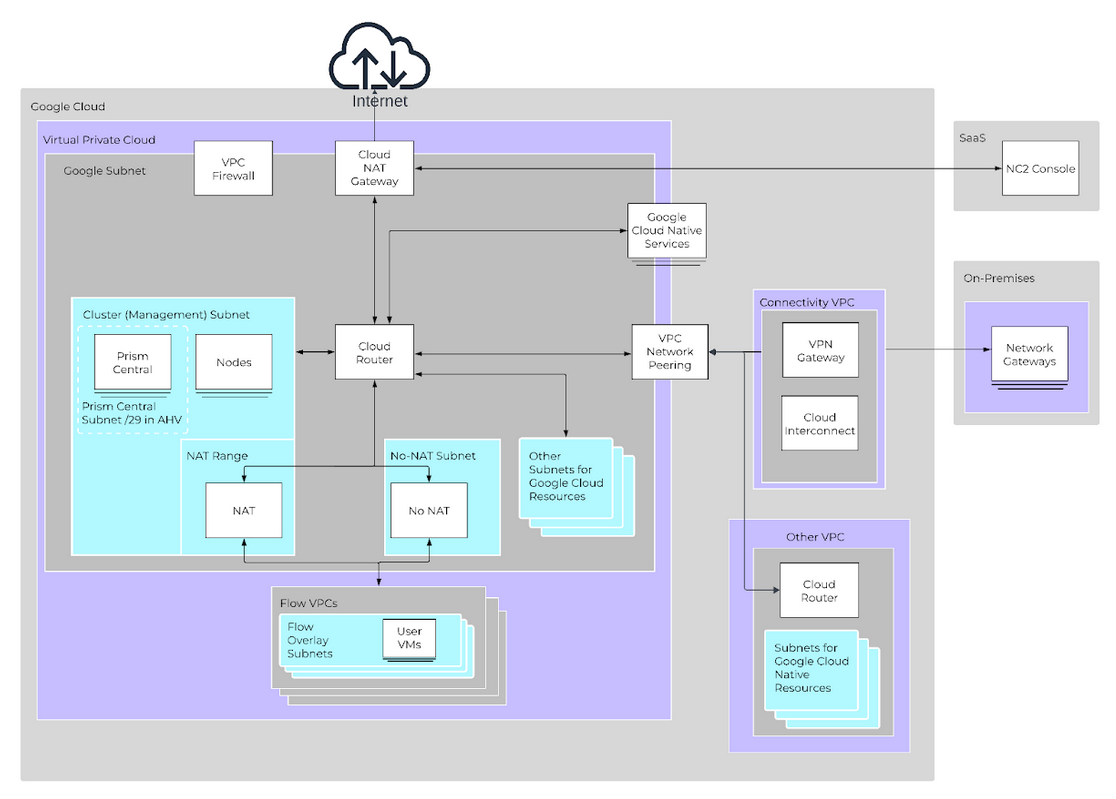
Prism Central contains the control plane for Flow Virtual Networking. The User VMs using the Flow VPC(s) can communicate to native Google Cloud services and allows the VMs to have parity with native Compute Engine VM instances.
Unlike NC2 in Azure, NC2 in Google Cloud does not require Flow Gateway VMs (FGWs).
Usage and Configuration
At a high level, the deployment process for Nutanix Cloud Clusters (NC2) on Google Cloud follows these steps:
- Set up or access an active Google Cloud subscription and project.
- Configure the necessary Google Cloud APIs and create a Service Account with the required IAM roles and permissions.
- (Optional) Configure networking in Google Cloud, including a Virtual Private Cloud (VPC) and the necessary subnets, or use a VPC created automatically during cluster creation.
- Create a My Nutanix account and subscribe to the NC2 service.
- Add your Google Cloud account to an organization in the NC2 console.
- Create a Nutanix Cluster in a new or existing Google Cloud VPC using the NC2 console.
Cloud Management
Nutanixを使用してインフラストラクチャーをモダナイズしたら、次のステップは運用と自動化をモダナイズし、クラウド運用モデルを確立することです。 クラウド運用モデルにより、あらゆる規模の顧客がクラウド プラットフォームをより迅速かつ効率的に構築および管理できるようになります。 目標は、サービス リクエストへの対応に費やす時間を減らし、イノベーションとビジネス価値の提供により多くの時間をかけることです。
クラウド管理の3つの主な側面は次のとおりです:
- 構築
- 操作
- 統治
Nutanix Cloud Managerは独自のデータセンターでクラウド オペレーティング モデルを確立するためのツールを提供し、ネイティブのパブリック クラウド サービスも統合します。 例えば、Nutanix Self-Service(旧称:Calm)を使用すると、ネイティブ インスタンス(EC2、Azure仮想マシン、GCPのCompute Engineインスタンスなど)を使用してインフラストラクチャーをAWS、Azure、またはGCPにデプロイできます。 または、Nutanix Intelligent Operationsを活用して、仮想マシンの挙動を理解し、定型的なタスクのための使いやすい自動化を作成し、将来的なワークロードを計画することもできます。 最後に、Cost GovernanceとSecurity Centralを使用して、クラウド全体のコストとセキュリティを管理できます。
要約すると、Nutanix Cloud Managerには4つのサービスがあります:
- インテリジェントオペレーション(Intelligent Operations)
- コストガバナンス(Cost Governance)
- セルフサービス(Self-Service)
- Security Central
本書ではこれらのサービスについてさらに詳しく説明します。Cost Governanceセクションは近日公開予定です。
NOTE: Security CentralについてはNetwork Services セクションで説明されています。
チャプター
- Intelligent Operations
- Self-Service
Intelligent Operations
次のセクションでは、Nutanix Intelligent Operationsのいくつかの主要機能を説明します。
NOTE: 現在、すべての機能がカバーされているわけではありません。このセクションでは、現時点では次の内容について説明します:
- 異常検出(Anomaly Detection)
- キャパシティプランニング
- X-Playによるローコード/ノーコードでの自動化
残りのIntelligent Operationsの機能については、アップデートをお待ち下さい:
- レポーティング
- 非Nutanix環境のESXiモニタリング(例:3-Tier ESXi環境のモニタリング)
- SQL Serverモニタリング
- アプリケーション検出
- 機械学習によるセルフチューニング(X-Pilot)
異常検出(Anomaly Detection)
IT運用の世界には、多くのノイズがあります。 従来のシステムでは、大量のアラート、イベント、通知が生成されており、多くの場合にオペレーターは、 a) ノイズに紛れて重要なアラートが表示されないか、 b)アラートやイベントを無視していました。
Nutanixの異常検出により、システムは時系列データ(例えば、CPU使用率、メモリ使用率、レイテンシーなど)の季節的傾向を監視し、期待値の「バンド」を確立します。 「バンド」の外にあたる値のみがイベントやアラートをトリガーします。 エンティティまたはイベントのページから異常によるイベントやアラートを確認できます。
以下のグラフは、システムで大規模なバッチロードを実行した際の、多くのI/Oおよびディスク使用率の異常を示します:
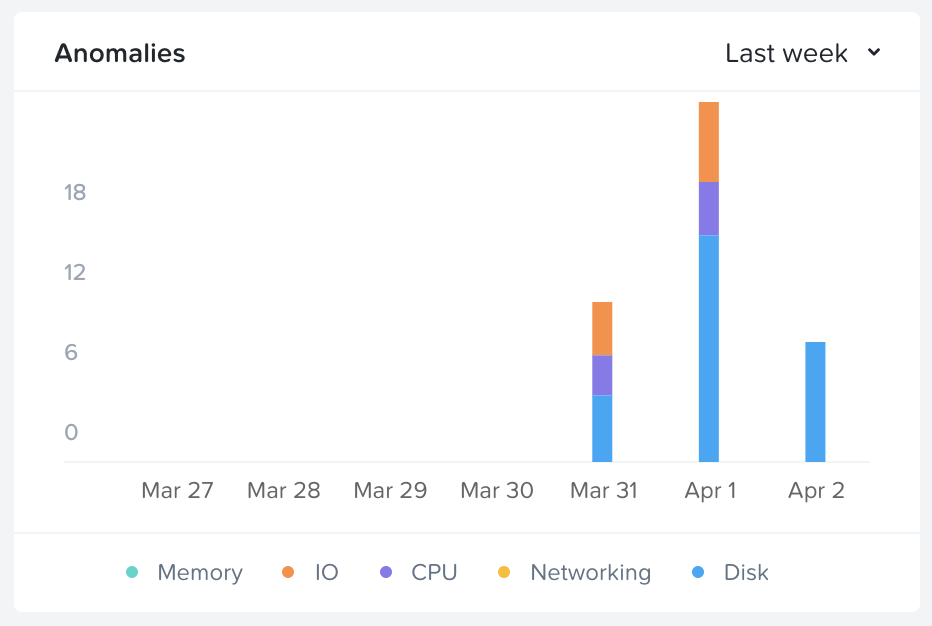
以下は、サンプルメトリックと確立された「バンド」の時系列値を示します:
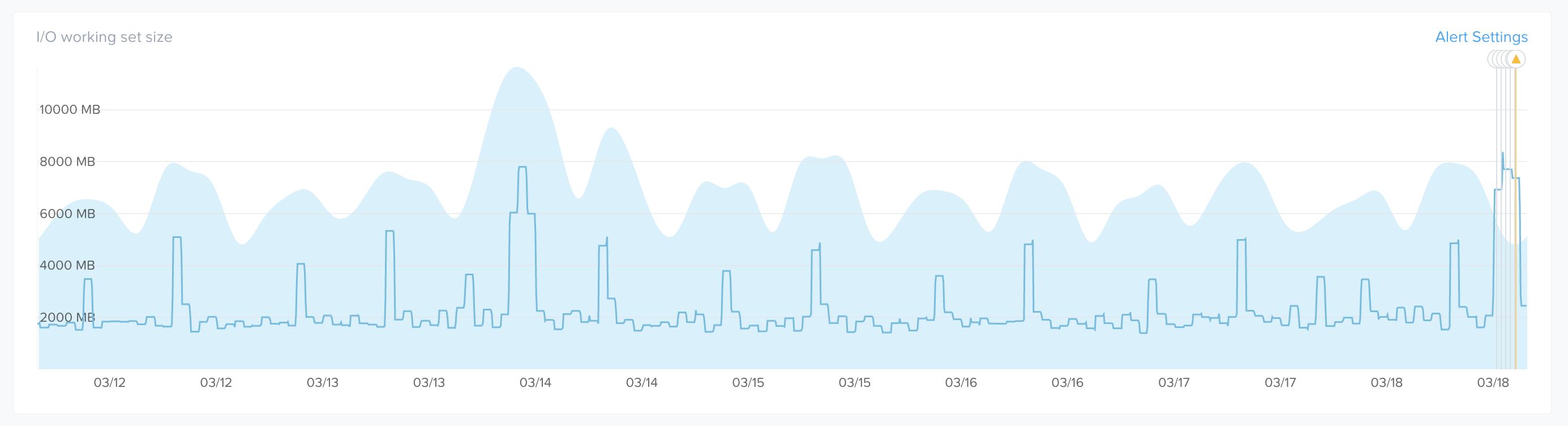
「通常」状態のアラートは望んでおらず、これにより不要なアラートが削減されます。 例えば、データベースシステムは、通常でもキャッシュなどにより95%を超えるメモリ使用率で実行されます。 万が一、これが低下して10%になると、それは何かよくない(データベースサービスのダウンなど)異常かもしれません。
別の例としては、週末のバッチ処理ワークロードがどのように実行されるかです。 例えば、平日にはI/O帯域幅が低く、しかしながらバッチ処理(例えば、バックアップ、レポートなど)が実行される週末には、I/Oに大きなスパイクが発生する場合があります。 システムはこれの季節性を検出して、週末でのバンドを上げます。
ここでは、値が予想される範囲外であるため、異常イベントが発生したことがわかります:
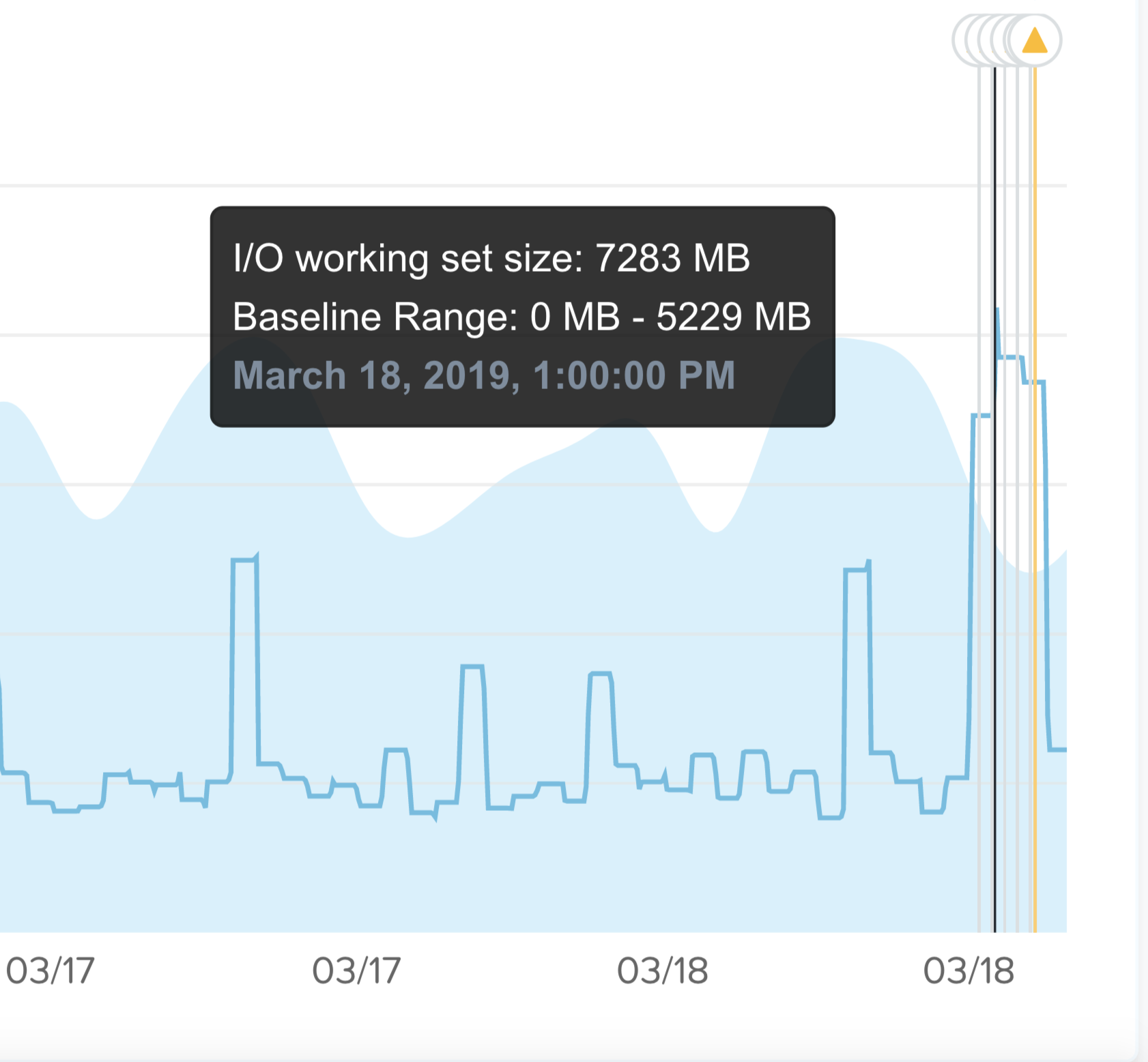
異常のもう1つの興味深いトピックは、季節性です。 例えば小売業者では、年間の他期間より、ホリデー期間中、または月末の終わりに高い需要が見られます。
異常検出ではこのような季節性を考慮し、以下の期間もとにミクロ(毎日)とマクロ(四半期)の傾向を比較します:
- 毎日(Daily)
- 毎週(Weekly)
- 毎月(Monthly)
独自のカスタムアラートまたは静的しきい値を設定することもできます:
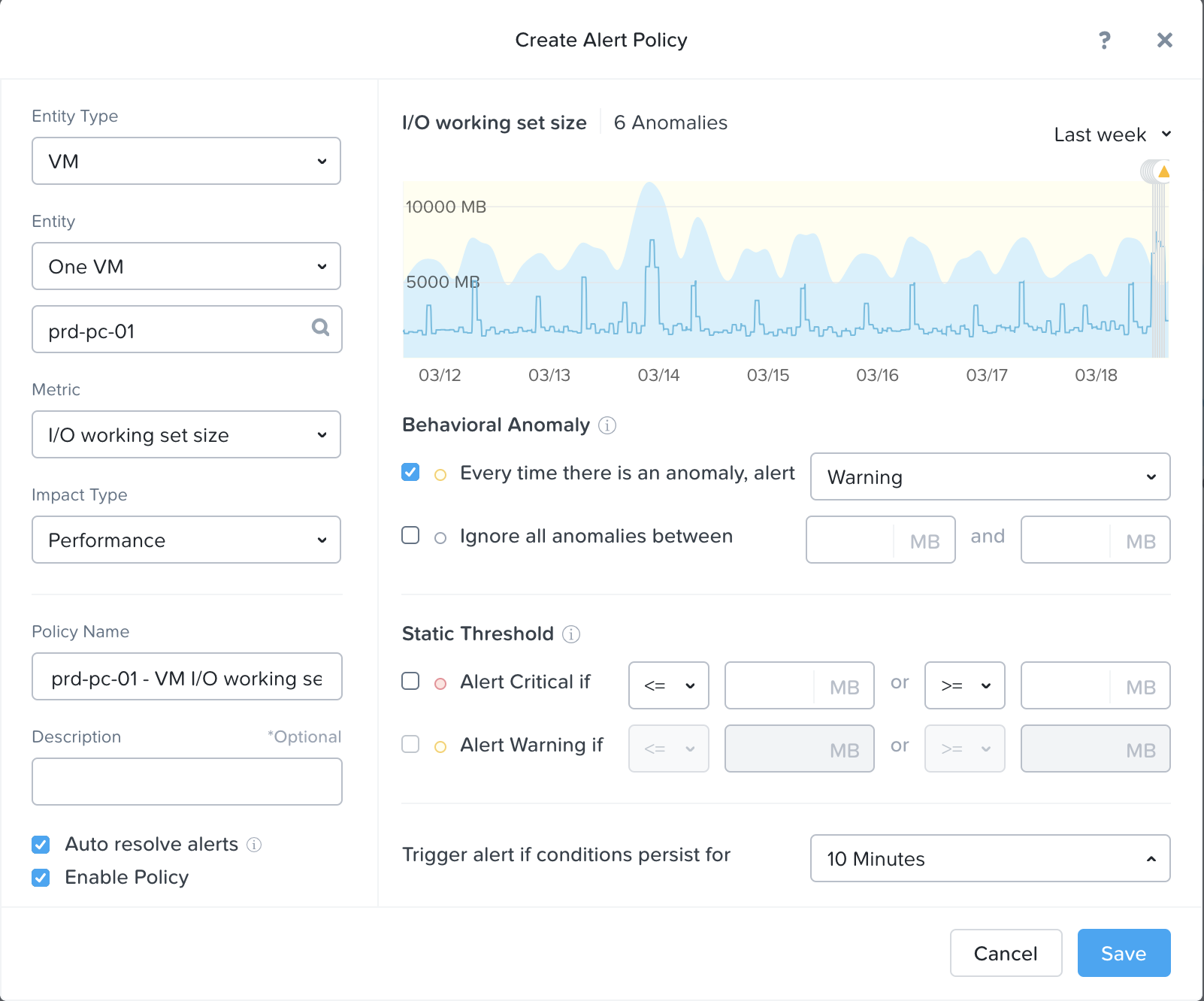
異常検出アルゴリズム
Nutanixは「Generalized Extreme Studentized Deviate検定」と呼ばれるバンドを決定する手法を利用しています。 これについて簡単に考えると、アルゴリズムによって確立された下限と上限の間にある、値の信頼区間に似ています。
アルゴリズムでは、季節性と期待されるバンドを計算するために、3倍の粒度(毎日、毎週、毎月など)が必要です。 例えばそれぞれの季節性に適応するには、以下の量のデータが必要になります:
- Daily: 3 日間
- Weekly: 3 週間 (21 日)
- Monthly: 3 か月間 (90 日)
Twitterには、彼らがこれをどう活用しているかについての良いリソースがあり、ロジックをさらに詳しく説明しています: LINK
キャパシティプランニング
キャパシティプランニングの詳細情報を取得する際には、Prism Centralにある「クラスタランウェイ (Cluster Runway)」セクションで、特定のクラスタをクリックしてください。
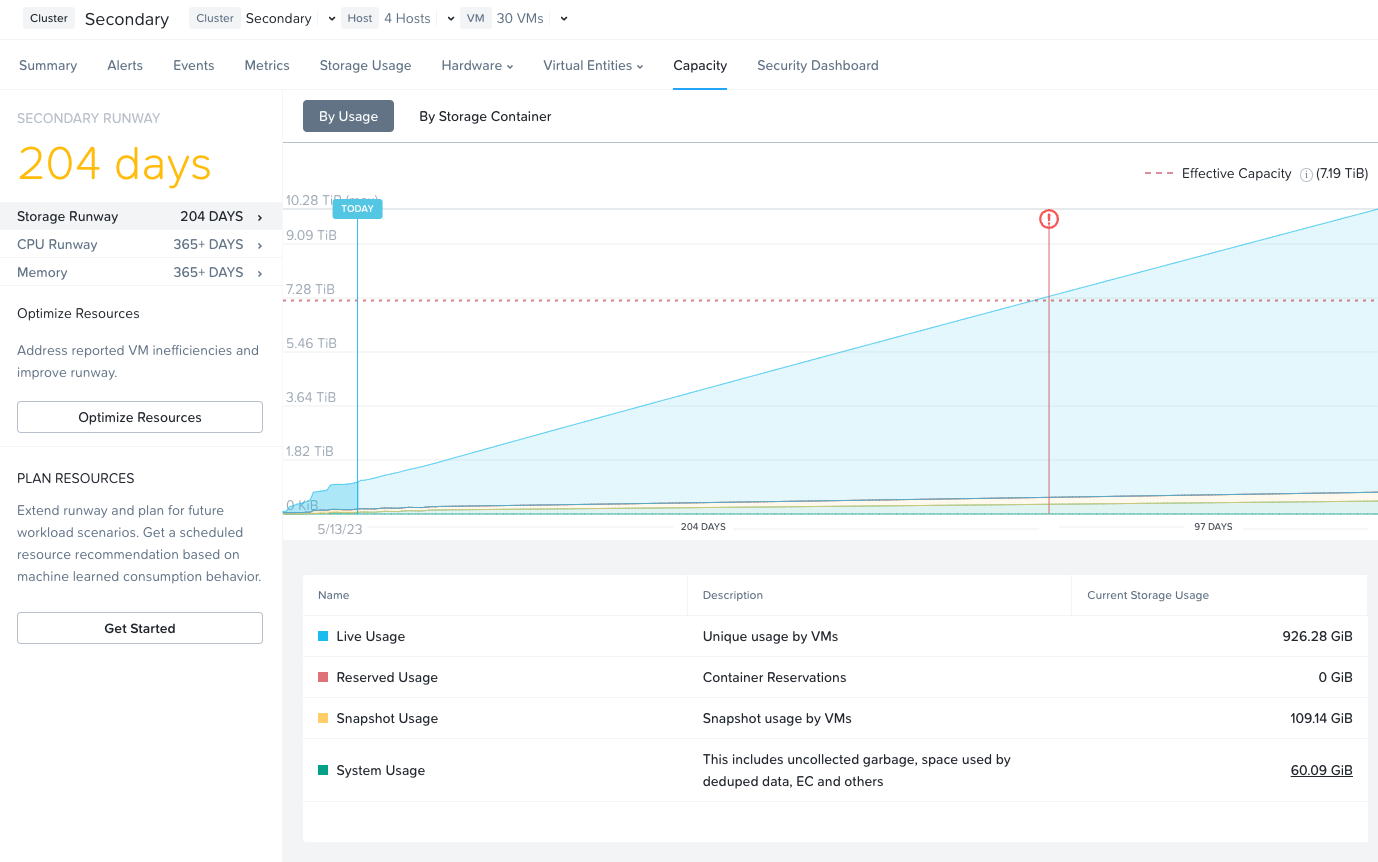
この画面は、クラスタランウェイに関する詳細情報や、最も切迫したリソース(制約的なリソース)に関する情報を表示しています。 また、リソースを大きく消費している対象に関する詳細情報や、キャパシティをクリーンアップできる可能性やクラスタ拡張のための適切なノードタイプに関する情報を得ることができます。
X-Play(クロスプレイ)
日常的な活動を考えると、より多くのことを自動化できます。 私達は日常生活の中でこれを常にルーチンで行っており、テクノロジーによって他の分野と同様のことができます。 Nutanix X-Play(発音はクロスプレイ)では、Prismによって一般的なアクティビティのセットを自動化できます。 製品に飛び込む前に、まずは、何をしようとしているのかを説明します。
イベント駆動型の自動化は、以下のように動作します:
イベント → ロジック → アクション
このシナリオでは、一連のアクションまたは一連のアクションをトリガーする、ある種のイベント(または連なっているイベント)が発生します。 これの良い例は、IFTTT(「if this then that」の略語から)であり、イベントを受け取り、いくつかのロジックを適用し、その後いくつかのアクションを実行します。
例えば、家を出るときには家の明かりを消します。 イベント(例えば、家を出る、デバイスが存在しない)をプログラムして、システムがすべてのライトを自動的にオフにするようにトリガーできれば、私たちの生活がはるかに簡単になります。
これをIT運用のアクティビティと比較すると、同様のパターンが見られます。 イベントが発生(例えば、VMがより多くのディスク領域を必要とする)した際、次に一連のアクション(例えば、チケットの作成、ストレージの追加、チケットのクローズなど)を実行します。 これらの反復的なアクティビティは、自動化によって付加価値を付け、より有益なアクティビティに集中できるようにする完璧な例です。
X-Playを使用すると、一連のイベントやアラートを取得し、システムがそれらを捉えて一連のアクションを実行できるようになります。
開始するには、Infrastructureメニューの「Operations」の下にある「Plays」セクションに移動します:
これにより、メインのX-Playページが開きます:
「Get Started」をクリックして現在のプレイを表示するか、新しいものを作成します:
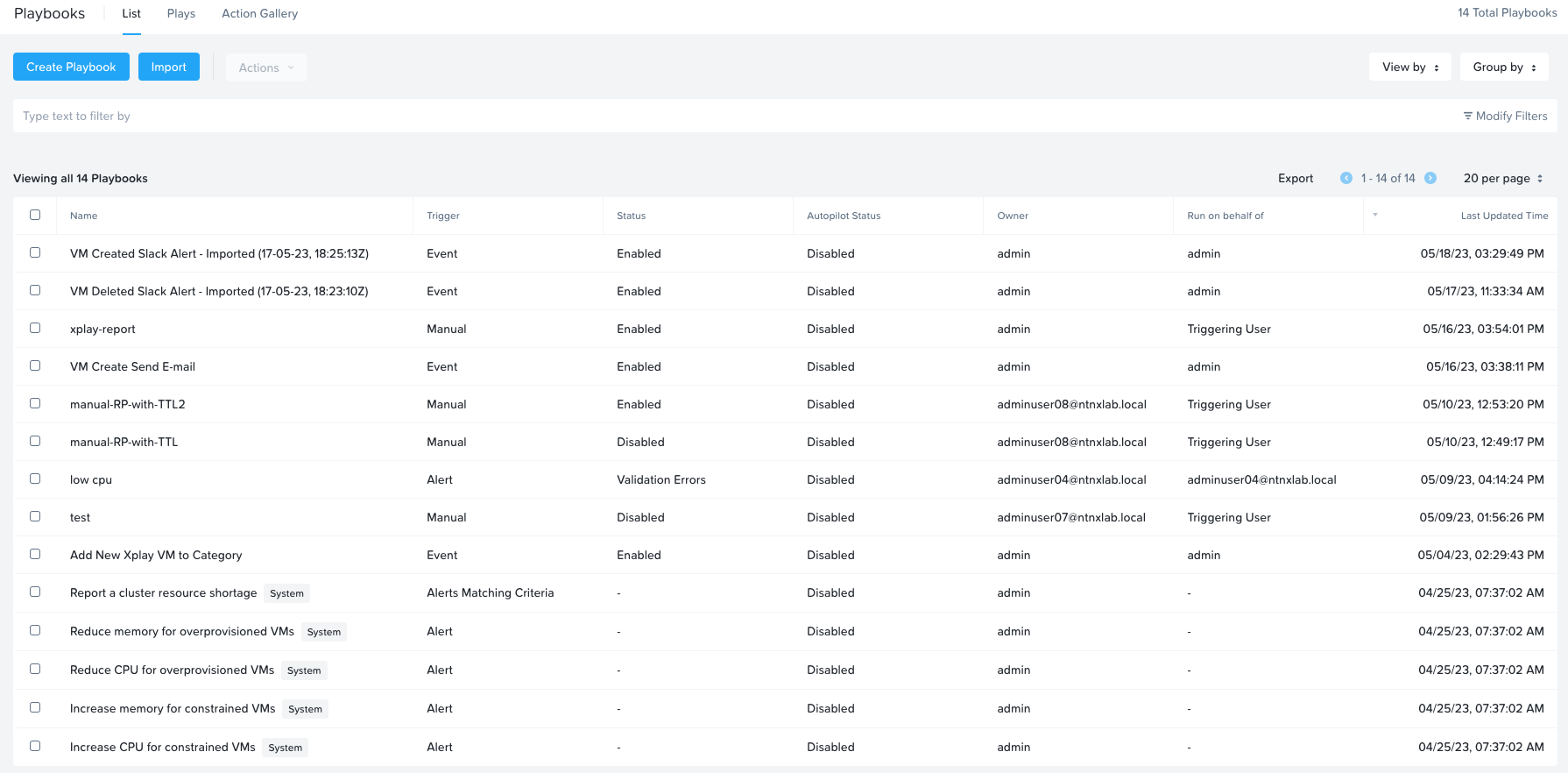
ここから、最初にトリガーを定義して、新しいプレイブックを作成できます:
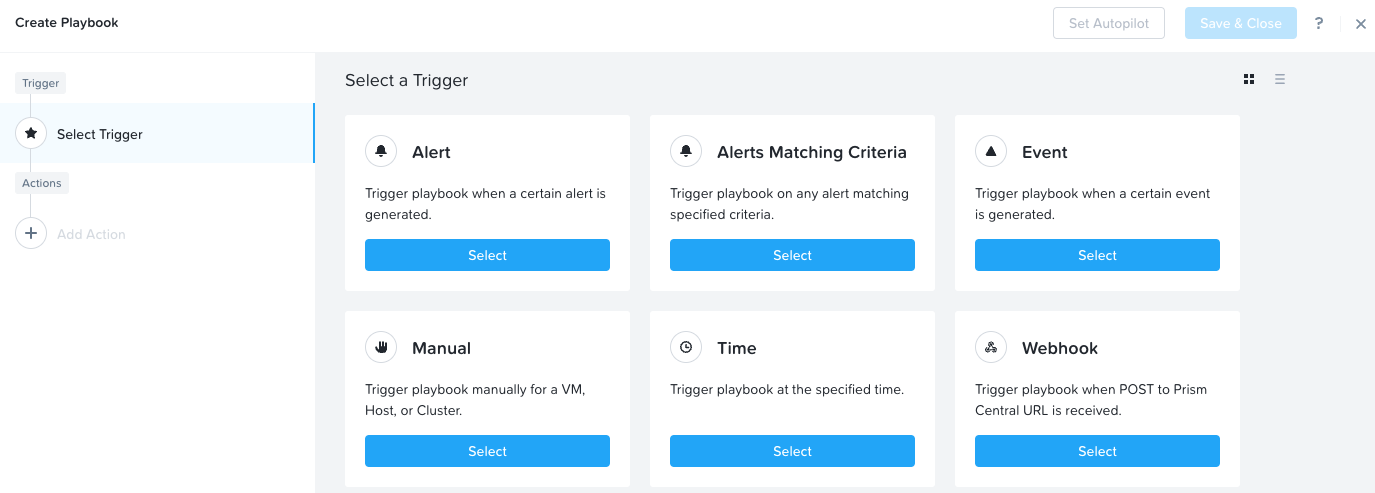
以下に、ユーザー定義のアラートポリシーをもとにしたトリガーの例を示します:
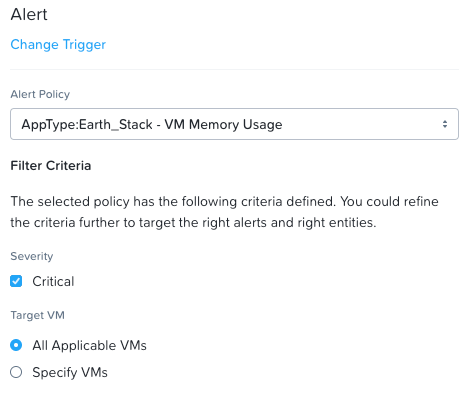
トリガーを定義したら、一連のアクションを指定します。以下に、いくつかのサンプルアクションを示します:
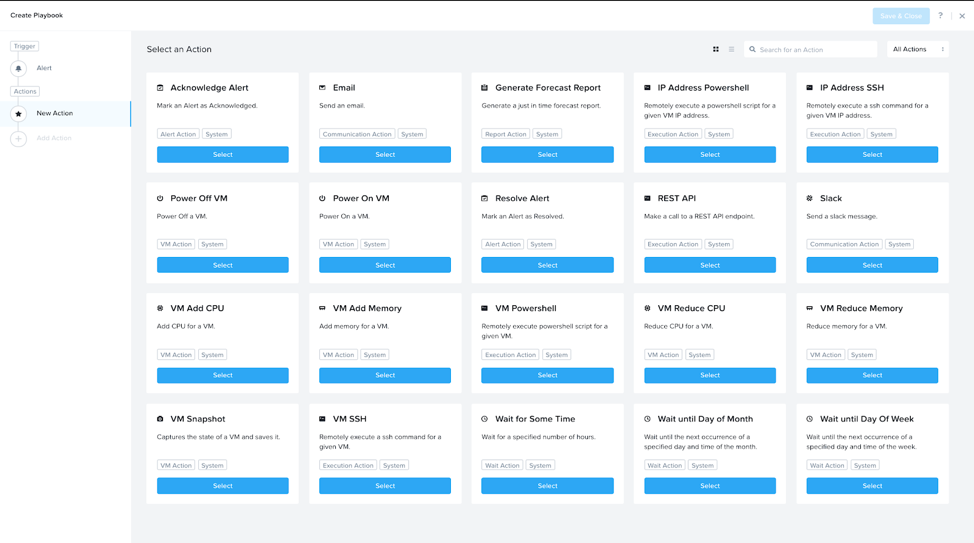
アクションの詳細を入力します。これは、REST APIコールのサンプルを示します:
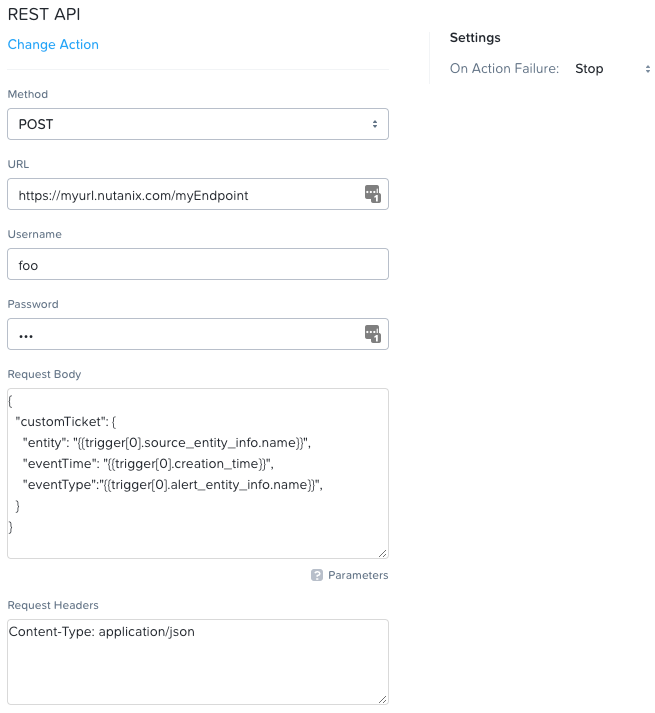
REST APIアクションと外部システム
X-Playは、Eメールの送信、Slackメッセージの送信など多くのデフォルトアクションを提供します。REST APIコールの実行なども同様です。
これは、CMDBやチケット管理、自動化ツールのような外部システムとのインターフェイスを考えるときに重要です。 REST APIアクションを使用することは、チケットの作成や解決、ワークフロー開始などのインターフェイスになります。 これは、すべてのシステムを同期させることができるため非常に強力なオプションです。
エンティティやイベント固有の詳細については、「parameters」変数を使用して取得できます:

完了するとプレイを保存でき、定義どおりに実行開始されます。
以下は、複数のアクションが実行されるプレイのサンプルを示します:
Playsタブには、プレイの実行時間とステータスが表示されます:
ご自身のインスタンスにインポートできるプレイブックの例については、nutanix.devのPlaybooks Libraryをチェックしてください。
また、その他の例やリファレンスについては、Getting Started with Nutanix X-Playを参照してください。
Self-Service
※本書の内容は、PC 7.3、AOS 7.3、Self Service 4.2.0 をベースにしています。
以下のセクションでは、Nutanix Cloud Manager Self-Serviceの主要な機能について説明します。
具体的には:
- ブループリント中心のインフラストラクチャーおよびアプリケーション設計
- Self-Serviceのエンドポイントおよびランブックによる自動化
- Self-Serviceマーケットプレイスを利用した事前構築済みアプリケーションの展開
- Prism CentralプロジェクトとNCM Self-Serviceの統合
- インフラストラクチャー ガバナンスのためのNCM Self-Serviceポリシー
- NCM Self-Service DSL(Domain Specific Language:ドメイン固有言語)
機能の概要
NCM Self-Serviceはマルチクラウド管理フレームワークであり、以下のような主要な利点を提供します。
- 人為的ミスの可能性削減を含む、効率性と俊敏性の向上
- Nutanix AHV、VMware(Nutanixおよび非Nutanix)、AWS、GCP、Microsoft Azure にまたがるマルチクラウド オーケストレーション
- NCM Self-Serviceマーケットプレイスのあらかじめ用意されたブループリントのアプリケーション管理、ならびにクライアントが作成したブループリントをマーケットプレイスに公開する機能
- 全体的なリソース使用状況を分析・可視化するためのCost Governanceとの統合
- Podおよびコンテナによる展開のためのKubernetesとの統合
- Infrastructure-as-Codeのブループリント設計のためのSelf-Service DSL
ブループリント中心のアプリケーション設計
NCM Self-Serviceのブループリントおよびインフラストラクチャー中心のアプリケーション設計により、自動化や展開を担当する管理者は、あらゆる設計のインフラストラクチャーおよびアプリケーションのプロトタイプを迅速に作成し、展開できます。 NCM Self-Serviceのブループリントには、次の2種類のブループリントが用意されています。
- 単一の仮想マシンのブループリント: 単一の仮想マシンと、その関連する展開用スクリプトや依存関係のあるものから構成されるアプリケーションまたはサービス。 依存関係には、ハードウェア構成、オペレーティング システムの種類やバージョン、そして展開が完了する前に実行する必要があるタスクなどが含まれます。 単一の仮想マシンのブループリントについての公式ドキュメントは Nutanix Support Portal にあります。
- マルチ仮想マシン/Podのブループリント: 1つ以上の仮想マシンで構成されるアプリケーションまたはサービスで、それぞれの仮想マシンに関連する展開用スクリプトや依存関係を含みます。 全体的な概念としては、単一の仮想マシンのブループリントに似ていますが、マルチ仮想マシン/Podのブループリントは、アプリケーションの仮想マシン間の関係を展開中に定義できる点が異なり、たとえば、データベースを、そのデータベースに依存するアプリケーションよりも先に展開できます。 コアとなるアプリケーション コンポーネントに加えて、マルチ仮想マシン/Podのブループリントにはスケーリングやライフサイクル管理の構成も含まれており、管理者やトリガーが、アプリケーションの要求に応じて手動または自動で構成を調整できるようになっています。 また、仮想マシンの展開に加えて、マルチ仮想マシン/PodのブループリントはKubernetes環境におけるPodベースのアプリケーション(例:コンテナ、Deployment、Service)の展開もサポートします。 マルチ仮想マシン/Podのブループリントについてのドキュメントは Nutanix Support Portal にあります。
展開する場所
NCM Self-Serviceのブループリントは、オンプレミスおよびクラウドのさまざまな場所への展開に対応しています:
- Nutanix AHVまたはVMware vSphereのオンプレミス
- Nutanix Cloud Clusters (NC2)、Amazon AWS、Microsoft Azure、Google Cloud Platform、Kubernetesを含むクラウド ロケーション
ブループリントの例
この図は、マルチ仮想マシン/Podのブループリントについての一例を示しています。 具体的には、以下の構成項目が表示されています:
- 単一の仮想マシンのハードウェア構成、すなわち、vCPU、vCPUあたりのコア数、仮想マシンのRAM(GiB単位)、そしてこの例では展開される仮想マシンに適用されるLinux Cloud-initの仕様が含まれます。 このCloud-Init仕様には、展開された仮想マシンへのSSHログインを許可するSSHキーも含まれています。
タイプのクラスタを展開し、そこに異種ノードを追加してクラスタの容量を拡張できます。
NCM Self-Serviceのブループリントは、タスクを通じて展開処理を実行します。 タスクには、展開を完了するために必要な個々のステップやアクション、またDay-2オペレーションの場合は、既存の展開をカスタマイズするステップやアクションが含まれます。 タスクは、アプリケーションの要件に応じて、逐次的または並列的に実行できます。
たとえば、典型的な仮想マシンの展開には「パッケージのインストール」ステップが含まれ、そこで仮想マシンの構成をカスタマイズするタスクが実行されます。 これらのタスクは、仮想マシンのベースとなるオペレーティングシステムが展開された後、さらにCloud-init(Linux)またはSysprep(Windows)による仮想マシンのカスタマイズが完了した後に実行されます。
ここに示す例は、上のスクリーンショットにある同じ仮想マシンであり、「パッケージのインストール」ステップでは、2つのスクリプトが実行されます。
- BaseVMConfiguration という名前のタスク: Linux OSのパッケージ キャッシュとシステム パッケージを更新するシェル スクリプトのタスクです。 このステップには、「firewalld」という名前のLinuxパッケージのインストールが含まれます。
- ConfigureFirewall という名前のタスク: firewalldサービスを構成し、その後に起動するシェル スクリプトのタスクです。
この例をさらに詳しく見ると、スクリプトを実行する場所(Endpoint)、タスクの種類(Execute)、スクリプトの種類(Shell)、そしてスクリプトを実行するために使用される認証情報(admin)を選択できるタスクの詳細が確認できます。
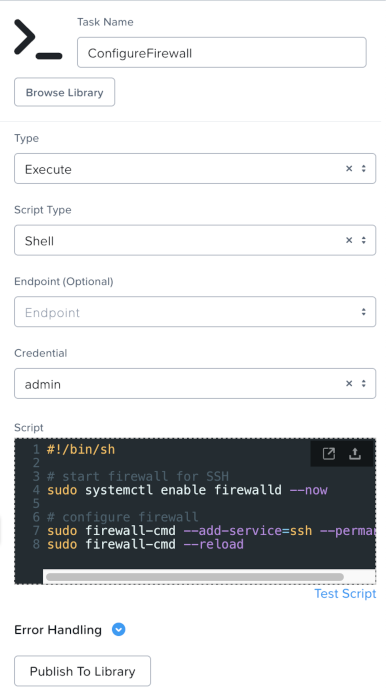
ブループリントのタスク スクリプトは、組み込みのSelf-Serviceライブラリに簡単に保存でき、複数のブループリント間で迅速かつ容易に再利用できます。
ブラウンフィールド アプリケーション
NCM Self-Serviceの文脈において、ブラウンフィールド アプリケーションとは、まだ Self-Serviceによって管理されていないサービス(例:仮想マシン)の集合を指します。 Self-Serviceがそれらのサービスとやりとりできるようにするには、まずそのアプリケーションをブラウンフィールドアプリケーションとしてSelf-Serviceにインポートする必要があります。
ブラウンフィールド アプリケーションの要点:
- 権限:ブラウンフィールド アプリケーションをインポートするには管理者権限が必要
- ブラウンフィールド アプリケーションでは、スナップショットおよびリストア機能はサポートされない
詳細については、Brownfield Apps in Self-Service を参照してください。
ランブックによる自動化
NCM Self-Service は、Runbookを介して手動およびトリガー ベースの処理をサポートします。 NCM Self-Serviceのコンセプトにおいて、ランブックは特定の目的を達成するために逐次的に実行できる一連のステップとして定義されます。 たとえば、手動実行のランブックを作成し、以下のステップを完了させることができます:
- Nutanix v4 APIを使用して、「Super Admin」という名前のNutanix IAMロールの識別子を取得する
- 新しいサービス アカウントのユーザーを作成し、その新しいユーザーを前のステップで取得した「Super Admin」ロールに関連付ける
- 新しいユーザー用に一意のAPIキーを作成する
- 新しいユーザーに対して、仮想マシンの新規作成と既存仮想マシンの一覧取得を許可するNutanix IAM認可ポリシーを作成する
この実際のランブックは、新しい仮想マシンの作成をNutanix X-Playが検出した際に実行されるステップの例です。 これらの2機能を組み合わせることで、認証と認可のスキームを作成する際に必要な手動入力を大幅に削減できます。
以下に示す例は、このランブックに、すべての前段のステップが正常に完了したことを検証する最終的なテスト ステップを追加したものです。
追加の例として、ここに示すランブックは、上記と同じステップを実行しますが、最初にタスクを追加しています。 具体的には、このランブックは「Super Admin」ロールのIDを取得し、そのロールが見つかったことを確認するチェックを行います。 ロールが見つからなかった場合、ランブックは変更を加えることなく安全に終了します。 ロールが見つかった場合、ランブックは設計どおりに残りのタスクを順に実行していきます。
エンドポイント
NCM Self-Serviceランブック内の各ステップは、特定のエンドポイントに関連付けることができます。 ランブック実行において特定のステップを実行するという文脈では、これによりランブック設計者は特定のステップを異なるシステム上で実行できるようになります。
たとえば、REST APIリクエストを送信するステップは、最初のリクエストをPrism Centralインスタンス「a」に送信し、そのリクエストの結果を出力変数に保存したうえで、後続のステップをPrism Centralインスタンス「b」で実行できます。 これにより、ランブックは単一のPrism Centralインスタンス環境、複数のPrism Centralインスタンス環境、あるいは任意の(ユーザーが構成した)エンドポイントの環境で動作させることができます。 NCM Self-Serviceがそのエンドポイントにログインできる限り、構成可能なエンドポイントの種類に制限はありません。
追加の例として、セキュリティ体制によってスクリプトの実行が特定のホスト上でのみ行われなければならない環境において、ジャンプ ホスト上でPowerShellやPythonのスクリプトを実行する場合が含まれます。
NCM Self-Serviceのブループリントと同様に、スクリプトは迅速にNCM Self-Serviceライブラリへ保存して容易に再利用でき、あらかじめ作成されたスクリプトが必要な場合にはライブラリから直接読み込めます。
マーケットプレイスでのアプリケーション展開
単一の仮想マシンおよびマルチ仮想マシンのブループリントを使用すると、特定の要件に応じて高度にカスタマイズされたアプリケーションを作成できます。 そしてアプリケーションの設計が完了すると、そのアプリケーションはNCM Self-Serviceマーケットプレイスを通じて、展開する管理者に提供できます。
NCM Self-Serviceマーケットプレイスは、事前に構成されたアプリケーションを展開承認リクエストをもとに展開するための仕組みであり、変更が加えられる前の展開手順の分析、そして必要に応じて展開リクエストを却下する機能を備えています。
初期状態で、ベストプラクティスの展開手法に沿った、複数の事前パッケージ化されたマーケットプレイス アプリケーションが利用可能です。 これには、LAMP Stack(Linux、Apache、MySQL、PHP)、Jenkins、GitLabなど、よく知られた人気のアプリケーションが含まれます。 すべてのアプリケーション、すなわち組み込みのものとカスタムのものの両方は、バージョン管理されており、展開されるアプリケーションが環境の要件を満たしていることを、変更が加えられる前に保証します。
ここでは、組み込みのLAMP Stackアプリケーションが示されており、含まれているアクションの一部について説明しています。 NCMのアプリケーションまたはブループリントの文脈において、アクションとは、展開中に実行されるステップ、もしくは展開後に、オンデマンドまたは特定のトリガーに基づいて実行できるステップのいずれかを指します。
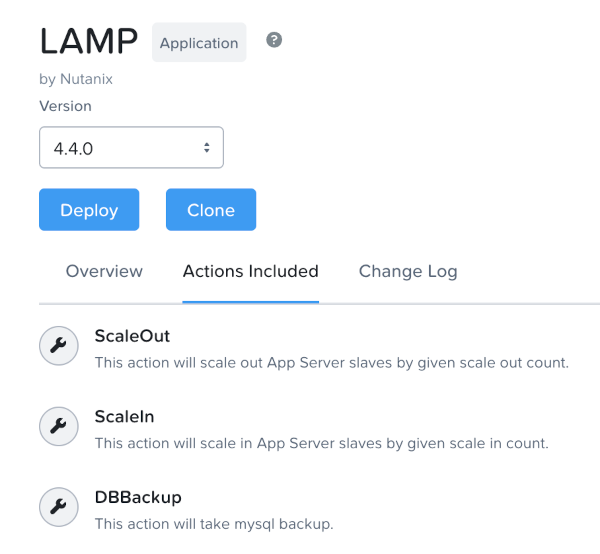
展開を要求するユーザーに付与されている権限に応じて、アプリケーションのインストールを通常どおり進行するか、または認可されたユーザーによる承認待ちキューに入れられます。
すべてのNCM Self-Serviceブループリント(単一の仮想マシンのブループリントを含む)は、NCM Self-Serviceマーケットプレイスに公開できます。 これによりIT管理者が管理するアプリケーションを、テスト/開発フェーズと本番展開フェーズの両方で幅広くカスタマイズ可能になります。 公開プロセスの一環として、承認フローが組み込まれており、いずれのユーザーも展開を要求する前に、そのアプリケーションのマーケットプレイス公開について承認を受ける必要があります。
次のスクリーンショットは、NCM Self-ServiceのUIからブループリントの展開を直接監視できる機能を示しています。 この展開画面は、ブループリント デザイナーからの手動によるアプリケーション起動時と、マーケットプレイスから起動されたアプリケーションの監査(Audit)タブの両方で利用できます。
組み込みのアプリケーション ブループリント
組み込みの、利用可能な事前構築済みアプリケーションの一部は次のとおりです:
- LAMP Stack(Linux、Apache、MySQL、PHP)
- CouchDB(オープンソースのデータベース)
- GitLab (WebベースのGitリポジトリ マネージャー)
- OpenLDAP(オープンソースのLDAP実装)
- Redis Cluster(インメモリーのデータ構造ストア)
- Jenkins(オープンソースの自動化サーバー)
承認を含むすべてのSelf-Serviceマーケットプレイスの管理操作は、マーケットプレイス マネージャーを通じて実行されます。
Prism CentralのプロジェクトとSelf-Serviceの統合
NCM Self-ServiceはPrism Centralのプロジェクトを広範に活用します。 プロジェクトとは、仮想マシンやアプリケーションをどのように、どこに展開できるかを定義するコンポーネントと構成の集合体です。
例:
- ユーザーとグループ
- インフラストラクチャー
- 仮想マシンやアプリケーション コンポーネントをホストするクラスタ
- 関連するネットワーク リソース(例:サブネット)
- NCM Self-Serviceのポリシー エンジンを介したポリシーとクォータ
- Nutanix Database Services(NDB)などのリンクされたサービス
次のスクリーンショットは、プロジェクト構成中のインフラストラクチャーの選択を示しています。 プロジェクトの作成または編集時にこれらを選択することで、管理者は展開を特定のクラスタに制限し、そのクラスタ内の特定サブネットへの接続に制限できます。
Prism CentralプロジェクトのNCM Self-Serviceへの統合により、どのユーザーが特定のタスクを実行できるか、どこでそれらのタスクを実行できるか、そしてユーザーの展開が消費できるリソース数の上限を制御できるようになります。 このクォータ管理のアプローチは、NCM環境におけるテナント管理に対して、堅牢で高度に構成可能な方法を提供します。
プロジェクトの分析
NCM Self-ServiceとPrism Centralプロジェクト間の深い統合により、プロジェクト内のワークロード割り当ての分析を容易に可視化できます。 ユーザーは、プロジェクト内で展開されたアプリケーションのリソース利用状況、特定のプロジェクトで展開されている仮想マシンの数、そしてそのプロジェクトのクォータ消費量をすばやく把握できます。
次のスクリーンショットは、選択したプロジェクトの上位ワークロードを示しています。
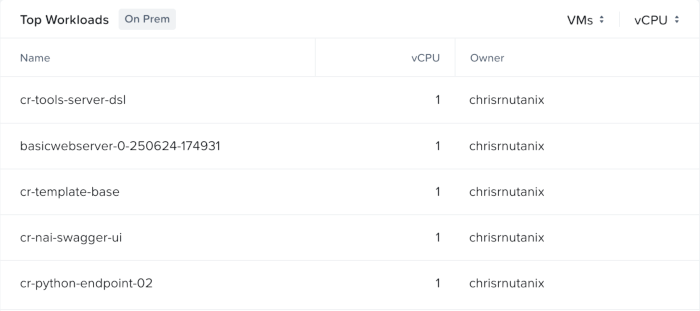
次のスクリーンショットは、仮想マシンの展開数と展開済みアプリケーションの対比によるワークロードのサマリーを示しています。
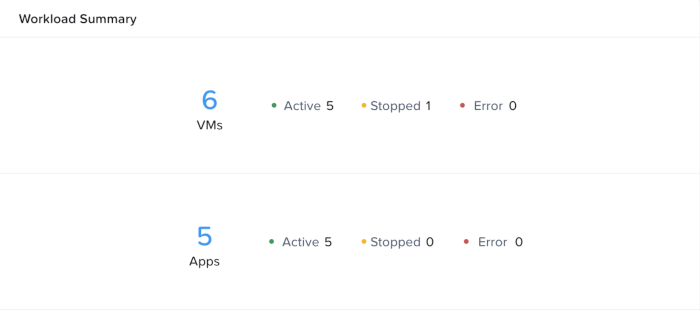
Self-Service ポリシー
スケジューラー ポリシーにより、Self-Serviceの管理者はスケジュールされたタスクを作成できます。 たとえば、営業時間外の所定の時刻にアプリケーションを停止し、翌営業日にアプリケーションを再起動する、といったスケジュールされたタスクです。 また、スケジュールされたタスクを使ってNCM Self-Serviceのランブックを実行することも可能であり、管理者は選択したエンドポイントで、特定の時刻に定義済みの手順のセットを実行できます。
Self-Serviceのポリシー機能は、アプリケーションの承認に関しても詳細な制御を提供します。 このレベルのガバナンスは、前述のSelf-Serviceマーケットプレイス機能に直接結びついており、どのアプリケーションやアクションが実行前に承認を必要とするかを定義します。
スケジューラー ポリシーと承認ポリシーの組み合わせは、特に時間課金の環境で稼働するインフラストラクチャー リソースに関して、コストに関する問題を防ぐのに役立ちます。
すべてのNCM Self-Serviceポリシーはポリシー エンジンを通じて管理され、NCM Self-ServiceのUI内で直接取り扱われます。
次のスクリーンショットは、承認ポリシー作成の例を示しています。 この例では、「CustomApp」という名前のアプリケーションを起動するたびに、選択されたユーザー(administrator)全員の承認を完了する必要があります。
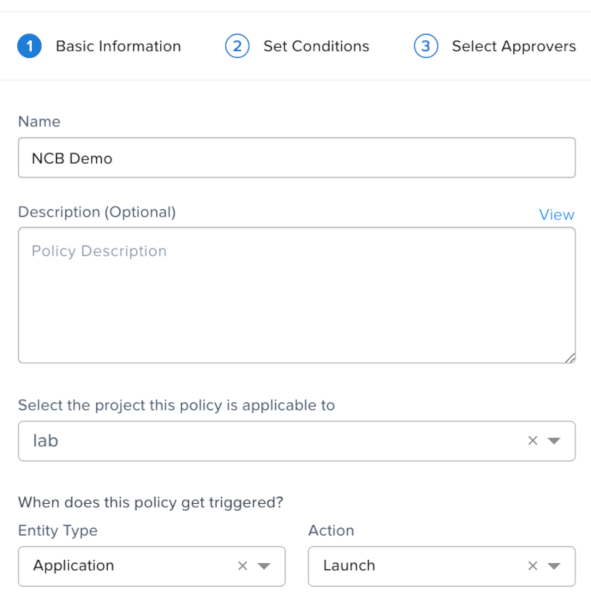
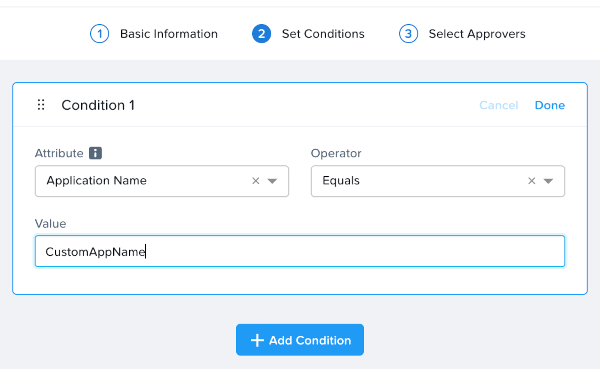
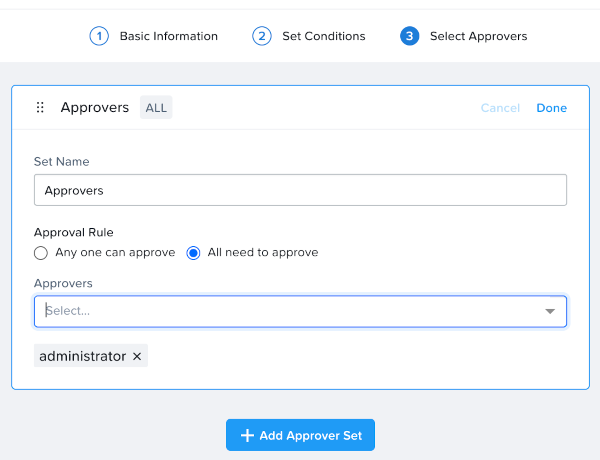
同様に、次のスクリーンショットは、特定の時刻にアプリケーション アクションを実行する例を示しています。 この例では1回限りの実行を示していますが、繰り返しスケジュールも同じUIで設定します。
NCM Self-Service DSL(Domain Specific Language:ドメイン固有言語)
Self-ServiceのUIで利用できる広範な管理機能に加えて、NCM Self-Serviceは非常に幅広く、開発者フレンドリーなDSLを提供します。 DSL(Domain Specific Language:ドメイン固有言語)は、開発者やスクリプトを作成する管理者が、標準的なプログラミング手法でSelf-Serviceを活用できるようにするものです。 NCM Self-Service DSLは特にオープンソースのPython言語で実装されており、Pythonスクリプトから直接Self-Serviceの機能をプログラム制御できます。
Self-Service DSL のハイライトは次のとおりです:
- 使いやすさ:直感的で分かりやすい構文により、ブループリントの作成、アプリケーションの起動、Day-2オペレーションなど、主要なNCM Self-Service機能を容易に使用できます。
- プラットフォーム非依存:Pythonは幅広いOSでサポートされているため、Self-Service DSLのコードも同様に多様な環境で利用できます。
- ポータビリティ:DSLベースの完全な展開は、パッケージ化して最小限の労力で環境間を移動でき、GitHubやGitLabなどのソース管理システムに保存できます。
Prism
Prism - プリズム - 名詞 - コントロールプレーン
データセンター運用をワンクリックで可能にするインターフェイス
洗練され、愛着を感じることができる直観的な製品を構築することは、Nutanixプラットフォームの核心であり、私達はそれに真剣に取り組んでいます。 本セクションでは、Nutanixのデザインメソドロジーとその適用について説明します。
また、NutanixのVisioのステンシルはこちらからダウンロードいただけます: http://www.visiocafe.com/nutanix.htm
チャプター
- Prismのアーキテクチャー
- ナビゲーション
- 機能と使用方法
- マイクロサービス インフラストラクチャー
- Prism Central Backup and Restore
Prismのアーキテクチャー
Prismは分散リソース管理プラットフォームであり、ローカルとクラウドのどちらでホストされているかにかかわらず、 ユーザーがNutanix環境全体のオブジェクトやサービスを管理およびモニターすることができます。
これらの機能は、以下2つの主要なカテゴリに分けられます:
- インターフェイス
- HTML5 UI、REST API、CLI、PowerShell コマンドレットなど
- 管理
- ポリシー定義とコンプライアンス、サービス設計とステータス、分析とモニタリング
以下は、Nutanixプラットフォームの一部としてのPrismを概念的に図示したものです:

Prismは、2つの主要コンポーネントに分けられます:
- Prism Central (PC)
- 複数のNutanix Clusterを、1つの集中管理インターフェイスから管理するためのマルチクラスタマネージャー。 Prism Centralは、AOS Clusterに追加導入し稼動することが可能な、オプションのソフトウェアアプライアンス (VM) です。
- 1対多のクラスタマネージャー
- Prism Element (PE)
- 単一のクラスタの管理と運用のためのローカルクラスタマネージャー。全てのNutanix Clusterに、Prism Elementが組み込まれています。
- 1対1のクラスタマネージャー
以下は、Prism CentralとPrism Elementの関係を概念的に図示したものです:

プロからのヒント
大規模な環境、あるいは分散環境(例えば1クラスタ以上あるいは複数のサイト)に導入する場合、運用のシンプル化を図るため、Prism Centralを使用し、 全てクラスタやサイトへの対応を1つの管理UIから実施できるようにすることを推奨します。
Prismのサービス
Prismのサービスは、HTTPリクエストに対応する特定のPrismリーダーと連携しながら、全てのCVM上で動作します。 「リーダー」を持っている他のコンポーネントと同様、Prismリーダーに障害が発生した場合、新しいリーダーが選定されます。 PrismリーダーではないCVMがHTTPリクエストを受け取ると、当該リクエストはPrismリーダーに、HTTPレスポンスステータスコード301を使用して、恒久的にリダイレクトされます。
以下は、PrismのサービスとHTTPリクエストの処理を概念的に図示したものです:
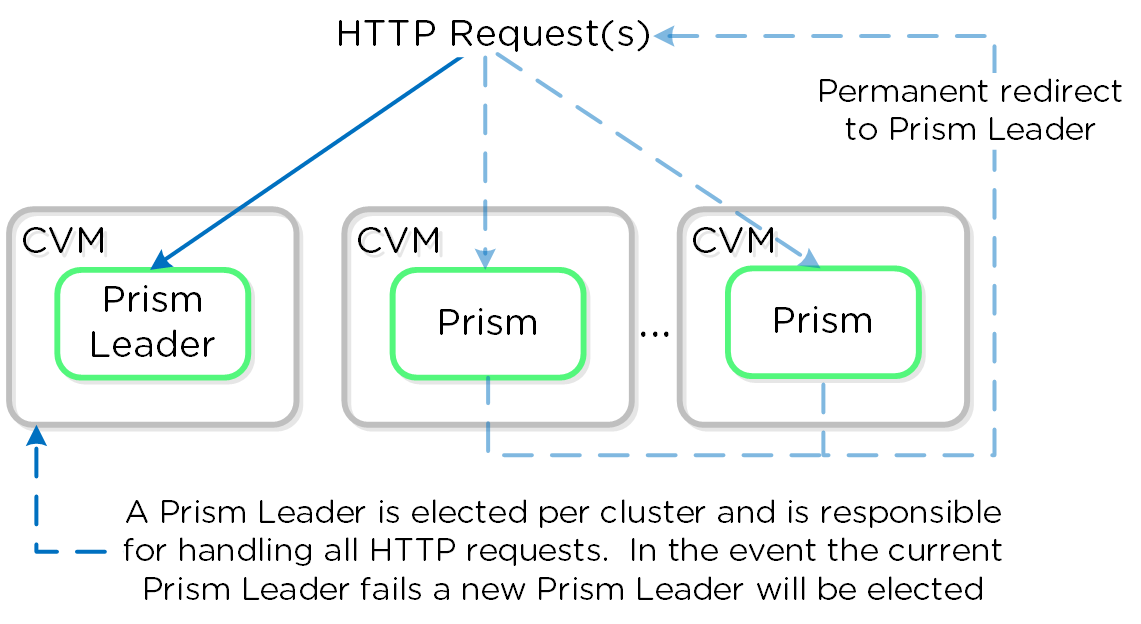
Prismのポート
Prismは、ポート80と9440を使用します。HTTPトラフィックがポート80に到達した場合、ポート9440のHTTPS側にリダイレクトされます。
クラスタの外部IPを使用する場合(推奨)、同IPは常に現在のPrismリーダーによってホストされます。 Prismリーダーに障害が発生した場合、クラスタIPは新たに選択されたPrismリーダーが引継ぎ、gratuitous ARP(gARP)は、古くなったARP(stale ARP)のキャッシュ エントリーをクリアするために使用されます。 本シナリオの場合、常にクラスタIPがPrismのアクセスに使用され、既にPrismリーダー内に存在するため、リダイレクトする必要がありません。
プロからのヒント
最新のPrismリーダーを特定するためには、いずれかのCVMで 'curl localhost:2019/prism/leader' を実行します。
認証とアクセス制御(RBAC)
認証
Prismは現在、以下の認証プロバイダーとのインテグレーションをサポートしています:
- Prism Element (PE)
- ローカル
- Active Directory
- LDAP
- Prism Central (PC)
- ローカル
- Active Directory
- LDAP
- SAML認証 (IDP)
SAMLと2要素認証(2FA)
SAML認証により、PrismはSAML準拠の外部IDプロバイダー(IDP、例えばOkta、ADFSなど)と統合できます。
これにより、プロバイダーサポートするPrismへのログインユーザーで、多要素認証(MFA)や2要素認証(2FA)機能を活用できます。
アクセス制御
近日公開
ナビゲーション
Prismの使用方法は極めて簡単ですが、いくつかの主要なページとその基本的な使用法をカバーしておきます。
Prism Central(導入されている場合)には、設定中に指定されたIPアドレス、または対応するDNSエントリーを使ってアクセスすることができます。 Prism Elementには、Prism Central(特定のクラスタをクリック)か、いずれかのNutanix CVMまたはクラスタIP(推奨)からアクセスできます。
ページがロードされると、ログインページが表示され、PrismまたはActive Directoryの認証情報を使ってログインすることができます。
ログインに成功すると、ダッシュボードページに遷移し、Prism Centralが管理している(複数の)クラスタ、またはPrism Elementが管理しているローカルクラスタに関する概要情報が表示されます。
Prism CentralとPrism Elementについては、以下のセクションで詳しく解説します。
Prism Central
図は、複数のクラスタをモニタリングおよび管理している状態のPrism Centralダッシュボードの例です:
ここから、環境の全体的なステータスを監視し、アラートや気になる項目がある場合はさらに詳しく調べることができます。
Prism Centralには、以下の主要なページが含まれています(注:検索は、ナビゲーションにおいて優先、推奨される方法です):
- ホームページ
- サービスのステータス、キャパシティプランニング、パフォーマンス、タスクなどに関する詳細情報を含む、環境全体をモニターするためのダッシュボード。詳細な情報を取得するには、対象となる項目をクリックします。
- 仮想インフラ
- 仮想エンティティ(VM、コンテナ、イメージ、カテゴリなど)
- ポリシー
- ポリシーの管理と作成(セキュリティ(Flow)、保護(バックアップとレプリケーション)、リカバリ(DR)、NGTなど)
- ハードウェア
- 物理デバイスの管理(クラスタ、ホスト、ディスク、GPUなど)
- アクティビティ
- 環境全体のアラート、イベント、タスク
- オペレーション
- 操作ダッシュボード、レポートおよびアクション(X-Play)
- 管理
- 環境構成の管理(ユーザー、グループ、ロール、アベイラビリティ ゾーンなど)
- サービス
- アドオンサービスの管理(例えば、Calm、Karbon)
- 設定
- Prism Centralの設定
メニューにアクセスするには、ハンバーガーアイコンをクリックします:
メニューが展開され、使用可能なオプションが表示されます:
検索
検索は、Prism Central UIを移動するための主な手順になりました(メニューは引き続き使用可能です)。
検索バーを使用して移動するには、画面左上隅にあるメニューアイコンの横にある検索バーを使用します:
検索のセマンティクス
PCの検索では、多くのセマンティクスを利用できます。例えば、次のようなものです:
| ルール | 例 |
|---|---|
| Entity type | vms |
| Entity type + metric perspective (io, cpu, memory) | vms io |
| Entity type + alerts | vm alerts |
| Entity type + alerts + alert filters | vm alerts severity=critical |
| Entity type + events | vm events |
| Entity type + events + event filters | vm events classification=anomaly |
| Entity type + filters (both metric and attribute) | vm “power state”=on |
| Entity type + filters + metric perspective (io, cpu, memory) | vm “power state”=on io |
| Entity type + filters + alerts | vm “power state”=on alerts |
| Entity type + filters + alerts + (alert filters) | vm “power state”=on alerts severity=critical |
| Entity type + filters + events | vm “power state”=on events |
| Entity type + filters + events + event filters | vm “power state”=on events classification=anomaly |
| Entity instance (name, ip address, disk serial etc) | vm1, 10.1.3.4, BHTXSPWRM |
| Entity instance + Metric perspective (io, cpu, memory) | vm1 io |
| Entity instance + alerts | vm1 alerts |
| Entity instance + alerts + alert filters | vm1 alerts severity=critical |
| Entity instance + events | vm1 events |
| Entity instance + events + event filters | vm1 events classification=anomaly |
| Entity instance + pages | vm1 nics, c1 capacity |
| Parent instance + entity type | c1 vms |
| Alert title search | Disk bad alerts |
| Page name search | Analysis, tasks |
上記はセマンティクスのほんの一部に過ぎず、慣れるための最善の方法は実行してみることです!
Prism Element
Prism Elementには、以下の主要なページが含まれています:
- ホーム (Home) ページ
- アラート、キャパシティ、パフォーマンス、ヘルス、タスクなどに関する詳細情報を含む、ローカルクラスタをモニターするためのダッシュボードです。詳細な情報を取得する際には、対象となる項目をクリックします。
- Health ページ
- 環境、ハードウェアおよび管理下にあるオブジェクトのヘルスと状態に関する情報。NCCヘルスチェックステータスも含まれています。
- VMページ
- 完全なVM管理、モニタリングおよびCRUD (AOS)
- Storageページ
- コンテナの管理、モニタリングおよびCRUD
- Hardware ページ
- サーバー、ディスクおよびネットワークの管理、モニタリングおよびヘルスチェック。クラスタの拡張とノードおよびディスクの削除
- Data Protection ページ
- DR、Cloud ConnectおよびMetro Availabilityの構成。PDオブジェクト、スナップショット、レプリケーションおよびリストアの管理
- Analysis ページ
- クラスタおよび管理下のオブジェクトに対するイベントの相関関係を含む詳細なパフォーマンス分析
- Alerts ページ
- ローカルクラスタおよび環境に関するアラート
ホームページでは、アラート、サービスステータス、キャパシティ、パフォーマンス、タスクなどに関する詳細な情報を提供します。詳細な情報を取得する際には、対象となる項目をクリックします。
この図は、ローカルクラスタの詳細を表示している状態のPrism Elementダッシュボードの例です。
キーボードのショートカット
アクセスの良さと使いやすさがPrismの重要な構成概念です。エンドユーザーの操作をよりシンプル化し、キーボードから全てを操作できるようにショートカットが用意されています。
以下にキーショートカットの一部を示します:
ビューの変更(ページコンテキストの切り替え):
- O - オーバービュー (Overview)
- D - ダイアグラムビュー (Diagram View)
- T - テーブルビュー (Table View)
アクティビティとイベント:
- A - アラート
- P - タスク
ドロップダウンおよびメニュー(矢印キーで選択)
- M - メニューのドロップダウン
- S - 設定(歯車アイコン)
- F - 検索バー
- U - ユーザードロップダウン
- H - ヘルプ
機能と使用方法
次のセクションでは、典型的なPrismの使用方法と、一般的なトラブルシューティング方法について説明します。
Nutanixソフトウェアのアップグレード
Nutanixソフトウェアのアップグレードは非常に簡単で、システムを停止させる必要もありません。
最初に、Prismにログインし画面の右上にある歯車アイコン(設定)をクリックするか、「S」を押し「ソフトウェアのアップグレード (Upgrade Software)」を選択します:
「ソフトウェアアップグレード (Upgrade Software)」ダイアログが表示され、現在のソフトウェアバージョンと、使用可能なアップグレードバージョンが示されます。また、マニュアルでAOSバイナリファイルをアップロードすることも可能です。
これにより、クラウドからアップグレードバージョンをダウンロード、またはマニュアルでアップロードすることができます:
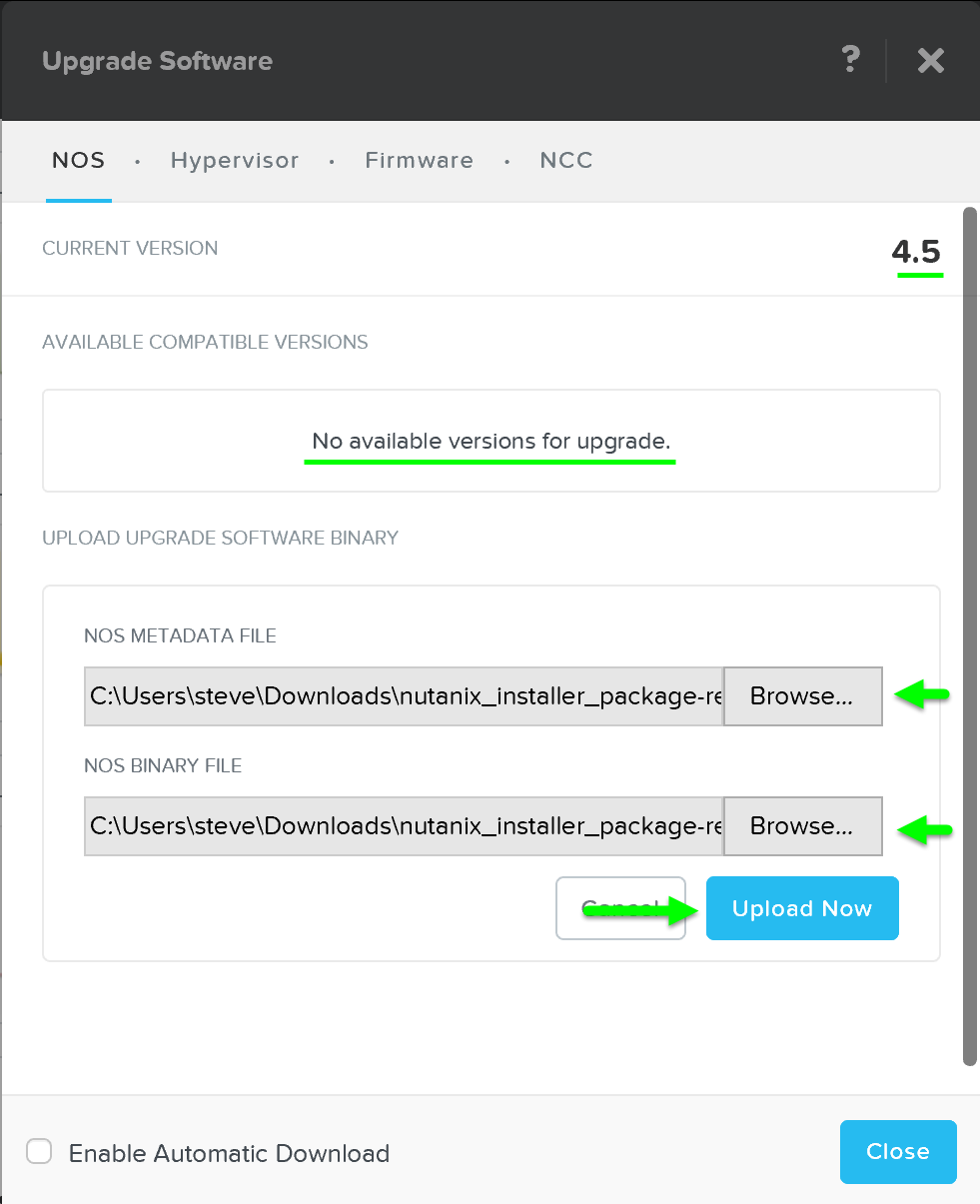
CVMからのソフトウェアのアップロード
場合によっては、ソフトウェアをダウンロードしたうえで、CVM自身からアップロードすることができます。 例えば、ビルドをCVMのローカルにダウンロードするために使用できます。
最初にCVMにSSH接続し、Prismリーダーを見つけます:
curl localhost:2019/prism/leader && echo
PrismリーダーにSSH接続して、ソフトウェアバンドルとメタデータのJSONファイルをダウンロードします。
以下のコマンドを実行して、ソフトウェアをPrismに「アップロード」します:
ncli software upload file-path=<PATH_TO_SOFTWARE> meta-file-path=<PATH_TO_METADATA_JSON> software-type=<SOFTWARE_TYPE>
以下は、Prism Central の例を示します:
ncli software upload file-path=/home/nutanix/tmp/leader-prism_central.tar meta-file-path=/home/nutanix/tmp/leader-prism_central-metadata.json software-type=prism_central_deploy
次に、Nutanix CVMにアップグレードソフトウェアをアップロードします:
ソフトウェアのロードが完了したら、「アップグレード (Upgrade)」をクリックし、アップグレード処理を開始します:
確認のためのボックスが表示されます:
アップグレードの事前チェックが行われ、続いてアップグレードが順次進行します。
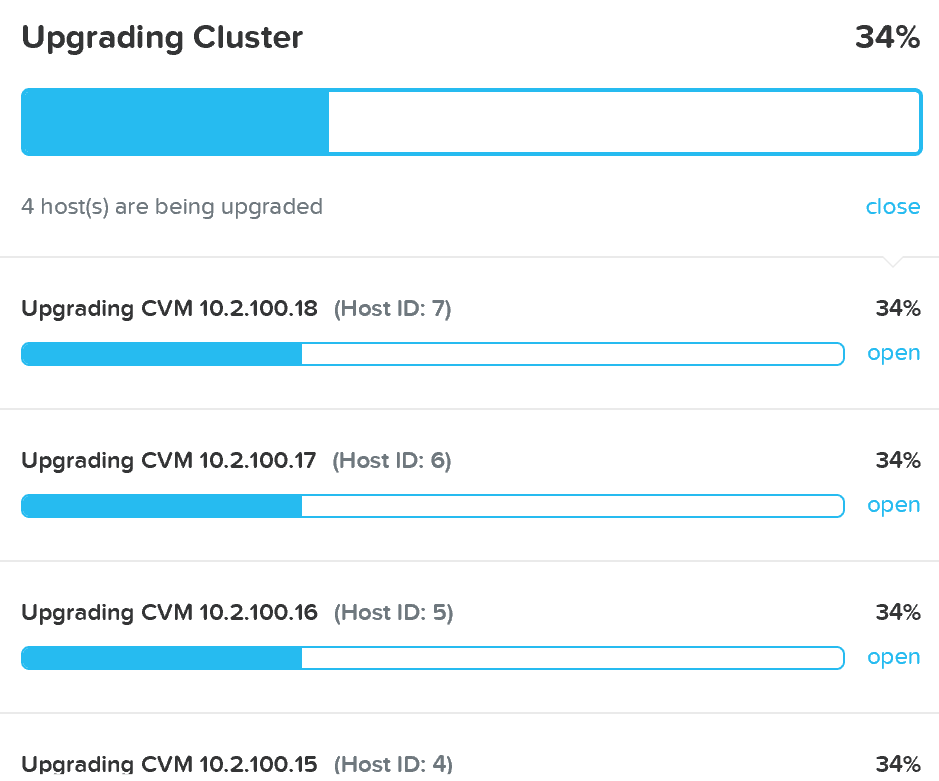
アップグレードが完了すると、結果が表示され、全ての新しい機能が利用できるようになります:
注意
現状のPrismリーダーでは、アップグレードの最中、Prismのセッションが一瞬切断されます。 但し、これによってVMやサービスが影響を受けることはありません。
ハイパーバイザーのアップグレード
Nutanixソフトウェアのアップグレードと同様に、ハイパーバイザーのアップグレードもPrism経由で順次自動的に進行します。
前述と同様に、「ソフトウェアのアップグレード (Upgrade Software)」ダイアログボックスを表示して、「ハイパーバイザー (Hypervisor)」を選択します。
これで、クラウドからハイパーバイザーのアップグレードバージョンをダウンロード、またはマニュアルでアップロードすることができます:
ハイパーバイザーにアップグレードソフトウェアがロードされます。ソフトウェアがロードされたら、「アップグレード (Upgrade)」をクリックしてアップグレード処理を開始します:
確認のためのボックスが表示されます:
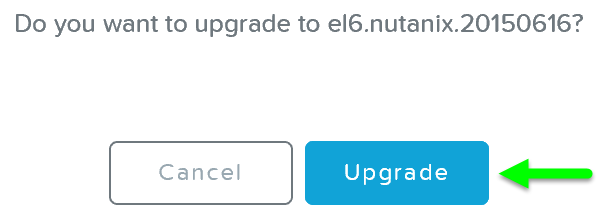
システムがホストのプリアップグレードチェック を行い、ハイパーバイザーをアップロードし、クラスタをアップグレードします:
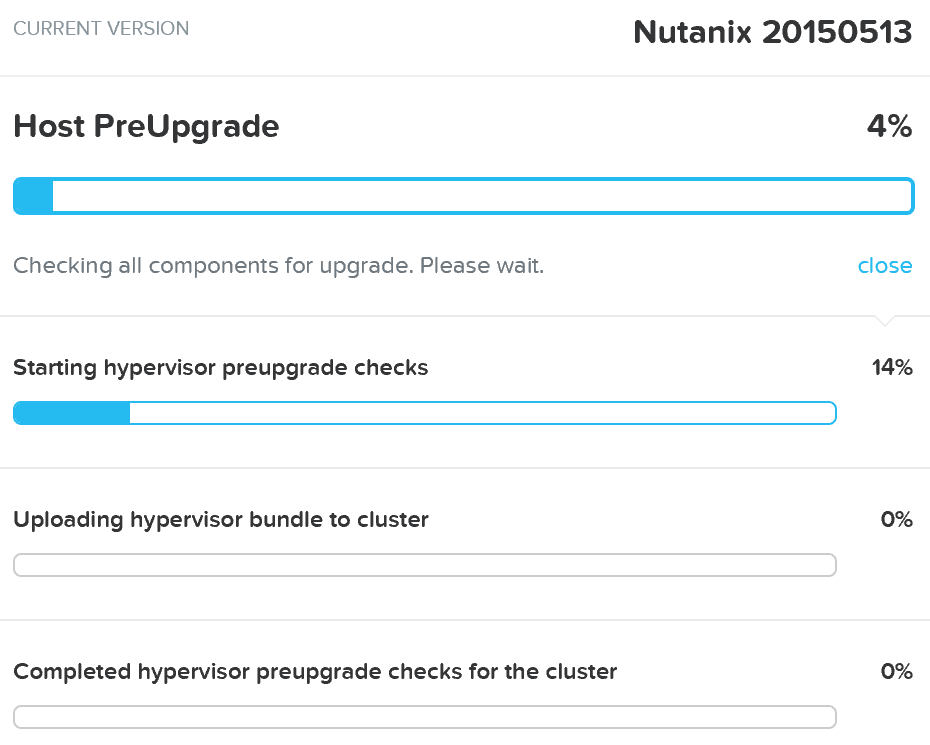
プリアップグレードチェックが完了すると、ハイパーバイザーアップグレードが順次進行します:
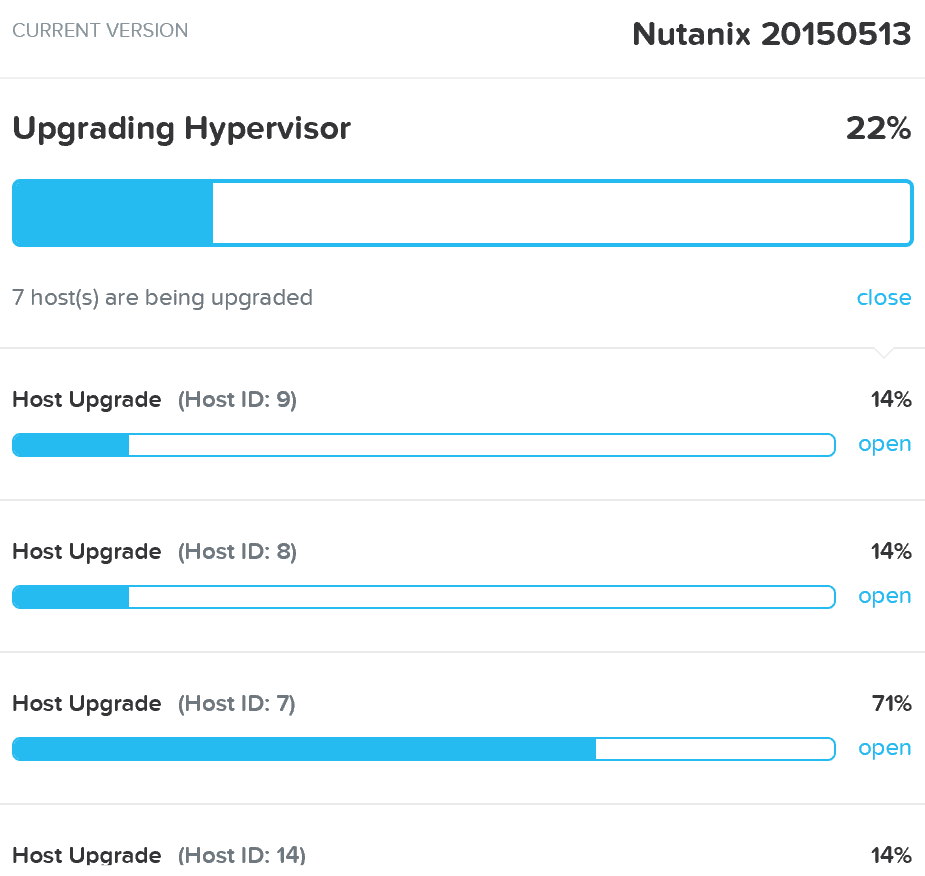
Nutanixソフトウェアのアップグレード同様、各ホストのアップグレードも稼動中のVMに影響を与えることなく、順次進行します。 VMは、現在のホストとは別にライブマイグレーションされ、ホストがアップグレードされる通りブートが行われます。 この処理は、クラスタ内の全てのホストのアップグレードが完了するまで、それぞれのホストに対して繰り返し実行されます。
プロからのヒント
クラスタ全体のアップグレードステータスは、いずれかのNutanix CVMで、'host_upgrade --status' を実行することで確認できます。各ホストの詳細なステータスは、各CVMの ~/data/logs/host_upgrade.out にログされています。
アップグレードが完了すると結果が表示され、全ての新しい機能が利用できるようになります:
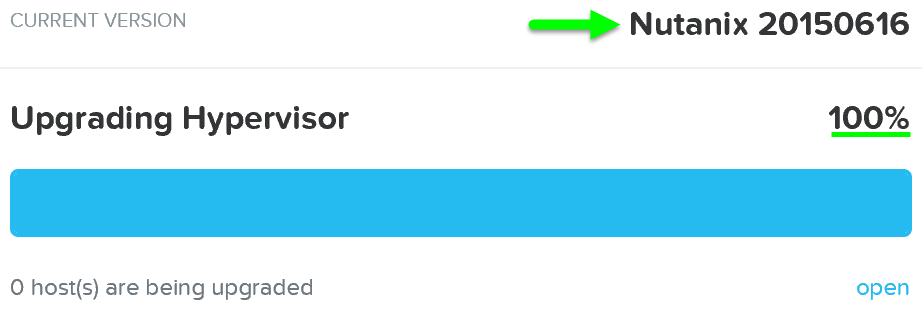
クラスタの拡張(ノードの追加)
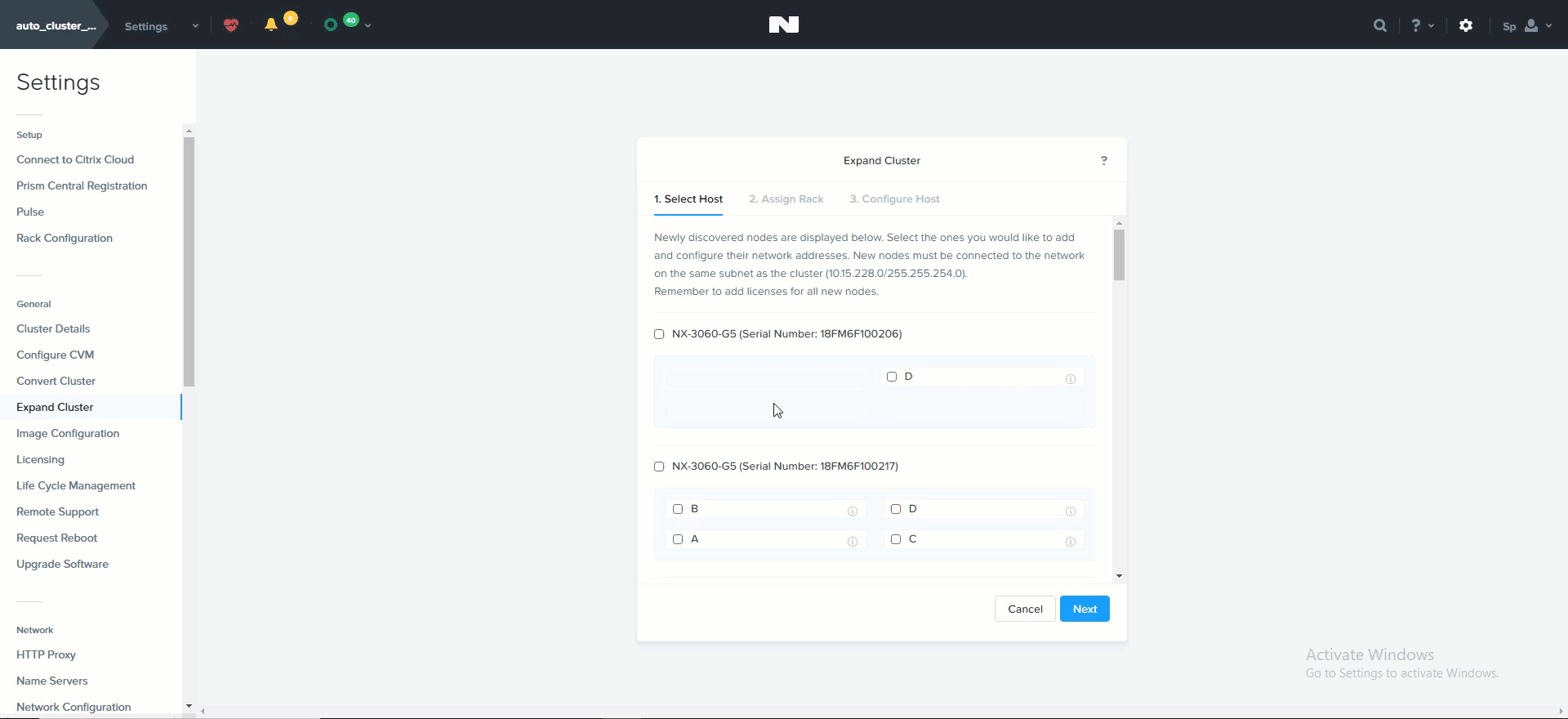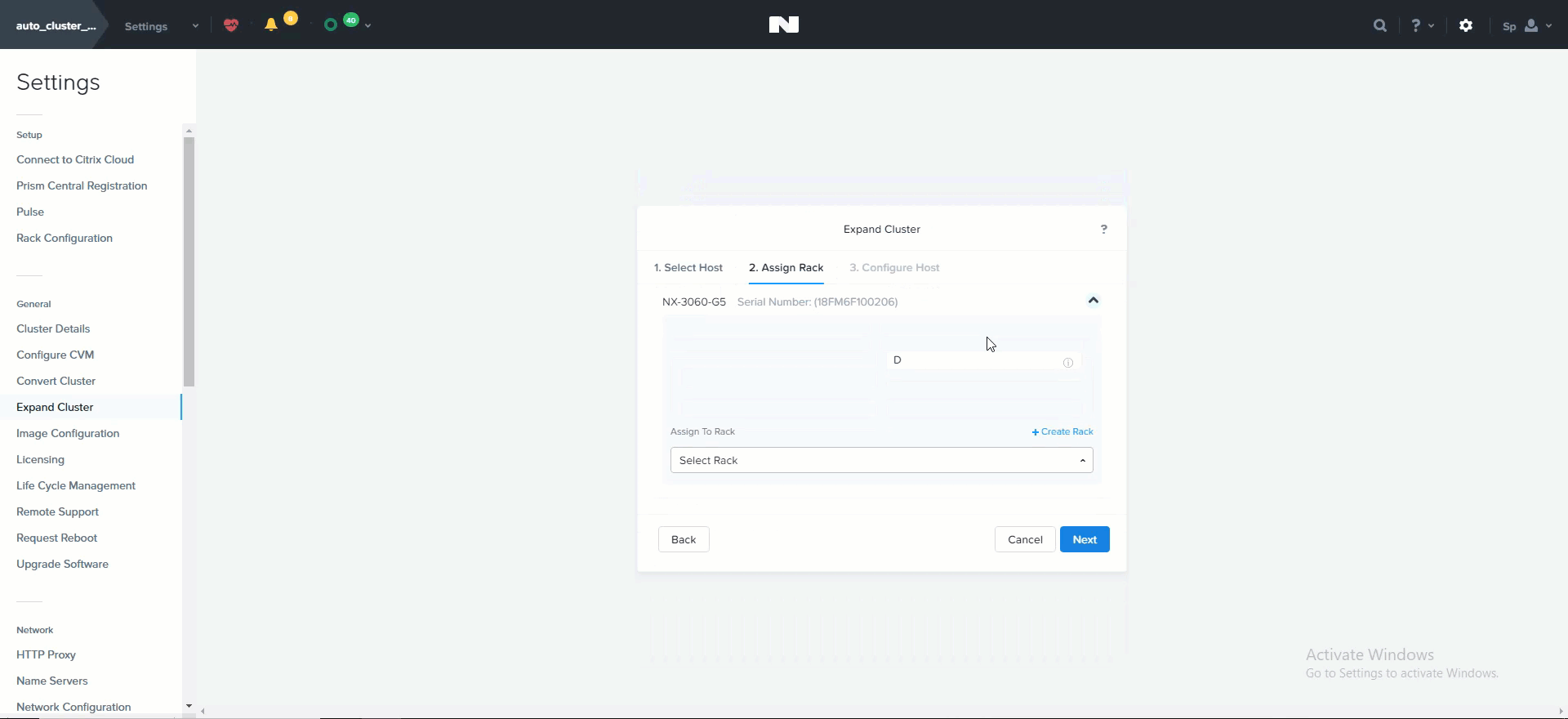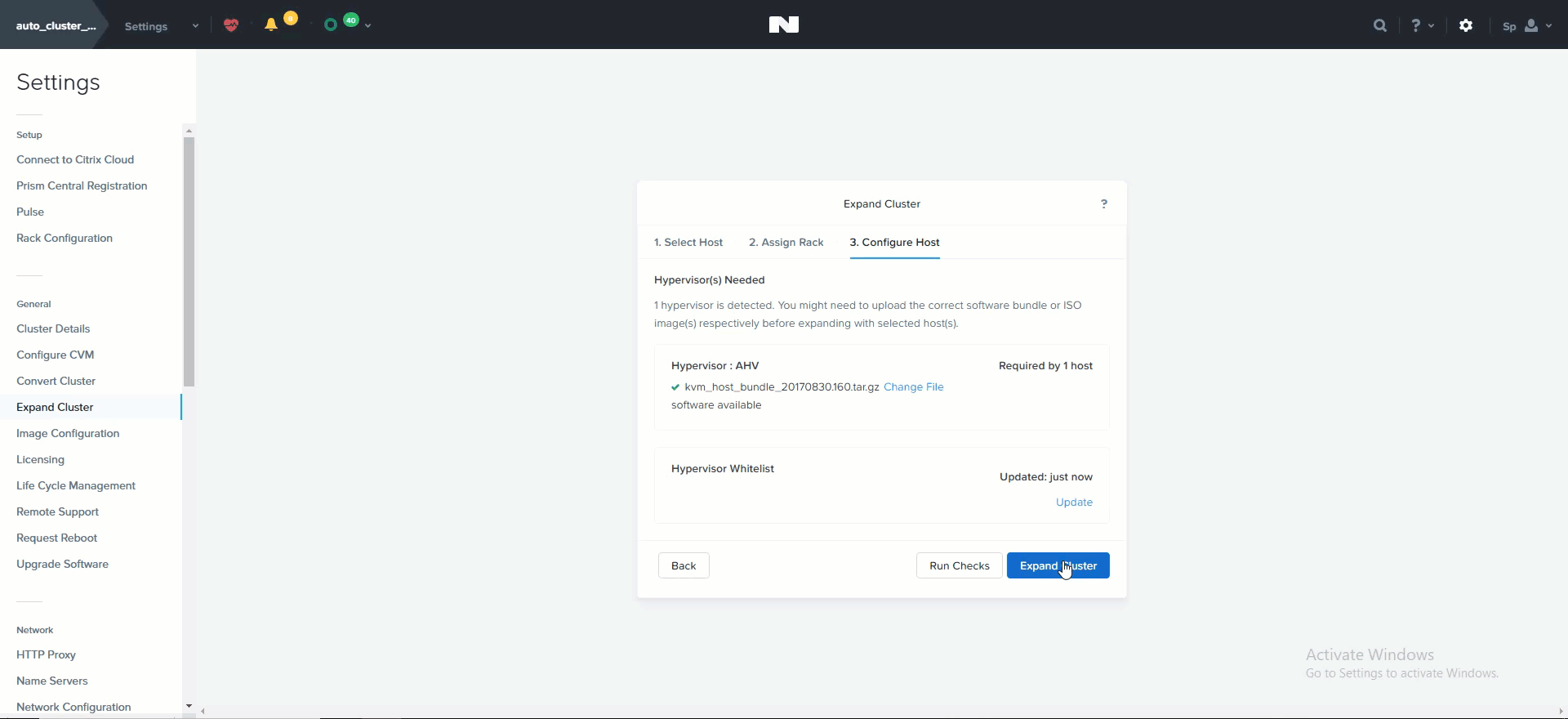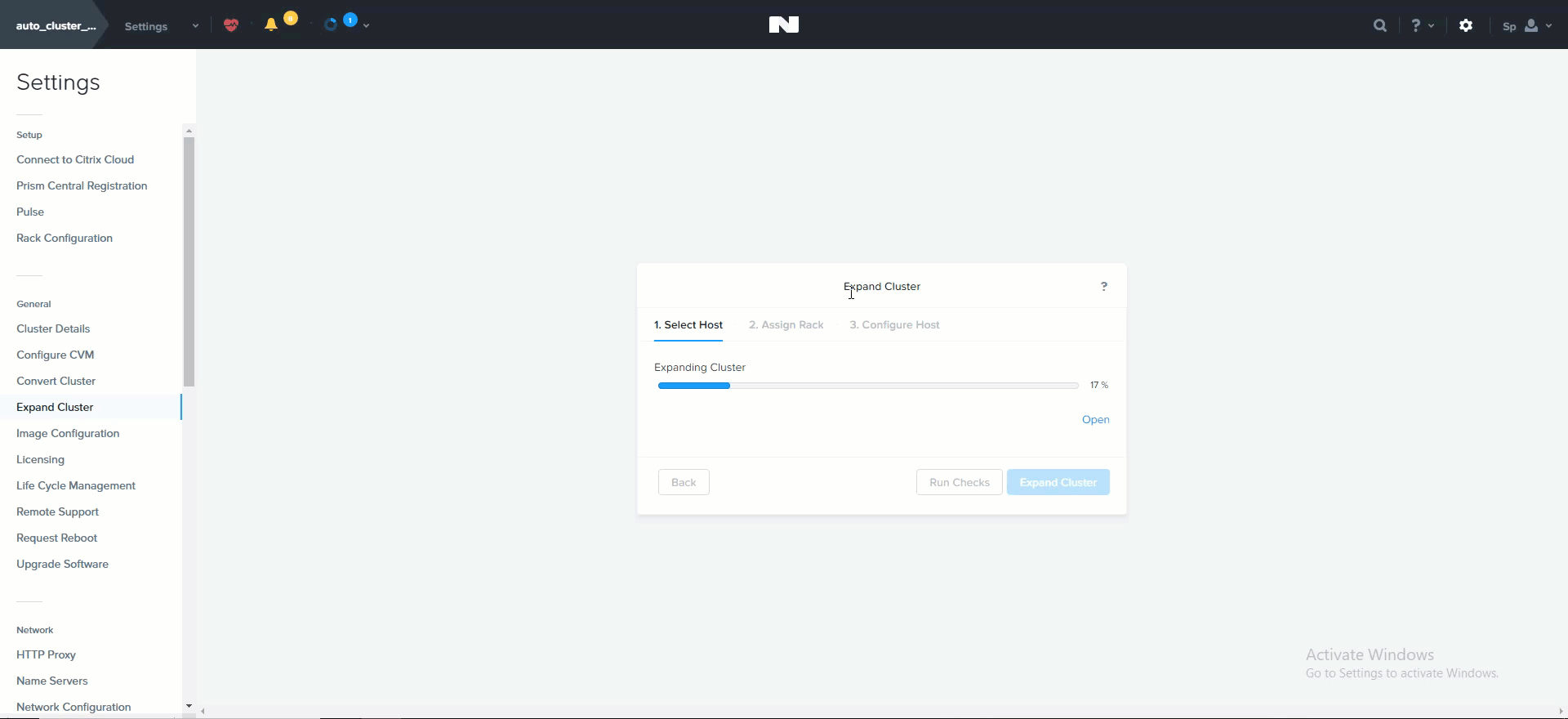
Nutanixクラスタを動的に拡張できることは重要な機能です。Nutanixクラスタを拡張する際には、ノードをラックに格納、スタック後、ケーブルを接続して電源を供給します。ノードに電源が投入された後は、現在のクラスタからmDNSを使用してそれらを検知できるようになります。
図は、既存7ノードのクラスタにおいて新規の1ノードが検知された状態を示しています。
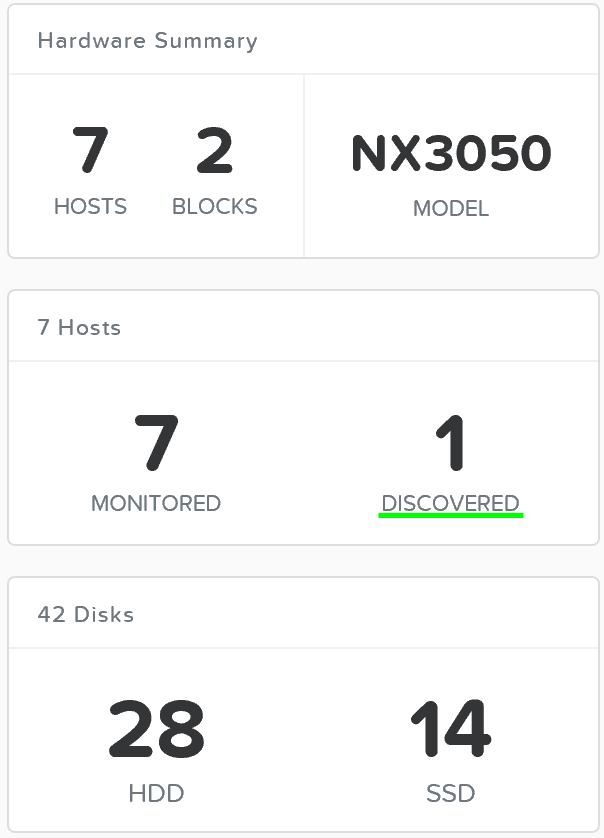
複数のノードについても検知が可能であり、クラスタに対して同時に追加することもできます。
ノードが検知された後、「ハードウェア (Hardware)」ページの右上にある「クラスタの拡張 (Expand Cluster)」をクリックすることで、拡張が開始されます:
クラスタの拡張処理は、歯車アイコンをクリックすることで、どのページからでも実行できます:
これをクリックすると、クラスタ拡張メニューが起動され、追加する(複数の)ノードを選択し、コンポーネントに対するIPアドレスを指定することができます:
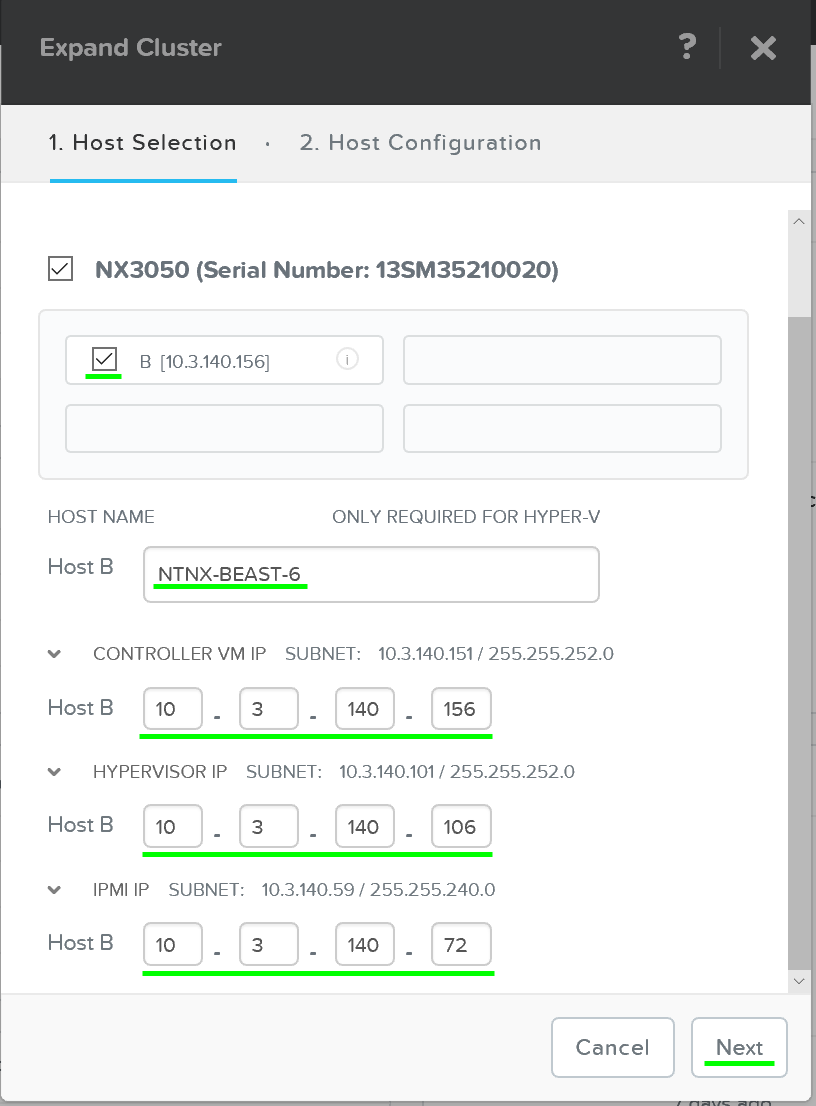
ホストを選択すると、追加するノードで使用するハイパーバイザーイメージをアップロードするよう促されます。ハイパーバイザーがAHVの場合、またはイメージが既にFoundation インストーラーストア上に存在する場合、アップロードは必要ありません。
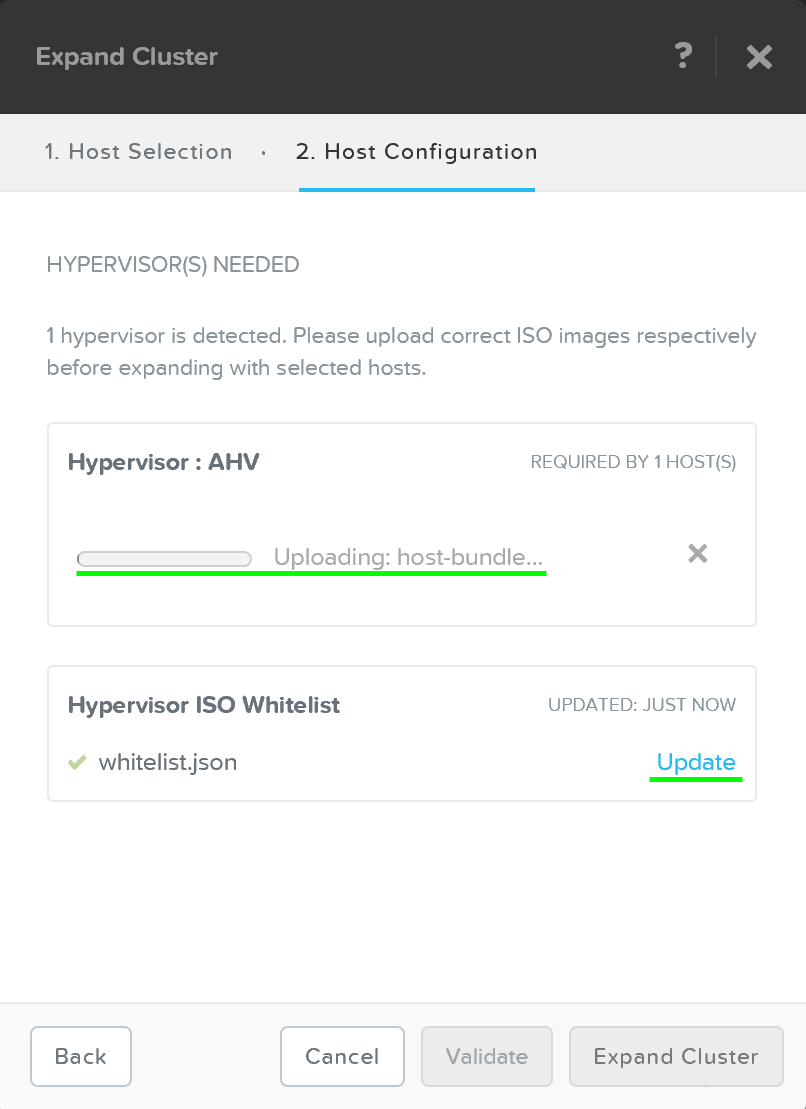
アップロードが完了し、「クラスタの拡張 (Expand Cluster)」をクリックするとイメージングと拡張処理が開始されます:
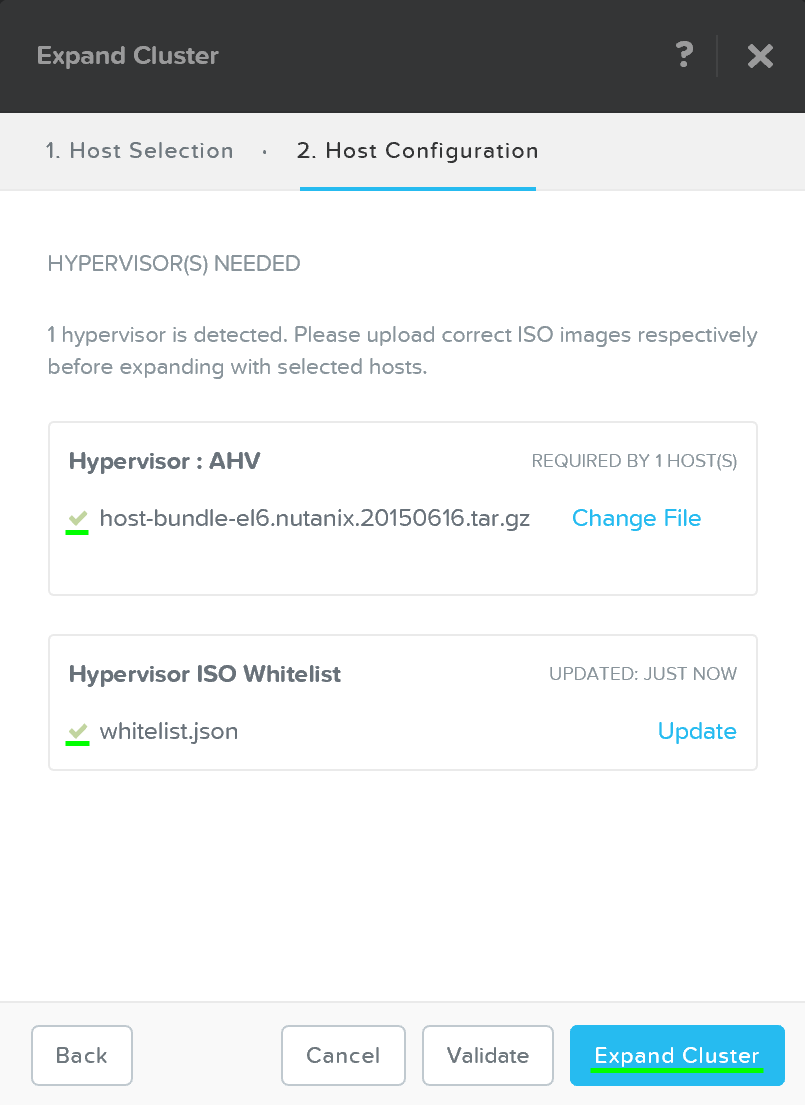
ジョブがサブミットされ、対応するタスクが表示されます:

タスクを開くと、詳細な進行状況を確認できます:
イメージングとノード追加処理が完了すると、更新されたクラスタサイズ通りソースを確認できます:
I/Oメトリクス
パフォーマンスに関するトラブルシューティングを実施する上では、まずボトルネックの特定が重要となります。この対応を支援するためにNutanixでは、新たな「I/Oメトリクス」セクションをVMページに追加しました。
レイテンシーは、様々な変数(キューの深さ、I/Oサイズ、システムの状態、ネットワーク速度など)の積として表現されます。このページでは、I/Oサイズ、レイテンシー、ソースおよびパターンに関するインサイトを提供します。
この新しいセクションを利用するためには、「VM」ページに入り、一覧から必要なVMを選択します。これで、ハイレベルな使用状況のメトリクスが表示されます:

一覧の下にあるセクションに、I/Oメトリクス (I/O Metrics) タブが表示されます:

「I/Oメトリクス」タブを選択すると、詳細ビューが表示されます。ここでは、同ページの詳細と使用方法について説明します。
最初のビューは「平均I/Oレイテンシー(Avg I/O Latency)」で、過去3時間の平均R/Wレイテンシーを表しています。デフォルトでは、対応する詳細メトリクスと共に、その時点での最新の値が表示されます。
また、グラフにポインタを合わせると、過去のレイテンシー値が表示され、グラフ上の時間をクリックすると、以下のようにメトリクスの詳細が表示されます。

これはスパイク、つまり突然数値が跳ね上がっている状態の確認に有効となります。このような状況が見られた場合には、そのスパイク表示をクリックして以下のような詳細情報を評価し、さらに調査を進めることができます。
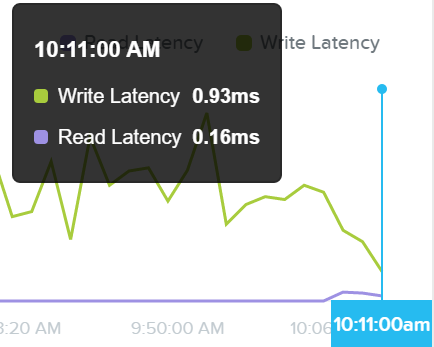
レイテンシーに全て問題がなければ、それ以上の調査は必要ありません。
次のセクションは、READおよびWRITE I/Oサイズのヒストグラムを表示したものです:
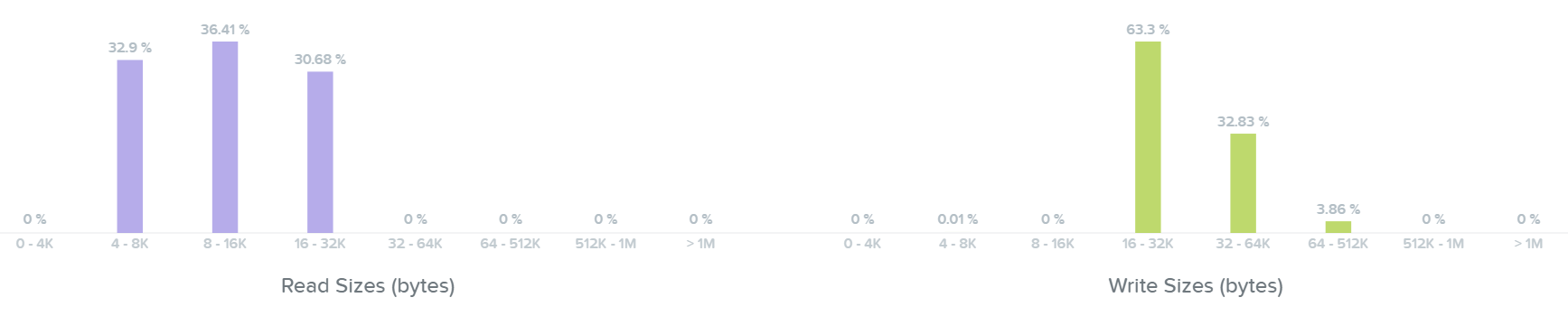
ここでは、READ I/Oが、4Kから32Kのサイズ範囲にあることが分かります:
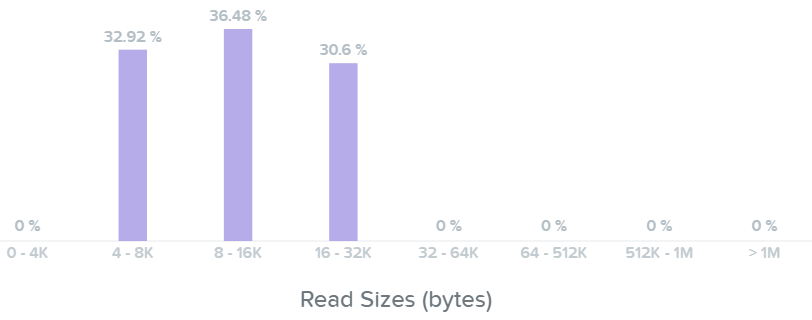
ここでは、WRITE I/Oについては、ほぼ16Kから64Kに収まっているものの、一部は512Kまでのサイズになっていることが分かります:
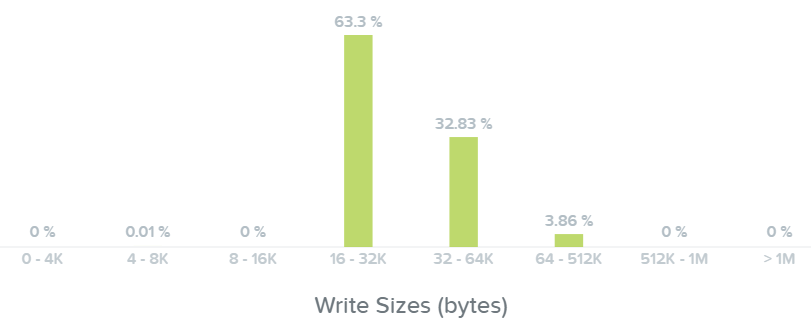
プロからのヒント
数値にスパイクが見られる場合には、まずI/Oサイズを確認します。大きなI/O(64Kから1MB)は、一般的に小さなI/O(4Kから32K)よりも大きなレイテンシーを示します。
次のセクションは、READおよび WRITE I/OのI/Oレイテンシーヒストグラムを示したものです:

READレイテンシーヒストグラムを見ると、ほとんどのREAD I/Oがミリ秒未満 (<1ms) に収まっていますが、一部は2~5msに達していることが分かります。
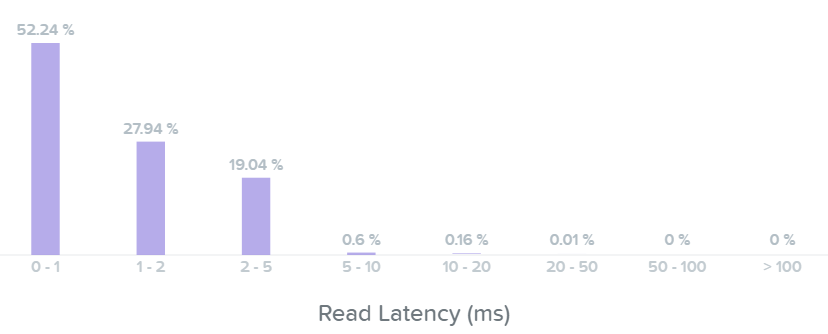
「Readのソース (Read Source)」を見ると、ほとんどのI/OがSSD層で発生していることが分かります:

データが読み込まれると、ユニファイド キャッシュ(Unified Cache)内にリアルタイムで配置されます(詳しくは、「I/Oパスとキャッシュ」のセクションを参照)。 ここでは、データがキャッシュに配置され、DRAMから提供されている様子が理解できます:

基本的に、全てのREAD I/Oがミリ秒 (1ms) 未満のレイテンシーで行われていることが分かります:
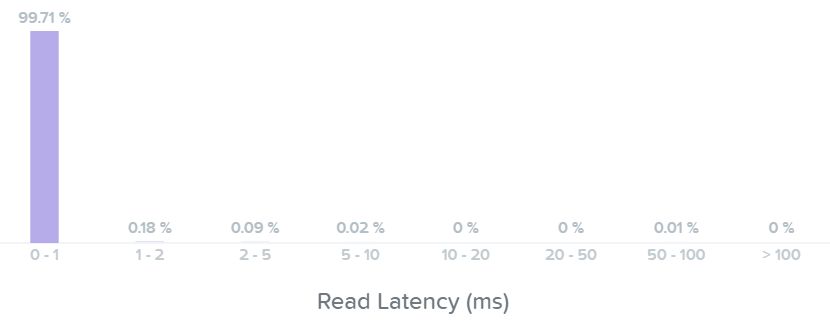
ここでは、ほとんどのWRITE I/Oが、1~2ms未満のレイテンシーで行われていることが分かります:
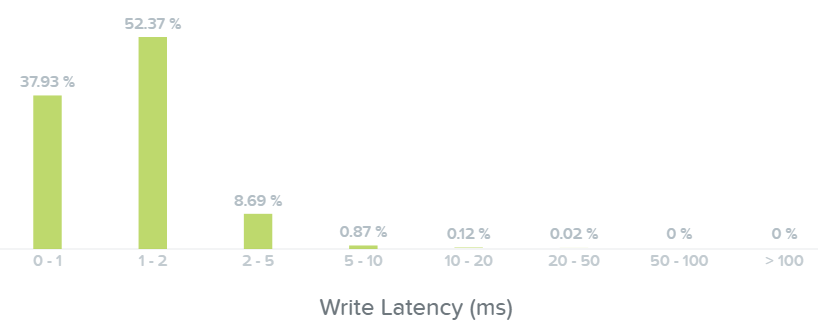
プロからのヒント
READレイテンシーにスパイクが見られ、かつI/Oサイズが大きくない場合は、READ I/Oリクエストに対する結果がどこから返されているかを確認します。最初にHDDから読み込む場合は、DRAMキャッシュよりも大きなレイテンシーを示しますが、一度キャッシュに入れば、以降のREADはDRAMに対してヒットするようになり、レイテンシーが改善されます。
以下の最後のセクションでは、I/Oのパターンとランダムとシーケンシャルの比較内容を示しています:
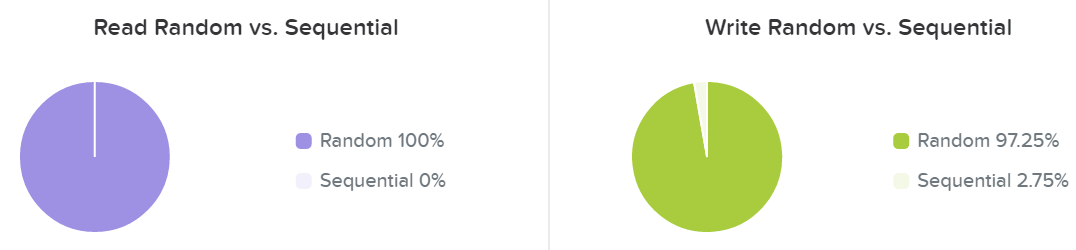
通常、I/Oのパターンはアプリケーションやワークロードによって、様々に異なるものとなっています(例えば、VDIはほとんどがランダムでHadoopは基本的にシーケンシャルなど)。さらに、2つをミックスしたワークロードも存在します。例えばデータベースは、インサートや一部のクエリではランダムですが、ETL処理中はシーケンシャルとなります。
マイクロサービス インフラストラクチャー
マイクロサービス インフラストラクチャー(MSP)は、Flow Virtual Networking、Objects、セキュリティ ダッシュボードなど、Prism Centralベースのコンポーネントに関連付けられたマイクロサービスを配信するための共通フレームワークを提供します。 MSPは、IDとアクセスを管理する機能(IAM)や、内部サービスの負荷分散といったサービスも提供します。
MSPが登場する前は、Prism Centralはモノリシックなアプリケーションでした。 MSPを有効にすると、特定のサービスがKubernetes(K8s)クラスタに移行されてPodとして起動されます。 時間の経過とともに、ほとんどのPrism Centralサービスは移行され、共通プラットフォームを活用するマイクロサービスに変換されます。 これによりLCMでサービスを個別にアップグレードできるようになり、Prism Centralインスタンスの全体をアップグレードすることなく特定のサービスをアップグレードできるため、アップグレードがより高速化され、パッチ更新も迅速になります。
PC.2022.9以降は、マイクロサービス インフラストラクチャーはデフォルトで有効になっています。 Prism Centralを最新バージョンにアップグレードすると、MSPが自動的に有効化されます。 前提要件と考慮事項については、Prism Central Infrastructure Guide を参照してください。
ネットワークの設定
MSPが有効になると、Prism Central上にKubernetesクラスタが作成されます。 このKubernetesクラスタは、スタンドアロンPrism Centralを備えた1つのノードか、スケールアウトPrism Centralを備えた3つのノードで構成されます。
MSPは次のサブネットを使用します。
| サブネット | 用途 |
| 10.100.0.0/16 | KubernetesのPodネットワークに予約 |
| 10.200.32.0/24 | Kubernetesサービス(Flow Virtual Networking、IAMなど) |
| 10.200.0.0/16 | Kubernetesのサービス ネットワークに予約 |
| 10.100.0.0/24 | Kubernetes Pod - Prism Central VM 1 |
| 10.100.1.0/24 | Kubernetes Pod - Prism Central VM 2 |
| 10.100.2.0/24 | Kubernetes Pod - Prism Central VM 3 |
これらのサブネットがすでにDNSまたはActive Directoryに使用されていて、別のIPアドレス範囲が必要な場合は、Nutanix サポートにお問い合わせください。
ファイアウォールでは、Prism Centralと以下の間の双方向トラフィックが許可される必要があります:
- すべてのPrism ElementのCVM IPアドレス
- Prism ElementのVirtual IPアドレス
- Prism ElementのData Services IPアドレス
TCPポート:
- 3205 - iSCSIのデータ プレーン接続
- 3260 - iSCSIのコントロール プレーン接続
- 9440 - Prism UI/API
さらにPrism Centralは、すべてのPrism Element CVM IPおよび Prism Element Virtual IPに対してのping応答をうけられる必要があります。
デプロイ中に、Prism Centralはいくつかのクラウド サービスに443ポート経由でアクセスする必要があります。 最新のリストと図については、Support & Insights PortalのPorts & Protocols ページを参照してください。 インターネットにアクセスできないネットワークでのダーク サイトにて導入する方法もあり、それについても Prism Central Infrastructure Guide で説明されています。
Prism Centralを展開する場合、またはMSPを有効にする場合には、内部ネットワーク構成に2つの選択肢があります。
- プライベート ネットワーク(デフォルト): 内部プライベート ネットワークが、Kubernetesノード通信のためにVXLANで展開されます。 デフォルトの設定は192.168.5.0/24です。 この場合、物理ネットワークでの追加IPアドレスは不要です。
- VLANネットワーク: Nutanixクラスタ上に設定された、管理対象または管理対象外のVLANネットワーク。 シングルノードPCをセットアップする場合には物理ネットワークから5つのIPアドレスが必要で、3ノードのスケールアウトPCをセットアップする場合には10個のIPアドレスが必要です。 この場合にはKubernetesノード通信用に、すべてのPCVMに2番目のNICが追加されます。
MSPのアーキテクチャー
以下の図は、デフォルトのプライベートVXLANネットワークを想定したものです。
シングルノードPC展開でのKubernetesノードのアーキテクチャ例の図は次のようになります。 この例では、Kubernetesクラスタ内で実行されているすべてのサービスが示されているわけではないことに注意してください。
この例では、10.10.250.50がPCVMに割り当てられたIPアドレスで、10.100.0.0/24 がKubernetes Podのネットワークとして使用されます。

スケールアウトPCの場合、2つの追加のKubernetesノードがプロビジョニングされ、それぞれのPodでは10.100.1.0/24と10.100.2.0/24のネットワークが使用されます。
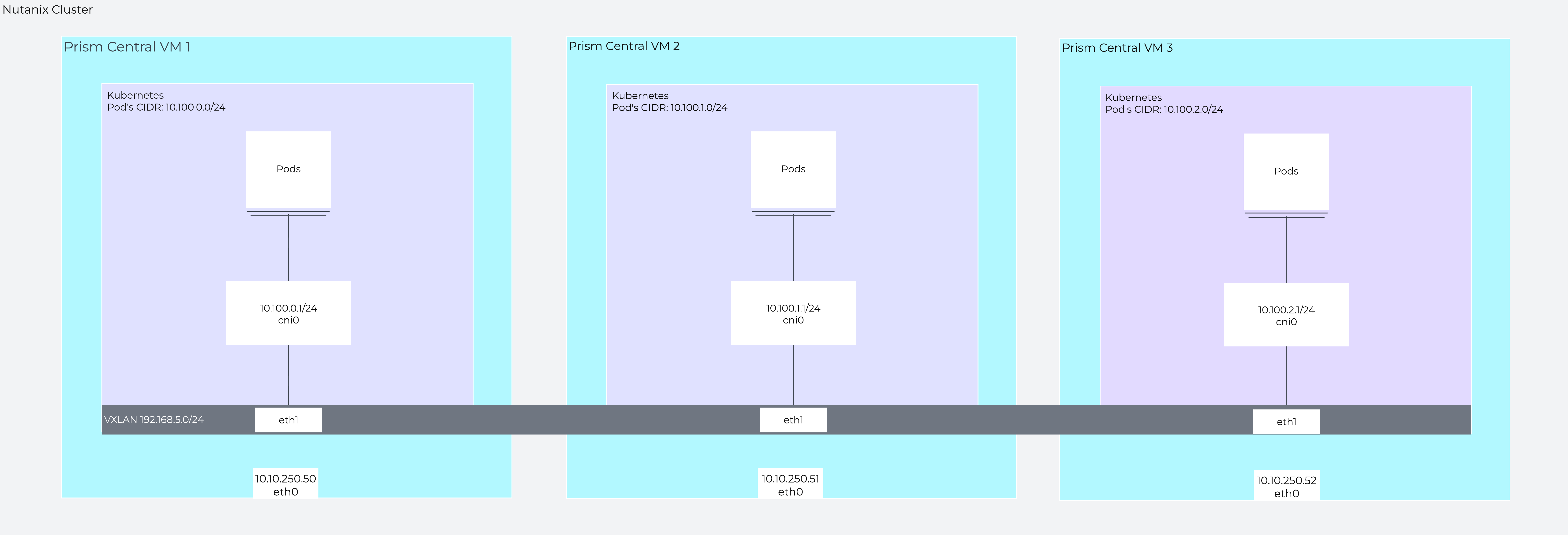
VXLANを使用したスケールアウトPCのセットアップでは、ノード間でのPod同士のトラフィックで直接ルーティングを使用し、Prism Central VMのIPアドレスを使用してカプセル化されます。
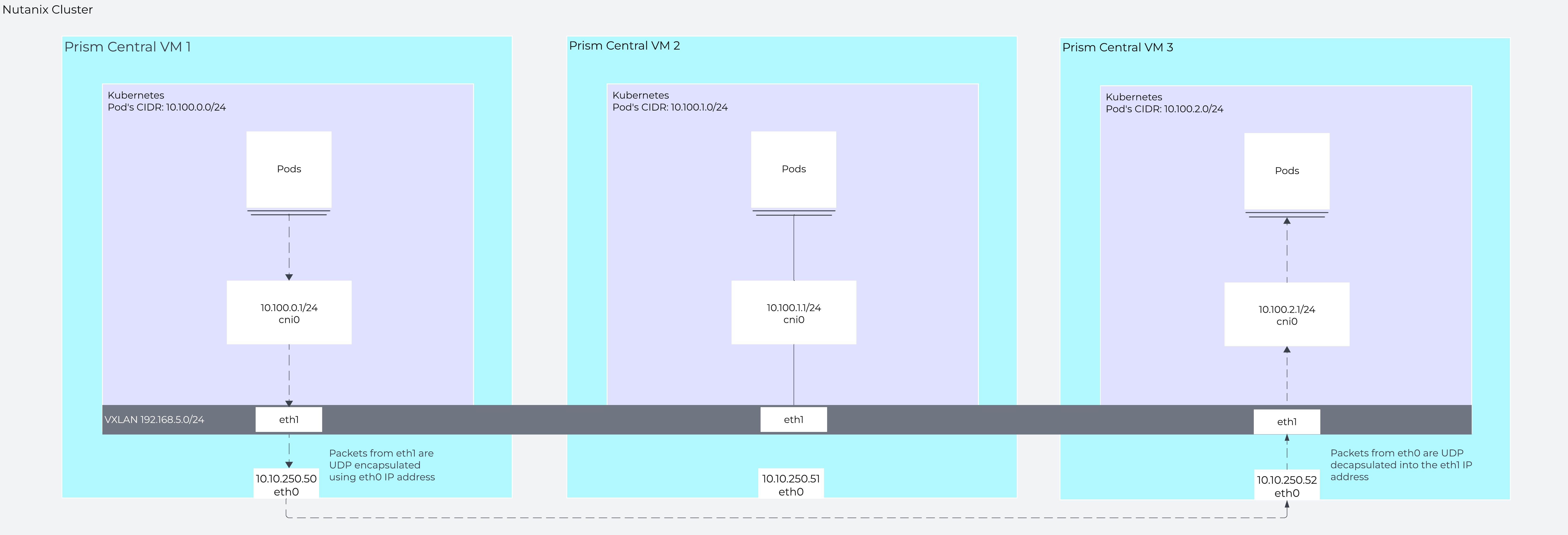
Prism Central Backup and Restore
Prism Central Backup and Restoreを使用すると、Prism Centralの展開とさまざまなサービス設定およびポリシーを、同じPrism Centralによって管理されるPrism Elementクラスタに継続的にバックアップできます。 Prism Centralインスタンスをホストしているクラスタで災害が発生した場合、別のクラスタでPrism Centralの展開を回復できます。
Prism Central Backup and Restoreのアーキテクチャー
Prism ElementとPrism Centralには、インフラストラクチャーのさまざまなコンポーネントやサービスからの構成、定期的なパフォーマンス、メトリック データを保存するInsights Data Fabric(IDF)と呼ばれるデータベースがあります。
Prism Central Backup and Restoreが有効化されている場合、Prism CentralのIDFインスタンスのデータは、バックアップ用に指定されたPrism ElementのIDFインスタンスに定期的に複製されます。 Prism Centralバックアップのターゲットとして、AHVまたはESXiで稼働している、最大3つのNutanixクラスタを選択できます。 レプリケーションは30分ごとに行われます。 レプリケーションには、9440ポートが使用されます。
リストア操作が発生すると、Prism CentralはバックアップPrism Elementクラスタの1つの上に再構築され、IDFデータ バックアップからのデータが再シードされます。
このアーキテクチャー図では、Prism Centralが3つのクラスタを管理しており、Prism CentralはCluster 1でホストされています。 これらのクラスタは、物理的に異なる場所に存在する可能性があることに注意してください。 バックアップ用に選択されたクラスタは、AOS 6.0以降であればESXiまたはAHVで稼働でき、Prism Centralによって管理され、少なくとも1つのクラスタがAOS 6.5.3.1以上である必要があります。 さらに、Prism Centralと登録されたクラスタ間の時刻を同期するには、Prism Central上でNTPが構成されている必要があります。
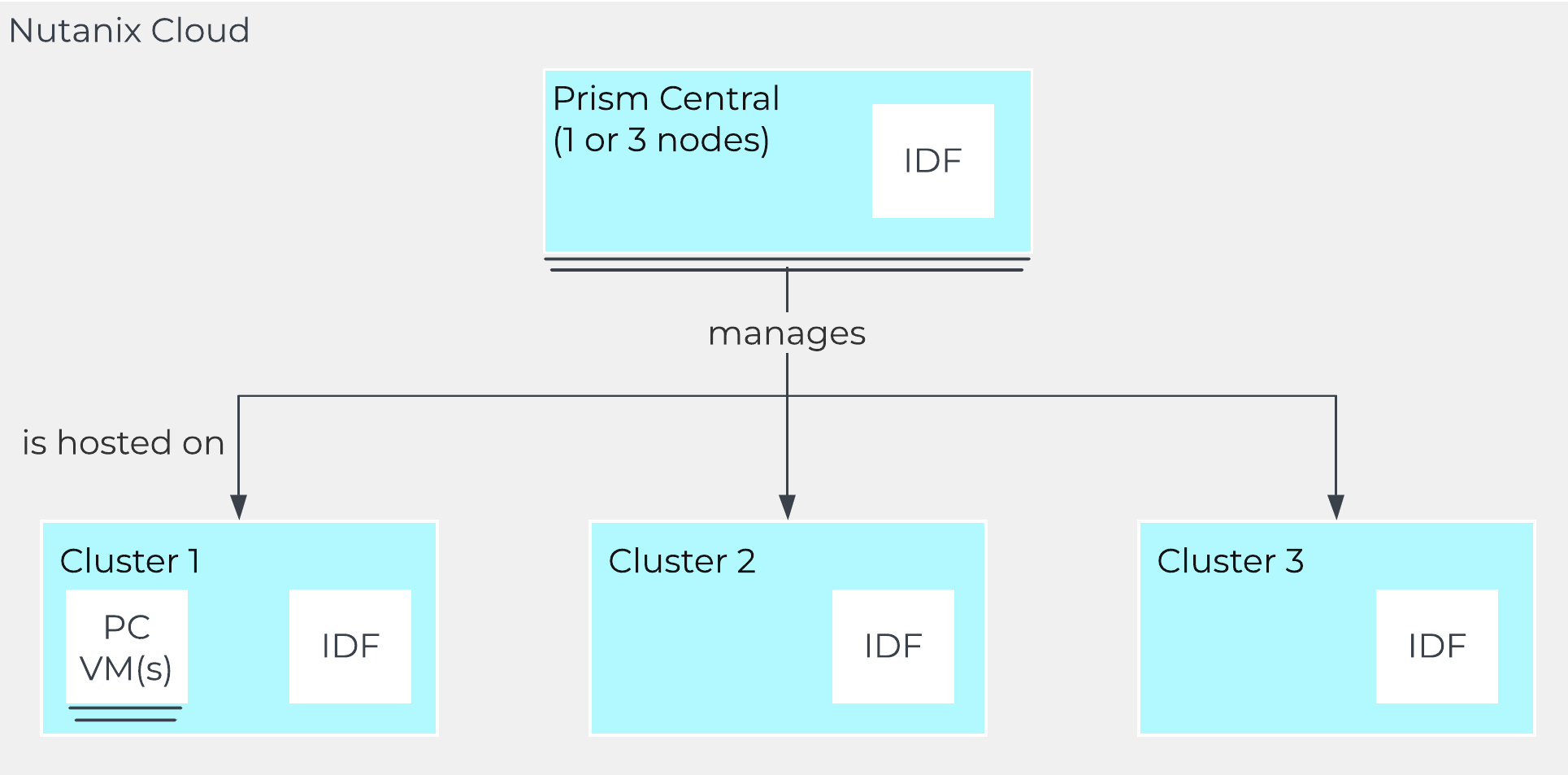
Prism Central Backup and Restoreを有効にすると、Prism CentralからのIDFデータが、TCP 9440ポート経由で、選択したクラスタ上のIDFデータベースへと定期的に同期されます。 この例では、Prism CentralはCluster 1でホストされており、Cluster 2 とCluster 3の両方に複製されています。
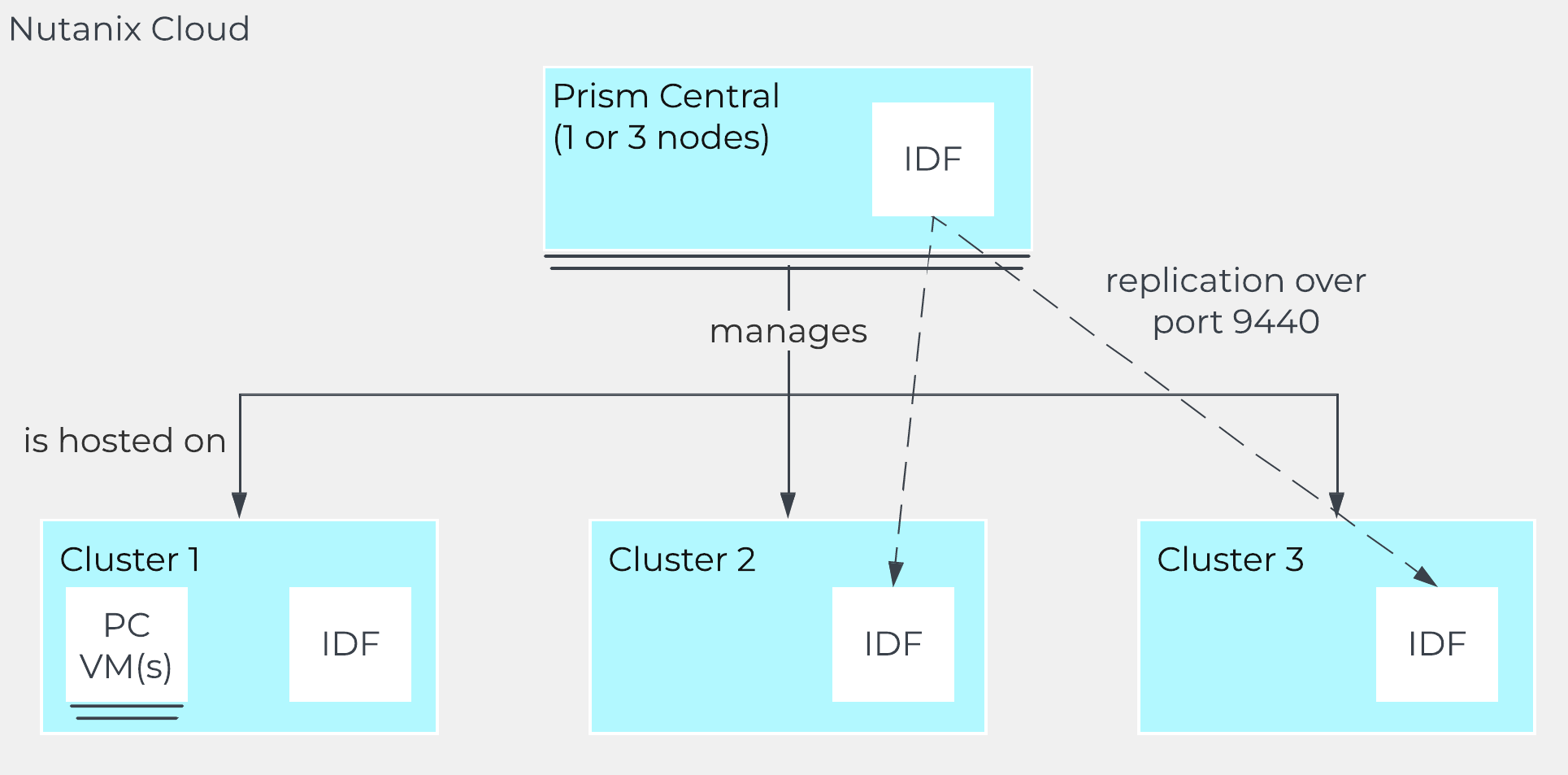
前提要件の完全なリストと、同期およびリストアされるサービスとデータについては、Prism Central Backup and Restoreのドキュメント を参照してください。
Cluster 1が利用できない場合は、Prism Centralも利用できなくなり、Cluster 2またはCluster 3のPrism ElementインターフェイスからPrism Centralを回復できます。
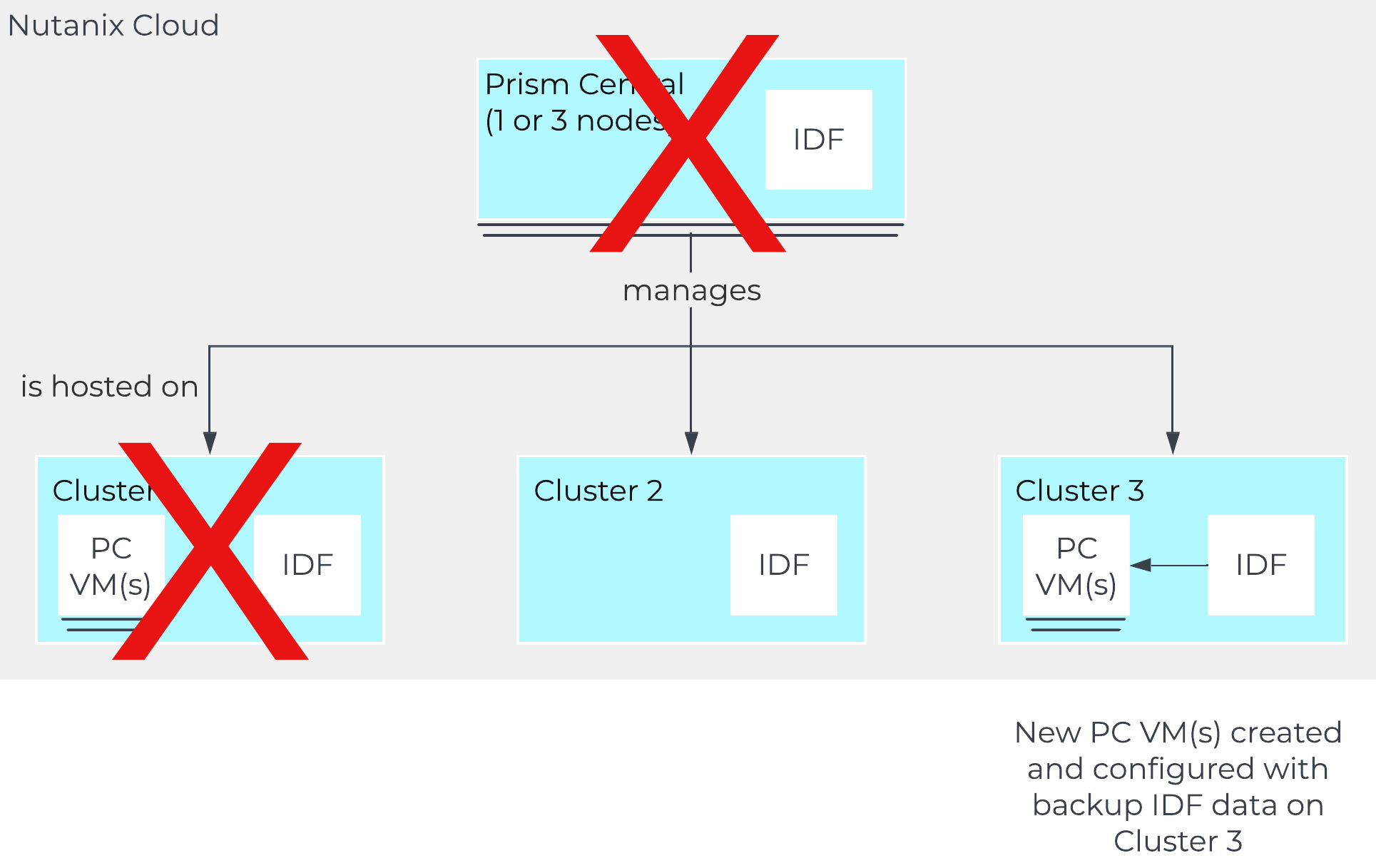
リカバリのプロセスでは、必ず新しいPrism Centralデプロイメントを使用してください。 Cluster 1がオンラインに戻ったら、必ず元のPrism Centralはシャットダウンまたは削除してください。 リカバリ後は、同じバックアップ ターゲットへのレプリケーションが続行されます。
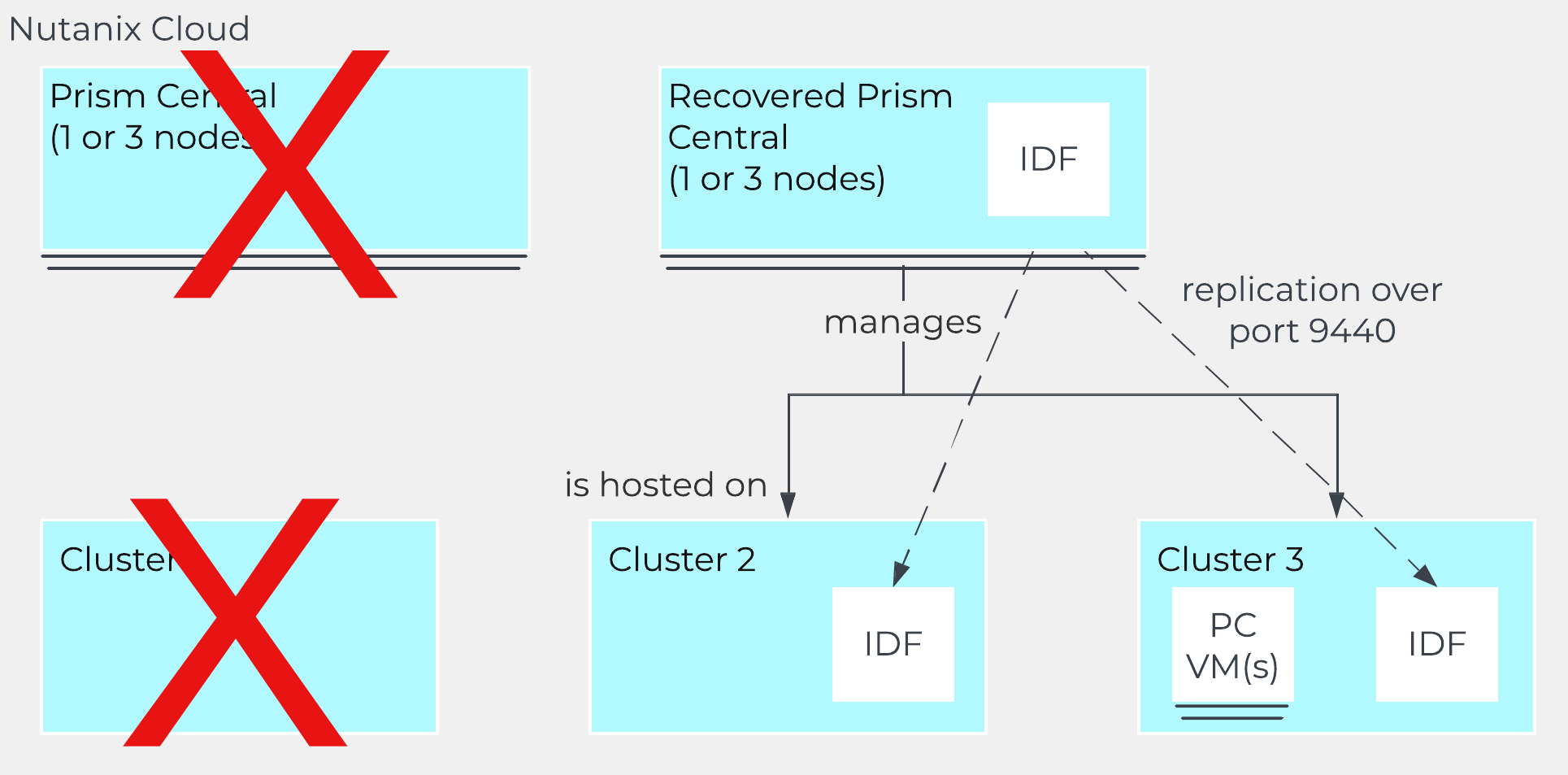
Nutanix Database Service
Nutanix Database Service(NDB)はオンプレミスおよびパブリック クラウドでのデータベース ライフサイクル管理を簡素化し自動化するDatabase-as-a-Serviceプラットフォームであり、Microsoft SQL Server、Oracle Database、PostgreSQL、MySQL、MongoDBのデータベースを対象としています。 NDBを利用することで、組織は、データベースのプロビジョニングをシンプルで迅速かつ安全に行い、アジャイルなアプリケーション開発を支援しつつ、数百から数千に及ぶデータベースを効率的かつ安全に管理し、パフォーマンス、可用性、コストの要件を満たすことができます。
NDBは、AWSのパブリック クラウド内のNutanix Cloud Clusters(NC2)を含む、任意のNutanixクラスタにデプロイできます。 クラスタではAHVまたはESXiが実行できます。 NDBはNutanix AOSのスナップショット、保護ドメイン、およびレプリケーション機能を活用し、データベース管理に利用します。
NDBは仮想マシン(VM)上で動作し、高可用性(HA)構成で展開できます。 また、NDBはNutanixクラスタのHA機能からも恩恵を受けており、Nutanixのアップグレード中やノードの交換時にNDBの仮想マシンをライブ マイグレーションしたり、障害発生後に別のホストで仮想マシンを起動したりすることができます。
Nutanix Cloud Platform上でデータベースを運用する方法や、Nutanix Database Serviceについての詳細は、以下のリソースを参照してください:
- Nutanix.com Database ソリューション ページ
- データベースのための Nutanix Validated Design
- Nutanix University の Nutanix Database Service プレイリスト
以下のチャプターで、NDBについてさらに詳しく説明します:
チャプター
- NDBのアーキテクチャー
- NDBの構成とベスト プラクティス
NDBのアーキテクチャー
NDBのアーキテクチャー
NDBは、AHVまたはESXiを実行しているNutanixクラスタ上にデプロイできるソフトウェア ソリューションです。 NDBは、単一のコントロールプレーン仮想マシンによって、複数のNutanixクラスタにまたがり、高可用性(HA)構成、およびマルチ クラスタでのHA構成でデプロイできます。 NDBのインストールおよび設定方法にかかわらず、データベース管理機能(プロビジョニング、クローニング、コピー データ管理、パッチ適用、バックアップ)は変わりません。 HA構成での展開では、API、GUI、およびメタデータ リポジトリが耐障害性を持ち、1台の仮想マシン障害があっても、またはアップグレード中もオンラインのままです。 このガイドでは、NDBコントロール プレーンの設定についてさらに学べます。
NDBの単一コントロール プレーン仮想マシン展開
NDBは単一のコントロール プレーン 仮想マシンとしてデプロイできます。このインストールは、NDBのAPI、GUI、メタデータに対してデータの回復性が不要な場合に理想的です。 ただし、仮想マシンをホスティングしているNutanix Cloud Platformは高可用性で回復性があります。 アップグレード中には、アップグレードプロセスの一部でNDBの機能がオフラインになります。
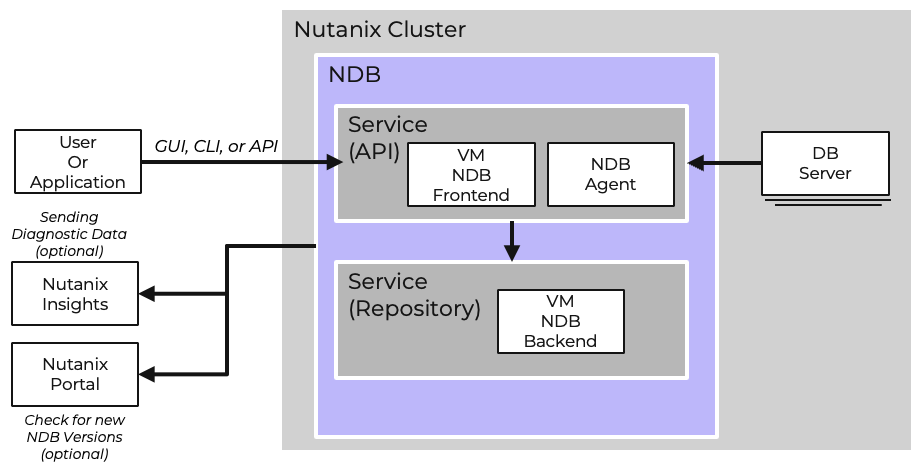
NDBの単一コントロール プレーン仮想マシンのコンポーネント
- NDBフロントエンド
- フロントエンド サーバーは、Webインターフェイスを提供し、APIエンドポイントとして機能します。
- Nutanixデータベース エージェント
- エージェントは、データベース サーバー 仮想マシン上でのNDB関連オペレーションのスケジュールと監視を行うサービスです。
- Nutanixデータベース サービス バックエンド
- バックエンドはリポジトリ データベースであり、デプロイされたデータベース、構成されたデータベース 仮想マシン、タイムマシン、スナップショット、ログ キャッチアップ操作、保持ポリシーなどのメタデータを管理します。
NDBのマルチ クラスタ展開
複数のNutanixクラスタがある場合には、NDBを2つ以上のクラスタにまたがって展開でき、以下を含むいくつかのユースケースに対応できます。
- 複数のNutanixクラスタにわたってデータベースを作成および管理し、高可用性と災害復旧を実現する。(例: Microsoft SQL Serverの可用性グループやPostgreSQLの高可用性)
- データアクセス管理ポリシーを使用して、すべての登録されたNutanixクラスタで、タイムマシンのデータ可用性を管理する。
- 本番環境および非本番環境のデータベース インスタンスを、地理的に分散したNutanixクラスタ間で単一のパネルから管理する。
- 複数のサイトにわたる、ソース データベースからテストおよび開発用データベースのクローン。
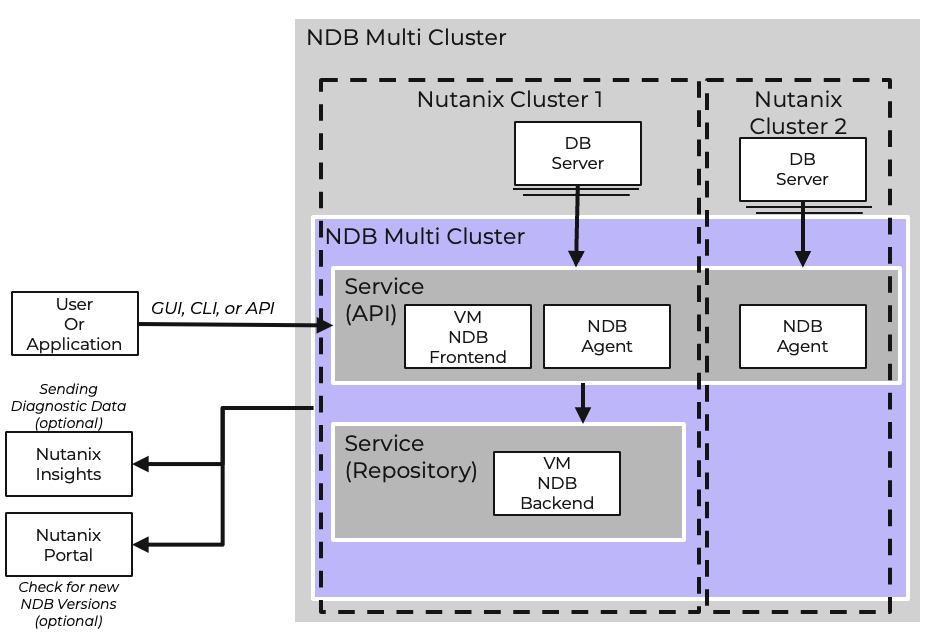
NDBの高可用性(HA)展開
NDBコントロールプレーンの高可用性および自動フェイルオーバーを確保するために、Nutanixとしては、AHVまたはESXiによる3つのNutanixクラスタを必要とし、NDBコントロール プレーン仮想マシンをフェイル障害ドメイン間で分散配置します。 サイト障害に対する保護のため、これらは別々のデータセンターまたはサイトに配置され、ラウンドトリップ時間(RTT)が25ミリ秒未満である必要があります。 選択されたクラスタ間のネットワーク遅延が25ミリ秒を超える構成はサポートされていません。
2クラスタ構成はサポートされていませんが、これは2台のAPIサーバおよび2台のリポジトリ サーバが稼働しているNutanixクラスタが単一障害点と見なされるためです。
Nutanix Database Service高可用性のコンポーネント
- APIサーバー
- NDBコントロールプレーンのステートレスREST APIゲートウェイは、APIフロントエンドおよびユーザー インターフェイスに使用されます。
- リポジトリ
- PostgreSQLデータベースは、NDBコントロール プレーンのデータ永続性レイヤを実行し、NDBのメタデータを保存します。 高可用性の構成では、NDBはPatroniフェイルオーバー マネージャーを使用し、3つのPostgreSQLレプリカ(プライマリ、同期、非同期)を持ちます。
- HAProxy
- 高可用性のロードバランサーおよびプロキシ サーバーは、APIおよびリポジトリ サーバーへの接続をルーティングします。
- VIP
- フローティング仮想IPアドレス(VIP)は、HAProxyノードにまたがり、ユーザーの接続に高可用性を提供します。 すべてのフロントエンドのユーザー接続は、VIPを通じて行われます。 NDBは、HAProxyノード間でVIPを移動させるルーティング ソフトウェアとしてKeepalivedを使用します。
- NDBエージェント
- NDBコントロール プレーン管理スタック内の仮想マシンは、複数のクラスタに対してNDBを有効にすると作成されます。 NDBに追加されたすべてのリモートNutanixクラスタには、そのクラスタのデータベース オペレーションを、管理、スケジュール、実行するNDBエージェントのインスタンスがあります。
- NDBデータベース エージェント
- NDBサービスは、データベース サーバー仮想マシン上で動作します。 これは、データベース サーバー仮想マシン上のNDBに関連するオペレーションのスケジュールと監視を行います。
複数のクラスタでHAを実行する場合、HA仮想マシン用のVLANは両方のクラスタで共有されている必要があり、異なるNutanixクラスタにHAProxyのサーバーを配置するためにサーバー間でVLANをストレッチする必要があります。
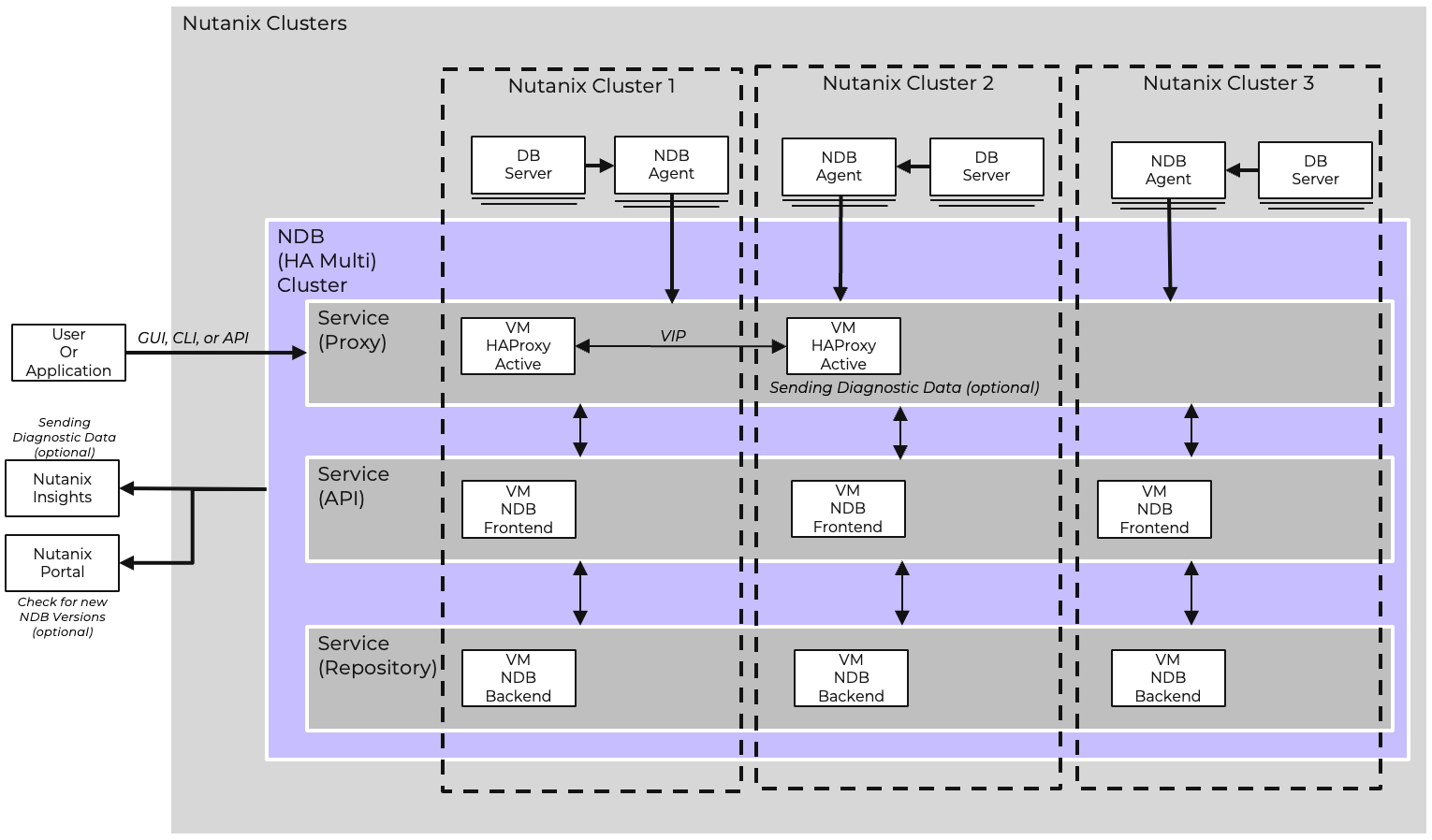
異なるNDBトポロジーにおけるIPアドレス要件と仮想マシンの分散配置
NDB Administration Guide には、Nutanix環境のニーズに合ったIPアドレスや仮想マシンの分散に関する最新の要件が記載されています。 また、以下のNDB HAリファレンス アーキテクチャも、環境に最適な構成を確認するための良いガイドとなります。
プロからのヒント
マルチクラスターのトポロジーの場合:
NDBサーバー: 非HA構成では、NDBサーバーが、すべてのNDBサービスのコントロール プレーン コンポーネントをホストします。 HAを有効にすると、元のNDBサーバーはHAスケールアウトの一環として最初のNDB APIサーバーになるため、HAトポロジー オプションには存在しなくなります。
NDB HAリファレンス アーキテクチャ
以下のリンクから Nutanix Database Service High Availability Reference Architecture をご覧ください。 このリファレンス アーキテクチャは、複数のNutanixクラスタにわたってNutanix AHVを使用してNDB高可用性(HA)を構成およびデプロイするための包括的なガイドです。
NDBの構成とベスト プラクティス
Nutanix Database Serviceコントロール プレーン
コントロール プレーンの構成
以下は、NDBサービスのトポロジー オプションです:
- 単一クラスタで、マルチ クラスタが有効化されておらず、NDB HAも有効化されていない: HAなしで管理される単一のNutanixクラスタ。
- マルチ クラスタが有効化されているが、NDB HAが有効化されていない: HAなしで管理される複数のNutanixクラスタ。
- マルチ クラスタが有効化され、NDB HAがクラスタ間で有効化されている: 最少で3つのNutanixクラスタが管理され、NDBコントロール プレーンのHAが3つのNutanixクラスタ間で有効化されている。
NDBがHAを有効化せずに構成されている場合、上記の最初の2つのオプションで示されているように、NDBサービスは単一の仮想マシン上で実行され、NDBをアップグレードするときに利用できなくなります。 仮想マシンは、起動中のNutanixクラスタ上の他ノードに移行できます。 HAが有効化されている場合、上記の最後のオプションで示されているように、NDBサービスは複数の仮想マシンに分散されるため、NDBサービスの回復性が向上し、アップグレード中もNDBがオンラインのままになります。
NDB HAについては、このガイドの「NDBのアーキテクチャー」ページで詳しく読むことができます。
Note
※Nutanix Objectsストアにログバックアップを保存するには、Nutanix Objectsのサブスクリプションが必要です。 詳細については、KB 13612 を参照してください。
※データベースは、1つのNDBインスタンスによってのみ管理されます。
タイムマシンの構成
データベース保護のためにNDB環境で管理できるタイムマシンの最大数は、NDBを高可用性で使用しているか、およびNutanix Objectsとあわせて使用しているかによって変わります。 これらの詳細や、NDBコントロール プレーン仮想マシンに対するvCPU、コア、およびメモリの正しいリソース構成については、NDB Administration Guide を確認してください。
ネットワークの構成
NDBは、管理セクションでVLANを追加したネットワーク プロファイルを作成すれば、Nutanixクラスタ上で構成された任意のネットワークVLANを使用できます。 ネットワーク ポートとセグメント化されたネットワークの詳細については以下をご覧ください。
ネットワーク ポートの要件
ポート リファレンス ガイドには、Nutanix製品およびサービスに関する詳細なポート情報が含まれており、ポートの送信元と送信先、サービスの説明、通信方向、プロトコルの要件が記載されています。
この表は、ポート リファレンス ガイドへのリンクを提供します。1
| NDBポート要件 | ドキュメントへのリンク |
|---|---|
| データベース サーバー 仮想マシン | NDB (Database Server VM) |
| マルチ クラスタ ネットワーク | NDB (Multi-cluster Network) |
| Oracle | NDB (Oracle) |
| SQL Server | NDB (SQL Server) |
| PostgreSQL | NDB (PostgreSQL) |
| MySQLとMariadB | NDB (My SQL and Maria DB) |
| NDBコントロール プレーン(HA) | NDB Control Plane (HA) |
ネットワーク セグメンテーション
NDBは、管理、仮想マシン、そしてデータサービス用にネットワーク セグメンテーションが構成された、Nutanix Cloud Clustersをサポートしています。 アーキテクチャー図は以下をご覧ください。
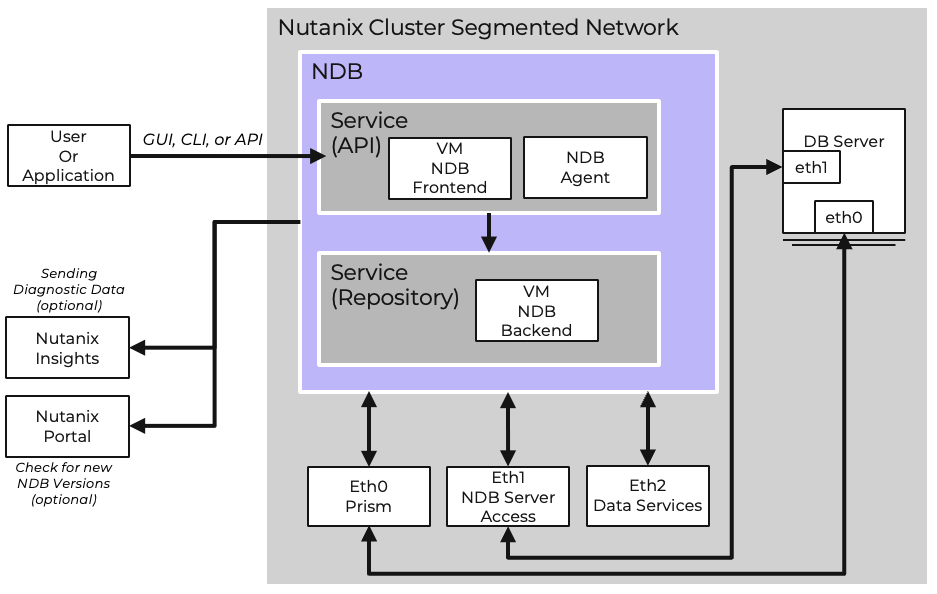
データベースがセグメント化されたネットワークを利用できるかどうかや、各データベースのネットワークプロファイルを作成する方法については、Nutanix Support Portalにある NDB Management Guide を確認してください。
Databaseのベスト プラクティス
NDBがデータベースをプロビジョニングする際に、Nutanixによる最新の推奨ベスト プラクティスが適用されます。 Nutanix Support Portalで、NDBを使用してデータベースを展開するためのベスト プラクティスを見るには、以下のリンクをクリックしてください。
- MySQL/MariaDB ベスト プラクティス
- PostgreSQL ベスト プラクティス
- Microsoft SQL Server ベスト プラクティス
- Oracle Database ベスト プラクティス
- MongoDB ベスト プラクティス
Nutanix Database Serviceを使用せずにNutanix上でデータベースを実行している場合は、データベースから最良のパフォーマンスを得るために、これらのベスト プラクティスを手動で適用する必要があります。
脚注
API
※本書の内容は、PC 2024.3 と AOS 7.0 をベースにしています。
Prism CentralおよびPrism ElementのHTML5インターフェイスは、Nutanix Cloud Platform(NCP)の管理における重要なコンポーネントです。 しかし、さまざまなユースケースで、Prism Centralの機能や動作のプログラムによる制御と、Prism Centralと統合されているNutanix製品と同様のプログラム制御が求められます。 Prism CentralおよびPrism Elementインターフェイスで提供されるほとんどの機能は、完全なセットのREST APIを通じても提供されています。 これらの API は、Nutanix プラットフォームにおけるプログラムのためのインターフェイスを提供し、お客様およびパートナーが自動化、サードパーティツール、スクリプト、アプリケーションの開発、さらには必要に応じてカスタマイズされた UI の作成を可能にします。
動的な、あるいは「ソフトウェア デファインド」な環境に不可欠なものとして、Nutanixでは、様々なインターフェイスを提供することで、シンプルなプログラミングとインターフェイス機能を実現します。 主なインターフェイスには、次のようなものがあります:
- REST API
- CLI - aCLIおよびnCLI
- スクリプトインターフェイス
Nutanix.dev - Nutanix Developer Portal
さらに利用可能なNutanix Prismと製品APIの詳細を学び、サンプル コードを確認してセルフペース ラボを受講するには、必ず https://www.nutanix.dev をチェックしてください!
リソースおよびスクリプト:
- Nutanix.dev (Developer Portal): https://www.nutanix.dev
- Nutanix.dev GitHub - https://github.com/nutanixdev
- Nutanix.dev Code Samples - https://github.com/nutanixdev/code-samples
- Nutanix.dev Technical Articles - https://www.nutanix.dev/blog/
- Nutanix v4 API Documentation: https://developers.nutanix.com
- Nutanix GitHub - https://github.com/nutanix
免責事項: すべてのコード サンプルは © Nutanix, Inc. であり、MITライセンス(https://opensource.org/licenses/MIT)のもとで現状のまま提供されます。
チャプター
- REST API
- CLI - nCLIおよびaCLI
- PowerShellコマンドレット
REST API
REST APIとSDKの概要
Note: Nutanix v4 APIは、すべてのユースケースに推奨されるバージョンです。 ここでは、v4 Prism Central APIに焦点を当て、レガシーAPI(v1、v2、v3)は、特定の機能や機能がv4 APIで利用できない場合にのみ使用する必要があります。
Prism Central REST APIはPrism Central UIのほぼ全ての機能やデータポイントを公開しており、オーケストレーションや自動化ツールから簡単にNutanixを制御することができます。 これにより、Terraform、Ansible、SaltStack、Puppetなどのツールで、容易にNutanixのカスタム ワークフローを構築できます。 つまり、どのようなサードパーティ開発者でも独自のUIを開発し、REST API経由でNutanixのデータを引き出すことができます。
以下の図は、Nutanix REST API Explorer の一部を示しており、開発者が API と対話し、想定されるデータの形式を確認できることを説明しています。
Nutanix v4 APIおよびSDKのドキュメント
すべてのNutanix v4 APIドキュメントは、https://developers.nutanix.com にある新しいドキュメント ポータルからアクセスできます。 以下のスクリーンショットは、Nutanix v4 APIドキュメントのホーム ページを示しています。
Note: レガシーv3 APIは、Prism Centralにログインすると利用可能なNutanix REST API Explorerで引き続きサポートされています。
Nutanix v4 API: SDKのサポート言語
以下の言語向けのSDKが現在利用可能です。
- Python(3.6、3.7、3.8、3.9 が公式にサポートされている)
- Java
- Go
- JavaScript
REST API Explorer for legacy v2 APIs(Prism Element)
レガシーAPIは、以下のスクリーンショットに示されているように、Nutanix REST API Explorerで引き続きサポートされています。
Prism Element REST API Explorer
Expand Operations で、詳細とRESTコールの例を表示するよう展開できます。
REST API Explorer for legacy v3 APIs(Prism Central)
REST APIの認証
Nutanix v4 REST APIは、2つの認証方式をサポートしています:
- ユーザー名とパスワードによるHTTPベーシック認証
- 組み込みまたは環境固有の認可ポリシーを使用したNutanix IAM APIキー認証
認証は2つの「モード」で完了できます:
- 読み取り専用:APIによってのみ公開される情報を収集および検査します。
- 管理的:読み取り専用ユーザー アカウントとエンティティ管理で利用できるすべてのアクションです。 仮想マシンのCRUD操作、NCM Self-Service のブループリント、Nutanix Flow ネットワーク セキュリティ ポリシーを含みますが、これらに限定されません。
Nutanix IAM認可ポリシーは、ユーザーが実行可能な特定のアクションに対して詳細な制御を適用できます。
REST APIのバージョン
現在、Nutanix Prism ElementとPrism Centralは一般的に利用可能な3つのAPIを提供しています。
- v4: Prism Centralのみで利用可能。 すべての管理アクティビティ、たとえば仮想マシン管理やCRUD操作、またはNCM Self-ServiceやFlow Network SecurityなどのPrism Centralに統合されている製品の管理に推奨されるAPIです。
- レガシーv3 API: Prism Centralのみで利用可能。 完全なサポートは将来的な非推奨化まで継続されます。 仮想マシン管理やNCM Self-Service(旧称Calm)、Flow Network Securityを含むNutanix製品管理などのマルチクラスタのアクティビティに使用されます。
- レガシーv2.0 API: Prism Elementでのみ利用可能。 完全なサポートは将来的な非推奨化まで継続されます。 特にPrism Centralが展開されていない環境で、ストレージ コンテナの管理操作など、クラスタ ローカルのアクティビティに使用されます。
利用可能なAPIバージョンとそれらが公開する操作の詳細については、Nutanix.devにあるAPI Versionsを参照してください。
Nutanix製品が提供しているAPI
APIによって完全または部分的に管理できるNutanix製品の非網羅的なリストは次のとおりです。 必要に応じてドキュメントにリンクされています。
- Nutanix Prism Central: v4
- Nutanix Prism Central: v3
- Nutanix Prism Element
- NCM Self-Service
- Nutanix Database Service
全てのAPIリファレンスの完全なリストについては、Nutanix.dev API Referenceを参照してください。
Prism Central v4 APIs and SDKs
Prism Element v2.0 vs Prism Central v3 APIs
Note: レガシーとして後方互換性のサポートのためにのみ提供されます。
選択されるAPIは、要求される操作によって異なります。
Prism Central v3はマルチクラスタのものであり、Prism Centralを通じてのみ利用可能です。 こちらは、分散配置されたディスク イメージ、NCM Self-Service(旧称:Calm)のブループリントとアプリ、マーケットプレイス アイテム、ネットワーク セキュリティ ルールなど、複数のクラスタに影響を与えうる操作を公開しています。
Prism Element v2.0はクラスタ ローカルであり、Prism Elementを通じてのみ使用可能ます。 こちらは、ストレージ コンテナ、保存データの暗号化、ストレージ プール、ホストなどのローカル クラスタ エンティティ固有の操作を公開しています。
使用例: Prism Central API v4 REST API
Request
Nutanix Prism Centralを通じてのみアクセス可能です。すべてのAPIリクエストは以下のように組み立てられます。
METHOD https://PRISM_CENTRAL_IP_OR_FQDN:9440/api/NAMESPACE/VERSION/PATH/ACTIONS
Prism CentralのIPアドレスを192.168.1.110と仮定した場合の、すべてのPrism Centralイメージをリストするリクエストの例:
GET https://192.168.1.110:9440/api/vmm/v4.0/content/images
イメージ作成の例:
POST https://192.168.1.110:9440/api/vmm/v4.0/content/images
JSON形式でイメージの構成を付加する例:
{ "name": "", "type": "DISK_IMAGE", "description": "Image created with Nutanix v4 APIs", "source": { "url": "", "$objectType": "vmm.v4.content.UrlSource" }, "clusterLocationExtIds": [ "" ] }
リクエストの冪等性を確保するために、このリクエストには Ntnx-Request-Id ヘッダーを付加する必要があり、その値は、この特定のリクエストを一意に識別するUUIDです。
UUIDの生成方法は環境によって異なりますが、さまざまなオンラインツールを使用して生成可能です。
レスポンス
リクエストの応答にはタスクのステータスが含まれており、data.extId フィールドで示されます。
このタスクは、Prism CentralまたはAPIを通して確認することで、操作のステータスを表示でき、それには進行状況のパーセンテージやプロセス中に発生したエラーが含まれます。
{ "data": { "$reserved": { "$fv": "v4.r0" }, "$objectType": "prism.v4.config.TaskReference", "extId": "ZXJnb24=:447c5e9e-b7ad-408e-ae4f-82de667ef72e" }, "$reserved": { "$fv": "v4.r0" }, "$objectType": "vmm.v4.content.CreateImageApiResponse", "metadata": { "flags": [ { "$reserved": { "$fv": "v1.r0" }, "$objectType": "common.v1.config.Flag", "name": "hasError", "value": false }, { "$reserved": { "$fv": "v1.r0" }, "$objectType": "common.v1.config.Flag", "name": "isPaginated", "value": false }, { "$reserved": { "$fv": "v1.r0" }, "$objectType": "common.v1.config.Flag", "name": "isTruncated", "value": false } ], "$reserved": { "$fv": "v1.r0" }, "$objectType": "common.v1.response.ApiResponseMetadata", "links": [ { "$reserved": { "$fv": "v1.r0" }, "$objectType": "common.v1.response.ApiLink", "href": "https://192.168.1.110:9440/api/prism/v4.0/config/tasks/ZXJnb24=:447c5e9e-b7ad-408e-ae4f-82de667ef72e", "rel": "self" }, { "href": "https://192.168.1.110:9440/api/vmm/v4.0/content/images", "rel": "image-list" } ] } }
この例を独自の環境で使用するには、`192.168.1.110` を要件に一致するものに変更します。
Related Resources
- v4 API: Create Prism Central Image:Nutanix.devに掲載されている、Prism Centralイメージを作成するための完全なv4 REST APIコードサンプル
- v4 API: Create Prism Central Image (Python SDK):Nutanix.devに掲載されている、Prism Centralイメージを作成するための完全なv4 REST API Python SDKコードサンプル
- Nutanix v4 API Code Sample Library.
使用例: Prism API v3.0
リクエスト
Nutanix Prism API v3は、Prism Centralを通じてのみ使用可能です。 全てのAPIリクエストは次のように構成されます。
METHOD https://PRISM_CENTRAL_IP:9440/api/nutanix/v3/API_NAME/VARIABLES
Prism Central IPが192.168.1.110であると仮定した、全ての仮想マシンをリストするリクエストの例。
POST https://192.168.1.110:9440/api/nutanix/v3/vms/list
JSON形式のペイロードが付随します。 この例では、Prism Centralは種類がvmのすべての項目を返すように指示しています。
{ "kind": "vm" }
仮想マシン作成の例:
POST https://192.168.1.110:9440/api/nutanix/v3/vms
JSON形式の仮想マシン構成が付随します。 例:
{ "spec": { "name": "vm_api_v3", "resources": {}, "cluster_reference": { "uuid": "0005f2f7-eee7-1995-6145-ac1f6b35fe5e", "kind": "cluster" } }, "metadata": { "kind": "vm" } }
レスポンス
このリクエストからのレスポンスにはタスクのステータス(現在はPENDING)が含まれ、新しい仮想マシンを所有するクラスタや、tasks APIを使用して詳細をクエリできるtask_uuidが含まれます。
{ "status": { "state": "PENDING", "execution_context": { "task_uuid": "1c64cc8b-241d-4132-955f-f6e26239ac02" } }, "spec": { "name": "vm_api_v3", "resources": {}, "cluster_reference": { "kind": "cluster", "uuid": "0005f2f7-eee7-1995-6145-ac1f6b35fe5e" } }, "api_version": "3.1", "metadata": { "use_categories_mapping": false, "kind": "vm", "spec_version": 0, "uuid": "d965afdc-4606-4a0b-bc99-f868ae615039" } }
この例を独自の環境で使用するには、クラスタのuuidをクラスタにあわせた値に変更します。
詳細については、Nutanix.devのAPI ReferenceにあるCreate a new VMを参照してください。
使用例: Prism API v2.0
リクエスト
Nutanix Prism API v2.0は、Prism Elementを通じてのみ利用可能です。 すべてのAPIリクエストは次のように構成されます。
METHOD https://CVM_OR_CLUSTER_IP:9440/api/nutanix/v2.0/API_NAME/VARIABLES
クラスタIPが192.168.1.100であると仮定して、すべてのストレージ コンテナをリストするリクエストの例。
GET https://192.168.1.100:9440/api/nutanix/v2.0/storage-containers
仮想マシン作成の例
POST https://192.168.1.100:9440/api/nutanix/v2.0/vms
JSON形式の仮想マシン構成が付随します。 例:
{ "description": "VM created by v2.0 API", "memory_mb": 1024, "name": "vm_api_v2.0", "num_vcpus": 1, "num_cores_per_vcpu": 1, "vm_disks": [ { "is_cdrom": false, "vm_disk_create": { "size": 128849018880, "storage_container_uuid": "b2fefc62-6274-4c84-8e6c-a61f5313ea0e" } } ] }
レスポンス
このリクエストからの応答には、tasksAPIを使用してクエリできるPrismタスクのUUIDが含まれています。
{ "task_uuid": "eec7d743-b6c7-4c6d-b821-89b91b142f1d" }
この例を独自の環境で使用するには、storage_container_uuidをクラスタにあわせた値に変更します。
詳細については、Nutanix.devのAPI ReferenceにあるCreate a Virtual Machineを参照してください。
Note: /api/nutanix/v2.0パスは、/PrismGateway/services/rest/v2.0のエイリアスです。 PrismGatewayパスはPrism API v2.0ドキュメントでよく参照されますが、どちらのパスも互換的に使用でき、同じ結果が得られます。
CLI - aCLIおよびnCLI
aCLI
Acropolis CLI(aCLI)は、Nutanix製品のAcropolisとAHV部分を管理するためのCLIです。 これらの機能は、AOS 4.1.2以降のリリースで有効になり、Nutanix AHVクラスタのCVMのみで使用できます。 aCLIは、Prism Centralではサポートされていません。
現行のaCLIコマンド リファレンスは、Nutanix Portalで見つけられます。
aCLIシェルの起動
説明: aCLIシェルの起動
acli
または
説明: LinuxシェルからaCLIコマンドを実行
acli <command>
aCLIを起動、結果をJSONフォーマットで出力
説明: クラスタ内のAOSノード一覧を出力
acli -o json
AHVホストの一覧
説明: クラスタ内のAHVノード一覧を出力
host.list
このスクリーンショットは、「host.list」の出力をテーブル形式とJSON形式の両方で示しています。 難読化された情報は、クラスタ固有のシリアル番号とIPアドレスです。
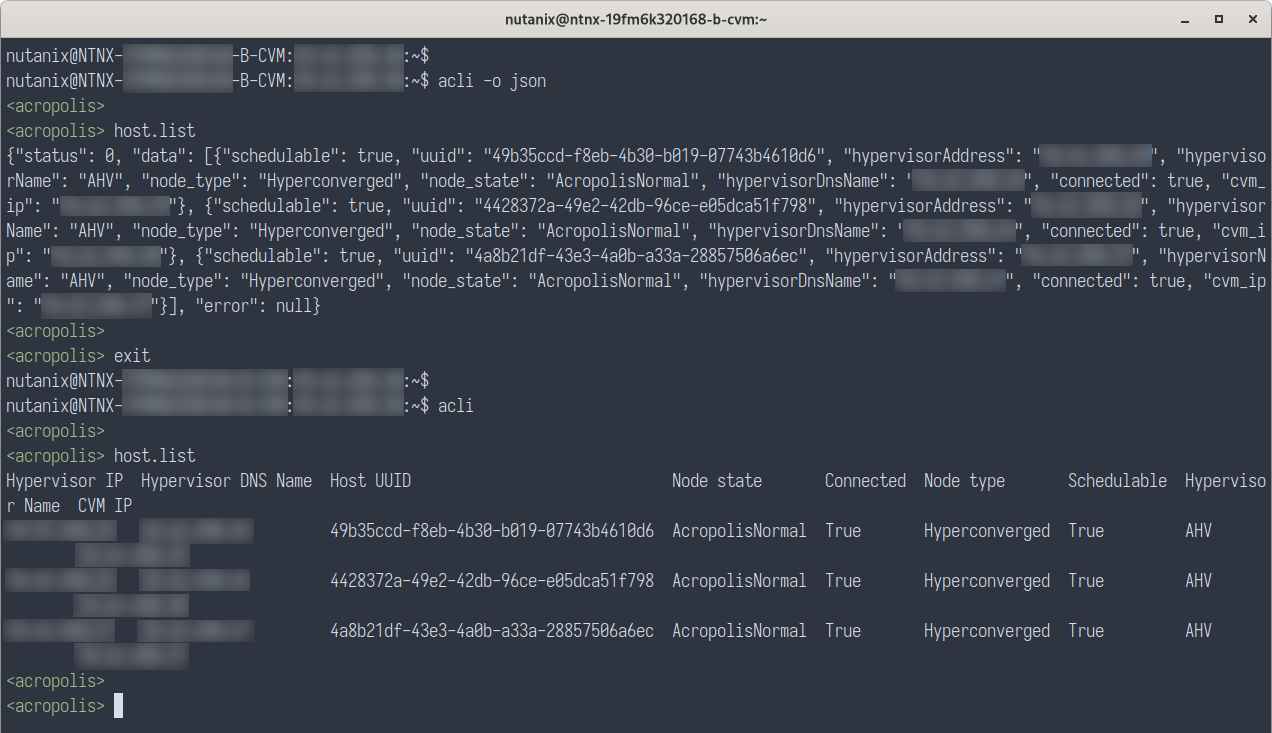
ネットワークの作成
説明: VLANベースのネットワークを作成
net.create <NAME> <TYPE>.<ID>[.<VSWITCH>] ip_config=<A.B.C.D>/<NN> vlan=<VLAN>
例:
net.create vlan.133 ip_config=10.1.1.1/24 vlan="133"
ネットワーク一覧
説明: ネットワーク一覧出力
net.list
DHCPスコープの作成
説明: DHCPスコープの作成
net.add_dhcp_pool <NET NAME> start=<START IP A.B.C.D> end=<END IP W.X.Y.Z>
注意:ネットワークの作成時にDHCPサーバーのアドレスが設定されなかった場合、ネットワーク範囲内で最後に使用可能なIPアドレスがAcropolis DHCPサーバーに選択されます。
例:
net.add_dhcp_pool vlan.100 start=10.1.1.100 end=10.1.1.200 vlan="100"
既存ネットワークの詳細を取得
説明: ネットワークのVMとVM名、UUID、MACアドレスおよびIPを含む詳細を取得
net.list_vms <NET NAME>
例:
net.list_vms vlan.133
ネットワークのためのDHCP DNSサーバーを設定
説明: DHCP DNSの設定
net.update_dhcp_dns <NET NAME> servers=<COMMA SEPARATED DNS IPs> domains=<COMMA SEPARATED DOMAINS>
例:
net.update_dhcp_dns vlan.100 servers=10.1.1.1,10.1.1.2 domains=ntnxlab.local
仮想マシンの作成
説明: 仮想マシンの作成
vm.create <COMMA SEPARATED VM NAMES> memory=<NUM MEM MB> num_vcpus=<NUM VCPU> num_cores_per_vcpu=<NUM CORES> ha_priority=<PRIORITY INT>
例:
vm.create testVM memory=2G num_vcpus=2
複数の仮想マシンを作成
説明: 複数の仮想マシンを作成
vm.create <CLONE PREFIX>[<STARTING INT>..<END INT>] memory=<NUM MEM MB> num_vcpus=<NUM VCPU> num_cores_per_vcpu=<NUM CORES> ha_priority=<PRIORITY INT>
例:
vm.create testVM[000..999] memory=2G num_vcpus=2
既存の仮想マシンからクローンを作成
説明: 既存の仮想マシンからクローンを作成
vm.clone <CLONE NAME(S)> clone_from_vm=<SOURCE VM NAME>
例:
vm.clone testClone clone_from_vm=MYBASEVM
既存の仮想マシンから複数のクローンを作成
説明: 既存の仮想マシンから複数のクローンを作成
vm.clone <CLONE PREFIX>[<STARTING INT>..<END INT>] clone_from_vm=<SOURCE VM NAME>
例:
vm.clone testClone[001..999] clone_from_vm=MYBASEVM
ディスクを作成して仮想マシンに追加
説明: OSのためのディスクを作成
vm.disk_create <VM NAME> create_size=<Size and qualifier, e.g. 500G> container=<CONTAINER NAME>
例:
vm.disk_create testVM create_size=500G container=default
仮想マシンにNICを追加
説明: NICを作成して追加
vm.nic_create <VM NAME> network=<NETWORK NAME> model=<MODEL>
例:
vm.nic_create testVM network=vlan.100
ディスクに仮想マシンのブートデバイスを設定
説明: 仮想マシンのブートデバイスを設定
特定のディスクIDからブートするように設定
vm.update_boot_device <VM NAME> disk_addr=<DISK BUS>
例:
vm.update_boot_device testVM disk_addr=scsi.0
CD-ROMを仮想マシンに追加
CD-ROMを仮想マシンに追加
vm.disk_create <VM NAME> cdrom="true" empty="true"
例:
vm.disk_create testVM cdrom="true" empty="true"
CD-ROMに仮想マシンのブートデバイスを設定
CD-ROMからブートするよう設定
vm.update_boot_device <VM NAME> disk_addr=<CD-ROM BUS>
例:
vm.update_boot_device testVM disk_addr=ide.0
CD-ROMにISOをマウント
説明: 仮想マシンのCD-ROMにISOをマウント
手順:
- ISOをコンテナにアップロード
- クライアントIPのホワイトリストを有効化
- ISOをアップロードして共有
CD-ROMとISOを作成
vm.disk_create <VM NAME> clone_from_adfs_file=</CONTAINER/ISO> cdrom=true
例:
vm.disk_create testVM clone_from_adfs_file=/default/ISOs/myfile.iso cdrom=true
CD-ROMを作成済みの場合はマウントのみを実行
vm.disk_update <VM NAME> <CD-ROM BUS> clone_nfs_file<PATH TO ISO>
例:
vm.disk_update atestVM1 ide.0 clone_nfs_file=/default/ISOs/myfile.iso
CD-ROMからISOをデタッチ
説明: CD-ROMからISOを削除
vm.disk_update <VM NAME> <CD-ROM BUS> empty=true
仮想マシンの起動
説明: 仮想マシンを起動する
vm.on <VM NAME(S)>
例:
vm.on testVM
全ての仮想マシンを起動
例:
vm.on *
プリフィックスの一致する全ての仮想マシンを起動
例:
vm.on testVM*
特定範囲の仮想マシンを起動
例:
vm.on testVM[0-9][0-9]
nCLI
現行のnCLIのコマンド リファレンスは、Nutanix Portalで見つけられます。
Nutanix Command Line Interface(nCLI)では、Nutanixクラスタに対してシステム管理コマンドを実行できます。 aCLIとは対照的に、nCLIはローカル マシンにインストールできます。 インストールの詳細については、上記のNutanix Portalのリンクを参照してください。
Nutanixのバージョンを表示
説明: Nutanixソフトウェアの現在のバージョンを表示
ncli cluster version
このスクリーンショットは、シングル ライン コマンドとしての「ncli version」からの出力と、ncli「セッション」内からの出力の両方を示しています。
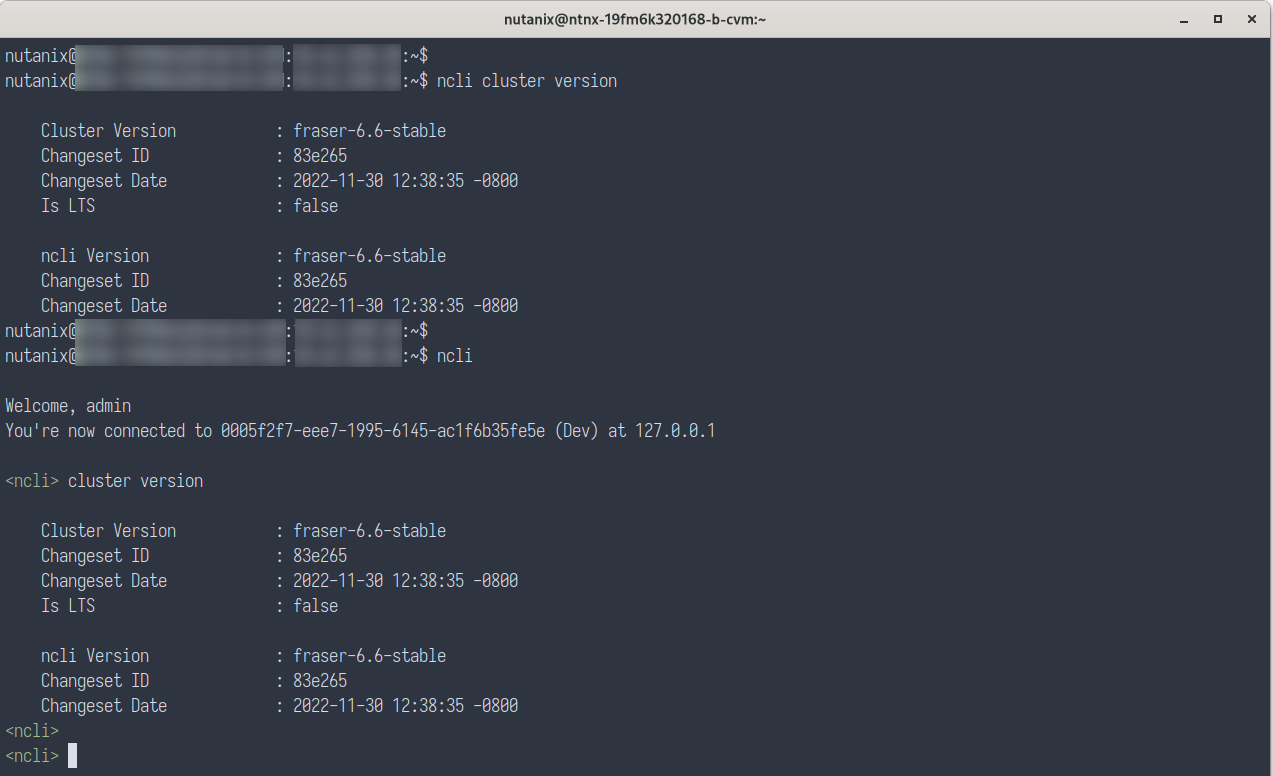
NFSホワイトリストにサブネットを追加
説明: NFSホワイトリストに特定のサブネットを追加
ncli cluster add-to-nfs-whitelist ip-subnet-masks=10.2.0.0/255.255.0.0
ストレージ プール一覧
説明: 既存のストレージ プール一覧を表示
ncli sp ls
Note: この例は、短縮されたコマンドの使用法を示しています。 「storagepool」は「sp」、「list」は「ls」になります。
コンテナ一覧
説明: 既存のコンテナ一覧を表示
ncli ctr ls
コンテナの作成
説明: 新しいコンテナを作成
ncli ctr create name=<NAME> sp-name=<SP NAME>
仮想マシンの一覧
説明: 既存のVM一覧を表示
ncli vm ls
パブリックキーの一覧
説明: 既存のパブリックキー一覧を表示
ncli cluster list-public-keys
パブリックキーの追加
説明: クラスタアクセスのためのパブリックキーを追加
CVMにSCPしておいたパブリックキーをクラスタに追加する
ncli cluster add-public-key name=myPK file-path=~/mykey.pub
パブリックキーは、あらかじめCVMにSCPで転送しておきます。
パブリックキーの削除
説明: クラスタアクセスのためのパブリックキーを削除
ncli cluster remove-public-keys name=myPK
プロテクションドメインの作成
説明: プロテクションドメインの作成
ncli pd create name=<NAME>
リモートサイトの作成
説明: レプリケーションのためのリモートサイトを作成
ncli remote-site create name=<NAME> address-list=<Remote Cluster IP>
ストレージ コンテナ内の全ての仮想マシンのためのプロテクションドメインを作成
説明: 指定したコンテナ内の全ての仮想マシンを保護
ncli pd protect name=<PD NAME> ctr-id=<Container ID> cg-name=<NAME>
指定した仮想マシンに対するプロテクションドメインを作成
説明: 指定した仮想マシンを保護
ncli pd protect name=<PD NAME> vm-names=<VM Name(s)> cg-name=<NAME>
AOSファイル(vDisk)のためのプロテクションドメインを作成
説明: 指定したAOSファイルを保護
ncli pd protect name=<PD NAME> files=<File Name(s)> cg-name=<NAME>
プロテクションドメインのスナップショットを作成
説明: プロテクションドメインのワンタイムスナップショットを作成
ncli pd add-one-time-snapshot name=<PD NAME> retention-time=<seconds>
リモートサイトに対するスナップショットとレプリケーションスケジュールの作成
説明: n個のリモートサイトに対するスナップショットとレプリケーションの反復スケジュール作成
ncli pd set-schedule name=<PD NAME> interval=<seconds> retention-policy=<POLICY> remote-sites=<REMOTE SITE NAME>
レプリケーションステータスの表示
レプリケーションステータスのモニター
ncli pd list-replication-status
プロテクションドメインをリモートサイトに移行
説明: プロテクションドメインをリモートサイトにフェイルオーバー
ncli pd migrate name=<PD NAME> remote-site=<REMOTE SITE NAME>
プロテクションドメインの有効化
説明: リモートサイトでプロテクションドメインを有効にする
ncli pd activate name=<PD NAME>
クラスタ回復機能 (resiliency) のステータスを確認
ノードのステータス
ncli cluster get-domain-fault-tolerance-status type=node
ブロックのステータス
ncli cluster get-domain-fault-tolerance-status type=rackable_unit
PowerShell コマンドレット
Nutanix PowerShell コマンドレットの使用を開始するにはNutanix Support PortalにあるPowerShell Cmdlets Referenceを参照してください。
以下では、Nutanix PowerShell コマンドレットの使用方法、および前提となるWindows PowerShellについて説明します。
PowerShellのバージョン
この記事の執筆時点で、利用可能な最新バージョンはPowerShell 7.3.4です。
このNutanix Cloud Bibleの章で説明されているコマンドは、以前のPowerShellバージョンには適用されない場合があります。
PowerShellの基本
Windows PowerShellは、.NETフレームワークに実装された強力なシェルでありスクリプト言語です。 使い方は非常にシンプルかつ直観的でインタラクティブな操作が可能です。 PowerShellには、いくつかの構成要素があります:
コマンドレット
コマンドレットは、特定の処理を行うためのコマンドまたは .NETのクラスです。 ほとんどの場合、Getter/Setterメソッドに従い、通常は <Verb>-<Noun> という構文を使用します。 例えば、Get-ProcessやSet-Partitionなどが該当します。
パイプとパイプライン
パイプはPowerShellの重要な機能(同様な機能がLinuxにもあります)であり、正しく使えば様々なことがシンプルになります。 パイプを使用すると、基本的にパイプラインの1つのセクションの出力を取得し、それをパイプラインの次のセクションへの入力として使用します。 パイプラインは必要に応じて(パイプの次のセクションに供給される出力が残っていると仮定して)いくらでも連結することができます。
簡単な例として、現在のプロセス一覧を取得し、その特性でマッチングまたはフィルタリングし、最後にソートするという処理を以下に示します:
Get-Service | where {$_.Status -eq "Running"} | Sort-Object Name
パイプラインは、for-each文でも使用できます。例えば次のようになります:
# For each item in myArray $myArray | %{ # Do something }
主要なオブジェクトタイプ
以下にPowerShellの主要なオブジェクトタイプを示します。 オブジェクトタイプは、.getType() メソッドで確認できます。 例えば、$someVariable.getType() はオブジェクトタイプを返します。
変数(Variable)
$myVariable = "foo"
注意: 一連のコマンドまたはパイプラインの出力に、変数を設定することもできます。
$myVar2 = (Get-Service | where {$_.Status -eq "Running"})
$myVar3 = (Get-Process | where {$_.ProcessName -eq "Chrome"})
この例では、括弧内のコマンドが最初に評価され、変数がその出力先になります。
配列(Array)
$myArray = @("Value","Value")
注意: 配列、ハッシュテーブルまたはカスタムオブジェクトの配列も使用できます。
ハッシュテーブル
$myHash = @{"Key" = "Value";"Key" = "Value"}
便利なコマンド
特定のコマンドレットのヘルプ内容を取得します(Linuxのmanページと同様)。
Get-Help <コマンドレットの名前>
例:
Get-Help Get-Process
コマンドまたはオブジェクトのプロパティとメソッド一覧を表示
<Some expression or object> | Get-Member
例:
$someObject | Get-Member
主要なNutanixコマンドレットと使用方法
NutanixコマンドレットはPrism Central UIから直接ダウンロードでき、右上隅のドロップダウン メニューで見つけられます。
Nutanixコマンドレット v2.0 - 使用例
現行のNutanixコマンドレットv2.0のリファレンスはNutanix Portalで見つけられます。
Nutanixコマンドレットの一覧
Get-Command -Module Nutanix.Prism.Common
Get-Command -Module Nutanix.Prism.Ps.Cmds
Prism Centralへの接続
全ての接続詳細の入力が求められ、有効なSSL証明書のみを受け入れます:
Connect-PrismCentral
接続の詳細(パスワードを除く)を入力し、有効および無効なSSL証明書を受け入れます:
Connect-PrismCentral -AcceptInvalidSSLCerts -Server <prism_central_ip_addres> -UserName <username>
全ての仮想マシンの一覧
Get-VM
特定の文字列にマッチする仮想マシンの取得
変数に割り当て:
$searchString = "my-vm-name" $vms = Get-VM | where {$_.vmName -match $searchString}
インタラクティブ:
$myVm = Get-VM | where {$_.vmName -match "myVmName"}
インタラクティブでテーブル形式にフォーマット:
$myVm = Get-VM | where {$_.vmName -match "myVmName"} | ft
全てのストレージ コンテナの一覧
Get-StorageContainer
似ている名前のストレージ コンテナの一覧
Get-StorageContainer | where {$_.name -like "Nutanix*"}
全てのネットワークの一覧
Get-Network
名前を元にしたネットワークの取得
Get-Network | where ${_.name -eq "Default"}
Prism Centralからの切断
Disconnect-PrismCentral
Note
レガシーなNutanixコマンドレットの情報
次のセクションの情報は、レガシーなNutanixコマンドレットおよびPowerShellバージョンのみに適用されます。 これは、レガシー サポートのためにここに残されています。 可能であれば、新規ユーザーには、PowerShellとNutanixコマンドレットの両方の最新バージョンをインストールすることをお勧めします。
Nutanix Cmdlets v1.0 - 使用例
Nutanixコマンドレットv1.0のリファレンスは、Nutanix Portalで見つけられます。
Nutanixスナップインのロード
スナップインがロードされているかどうかを確認し、実施されていなければロードする
if ((Get-PSSnapin -Name NutanixCmdletsPSSnapin -ErrorAction SilentlyContinue) -eq $null) { Add-PsSnapin NutanixCmdletsPSSnapin }
Nutanix コマンドレットの一覧表示
Get-Command | Where-Object{$_.PSSnapin.Name -eq "NutanixCmdletsPSSnapin"}
Nutanixクラスタに接続
Connect-NutanixCluster -Server $server -UserName "myuser" -Password (Read-Host "Password: " -AsSecureString) -AcceptInvalidSSLCerts
検索文字列に一致するNutanix仮想マシンの一覧
変数に対して出力
$searchString = "myVM"
$vms = Get-NTNXVM | where {$_.vmName -match $searchString}
インタラクティブ
Get-NTNXVM | where {$_.vmName -match "myString"}
インタラクティブおよびフォーマット設定
Get-NTNXVM | where {$_.vmName -match "myString"} | ft
Nutanix vDiskの一覧
変数に対して出力
$vdisks = Get-NTNXVDisk
インタラクティブ
Get-NTNXVDisk
インタラクティブおよびフォーマット設定
Get-NTNXVDisk | ft
Nutanixコンテナ一覧
変数に対して出力
$containers = Get-NTNXContainer
インタラクティブ
Get-NTNXContainer
インタラクティブおよびフォーマット設定
Get-NTNXContainer | ft
Nutanixプロテクションドメインの一覧
変数に対して出力
$pds = Get-NTNXProtectionDomain
インタラクティブ
Get-NTNXProtectionDomain
インタラクティブおよびフォーマット設定
Get-NTNXProtectionDomain | ft
Nutanix整合性グループ一覧
変数に対して出力
$cgs = Get-NTNXProtectionDomainConsistencyGroup
インタラクティブ
Get-NTNXProtectionDomainConsistencyGroup
インタラクティブおよびフォーマット設定
Get-NTNXProtectionDomainConsistencyGroup | ft
Modern Applications and AI/ML
Cloud Native Services
CNCFでは、クラウドネイティブを「組織が、パブリック、プライベート、ハイブリッドクラウドといったモダンで動的な環境において、拡張可能なアプリケーションを構築および実行できるようにするテクノロジーのセット」と定義しています。 アプリケーションモダナイゼーションへの移行を推進する主要なテクノロジーには、コンテナ、マイクロサービス、そしてKubernetesが含まれます。
Nutanix Cloud Infrastructure(NCI)は、大規模なKubernetesで実行されるクラウドネイティブ ワークロードの理想的な基盤です。 Nutanixはプラットフォームのモビリティを提供し、Nutanixプライベートクラウドと、パブリッククラウドとの両方でワークロードを実行するための選択肢を提供します。 Nutanixアーキテクチャーはハードウェア障害を念頭に置いて設計されており、それはKubernetesプラットフォームコンポーネントとアプリケーションデータの両方に、より良い回復力を提供します。 HCIノードを追加することで、Kubernetesコンピュートノードに拡張性と回復力が提供される恩恵を受けられます。 同様に重要なこととして、各HCIノードとともにデプロイされる追加のストレージコントローラーがあることで、ステートフルなコンテナ化されたアプリケーションのストレージパフォーマンスが向上することが挙げられます。
Nutanix Kubernetes Platform(NKP)は、エンタープライズ対応のクラウド ネイティブ プラットフォームであり、クラウド、マルチクラウド、ハイブリッドクラウド、オンプレミス、エッジ、エアギャップ環境を含むさまざまなインフラストラクチャ全体で、Kubernetesの管理と展開を簡素化します。 NKP は、プロダクション対応のクラウド ネイティブ環境を迅速に展開でき、Nutanix Cloud Infrastructure(NCI)、Nutanix Unified Storage、Nutanix Database Serviceといった他の Nutanix 製品と統合することで、異なるクラウド環境をまたいでコンテナと仮想マシンのための一貫したプラットフォームを提供します。
Note: 既存の NKE 顧客について
Nutanix Kubernetes Engine(NKE)の顧客は、Nutanix Kubernetes Platform(NKP)2.12 以降に移行できます。 NKE は、バージョン 2.10 以降はリリースされません。
Nutanix Unified Storage(NUS)は、永続的で拡張性のあるソフトウェアデファインドストレージをKubernetesクラスタに提供します。 これらには、Nutanix CSI Driver を介したブロックおよびファイルストレージと、Nutanix COSI Driver を介したS3互換のオブジェクトストレージが含まれます。 さらに、Nutanix Database Service(NDB)によって、NDB Kubernetes Operator を使用した大規模なデータベースのプロビジョンと操作が可能です。
以降のチャプターで、これらについて詳しく説明します。
チャプター
- Nutanix Kubernetes Platform
- パートナーによるKubernetesディストリビューション
Nutanix Kubernetes Platform
Nutanix Kubernetes Platform(NKP)は、オンプレミス、エッジ ロケーション、パブリッククラウド環境の全体で、Kubernetesクラスタの大規模な展開と管理において一貫した体験を提供します。
このプラットフォームは、開発者の要望に応えるために、純粋なアップストリーム オープンソースKubernetesと、戦略的に選定された最良のインフラストラクチャ アプリケーションを提供しており、それらはKubernetesをプロダクション環境で稼働させるために重要です。 すぐに利用可能な(out-of-the-boxの)アプリケーションについては、Platform Applications を参照してください。
サポートされる構成
本ソリューションは、以下の構成に適用されます:
主要なユースケース:
- コンテナ
- マイクロサービス
- 生成AIフレームワーク
- アプリケーションのモダナイゼーション
- エッジ コンピューティング
- 市販の商用製品
サポートされる環境:
- Nutanix
- vSphere
- パブリック クラウド(AWS、Azure、Google Cloud)
- Pre-provisioned(ベアメタルと仮想マシン)
場所:
- オンプレミス
- パブリッククラウド
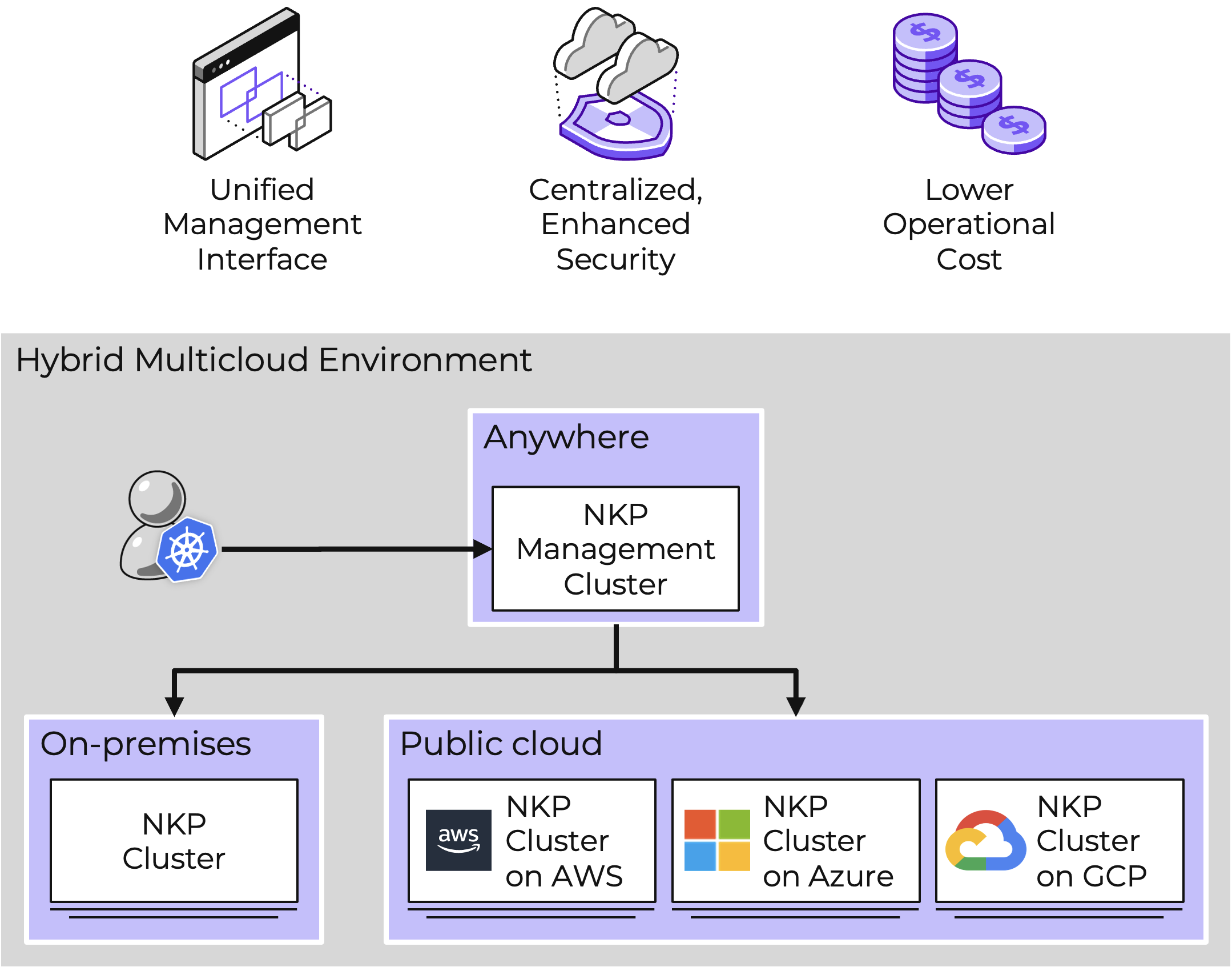
サポートされるOSイメージ:
- Rocky Linux、Ubuntu、Flatcar Container Linux、Bring Your Own Image(BYOI)など。サポートされるイメージの一覧については、Supported Infrastructure Operating Systems を参照してください。
管理インターフェイス:
- NKP UI
- NKP CLI
- kubectl
アップグレード:
- NKP CLI
互換性のある機能:
- マルチクラスタのライフサイクル操作
- ビルトインのマルチテナンシー
- GitOps
- オートスケーリングとセルフヒーリング
- カスタマイズ可能な可観測性と、ログ ダッシュボード
- GPU Operatorのサポート
- AI支援によるチャットボット
- アプリケーション カタログ
- コスト管理
エアギャップ環境:
NKPはエアギャップ環境での展開をサポートしており、組織が安全で隔離された環境でプロダクションKubernetesを運用可能にします。 これには、オンプレミスおよびクラウドベースのエアギャップ環境が含まれます。
クラスタの種類
NKPは、単一のセルフマネージド クラスタとして展開することも、マルチクラスタ アーキテクチャで展開することも可能です。 これらの2環境における異なるクラスタの種類は次のとおりです:
- Management Cluster はNKPをホストし、セルフマネージドで、他のクラスタを管理します。
- Managed Clusters は、NKPによって作成され、NKPマネジメント クラスタによって完全に管理されるワークロード クラスタです。
- Attached Clusters アプリケーション管理のためにNKPに接続された、外部で作成されたワークロード クラスタです。
ハイブリッドクラウドでのFleet管理
NKPのFleet管理は、オンプレミス、クラウド、およびエッジ環境全体でKubernetesクラスタ管理を簡素化し、セキュリティ機能、可視性、自動化、ガバナンス機能を提供して、一貫性とセキュリティを確保します。 またWorkspaceを通じて、異なる部門やビジネス ラインに割り当てられたクラスタの集中管理を可能にします。
アーキテクチャー
The Nutanix Kubernetes Platform(NKP)のアーキテクチャーは、いくつかの主要コンポーネントで構成されています。
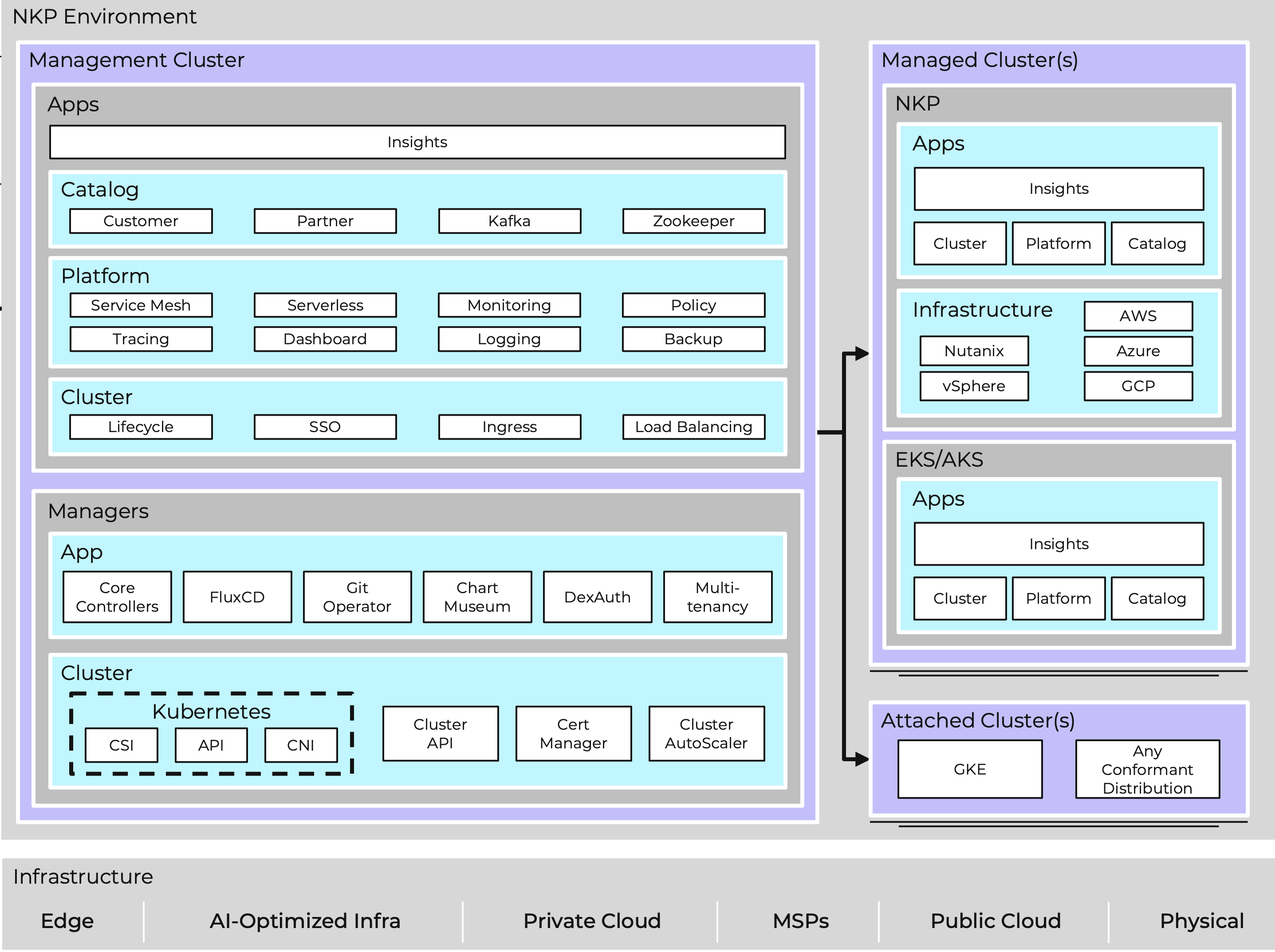
Management Cluster
Management Clusterは、NKPの操作のための中央ハブとして機能します。 ここでは、クラスタとアプリケーションの操作を管理するためのコントローラーであるマネージャーがホストされます。
- Cluster Manager は、クラスタのライフサイクル管理を担当します。 主要なコントローラーはCluster API Controllerであり、Kubernetesクラスタのライフサイクル管理をサポートします。
- Application Manager は、認証、認可、その他のタスクなど、環境レベルの統合を取り扱います。
主要なコンポーネント
Cluster API
Cluster API(CAPI)はNKPの重要なコンポーネントであり、Kubernetesクラスタのライフサイクルを管理するための標準化された方法を提供します。
これは、以下を提供します:
- 作成、スケーリング、アップグレード、削除を含む、自動化されたクラスタのライフサイクル管理。
- ハイブリッドおよびマルチクラウド戦略をサポートし、複数の環境で一貫したAPIを提供。
- カスタムスクリプトや自動化の必要性を排除し、複雑さを軽減して、信頼性を向上させます。
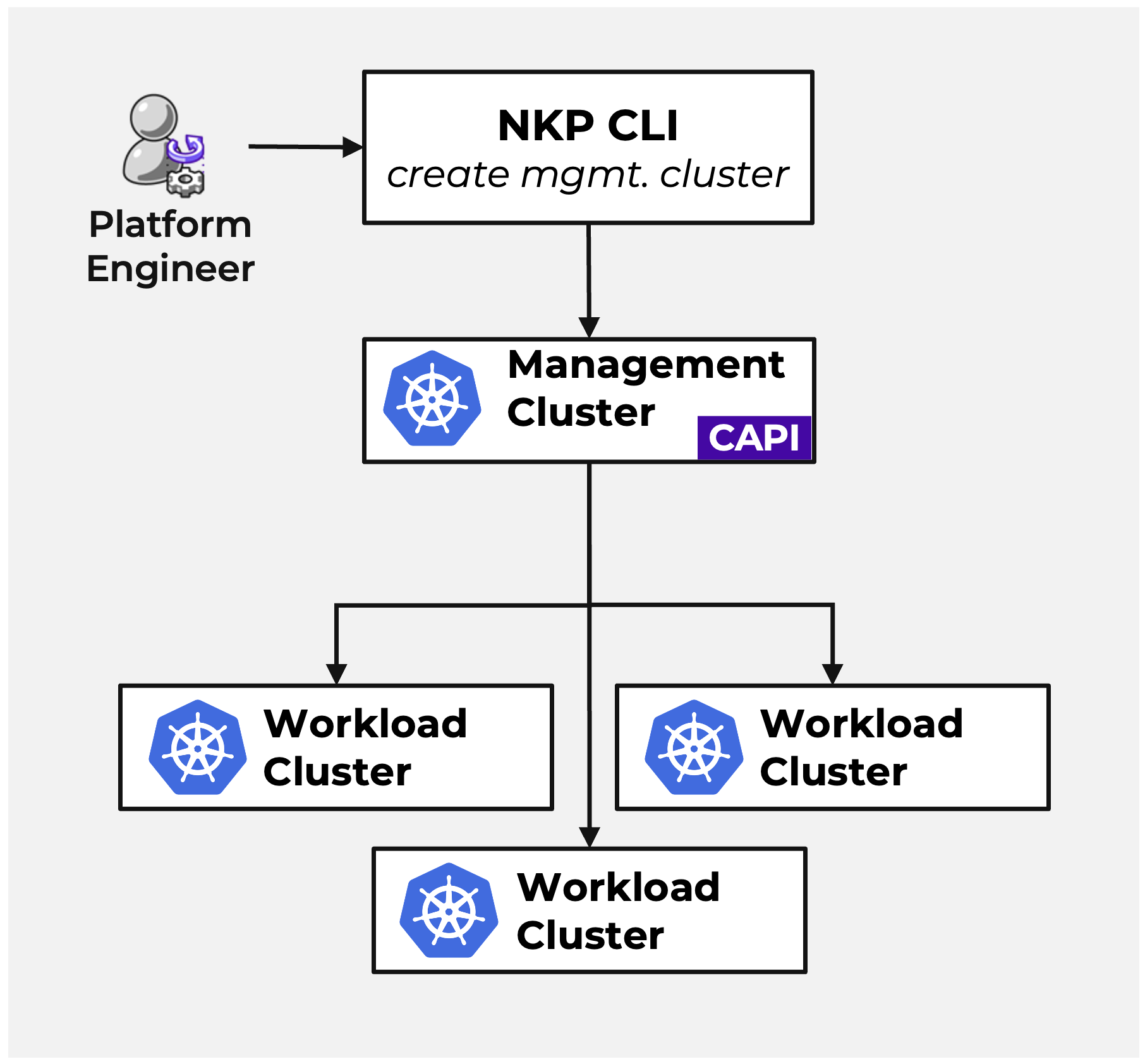
ネットワークとストレージ
- NKPはコンテナ間のネットワーク接続のために、2つのコンテナ ネットワーク インターフェイス(CNI)プロバイダー(CiliumとCalico)をサポートしています。
- コンテナ ストレージ インターフェイス(CSI)は、標準化され、永続的なコンテナ ストレージ管理を提供します。
セキュリティおよびRBAC
- すぐに使用できる(Out-of-the-boxの)SSOとして、LDAP、SAML、OIDC、そしてGitHubをサポート。
- ワークスペースおよびプロジェクト レベルでの、細粒度のRBAC。
クラスタ サービス
クラスタのライフサイクル管理
NKPのクラスタ ライフサイクル管理(LCM)は、運用負荷を軽減し、クラスタの信頼性と効率を向上させます。
- 簡単なクラスタ アップグレード
- オンデマンドでスケールイン / スケールアウトする、ビルトインのクラスタ オートスケーラー
- セルフヒーリングによるクラスタの回復性
Load BalancerとIngress
Load Balancer
- ビルトインのオンプレミス インストール用のロードバランサー(例えば MetalLB)
- クラウドで実行する際には、ネイティブなクラウド プロバイダーのロードバランサーを活用します。
レイヤー7 サービス ルーティング(Ingress)
- NKPでは、HTTPトラフィックのレイヤー7 サービス ルーティングに Traefik を使用し、URLパスやヘッダーに基づく詳細なトラフィック管理を可能にします。
プラットフォーム サービス
可観測性(オブザーバビリティ)
NKPは、以下の手法を用いてKubernetesインフラストラクチャとアプリケーション スタック全体を、監視、追跡、分析することにより、フルスタックの可観測性を提供します:
- Grafana: さまざまなダッシュボード オプション(ビルトイン、カスタム、コミュニティ)を備えた、メトリックとログのデータ可視化ソリューションです。
- Prometheus: メトリックを収集し、保存するための監視およびアラート ツールキットです。 これはクラウド ネイティブ環境向けに設計されており、リアルタイム監視およびアラート機能を提供することで、運用の安定性を確保し、迅速な問題解決を実現します。
- Thanos: Prometheusの拡張機能で、データを集約し、高可用性のメトリクス プラットフォームを提供し、長期保存機能を備えています。
データ サービス
Nutanix Data for Kubernetes(NDK)
NDKは、以下の手法を用いてデータ保護と管理機能を強化します:
- プライマリ環境のパフォーマンスに影響を与えない、ステートフル アプリケーションのための非同期レプリケーション。
- 総合的なアプリケーション パッケージング。
- 効率的なビジネス オペレーションのためのRTOの短縮。
Velero
VeleroはNKPに含まれるオープンソース ツールであり、以下の機能を提供します:
- 災害復旧(Disaster Recovery): アプリケーションの既知の正常な状態への迅速な復元が可能。
- データのマイグレーション: バージョンアップグレード、ワークロードのリロケーション、および環境の移行。
- データ保護: スケジュールされたバックアップと保持ポリシー。
Nutanix Kubernetes Platform Insights(NKP Insights)
NKP Insights Engineは、Kubernetesクラスタ上のイベントとメトリックを収集し、さまざまな重要度の潜在的な異常を検出します。
Nutanix Kubernetes Platformの詳細情報は、以下のリソースを参照してください:
- Nutanix Kubernetes Platformを Test Drive で試してみてください。
- .NEXT 2024 でプラットフォームの機能についてエキスパートが語る様子をご覧ください。
パートナーによるKubernetesディストリビューション
Nutanix Cloud Platformは、認定Kubernetesディストリビューションを実行するための理想的なソリューションです。 Nutanixは、大規模なモダンアプリケーションを正常実行するために必要なすべてのリソースを備えた、エンタープライズクラスのプラットフォームを提供します。
Kubernetesディストリビューションは、コンピューティング、ネットワーク、ストレージを必要とします。 Nutanixを使用することで、IT管理者や開発者はこれらのリソースに簡単にアクセスでき、好みのKubernetesディストリビューションを実行できます。 Red Hat OpenShift、Google Anthosなどを含むいくつかの主要なKubernetesディストリビューションプロバイダーは、ソリューションをNutanixで使用することを認定しています。 サポートされているパートナーソフトウェアソリューションは、Nutanixサポートポータルでオンラインで表示します。
Kubernetesアーキテクチャー
すべてのKubernetesディストリビューションには、少なくとも以下のコンポーネントによる基本的なアーキテクチャーがあります:
- etcd:すべてのKubernetesクラスタ構成データ、状態データ、そしてメタデータを保存するためのKey-Valueストア。
- Kubernetesコントロールプレーン:これには、Podをスケジューリングし、クラスタイベントを検出して応答するためのKubernetes API Serverとその他のコンポーネントが含まれる。
- Kubernetesワーカーノード:アプリケーションワークロードをホストするマシン。

さらに、これらのコンポーネントがすべてのKubernetes コントロールプレーンとワーカーのノードで実行されます。
- Kubelet
- Kube-proxy
- コンテナランタイム
これらのコンポーネントの詳細情報は、Kubernetes documentationで見つけることができます。
Red Hat OpenShift Container Platform
Nutanix上のOpenShift Container Platformでは、複数のインストール方法がサポートされています。 OCPは、Nutanixマーケットプレイスからアプリケーションとして直接デプロイして使用できます。(手順はこちら)
OCP 4.11以降では、フルスタックで自動化された Installer-Provisioned Infrastructure 方式が利用可能です。 OCP 4.12以降では、Assisted Installer 方式もサポートされています。
さらに、永続ストレージを提供する Nutanix CSI Operator は、OpenShift OperatorHub から容易に入手できます。(手順はこちら)
ソフトウェア、ハードウェア、サービスの共同検証による、Nutanix上におけるOpenShiftの Nutanix Validated Design が利用可能です。 これらは、エンタープライズの要件を満たすために詳細な機能テストとスケールテストを経た完全な設計です。 これらのソリューションはモジュールとして事前構築されている性質により、本番環境として容易に導入できることが保証されています。
Amazon EKS Anywhere
EKS Anywhereは、シンプルなクラスタ作成と統合されたサードパーティ ソフトウェアを備えた、オンプレミスでKubernetesクラスタを展開するためのエンタープライズ クラスのソリューションです。 Nutanix Cloud PlatformとAHVハイパーバイザーは、EKS Anywhereがサポートされるインフラストラクチャーを提供します。(詳細はこちら)
Cluster API Provider Nutanix (CAPX)
Cluster APIは、宣言型のKubernetesスタイルのAPIをクラスタの作成と管理のために提供する、Kubernetesのサブ プロジェクトです。 Nutanixは、CAPX として知られる、Nutanix Cloud Infrastructure用のCluster APIの実装を提供します。 Nutanix CSIドライバーは、CAPI/CAPXクラスタで完全にサポートされています。
Google Anthos
Google Anthosは、ベアメタル版Anthosクラスタ のインストール方法を使用して、Nutanix AHVハイパーバイザーを実行するNutanix Cloud Infrastructureにデプロイできます。
Rancher
RancherのKubernetes管理ツールは、Nutanix上で実行されている、あらゆるKubernetesクラスタを管理できます。 Rancherは、Nutanixプラットフォーム上でのRancher Kubernetes Engine(RKE)クラスタのプロビジョニング(詳細はこちら)もサポートしています。 RancherのビルトインのNutanixノード ドライバーをアクティブ化し、ノード テンプレートを作成すると、RKEクラスタにノード プールをプロビジョニングできます。
Azure Arc
Nutanix Kubernetes Engine(NKE)は、Azure Arc対応のKubernetesクラスタを実行できることが検証済みです。 Azureの顧客は、Azure Arcを介して、Azureのデータ サービスと管理機能をオンプレミスのKubernetesクラスタにシームレスに拡張できます。(詳細はこちら)
Kubermatic
NutanixとKubermaticのパートナーシップにより、NutanixはKubermatic Kubernetes Platformのサポートされるインフラストラクチャ プロバイダーです。(詳細はこちら)
Enterprise AI
2022年にChatGPTが誕生したことで、生成AIは世界に大きな衝撃を与えました。 多くの業界が、生成AIをどのように活用してビジネス目標を推進し、効率を向上させることができるかを模索しています。 これはEnterprise AIとして知られています。
Enterprise AIによって期待される成果には、生産性の向上、収益の増加、価値の創出が含まれます。 これらの成果を推進できる可能性が、あらゆる場所の組織に対して、自らの組織にEnterprise AIを実装する動機を与えています。
成功するEnterprise AIには、重要な問いへの答えが求められます:
- どのAIモデルを使うべきか/使っているのか?
- ビジネスのどの部分に生成AIを採用しているのか?
- 生成AIの需要に対応するために、インフラと運用をどのように拡張するのか?
Enterprise AIと、それらの重要な問いに対して組織がどのように答えを見つけられるかについて、さらに詳しく見ていきましょう。
チャプター
- Nutanix Enterprise AI
Nutanix Enterprise AI
Enterprise AIの主なユースケース
主なユースケースには次のものが含まれます:
- より優れたセキュリティの実装
- 不正検知や脅威の監視といった従来型AIの機能を基盤としながら、生成AIを活用して、より適応的な脅威シミュレーションを可能にし、インシデント対応を自動化し、セキュリティ システムの訓練やテストに用いる現実的なデータを生成します。
- コードおよびコンテンツ作成の高速化
- コード作成のCo-pilot、インテリジェントな文書処理、そしてドメイン固有のデータで訓練されたファインチューニング済みモデルを活用することで、ソフトウェア開発と高品質なコンテンツ生成を大幅に加速します。
- 顧客体験の劇的な向上
- 高度な分析を活用して顧客のフィードバックを理解し、パーソナライズされたチャットボットを導入し、顧客に合わせた対応を提供することで、より深いエンゲージメントと満足度を促進します。
Enterprise AIにおける課題
Enterprise AIの導入にあたって一般的に直面する課題には、次のようなものがあります:
- どこから始めればよいかわからない
- 必要となるスキルセットがまだ進化の途中であり、適切な人材を見つけて採用することが困難です。
- 知的財産やデータのセキュリティとプライバシーの確保
- パブリック クラウド ソリューションは展開が容易である一方で、データ主権やセキュリティ要件を常に満たすとは限りません。
- 実用的なソリューションの構築に支援が必要
- アプリケーション開発者とITチームは多くの場合、それぞれ異なる専門性と要件を持っており、両者をサポートできるプラットフォームが不可欠です。
Enterprise AIプラットフォームの構築
Enterprise AI プラットフォームの構築には、スケーラビリティ、信頼性、パフォーマンスを確保するために、複数のコンポーネントと技術の統合が含まれます。
- プライベートAIクラウド インフラストラクチャー
- AI対応ストレージ
- Kubernetes
- ベクトル データベース
- 推論およびエージェント向けのAIプラットフォーム
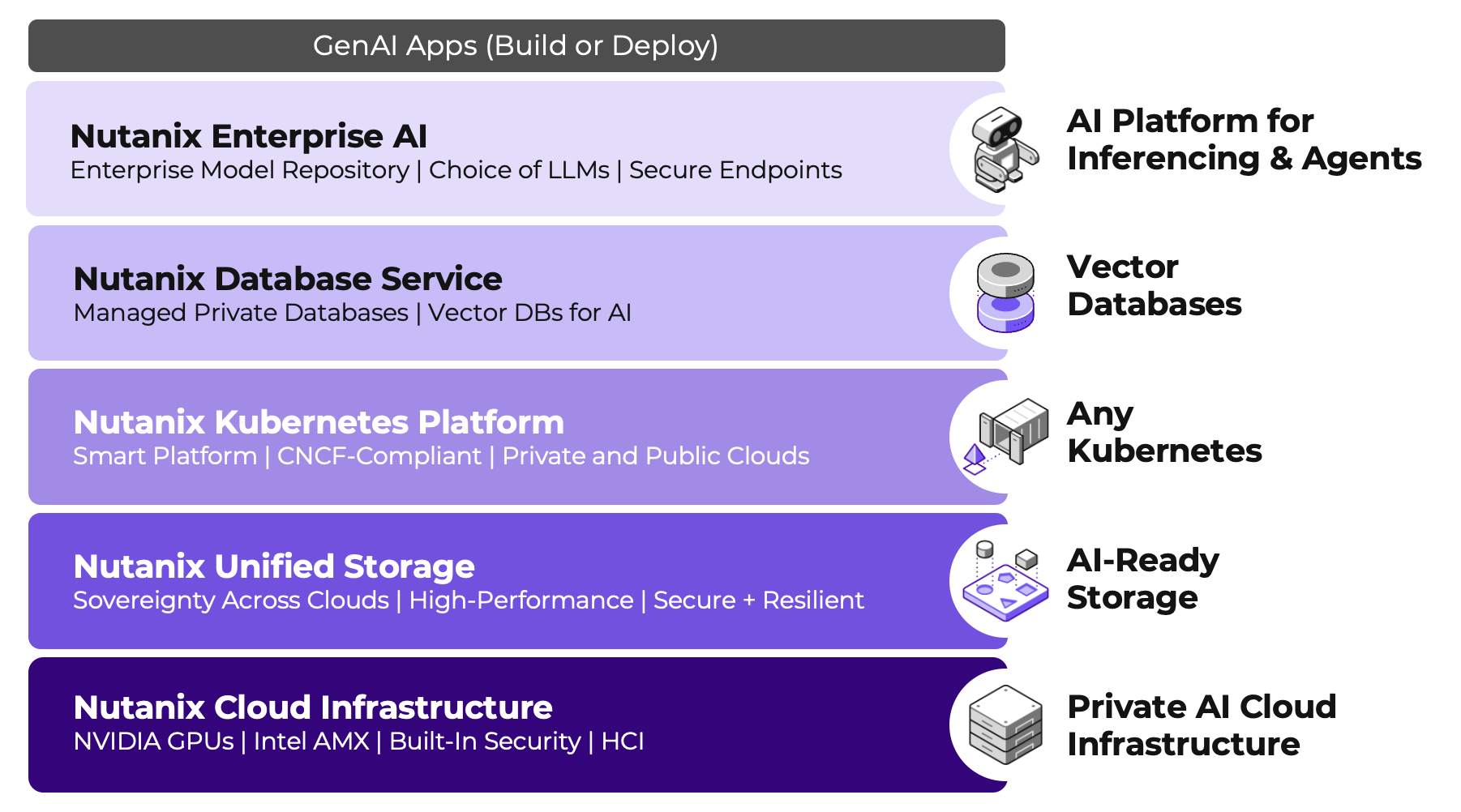
Nutanix Enterprise AI
Nutanix Enterprise AIは、Enterprise AIスタックにおけるAIプラットフォーム コンポーネントを実現するKubernetesアプリケーションであり、IT組織がLLMや推論エンドポイントを管理・展開できるようにします。
Nutanix Enterprise AI は以下の環境にデプロイ可能です:
- Nutanix Kubernetes Platform
- Amazon EKS
- Azure AKS
- Google Cloud GKE
Nutanix Enterprise AI の仕組み
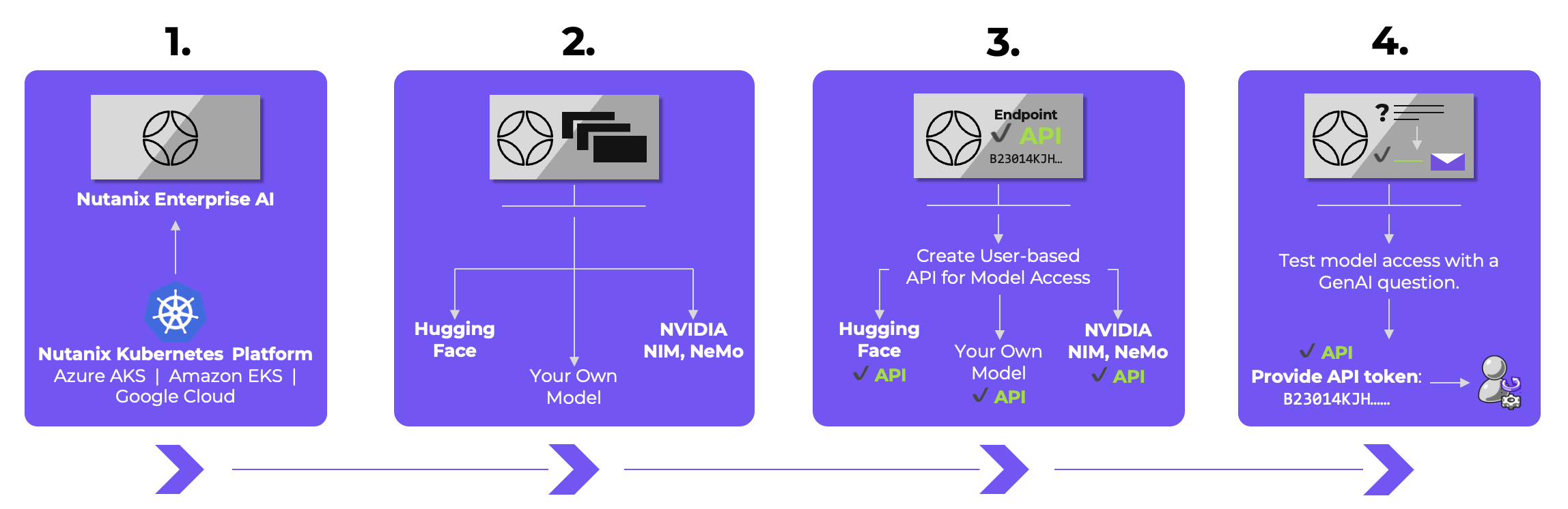
- Kubernetes 上に Nutanix Enterprise AI をデプロイして実行します。
- インターフェイスにログインし、Hugging FaceやNVIDIAから任意のLLMをデプロイするか、独自のカスタム モデルをインポートします。
- セキュアなエンドポイントとAPIキーを作成します。
- アプリケーション開発者やデータ サイエンティストにトークンを送信する前に、UI上でモデルを直接テストします。
そして、エンドポイントの使用状況、インフラストラクチャー、イベント、その他のメトリクスを監視・管理し、組織がどのようにAIを利用しているかを把握するとともに、問題のトラブルシューティングを行います。
Nutanix Enterprise AIの主な機能
- 洗練されたユーザー インターフェイス
- Hugging FaceやNVIDIA NIMから選択可能なAIモデル(LLM)- これは、テキスト生成、安全性(Safety)、埋め込み(Embedding)、リランカー(Reranker)、ビジョン モデルを含む
- 独自AIモデル(LLM)のアップロード
- APIトークンの作成と管理
- Hugging FaceとNVIDIA NIMのためのパートナーAPIトークン管理
- APIコード サンプルの提供
- ロール ベース アクセス制御(RBAC)
- AIモデルの事前テスト
- AIモデルとAPIのモニタリング
- Kubernetesリソースのモニタリング
- GPU使用状況のモニタリング
- イベント監査
- Nutanix Pulseとの統合レポート
- OpenTelemetryによるメトリクスのエクスポート
- エンドポイントのハイバネートとリジューム
使用例:Retrieval Augmented Generation(RAG)
オープン ソースのLLM(MetaのLlamaなど)は、インターネット上の膨大なデータで事前学習されていますが、あなたの組織固有の情報については何も知らない可能性があります。 たとえば、「次の会社の休暇はいつか」と質問した場合、国民の祝日については知っていても、あなたの組織特有の休暇日程については知らないかもしれません。 そこで役立つのが検索拡張生成(RAG:Retrieval Augmented Generation)です。
RAGにおいて重要な要素のひとつが、ドキュメント ストアとベクトル データベースです。 一般的なワークフローでは、ファイルまたはオブジェクト ストレージからドキュメントを取り込み、内容を分割して埋め込み(embedding)処理を行う関数で処理した後、その埋め込みベクトルをベクトル データベースに格納します。 この処理を効率化するために、オープン ソースと商用の両方のツールが利用できます。
ドキュメントの埋め込みが完了すると、RAG対応チャットボットのエンドユーザー向けワークフローは、以下の図のようになります。
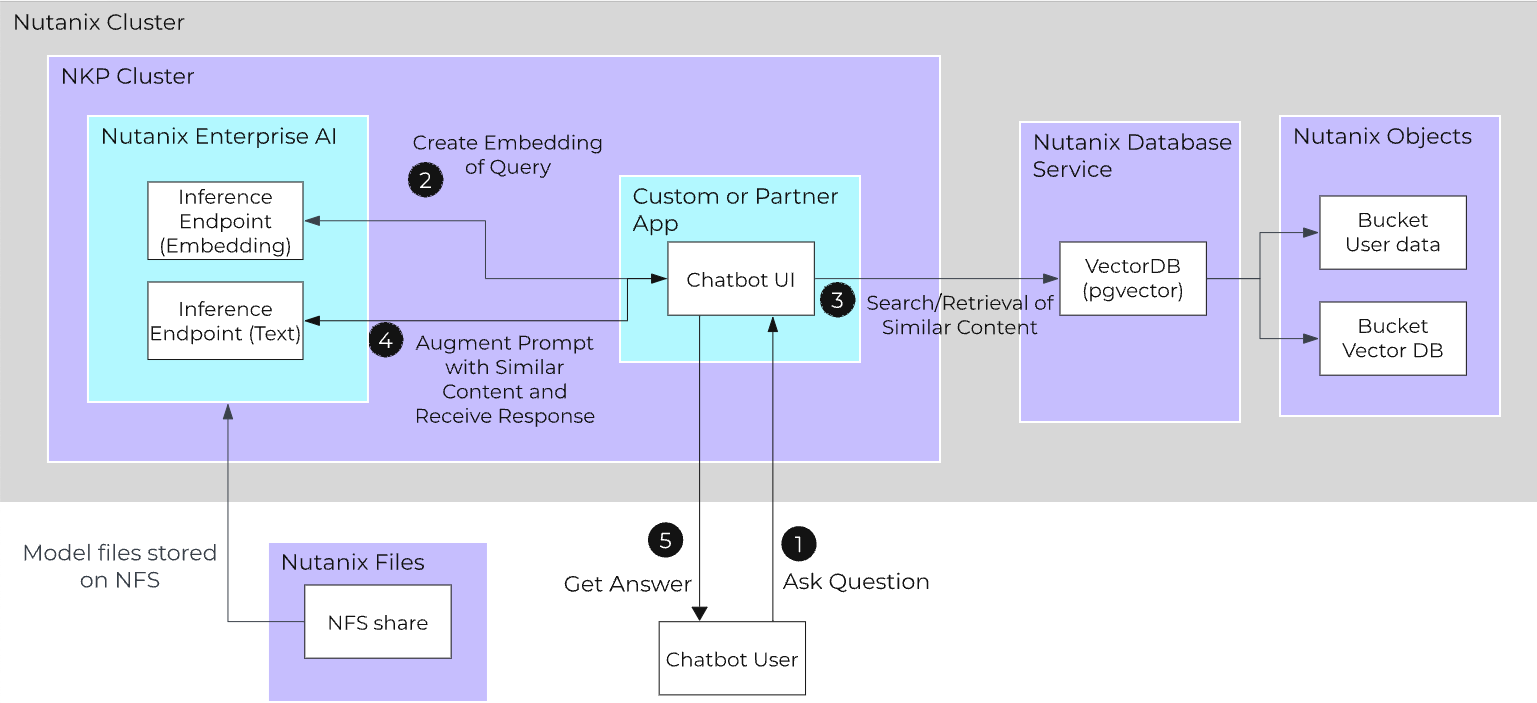
- 質問する
- ユーザーがチャットボットに質問をします。
- クエリの埋め込みベクトルを作成
- 推論APIに直接送信する代わりに、まずアプリケーションはNutanix Enterprise AI上でホストされている埋め込みモデルを使用してクエリの埋め込みベクトルを作成します。
- 類似コンテンツの検索(Search/Retrieval)
- 作成した埋め込みベクトルを使って、ソースのドキュメントの埋め込みベクトルが登録されているベクトル データベースから、類似する埋め込みベクトルを検索します。
- 推論APIにプロンプトを送信
- アプリケーションは、見つかったコンテキストでユーザーのプロンプトを拡張し、それをNutanix Enterprise AI上でホストされているテキスト生成モデルに送信します。
- 回答を取得
- チャットボットがユーザーに回答を返します。
Retrieval Augmented Generationワークフローの設計および実装に関する詳細は、Nutanix Validated Design を参照してください。
その他の参考資料
Nutanix Enterprise AIについてさらに詳しく知り、実際の動作をご覧になりたい方は、以下の参照資料をご確認ください:
- Nutanix Enterprise AI を体験するには、Test Drive をご利用ください。
- AI on Nutanix YouTubeプレイリスト
歴史を振り返る
これまでのインフラストラクチャーの歴史と、現在の状況に至るまでのおおまかな流れを簡単に振り返ってみましょう。
データセンターの進化
データセンターは、過去十年で大きな進化を遂げています。以下のセクションで、各時代を詳しく見てみましょう。
メインフレーム時代
長年に渡りメインフレームは、世の中を支配し今日のシステムの中核的な基礎を築いていきました。多くの企業は主にメインフレームの次のような特性を活かすことができました:
- 生来的に統合されたCPU、メインメモリとストレージ
- 内部冗長性を持った設計
一方でまた、次のような問題も発生しています:
- 多額のインフラストラクチャー導入費用
- 固有の複雑性
- 柔軟性に欠けた、著しくサイロ化された環境
スタンドアローンサーバーへの移行
一部のユーザーは、メインフレームでは実現することができない数々の特徴を持つピザボックス型やスタンドアローン型のサーバーへと移行しました。スタンドアローンサーバーの主な特徴は:
- CPU、メインメモリ、DASストレージで構成
- メインフレームに比べ高い柔軟性
- ネットワーク越しのアクセスが可能
しかし、これらのスタンドアローンサーバーでは次のような問題が発生しました:
- サイロが増加
- 低い、またはバランスの悪いリソース利用率
- コンピュート(計算資源)とストレージの両方にとって、サーバーが単一障害点 (SPOF) になる
集中型ストレージ
ビジネスでは常に利益を生み出す必要があり、データはその重要な要素となります。 直結ストレージ(DAS)を使用する場合、実際に使用する以上の容量が必要となり、またサーバー障害によってデータアクセス出来なくならないよう、データの高可用性(HA)対策が必要でした。
集中型ストレージは、メインフレームとスタンドアローンサーバーを共有可能な大規模なストレージ プールで置き換え、同時にデータ保護機能も提供しました。集中型ストレージの主な特徴は:
- ストレージリソースをプールすることでストレージの使用率を向上
- RAIDによる集中データ保護でサーバー障害によるデータの損失発生を回避
- ネットワーク越しのストレージ処理を実現
集中型ストレージにおける問題点:
- 潜在的によりコストが高い。しかしデータはハードウェアよりもさらに価値がある
- 複雑性の増加(SANファブリック、WWPN、RAIDグループ、ボリューム管理、スピンドルカウントなど)
- 管理ツールや管理チームが別途必要
仮想化の登場
この時点では、サーバーの使用率は低く、リソース効率性が収益に影響を与えていました。 そこに仮想化技術が登場し、1台のハードウェア上で複数のアプリケーションやオペレーティングシステム(OS)を仮想マシン(VM)として稼動させることができるようになりました。 仮想化は、ピザボックスの使用率を向上させましたが、さらにサイロの数を増やし、機能停止が与える影響を増加させる結果となりました。 仮想化の主な特徴は:
- ハードウェアからOSを抽象化 (VM)
- ワークロードを統合できるためサーバーの使用効率が非常に高い
仮想化の問題点:
- サイロの数が増え管理が複雑化
- (初期の仮想化では)VMの高可用性(HA)機能がないため、サーバーノードの障害がより大きな影響を及ぼす
- プールリソースの欠如
- 管理ツールや管理チームが別途必要
仮想化の成熟
ハイパーバイザーは、その効率が向上し機能も充実してきました。 VMware vMotionやHA、DRといったツールの出現により、ユーザーは、VMの高可用性を手に入れることができるようになり、サーバーワークロードを動的に移行できるようになりました。 しかし、1点注意しなければならないのは、集中型ストレージに対する依存性によって競合が発生することです。 つまり、これまで以上のストレージアレイ負荷の増加と不要なVMの乱造がストレージI/Oの競合を招いているのです。
主な特徴:
- クラスタリングによるサーバーリソースのプール
- サーバーノード間で動的にワークロードを移行することが可能 (DRS / vMotion)
- サーバーノード障害に対するVM高可用性 (HA) の提供
- 集中型ストレージが不可欠
問題点:
- VMの乱造による更に大規模なストレージ容量の要求
- ストレージアレイの拡張要求によってサイロの数や複雑性が増加
- ストレージアレイによって1GBあたりの単価が増加
- ストレージアレイ上でリソースが競合する可能性
- 安全性確保のためストレージ構成がより一層複雑に:
- VMのデータストア / LUN比率
- I/O リクエストに対応するためのスピンドル数
ソリッドステートディスク (SSD)
SSDはI/Oのボトルネックを軽減します。より高いI/Oパフォーマンスを提供しますし、大量のディスク筐体も必要ありません。 確かにパフォーマンスは非常に優れていますが、コントローラーやネットワークは、その膨大なI/O処理に追い着いていません。 SSDの主な特徴は:
- 従来のHDDに比べはるかに高速なI/O特性
- 基本的にシークタイムなし
SSDの問題点:
- ボトルネックがディスクのストレージI/Oからコントローラー/ネットワークに移動
- 依然としてサイロは残る
- ディスクアレイ構成の複雑さはそのまま
クラウドについて
クラウドの定義は非常に曖昧なものです。 簡単に言えば、別の誰かがどこかでホストしているサービスを購入し活用できる機能ということです。
クラウドの登場によって、IT部門や業務部門、そしてエンドユーザーのあり方も変わってきています。
業務部門やITの利用者は、クラウドと同様の俊敏性や、価値実現までの早さをIT部門に求めます。 これがかなわない場合には、自ら直接クラウドを利用しようとさえします。 しかし、これがIT部門に別の問題をもたらすのです。 それはデータセキュリティという問題です。
クラウドサービスの柱となるもの:
-
セルフサービス / オンデマンド
- 価値実現までの早さ (TTV - Time to Value) / 利用障壁の低さ
-
SLAに従ったサービス提供
- 稼動時間、可用性、パフォーマンスを契約に基づいた保証
-
フラクショナル(より小規模な単位)な消費モデル
- 使用する分のみの支払い(一部のサービスは無償)
クラウドの分類
一般的にクラウドは、主に以下の3つのサービス形態に分類することができます(レベルの高い順に並べてあります):
- Software as a Service (SaaS)
- URLへのアクセスのみでソフトウェアやサービスが利用可能
- 例: Workday、Salesforce.com、Google searchなど
- Platform as a Service (PaaS)
- 導入、開発のためのプラットフォーム提供
- 例: Amazon Elastic Beanstalk / Relational Database Services (RDS)、Google App Engineなど
- Infrastructure as a Service (IaaS)
- VM、コンテナ、NFV as a service
- 例: Amazon EC2/ECS、Microsoft Azure、Google Compute Engine (GCE) など
IT部門の変化
クラウドは、IT部門に対して目をそむけることのできないジレンマをもたらしています。 IT部門自身がクラウドに取り組んだり、同様の機能を提供したりすることは可能です。 しかし、データは社内に確保したいと望むものの、クラウドのセルフサービス機能や迅速性を提供しなければならないのです。
このような変化によって、IT部門は、エンドユーザー(自社の社員)に対する合理的なサービスプロバイダーとなることを強いられています。
レイテンシーの重要性
以下の表に、各I/Oタイプ別のレイテンシーを示します:
| 項目 | レイテンシー | 補足 |
|---|---|---|
| L1キャッシュ参照 | 0.5 ns | |
| L2キャッシュ参照 | 7 ns | L1キャッシュ×14 |
| DRAMアクセス | 100 ns | L2キャッシュ×20、L1キャッシュ×200 |
| 3D XPointベースのNVMe SSD READ | 10,000 ns(期待値) | 10 us または 0.01 ms |
| NAND NVMe SSD R/W | 20,000 ns | 20 us または 0.02 ms |
| NAND SATA SSD R/W | 50,000-60,000 ns | 50-60 us または 0.05-0.06 ms |
| SSDから4KをランダムREAD | 150,000 ns | 150 us または 0.15 ms |
| P2P TCP/IPレイテンシー(物理から物理) | 150,000 ns | 150 us または 0.15 ms |
| P2P TCP/IPレイテンシー (仮想から仮想) | 250,000 ns | 250 us または 0.25 ms |
| メモリから1MBシーケンシャルREAD | 250,000 ns | 250 us または 0.25 ms |
| データセンター内のラウンドトリップ | 500,000 ns | 500 us または 0.25 ms |
| SSDから1MBシーケンシャルREAD | 1,000,000 ns | 1 ms, メモリ×4 |
| ディスクシーク | 10,000,000 nsまたは10,000 us | 10 ms、データセンターラウンドトリップ x 20 |
| ディスクから1MBシーケンシャルREAD | 20,000,000 nsまたは 20,000 us | 20 ms、メモリ x 80、SSD x 20 |
| CAカリフォルニア州からパケット転送 -> オランダ -> カリフォルニア州 | 150,000,000 ns | 150 ms |
(典拠: Jeff Dean, https://gist.github.com/jboner/2841832)
上記の表から、CPUのキャッシュに対するアクセスは、 ~0.5-7ns(L1対L2)で実施されることが分かります。 メインメモリに対するアクセスは~100 nsで、ローカルのSSDに対する4KのReadは、~150,000 ns、つまり0.15msになります。
一般的なエンタープライズ向けSSD (この場合は、Intel S3700 - 仕様) を利用すれば、次のような性能が得られます:
- ランダムI/Oパフォーマンス:
- ランダム4K Read:最大75,000 IOPS
- ランダム4K Write: 最大36,000 IOPS
- シーケンシャルの転送量:
- 持続的なシーケンシャルRead: 最大500MB/s
- 持続的なシーケンシャルWrite: 最大460MB/s
- レイテンシー:
- Read: 50us
- Write: 65us
転送量について
従来のストレージの場合、I/Oのための主要なメディアタイプが幾つかあります:
- ファイバーチャネル (FC)
- 4-、8- および 10-Gb
- イーサネット(FCoEを含む)
- 1-、10-Gb、(40-Gb IB) など
以下の計算には、Intel S3700のRead 500MB/s、Write 460MB/sのバンド幅を使用します。
計算式は次の通りです:
numSSD = ROUNDUP((numConnections * connBW (in GB/s))/ ssdBW (R or W))
注意: SSDを半端な区切りでは利用できないので、端数は切り上げ(ROUNDUP)しています。 また、全てのI/Oの処理に必要なCPUが十分にあるものとし、また、コントローラーCPUの能力も十分なものと想定しています。
| ネットワーク帯域幅 (BW) | 帯域幅の飽和状態に必要なSSD本数 | ||
|---|---|---|---|
| コントローラーの接続性 | 使用可能な帯域幅 | Read I/O | Write I/O |
| Dual 4Gb FC | 8Gb == 1GB | 2 | 3 |
| Dual 8Gb FC | 16Gb == 2GB | 4 | 5 |
| Dual 16Gb FC | 32Gb == 4GB | 8 | 9 |
| Dual 32Gb FC | 64Gb == 8GB | 16 | 19 |
| Dual 1Gb ETH | 2Gb == 0.25GB | 1 | 1 |
| Dual 10Gb ETH | 20Gb == 2.5GB | 5 | 6 |
この表に示したように、SSDの最大論理パフォーマンスを得ようとすると、ネットワークのタイプによって、1~9つのSSDいずれでもネットワークがボトルネックとなる可能性があります。
メモリのレイテンシーによる影響
一般的にメインメモリのレイテンシーは ~100ns (幅がある) なので、以下のように計算できます。
- ローカルメモリのReadレイテンシー = 100ns + [OS / ハイパーバイザーのオーバーヘッド]
- ネットワークメモリのReadレイテンシー = 100ns + ネットワーク・ラウンドトリップ (NW RTT) レイテンシー + [OS / ハイパーバイザーのオーバーヘッド x 2 ]
一般的なネットワークRTTを~0.5ms(スイッチベンダーにより異なる)、つまり~500,000nsと仮定すると:
- ネットワークメモリReadレイテンシー = 100ns + 500,000ns + [OS / ハイパーバイザーオーバーヘッド x 2]
非常に高速なネットワークで、RTTが10,000nsと理論的に仮定すると:
- ネットワークメモリReadレイテンシー = 100ns + 10,000ns + [OS / ハイパーバイザーオーバーヘッド x 2]
つまり、どんなに理論的に高速なネットワークであっても、ネットワークを介さないメモリアクセスに比べ、10,000%のオーバーヘッドがかかるということです。 低速なネットワークなら、レイテンシーオーバーヘッドは、500,000%にも達することでしょう。
このオーバーヘッドを軽減するために登場したのが、サーバーサイドでのキャッシュテクノロジーです。
ユーザー空間とカーネル空間
よく議論に上るのは、ユーザー空間とカーネル空間の分担についての話題です。ここでは、それぞれの意味とメリット、デメリットについて説明します。
どんなオペレーティングシステム (OS) にも、2つのコアとなる処理領域があります:
- カーネル空間
- OSで最も強い権限を持つ部分
- スケジューリングやメモリ管理などを実施
- 物理デバイスドライバーを包含しハードウェアとのやり取りを実施
- ユーザー空間
- 「その他の全て」
- ほとんどのアプリケーションやプロセスがここに存在
- メモリや実行が保護されている
これら2つの空間が連携することで、OSは機能します。先に進む前に、幾つかの重要な用語を定義しておきます:
- システムコール
- カーネルコールとも呼ばれます。アクティブなプロセスが、カーネルにより処理される何らかの機能を呼び出すための仕組みで、割り込み(詳細は後述)によって実行される
- コンテキストスイッチ
- 実行状態をプロセス側からカーネル側に、またはその逆に切り替える処理
例えば、データをディスクに書き込むような単純なアプリケーションの例を見てみましょう。ここでは次のような処理が行われます:
- アプリがディスクへのデータ書き込みをリクエスト
- システムコールを実行
- カーネルに対するコンテキストスイッチ
- カーネルがデータをコピー
- ドライバー経由でディスクに書き込み処理
以下にこのようなやり取りの例を示します。
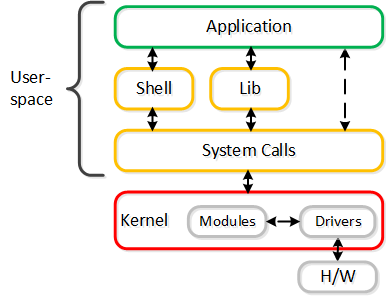
どちらの空間が優れているのでしょうか?実際には、それぞれにメリットとデメリットがあります:
- ユーザー空間
- 非常に柔軟
- 障害の影響が限定的(プロセスまで)
- 非効率的になり得る
- コンテキストスイッチで時間を消費(~1,000ns)
- カーネル空間
- 固定的
- 障害の影響範囲が広い
- 効率的
- コンテキストスイッチが不要
ポーリングと割り込み
もう1つのコアは、カーネル空間とユーザー空間のやり取りを実施するコンポーネントです。やり取りには2つタイプがあります:
- ポーリング
- 継続的に「ポーリング」、つまり何かを問い続ける
- 例:マウス、モニターのリフレッシュなど
- 一定のCPUを消費するがレイテンシーは大幅に低い
- カーネルの割り込みハンドラを使用する必要がない
- コンテキストスイッチが不要
- 割り込み
- 「ちょっとお願いできますか」
- 例:手を上げて何かを頼むようなもの
- 「CPU効率」は良いが、常にそうとは限らない
- 通常は高いレイテンシー
ユーザー空間とポーリングへのシフト
昔に比べると、デバイスは遙かに高速になり(例えば、NVMe、Intel Optane、pMEMなど)、カーネルとデバイスのやり取りがボトルネックになってきています。 このようなボトルネックを排除するために、多くのベンダーが処理をカーネルからユーザー空間に移し、ポーリング方式を採用することで、より優れた結果を得ようとしています。
この良い例として、Storage Performance Development Kit (SPDK)やData Plane Development Kit (DPDK)が上げられます。これらのプロジェクトは、パフォーマンスを最大化し、レイテンシーを最大限縮小して、優れた結果を生みだしています。
このようなシフトは、2つの主要な変更によって可能となっています:
- デバイスドライバーを(カーネルではなく)ユーザー空間に移動
- (割り込みではなく)ポーリングを使用
この方式の場合には、以下を排除できるため、これまでのカーネルベースに比べて遙かにすぐれたパフォーマンスを得ることができます:
- 処理負荷の高いシステムコールや割り込みハンドラ
- データコピー
- コンテキストスイッチ
ユーザー空間に置かれたドライバーを使用したデバイスとのやり取りを以下に示します:
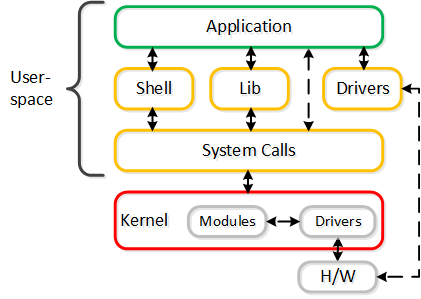
実際に、NutanixがAHVのために開発したソフトウェアの一部 (vhost-user-scsi) が、IntelのSPDKプロジェクトで使用されています。
Webスケール
Webスケール - ウェブスケール - 名詞 - コンピューターアーキテクチャー
インフラストラクチャーおよびコンピューティングのための
新しいアーキテクチャー
本セクションでは、「Webスケール」インフラストラクチャーの核となる概念と、なぜそれを採用するのかについて説明します。 始める前に、Webスケールだからといって、GoogleやFacebook、Microsoftのような「超大規模なスケール」になる必要はないということを明言しておきます。 Webスケールな構成はどんな規模(3ノードでも、数千ノードでも)でも可能であり、その恩恵を受けることができます。
これまでの課題は:
- とにかく複雑
- インクリメンタル(漸増的)な拡張が求められる
- アジャイルでなければならない
Webスケールなインフラストラクチャーについて説明する場合、いくつか重要な要素があります:
- ハイパーコンバージェンス
- ソフトウェア デファインド インテリジェンス
- 自律分散システム
- インクリメンタルかつリニアな拡張性
その他の要素:
- APIベースの自動化と豊富な分析機能
- セキュリティをコアに据えている
- 自己修復機能
以下のセクションでは、これらの技術的な意味を説明します。
ハイバーコンバージェンス
ハイパーコンバージェンスとは何か?という点については、複数の異なる見解が存在します。 対象とするコンポーネント(例えば、仮想化、ネットワークなど)によっても異なります。 しかし、中心となる概念は、「2つ以上のコンポーネントをネイティブに1つのユニットに統合すること」にあります。 「ネイティブに」という点が重要となります。 最大の効率を発揮するためには、該当コンポーネントは、単にひとまとめにする(bundle)のみではなく、ネイティブに統合される必要があります。 Nutanixの場合、サーバーとストレージを1つのノードとしてアプライアンスとして統合しています。 他のベンダーの場合には、ストレージとネットワークの統合という形態であったりします。
ハイパーコンバージェンスとは、つまり:
- 2つ以上のコンポーネントを1つのユニットにネイティブに統合し、容易な拡張を可能にすること
メリットとしては:
- ユニット単位で拡張可能
- ローカライズされたI/O
- サーバーとストレージを統合することで、従来のようなサイロ化を避けることができる
ソフトウェア デファインド インテリジェンス
ソフトウェア デファインド インテリジェンスとは、プロプライエタリなハードウェア、あるいは特殊なハードウェア(例えばASICやFPGA)のコアなロジックを抽出し、それをソフトウェアとしてコモディティハードウェア上で実装するものです。 Nutanixの場合、従来のストレージロジック(例えばRAID、重複排除、圧縮機能など)を抽出し、標準的なハードウェアで構成するNutanix CVM上のソフトウェアとして稼動させています。
サポート対象アーキテクチャー
Nutanixでは、現在、x86とIBM Powerアーキテクチャーの両方をサポートしています。
つまり:
- ハードウェアから主要なロジックを取り出し、コモディティハードウェア上でソフトウェアとして稼動させること
メリットとしては:
- 迅速なリリースサイクル
- プロプライエタリなハードウェアへの依存から脱却
- 経済効率のよいコモディティハードウェアの利用
- 生涯にわたる投資保護
最後の項目について: 古いハードウェアでも、最新の最も優れたソフトウェアを稼動させることができます。 つまり、減価償却サイクルに入ったハードウェアでも、最新版のソフトウェアや、今工場から出荷されている新しい製品と同等な機能が使用できるということです。
自律分散システム
自律分散システム(Distributed Autonomous Systems)は、特定のユニットがある処理に対応するという従来の概念を払拭し、その役割をクラスタ内の全てのノードで分散して受け持つというものです。 これこそが本当の分散システムです。これまでベンダーは、ハードウェアは信頼性に足るものだと仮定し、ほとんどの場合それは正解でした。 しかし、分散システムでは、いずれハードウェアは障害を起こすものと想定し、それに的確かつ停止なく対処できるということが重要だと考えます。
これらの分散システムは、障害への対応と修正が行なえるようデザインされており、自己修復あるいは自律的な回復が図られるようになっています。 コンポーネントに障害が発生すると、システムはユーザーに意識させることなく障害を処理・修復し、想定通りに運用を継続します。 ユーザーはアラートによって障害に気付きますが、急を要するものでない限り、管理者のスケジュールに沿って修復(例えば障害ノードの交換)を行うことができます。 別の方法として、障害を置き換える(交換せずに再構築する)方法もあります。「リーダー」に障害が発生した場合、新しいリーダー選定プロセスが働き、該当する対象に割り当てられます。 処理の分散については、MapReduceの概念が用いられます。
つまり:
- 役割や責任をシステム内の全ノードに分散する
- タスクの分散処理に、MapReduceのような概念を採用する
- 「リーダー」が必要な場合、選定プロセスを使用する
メリットとしては:
- 単一障害点 (SPOF) を排除
- ワークロードの分散によりボトルネックを排除
インクリメンタルかつリニアな拡張
インクリメンタル(漸増的)かつリニア(線形的)な拡張とは、当初は限定的なリソースからシステムを開始し、必要に応じてパフォーマンスをリニアに拡張していくことを意味します。 この拡張性の実現には、前述した要素が全て不可欠となります。従来、仮想ワークロードを処理するためには、サーバー、ストレージ、ネットワークという3階層のコンポーネントが必要で、それぞれは個別に拡張する必要がありました。 例えば、サーバー数を拡大しても、ストレージのパフォーマンスも拡張されるわけではありません。
Nutanixのようなハイパーコンバージドプラットフォームでは、ノードを拡張すると同時に、以下の要素も拡張されます:
- ハイパーバイザーおよびサーバーノード数
- ストレージコントローラー数
- サーバーおよびストレージのパフォーマンスと容量
- クラスタ処理全体に参加させるノード数
つまり:
- ストレージとサーバーのパフォーマンスと能力を、インクリメンタルかつリニアに拡張することが可能
メリットとしては:
- スモールスタートから拡張が可能
- 規模によらず一律で堅実なパフォーマンスを実現
理解しておきたい内容
まとめ:
- (物理サーバーにおける)非効率な計算資源の利用が、仮想化への移行へとつながった
- vMotionやHA、DRSといった機能に対応できるよう集中型のストレージ装置が登場した
- VMの乱造がストレージへの負荷やリソース競合状態を増加させた
- SSDが問題を緩和したが、ネットワークやコントローラーがボトルネックとなった
- キャッシュ/メモリへのアクセスをネットワーク経由で行うと、大きなオーバーヘッドが発生し、メリットが失われる
- アレイ構成の複雑さは解決されることなく従来どおり
- サーバーサイドのキャッシュが、アレイの負荷やネットワークへの影響を軽減したが、ソリューション実現には、新たに別のコンポーネントが必要となる
- 処理をローカルで完結させれば、従来はネットワーク経由の処理により発生していたボトルネックやオーバーヘッドを軽減できる
- インフラストラクチャー自体よりも、管理の簡素化やスタックのシンプル化に、もっと目を向けるべきである
- それを実現できれば、Webスケールな世界のできあがりです!
Nutanix Cloud バイブルについて
Nutanix Cloud バイブルは、Dheeraj Pandey(元Nutanix CEO)とSteven Poitras(元 Nutanix Chief Architect)なしでは実現できませんでした。
Nutanix Cloud バイブルが誕生した理由と経緯について、Dheeraj の言葉を引用します。
最初に、「バイブル」という本書の名前ですが、神に関心のない方や、無神論者であるため自分には関係ないと思われる方もいらっしゃるかと思います。 しかし、辞書「Merriam Webster」によれば、「バイブル」とは、たとえ宗教とは関係のない事柄であっても、聖書のように「高い権威や幅広い読者層を持つ傑出した出版物」という意味を持ちます。 この表現によってNutanix Cloud バイブルの本質を理解することができます。 本書は、Nutanixの中では、常に控えめな立場を取りながら、一方では最高レベルの知識を有する1人で、Nutanix最初のソリューションアーキテクトでもあるSteven Poitrasが最初に執筆を始めたものです。 彼は「初期からの社員」という立場に甘んじることなく、この分野の権威であり続けています。 彼の知識そのものがNutanixに力を与えているのではなく、自らの知識を共有しようという彼の行動力こそが、Nutanixという会社をより強いものにしています。 この分野における彼の高い専門性、PowerShellやPythonを活用した面倒な作業の自動化、卓越した(そして内容と形態が美しくバランスされた)リファレンスアーキテクチャーの構築、YammerやTwitterに関して助けが必要なメンバーのリアルタイムな支援、内省や自己改善を必要としているエンジニアとの透明な関係、さらに、常に意欲的であることこそが、Nutanixという会社の文化を形成しているのです。
彼はブログを書き始めるにあたって、内容の透明性を維持し、デザインをオープンにすることで業界の支持を築きあげるという大きな夢を持っていました。 企業として考えた場合、彼がブログに書いたようなレベルでデザインやアーキテクチャーを公開することは稀です。 確かに、オープンソース企業は、ソースコードを公開しているため透明性が高いように思われますが、デザインの詳細や内部的な動作の仕組みについては、決して語ろうとはしません。 しかしNutanixの競合相手が製品やデザインの弱点を知れば、逆にそれはNutanixを強くすることにも繋がるのです。 なぜなら、Nutanixに隠すべきものがほとんどなく、特定の領域でピンポイントの批評が得られるなら、それはNutanixにとって役に立つものだからです。 機能やデザインに対する一般からの評価については、それが本当の弱みなのか、あるいは、本来は強みにもかかわらず誰かの恐怖心を煽っているだけなのかを、企業向けソーシャルネットワークであるYammerを通じて、遅かれ早かれ結論付けることができます。 つまりNutanix Cloud バイブルによって、自分達を過信するといったあやまちを避けることができるのです。 本Nutanix Cloud バイブルは、お客様やパートナーに対する誠実心の表明なのです。
この日々進歩し続ける記事の内容は、単に専門家だけでなく、世界中の読者を楽しませています。 アーキテクトやマネージャー、CIOまでがカンファレンス会場のロビーで私を呼び止め、鮮やかで明解な記述と詳細な解説図や図表についての賛辞を述べてくれます。 本書においてSteven Poitrasは、話の内容を省略することなくWebスケールについて語っています。 ほとんどの現場のITの担当者が、世の中の「スピード」に追随できず埋もれていく中で、誰もがNutanixの分散アーキテクチャーを活用できるようにすることは、決して容易ではありませんでした。本バイブルでは、コンピューターサイエンスとソフトウェアエンジニアリングのトレードオフを非常に分かりやすい言葉で表現しており、ITとDevOpsの間のギャップを埋めることができます。Nutanixは、この3~5年間で、IT担当者がDevOpsのWebスケールな専門用語を使って会話するようになるだろうと考えています。
いつも誠実たらんことを
-- 元 Nutanix CEO、Dheeraj Pandey
後書き
さらにNutanixを学ぶために、ご自身で Nutanix Test Drive をチェックしてください!
Nutanix Cloud バイブルをお読みいただき、ありがとうございました。これからも更新を続けていきますので、どうかお見逃しなく。そして、どうぞNutanixプラットフォームをお楽しみください!